创新点
- 首次定义 Promptable Concept Segmentation (PCS)可提示概念分割任务,支持通过名词短语、图像样本或两者结合,检测、分割并跟踪图像 / 视频中所有匹配概念的实例,同时保留视频帧间目标身份。
- 引入 "存在头(Presence Token)" 解耦识别与定位任务;采用共享骨干网络的检测器 + 视频跟踪器架构,避免任务冲突。
- 构建四阶段数据引擎,通过媒体筛选、标签生成(含难负样本)、AI 验证器实现标注吞吐量翻倍,生成高质量的合成训练数据。
- 创建包含 20.7 万个独特概念的 SA-CO (大规模概念分割数据集与基准体系),涵盖 12 万张图像和 1.7 千个视频,概念数量是现有基准的 50 倍以上,支持 PCS 任务全面评估
问题
- SAM系列(Kirillov等人,2023年;Ravi等人,2024年)引入了图像和视频的可提示分割任务,专注于使用点、框或掩码进行可提示视觉分割(PVS),每个提示分割一个物体 。虽然这些方法取得了突破,但它们并未解决在输入中任何位置找到并分割某个概念的所有实例这一通用任务(例如,视频中的所有"猫")。
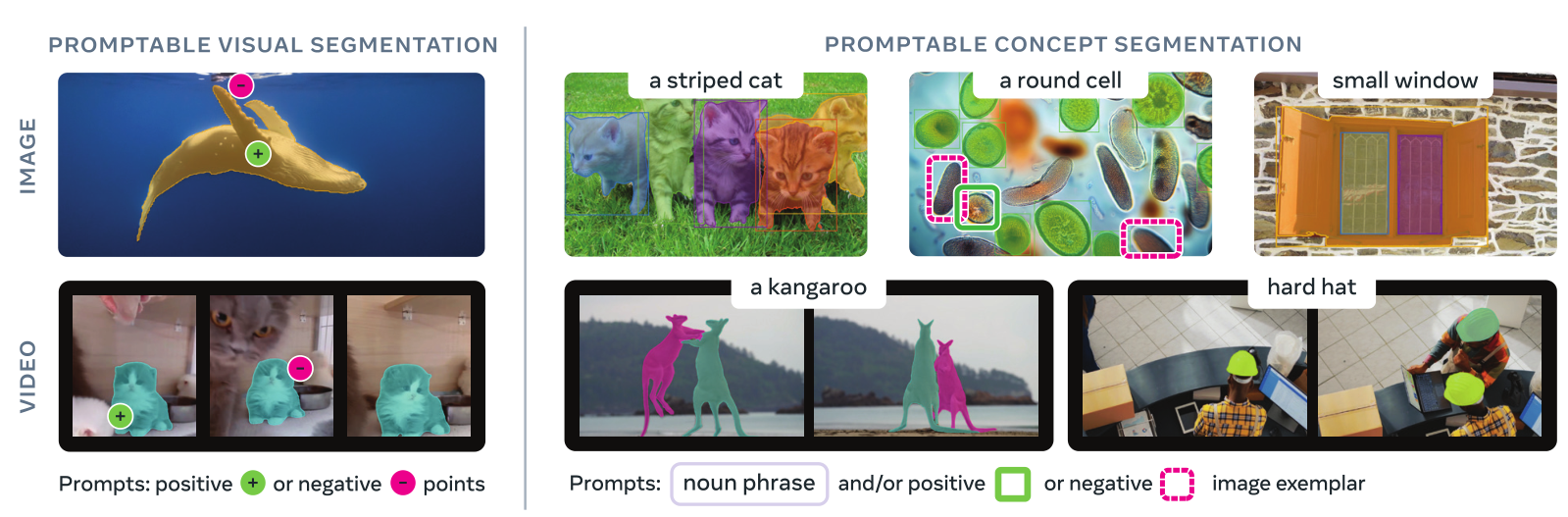
图1 SAM 3在基于点击的可提示视觉分割任务上比SAM 2有所改进(左图),并引入了新的可提示概念分割能力(右图)。用户可以分割由简短名词短语、图像示例(正面或负面)或两者组合所指定的视觉概念的所有实例。
解决方法
-
SAM 3 是一个在图像和视频的可提示分割方面实现跨越式进步的模型。它提高了PVS(可提示视频分割)的性能,并为可提示概念分割(PCS)树立了新的标准。我们将PCS任务形式化为:以文本和/或图像示例作为输入,预测与该概念匹配的每个对象的实例掩码和语义掩码,同时在视频帧中保持对象的身份一致性)。为了专注于识别基本视觉概念,我们将文本限制为简单的名词短语(NP),例如"红苹果"或"条纹猫",SAM 3具有完全的交互性,允许用户通过添加细化提示来解决歧义。

图2 在SA-Co基准测试上,与OWLv2(Minderer等人,2024)相比,SAM 3改进开放词汇概念分割的示例。
-
我们的模型由一个检测器和一个跟踪器组成 ,它们共享一个视觉编码器。为了应对开放词汇概念检测的挑战,我们引入了一个单独的存在头来分离识别和定位 ,这在使用具有挑战性的否定短语进行训练时尤其有效。跟踪器继承了SAM 2的Transformer编码器-解码器架构,支持视频分割和交互式细化。检测和跟踪的解耦设计避免了任务冲突,因为检测器需要与身份无关,而跟踪器的主要目标是在视频中区分不同身份。
-
为了实现显著的性能提升,构建了一个包含人类和模型参与的闭环数据引擎,用于标注一个大型且多样化的训练数据集。
-
数据引擎从带噪声的媒体-短语-掩码伪标签入手,通过人**工和AI验证器检查掩码的质量和完整性,筛选出标记正确的样本,并识别出具有挑战性的错误案例。**然后,人工标注员专注于通过手动修正掩码来修复这些错误。这使我们能够标注出包含400万个独特短语和5200万个掩码的高质量训练数据,以及一个包含3800万个短语和14亿个掩码的合成数据集。此外,我们还为PCS创建了"概念化万物分割(SA-Co)"基准(第5节),该基准包含20.7万个独特概念,在12万张图像和1700个视频中具有完整的掩码。
模型
SAM 3是SAM 2的泛化版本,支持新的PCS任务以及PVS任务。它通过概念提示(简单名词短语、图像示例)或视觉提示(点、框、掩码)来定义需要进行时空(个体)分割的对象。可以在单个帧上迭代添加图像示例和视觉提示,以优化目标掩码------使用图像示例可以分别移除假阳性对象或添加假阴性对象。我们的架构主要基于SAM和DETR系列。
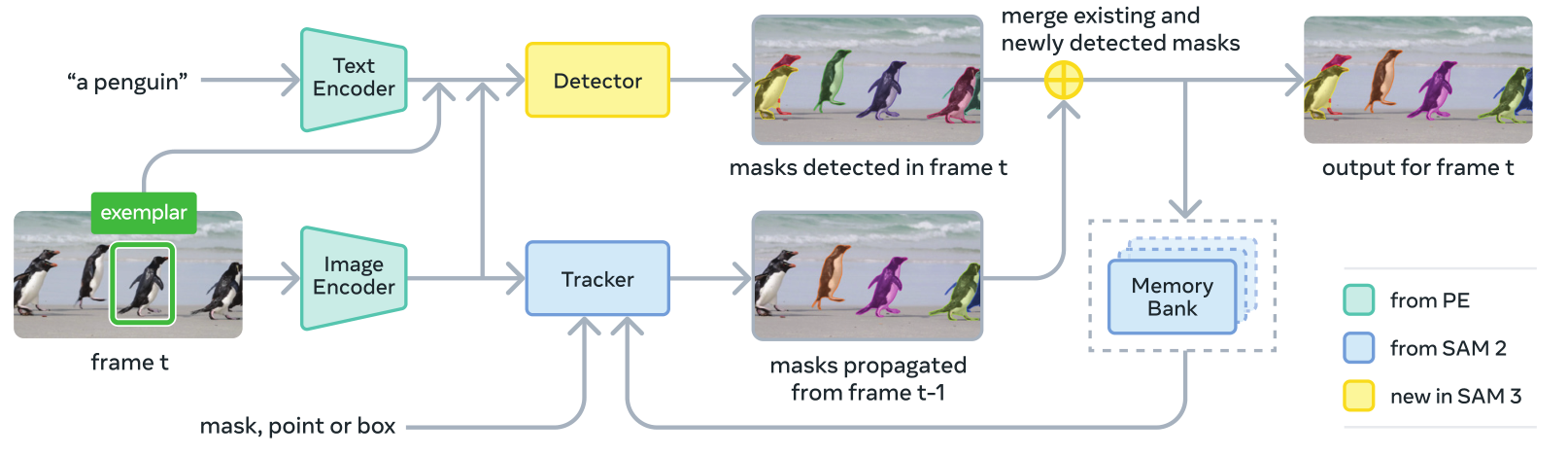
图4 SAM 3架构概述。
-
检测器架构 :该检测器的架构遵循通用的DETR范式。图像和文本提示首先通过位置编码(PE)进行编码 ,若存在图像示例,则通过示例编码器对其进行编码。我们将图像示例令牌和文本令牌统称为**"提示令牌"。然后,融合编码器接收来自图像编码器的无条件嵌入,并通过交叉关注提示令牌对其进行调节。每个解码器层都会为每个对象查询 预测一个分类分数**(在我们的案例中,是一个二元标签,用于表示该对象是否与提示相对应),以及一个与上一级预测的边界框之间的差值的方法。
-
存在令牌 :每个提议查询要同时识别 (是什么)和定位 (在哪里)图像/帧中的对象可能很困难。对于识别部分,来自整个图像的上下文线索很重要。然而,强迫提议查询去理解全局上下文可能会适得其反,因为这与定位目标固有的局部性相冲突。我们通过引入一个习得的全局存在令牌来分离识别和定位步骤。该令牌专门负责预测名词短语(NP)形式的目标概念是否存在于图像/帧中,即P(np)是否存在于输入中。
-
图像示例与交互性 :SAM 3支持图像示例,以一对形式给出------一个边界框和一个相关的二进制标签(正或负),这些可以单独使用或用于补充文本提示。然后,模型会检测所有与提示匹配的实例。例如,给定一个狗身上的正边界框,模型将检测图像中的所有狗。
-
跟踪器和视频架构 :给定一段视频和一个提示词P,我们使用检测器和跟踪器在整个视频中检测并跟踪与该提示词对应的对象。在每一帧上,检测器会找到新的对象O(t) ,跟踪器则将掩码片段M(t-1)(时空掩码)从之前时间(t-1)的帧传播到当前时间t的帧上的新位置 。我们使用匹配函数将传播的掩码片段与当前帧中出现的新对象掩码相关联。
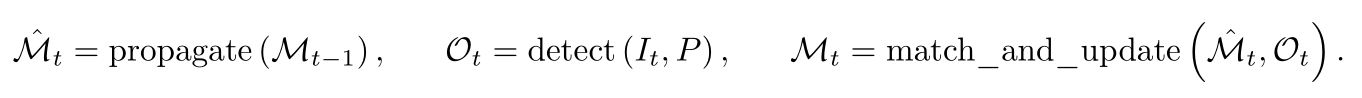
-
使用SAM 2风格传播跟踪对象:为第一帧上检测到的每个对象初始化一个掩码单元。然后,在后续的每一帧上,跟踪器模块预测新的掩码单元位置。基于那些已追踪物体之前的位置,通过单帧传播.
-
基于检测结果的匹配与更新 :在获得跟踪掩码后,我们通过一个简单的基于交并比(IoU)的匹配函数将其与当前帧检测结O(t)进行匹配,并将它们添加到当前帧中。我们还为所有未匹配的新检测对象生成新的掩码单元。这种合并可能会存在歧义,尤其是在拥挤场景中。我们通过接下来概述的两种时间消歧策略来解决这一问题。
(1)我们使用掩码小块检测分数形式的时间信息来衡量一个掩码小块在时间窗口内与检测结果匹配的一致性(基于其在过去帧中与检测结果匹配的次数 )。如果某个掩码小块的检测分数低于阈值,我们就会将其抑制。
(2)我们利用检测器的输出来解决跟踪器因遮挡或干扰物而出现的特定失效模式。我们会定期**用高置信度的检测掩码提示跟踪器,替换跟踪器自身的预测结果。**这确保了记忆库中包含最新且可靠的参考信息(而非仅依赖跟踪器自身的预测结果)。
-
使用视觉提示进行实例优化。在获得初始的掩码集(或掩码片段)后,SAM 3允许使用正向和负向点击来优化单个掩码(片段)。具体来说,给定用户的点击,我们应用提示编码器对其进行编码,并将编码后的提示输入到掩码解码器中,以预测调整后的掩码。在视频中,该掩码随后会在整个视频中传播,以获得优化后的掩码片段。
数据引擎
构建了一个高效的数据引擎,该引擎通过与SAM 3、人类标注员以及A I标注员的反馈循环,迭代生成带注释的数据 ,主动挖掘当前版本的SAM 3无法生成高质量训练数据的媒体-短语对,以进一步改进模型。通过将某些任务委托给AI标注员(那些准确率达到或超过人类的模型),与纯人类标注流程相比,吞吐量提高了一倍多。分四个阶段开发该数据引擎,每个阶段都增加AI模型的使用,以将人类精力引导至最具挑战性的失败案例,同时扩大视觉领域的覆盖范围。第1-3阶段仅关注图像,第4阶段扩展到视频。
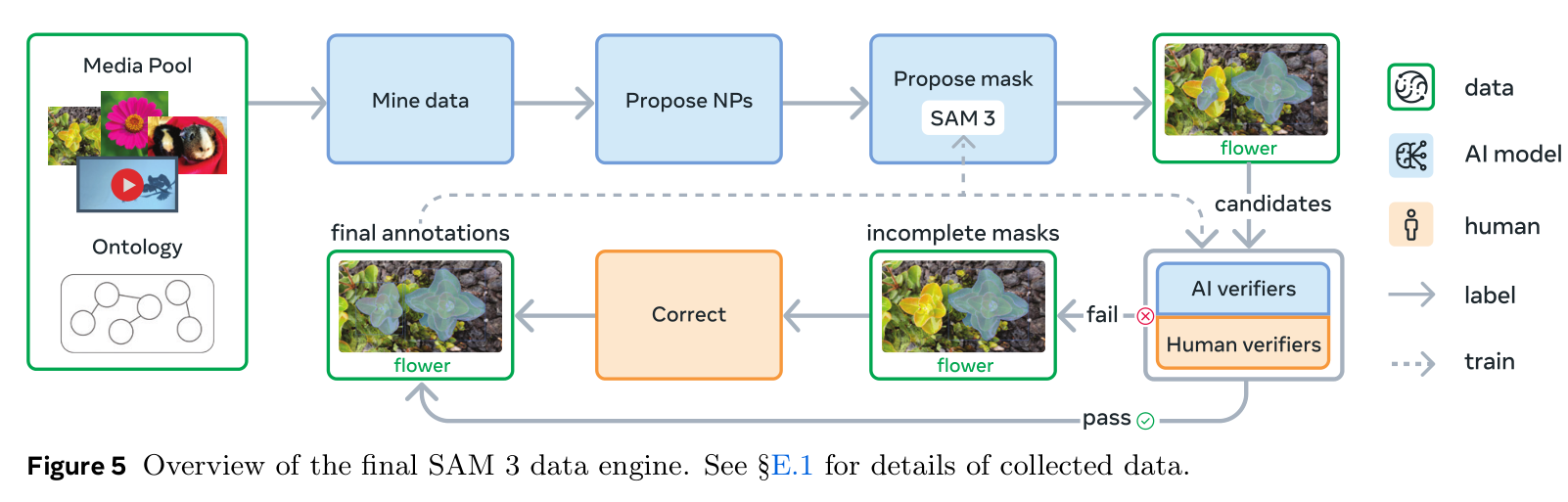
图5 SAM 3最终数据引擎概述。
- 数据引擎组件。借助精心设计的本体,从大型数据池中挖掘媒体输入(图像或视频)。一个AI模型会生成描述视觉概念的名词短语 (NP),随后另一个模型(例如SAM 3)会为每个生成的名词短语生成候选实例掩码 。
生成的掩码通过两步流程进行验证:
(1)在掩码验证(MV)中,标注员根据掩码的质量及其与名词短语的相关性 来接受或拒绝掩码。
(2)在**完整性验证(EV)中,标注员检查输入中该名词短语的所有实例是否都已被掩码标记。**未通过完整性检查的任何媒体-名词短语对都会被送入人工修正阶段,在此阶段,工作人员会添加、删除或编辑掩码。 - 第一阶段:人工验证。我们首先使用简单的字幕生成器和解析器随机采样图像和名词短语提议。初始的掩码提议模型是SAM 2,其提示来自现成的开放词汇检测器的输出,初始验证者为人工。
- 第二阶段:人工+人工智能验证 。在这一阶段,我们利用第一阶段收集到的MV和EV任务中的人工接受/拒绝标签来微调Llama ,从而创建能够自动执行MV和EV任务的人工智能验证器。这些模型接收图像-短语-掩码三元组,并输出关于掩码质量或完整性的多项选择评分。这种新的自动验证流程使我们的人力能够集中在最具挑战性的案例上。我们继续在新收集的数据上重新训练SAM 3,并对其进行6次更新。随着SAM 3和人工智能验证器的改进,自动生成的标签比例更高,进一步加快了数据收集速度。引入用于MV和EV的人工智能验证器后,数据引擎的吞吐量大约是人工标注员的两倍。
- 第三阶段:**扩展与领域拓展。**在第三阶段,我们使用人工智能模型挖掘更具挑战性的案例,并将SA-Co/HQ中的领域覆盖范围扩大到15个数据集。一个领域是文本和视觉数据的独特分布。在新领域中,MV人工智能验证器在零样本情况下表现良好,但EV人工智能验证器需要通过适度的特定领域人工监督来改进。
- 第四阶段:视频标注 。此阶段将数据引擎扩展至视频领域。我们使用成熟的图像SAM 3来收集有针对性的高质量标注,以应对视频特有的挑战。数据挖掘流程会应用场景/运动过滤、内容平衡、排序和定向搜索。视频帧会被采样(随机采样或按目标密度采样)并送入图像标注流程(来自第三阶段)。通过SAM 3(现已扩展至视频领域)生成掩码片段(时空掩码),并通过去重和移除无关掩码进行后处理。
实验
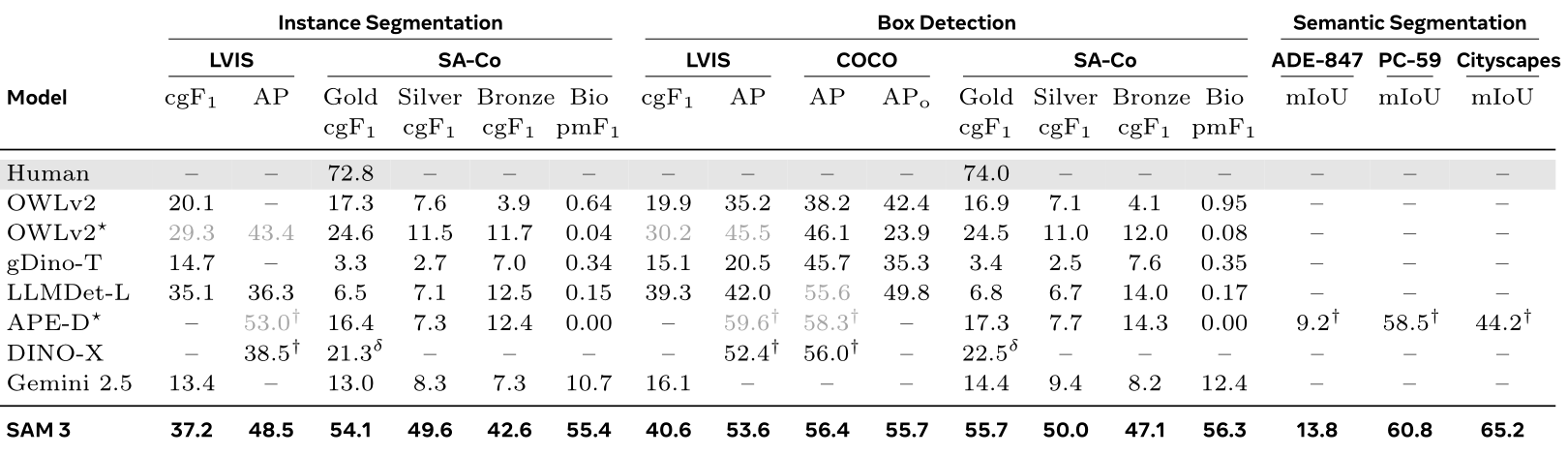
表1 基于文本的图像概念分割评估。(AP)对应COCO-O准确率,⋆:在LVIS上部分训练,†:来自原始论文,δ:来自DINO-X API。灰色数字表示相应闭集训练数据(LVIS/COCO)的使用情况。
实例分割 (Instance Segmentation):分割图像中每个目标的独立实例(如每只猫单独标注);
边界框检测 (Box Detection):仅输出目标的边界框(不做像素级分割);
语义分割(Semantic Segmentation):分割同一类目标的所有像素(如所有猫标为同一颜色)。
cgF₁ :PCS 任务核心指标,结合 "目标是否存在" 的分类准确率和定位准确率;
AP :衡量准确率 - 召回率曲线下面积;
pmF₁ :定位指标,仅计算有真实目标的样本的分割精度;
mIoU:语义分割指标,衡量预测掩码与真实掩码的重叠度。
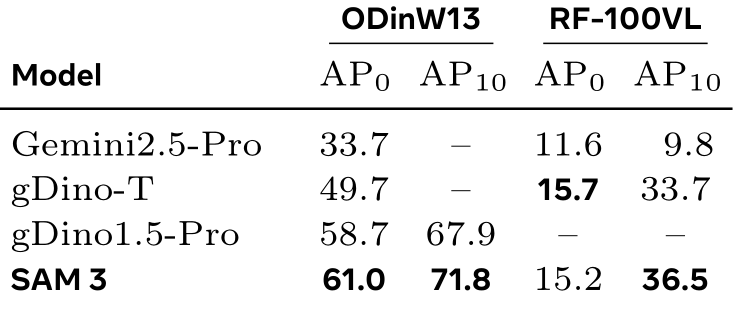
表2 真实世界数据集上的0样本和10样本迁移。
SAM 3 的少样本迁移能力------ 即模型在 "无训练" 或 "少量训练样本" 情况下,适配新场景 / 新领域目标检测任务的能力更强。

表3 在COCO、LVIS和ODinW13上使用1个示例进行提示。按提示类型评估:T(仅文本)、I(仅图像)和T+I(文本和图像结合)。AP+仅在阳性示例上进行评估。
组合提示(T+I)的性能最优,远超仅文本提示,图像样本能有效辅助文本,提升目标匹配精度
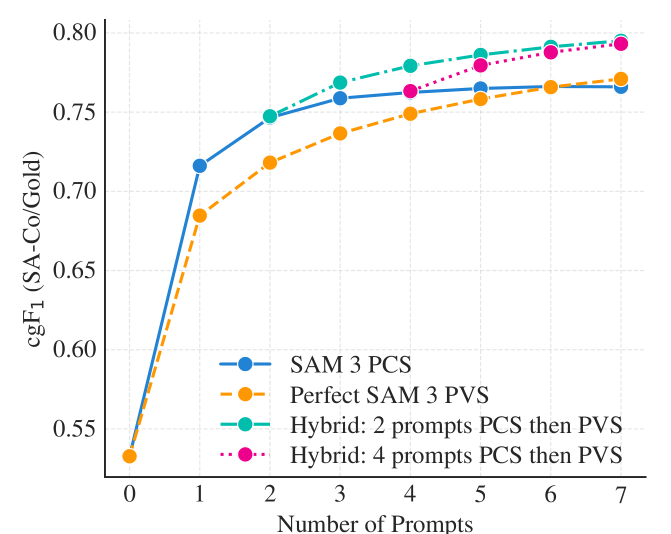
图 7:在 SA-Co/Gold 数据集的短语上取平均后,SAM 3 与理想 PVS 基准在 "cgF₁指标" 和 "交互式框提示数量" 之间的关系对比