Pandas提供了两种核心数据结构:Series和DataFrame,均基于NumPy数组构建,具备高效的数值计算能力。
DataFrame
DataFrame(数据框)就是excel表(多个Series的拼接)
读取数据
创建一个DataFrame并打印输出:
python
import pandas as pd
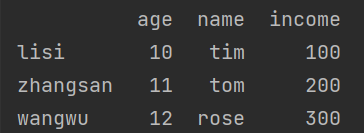
df_1 = pd.DataFrame({'age':[10,11,12],
'name':['tim', 'tom', 'rose'],
'income':[100,200,300]},
index=['lisi', 'zhangsan', 'wangwu'])
print(df_1)运行结果如下:
dataframe的属性:
python
#行索引
df_1.index
#列名
df_1.columns
#值
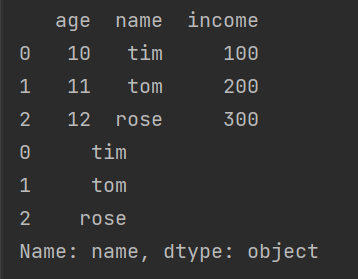
df_1.values读取name这一列:
python
df_1 = pd.DataFrame({'age':[10,11,12],
'name':['tim', 'tom', 'rose'],
'income':[100,200,300]})
print(df_1)
print(df_1.name)运行结果 :
排序和值替换
创建一个表格:
python
import pandas as pd
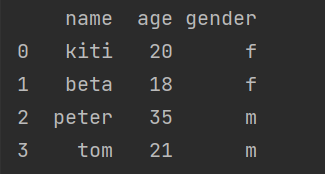
dic = {'name': ['kiti', 'beta', 'peter', 'tom'],
'age': [20, 18, 35, 21],
'gender': ['f', 'f', 'm', 'm']}
df = pd.DataFrame(dic)
print(df)排序:
python
df = df.sort_values(by=['age'])
df = df.sort_values(by=['age'], ascending=False)值替换:
python
a = df['gender']
b = a.replace(['m', 'f'], ['male', 'female'])
df['gender'] = b
print('d')运行结果:
Series
Series:(系列)可以看做竖起来的list
python
import pandas as pd
#生成第一个Series[按照默认的index]
s_1 = pd.Series([1,2,3,4,5])
print(s_1)
#自定义index
s_2 = pd.Series([1,2,3,4,5], index=['a', 'b', 'c', 'd', 'e'])
print(s_2)
s_3 = pd.Series(['Lily', "Rose", "Jack"])
print(s_3)
#Series的一些属性
s_1.index
s_2.index
s_1.values
s_3.values生成一个series对象
python
import pandas as pd
s_1 = pd.Series([1,2,3,4,5],
index=['a', 'b', 'c', 'd', 'e'])
s_2 = pd.Series(['lily', 'rose', 'jack'])查找:
1、通过标签访问
python
#访问某个元素
print(s_1['d'])
#访问多个元素[Series的切片]
print(s_1['a':'d'])
#访问多个元素
print(s_1[['a', 'd']])2、通过索引访问
python
print(s_2[2])
print(s_2[0:2])
print(s_2[[0, 2]])
print(s_1[4])删除:
python
s_1 = s_1.drop('a')
#判断一下某个值是否在Series里面
print('jim' != s_2.values)修改:
python
#改
s_2[0] = 'Peter'创建series
python
dic_1 = {"name1": "Peter", "name2":"tim",
"name3":"rose"}
s_4 = pd.Series(dic_1)
print(s_4)重置索引
python
s_4.index = range(0, len(s_4))
print('1')数据框查询的两种方法
loc()方法和 iloc()方法
生成一个指定日期:
python
import pandas as pd
import numpy as np
#生成指定日期
# datas = pd.date_range('20180101', periods=5)#产生一个时间数据,5个
df = pd.DataFrame(
np.arange(30).reshape(5,6),index=['20180101','20180102','20180103','20180104','20180105'],
columns=['A','B','C','D','E','F'])loc()方法
df.locx, y【标签索引】
python
#打印某个值
print(df.loc['20180103', 'B'])
#打印某列值
print(df.loc[:,'B'])
print(df.loc['20180103':,'B'])
print(df.loc['20180103':,['B', 'D']])
#打印某行值
print(df.loc['20180101', :])
#打印某些行
print(df.loc['20180103':,:])iloc()方法
位置索引
python
#获取某个数据
print(df.iloc[1,2])
#获取某列
print(df.iloc[:,2])
#获取某几列
print(df.iloc[:,[1,3]])
#获取某行
print(df.iloc[1,:])
#获取某些行
print(df.iloc[[1,2,4],:])简单操作DataFrame
创建一个DataFrame:
python
import pandas as pd
df = pd.DataFrame(
{'age':[10,11,12],
'name':['tim', 'tom', 'rose'],
'income':[100,200,300]},
index=['person1', 'person2', 'person3'])
print(df修改列名:
python
a= df.columns
df.columns = range(0, len(df.columns))
print(df.columns)修改行名:
python
print(df.index)
df.index = range(0,len(df.index))
print(df.index)在最后添加一列:
python
df['pay'] = [20, 30, 40]
print(df)增加一行:
python
df.loc['person4', ['age', 'name', 'income']] = [20, 'kitty', 200]
print(df)访问DataFrame
访问某列:
python
print(df.name)
a = df.name
b = df['name']访问某些列:
python
print(df[['age', 'name']])访问某行:
python
print(df[0:2])使用loc访问:
python
print(df.loc[['person1', 'person3']])访问某个值:
python
print(df.loc['person1', 'name'])删除
直接在原数据上删除
python
del df['age']
print(df)删除列
python
data = df.drop('name', axis=1, inplace=False)
print(data)解释:表示从 DataFrame df 中删除名为 'name' 的列
axis=1 表示删除的是列(如果是 axis=0 则表示删除行)
inplace=False 表示不直接在原 DataFrame 上修改,而是返回一个删除了 'name' 列的新 DataFrame
删除行
python
df.drop('person3', axis=0, inplace=True)