文章目录
- 摘要
- Abstract
- 一、图像预处理
-
- [1. 图像滤波](#1. 图像滤波)
-
- [1.1 高斯模糊:](#1.1 高斯模糊:)
- [1.2 中值模糊:](#1.2 中值模糊:)
- [1.3 拉普拉斯滤波器:](#1.3 拉普拉斯滤波器:)
- [1.4 双边滤波器:](#1.4 双边滤波器:)
- [2. 使用分割技术检测和移除背景](#2. 使用分割技术检测和移除背景)
- [3. 数据集增强](#3. 数据集增强)
- [4. 像素值调整](#4. 像素值调整)
- 二、案例:图片文字提取器
-
- [1. 原始版本](#1. 原始版本)
-
- [1.1 代码解读](#1.1 代码解读)
- [2. 进一步探究](#2. 进一步探究)
- 总结
摘要
本周围绕图像预处理与 OCR 文字提取展开,系统学习了图像滤波(高斯、中值、拉普拉斯、双边滤波)、背景分割(阈值化、边缘检测等)、数据集增强(翻转 / 旋转、裁剪等)、像素值调整(二值化、灰度化、归一化)四类核心图像预处理技术的原理与应用场景。
同时,以 EasyOCR 为工具搭建图片文字提取器,展示了从图像读取、灰度化 / 高斯滤波降噪到文本识别的完整流程,还进一步探究了裁剪、旋转等图像调整对识别精度的影响,并实现了为识别文本添加检测边框的可视化功能。
Abstract
This week, my learning focused on image preprocessing and OCR text extraction. I systematically studied the principles and application scenarios of four core image preprocessing techniques:image filtering (Gaussian filtering, median filtering, Laplacian filtering, bilateral filtering);background segmentation (thresholding, edge detection, etc.);dataset augmentation (flipping/rotation, cropping, etc.);pixel value adjustment (binarization, grayscale conversion, normalization).
Meanwhile, I built an image text extractor using EasyOCR as the tool, demonstrating the complete process from image reading, grayscale conversion/Gaussian filtering for denoising, to text recognition. Furthermore, I explored the impact of image adjustments (such as cropping and rotation) on recognition accuracy, and implemented a visualization function to add detection bounding boxes to the recognized text.
一、图像预处理
参考文章列表:
1,【原文链接:https://blog.csdn.net/matt45m/article/details/137092314】
2,【原文链接:https://blog.csdn.net/2302_80961196/article/details/153827359】
1. 图像滤波
图像滤波的作用是平滑图像、去除噪声、增强图像等。滤波操作可以通过应用各种类型的滤波器来实现,其中包括线性滤波器(如均值滤波、高斯滤波)和非线性滤波器(如中值滤波)等。
1.1 高斯模糊:
高斯模糊过滤器减少图像中的细节和噪声。它通过对每个像素及其周围像素应用高斯函数来"模糊"图像。这可以帮助平滑边缘和细节,为边缘检测或其他处理技术做准备。
实验证明:高斯核越大,模糊的范围越大。因此核大小合适时,会有磨皮效果,过大则会非常模糊,过小则边界明显。
效果如下:

1.2 中值模糊:
中值模糊过滤器适用于从图像中去除盐和胡椒噪声。它的工作原理是用邻近像素的中值替换每个像素。这可以帮助平滑孤立的噪声像素,同时保留边缘。
高斯滤波和中值滤波的区别:
高斯滤波:处理细小,均匀的噪点。将噪点与原图中像素点进行处理取加权平均值,最后使得噪点融入图片,虽然原图细节没有了,但是噪点并不突兀了,像加了磨皮滤镜。
中值滤波:处理图片中很显眼的"污点", 用"中位数"取代"平均值"。
1.3 拉普拉斯滤波器:
拉普拉斯滤波器用于检测图像中的边缘。它通过检测强度变化迅速的区域来工作。输出将是一个突出显示边缘的图像,然后可以用于边缘检测。这有助于识别和提取图像中的特征。
1.4 双边滤波器:
双边滤波器在保留边缘的同时平滑图像。它通过考虑像素的空间接近度和颜色相似性来实现这一点。空间上靠近且颜色相似的像素将一起平滑。空间上远离或颜色差异很大的像素不会被平滑。这导致了一个具有锋利边缘的平滑图像。双边滤波器在边缘检测之前的噪声减少中可能有用。
2. 使用分割技术检测和移除背景
检测和移除图像的背景是许多计算机视觉任务中的重要预处理步骤。分割可以将前景主题与背景分离,得到只包含主题的清晰图像。
原图:

常见图像分割方法:
阈值化(Thresholding) :阈值化是将图像转换为二值图像的方法。通过选择一个阈值,像素值高于阈值的被标记为前景,低于阈值的被标记为背景。你可以使用OpenCV的cv2.threshold()函数应用阈值化。
阈值化效果如下:

边缘检测(Edge Detection) :边缘检测可以找到图像中的边缘,即对象之间的边界。Canny边缘检测是一种流行的算法,你可以使用OpenCV的cv2.Canny()函数来实现。

区域生长(Region Growing):区域生长是一种从种子点开始,逐步将相邻像素添加到区域中的方法。你可以使用scikit-image的skimage.segmentation.region_growing()函数来实现。
分水岭算法(Watershed Algorithm):分水岭算法将图像视为地形图,通过模拟水流的流动来分割图像。你可以使用scikit-image的skimage.segmentation.watershed()函数来实现。
3. 数据集增强
数据增强是一种通过生成新的图像来人为扩展数据集大小的技术,有助于减少过拟合并提高模型的泛化能力。常见的图像数据增强包括:
**翻转和旋转:**对图像进行水平或垂直翻转,以及90度、180度、270度的旋转,可以生成新的数据点。这样做可以使模型更好地适应不同的视角和方向。
裁剪:将图像裁剪到不同的大小和比例,可以创建具有不同视野的新图像。随机裁剪和特定比例的裁剪都是常见的方法。
**颜色调整:**调整图像的亮度、对比度、色调和饱和度可以创建具有不同外观的图像。但要小心,不要使图像过度扭曲,以免模型混淆。
**图像叠加:**在图像上叠加透明图像、纹理或噪声可以创建原始数据的变化。例如,添加水印、标志、污垢或高斯噪声等。
**结合技术:**结合多种增强技术可以进一步扩展数据集。例如,结合翻转、旋转、裁剪和颜色调整,可以生成更多样化的图像。
4. 像素值调整
像素值调整类:优化图像基础属性
- 二值化
将图像转换为仅含黑白两种颜色的二值图像(像素值 0 或 255),通过设定阈值区分前景(如文字、目标)和背景。
应用场景:文字识别、条形码提取、轮廓分割(消除灰度渐变干扰)。 - 灰度化
- 归一化
作用:避免因像素值范围不一致导致模型收敛困难(如神经网络输入需标准化)。
二、案例:图片文字提取器
1. 原始版本
powershell
import easyocr
import cv2
# 1. 初始化OCR阅读器(指定语言:中文+英文,启用GPU加速)
reader = easyocr.Reader(['ch_sim', 'en'], gpu=True) # 若没有GPU,设为gpu=False
# 2. 读取图片并预处理(关键步骤:降噪、增强对比度)
img = cv2.imread('D:\Program\DeepseekOCR-learning\Period1-PicPreprocess\Pic\paipai.jpg') # 读取图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转为灰度图(减少色彩干扰)
# 输入的灰度图像(单通道),高斯滤波(去除噪声),确定卷积核大小,以及方向
# 0:x 方向和 y 方向的标准差σ。OpenCV 会自动根据核大小计算
blur = cv2.GaussianBlur(gray, (3, 3), 0)
# 3. 调用OCR识别
result = reader.readtext(blur, detail=1) # detail=1返回详细信息(坐标、置信度)
# 4. 提取纯文本并打印
text = [item[1] for item in result]
print("识别结果:", '\n'.join(text))1.1 代码解读
1,reader.readtext() 内部执行流程:
(1)图像预处理:自动对输入图像(此处为 blur 去噪后的灰度图)进行二次优化
(2)文本检测(Text Detection):使用预训练的文本检测模型,在图像中定位所有可能的文本区域,输出每个文本框的坐标。
(3)文本识别(Text Recognition):对每个检测到的文本框,裁剪出对应的图像区域;将裁剪后的区域输入预训练的文本识别模型,识别出文本内容。
注:计算识别结果的置信度(0-1 之间,越接近 1 越可靠)。
(4)结果格式化:根据 detail 参数,将检测和识别结果格式化为不同结构:
detail=0:仅返回纯文本列表(text1, text2, ...);
detail=1:返回包含坐标、文本、置信度的详细信息列表(默认值)。

2,text = item\[1 for item in result]
代码为:列表推导式,从 result 列表中提取每个文本区域的识别结果(即 item1),最终生成一个纯文本列表。
执行逻辑:遍历 result 中的每个元素 item,取出 item1(文本内容),将所有文本拼接成新列表 text。
3,'\n'.join(text)

"/n"可以换成其他字符,按需求进行使用
2. 进一步探究
对图片进行调整,判别影响
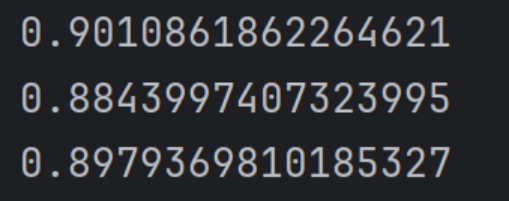
根据平均识别精确度来判别结果是否有被优化。
(1)观察两种精确度的计算方式
(2)下图分别是原图,裁剪后,旋转后的文本识别精确度
添加文本框
powershell
# fix_ocr.py
import os
import sys
from nltk import accuracy
# 在导入任何可能使用OpenMP的库之前设置这些
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
os.environ['OMP_NUM_THREADS'] = '1'
os.environ['MKL_NUM_THREADS'] = '1'
import cv2
import easyocr
import matplotlib.pyplot as plt
import numpy as np
# 1. 设置中文字体(关键步骤)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans'] # 指定字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
#1,initial OCR reading machine and choose language needing to recognize,
reader = easyocr.Reader(['en','ch_sim'], gpu=True)
#2,read img
img = cv2.imread('./Pic/paipai.jpg')
img_cut = cv2.imread('./Pic/paipai_cut.jpg')
img_rotation = cv2.imread('Pic/paipai_spin.jpg')
#3,process the img
#convert the img to a grayscale img
gary = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#remove noise by GaussianBlur
blur = cv2.GaussianBlur(gary, (3,3), 0)
#change original img to RGB and show
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(15,10))
plt.imshow(img_RGB)
#4,change img to text
#reprocess the pic for augmentation and extract information from it
result = reader.readtext(blur)
accuracy = 0
for i,item in enumerate(result):
coords = item[0]
print(f"文本位置{i + 1}:{item[0]}")
print(f"文本内容:{item[1]}")
points = np.array(coords,dtype=np.int32)
for j in range(4):
x1,y1 = points[j]
x2,y2 = points[(j+1)%4]
plt.scatter(x1,y1,s=30,c='red')
plt.plot([x1,x2], [y1,y2], color='red',linewidth=2,linestyle='--')
plt.title('OCR文本检测边框(基础版)')
plt.axis('off')
plt.tight_layout()
plt.show()1,enumerate 不是元组,而是一个内置函数,它返回一个枚举对象(迭代器)。
返回对象索引和内容
enumerate返回的是元组序列

总结
图像预处理是 OCR 的关键前提:不同滤波方式适配不同噪声类型,背景分割、像素调整等操作可减少干扰,提升文本区域的辨识度;数据集增强则能助力 OCR 模型泛化能力提升。
EasyOCR 文字提取核心步骤为「图像读取→灰度化 / 滤波降噪→文本检测(定位文本框)→文本识别→结果格式化」,可通过参数控制返回纯文本或含坐标、置信度的详细信息,满足不同使用需求。