通过前面的大致框架+udp+tcp的学习,我们已经大致了解了整个网络是如何搭建的
本篇章将通过网络的视角重新认识一下我们经常使用的软件xshell
目录
通过网络重识shell
我们重新回顾之前的一个小点,再次理解xshell
我们在腾讯或者阿里云上租用的云服务器,只要启动起来就默认启动一个SSH服务程序(通常是sshd)sshd是一个守护进程,后台运行,它是默认监听一个22端口的,xshell是一个本地程序,xshell支持ssh协议,所以通过xshell连接云服务器就是公网ip+端口访问,本质相当于两个进程互相通信,看到同一份资源(网络资源),ssh协议是应用层协议

这里可以看到我的xshell上面需要配置连接哪个公网ip,协议使用的是SSH,端口号是22
|---|---------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------|
| 1 |sshd主进程持续监听 22 端口,等待连接请求 | Xshell 发起 TCP 连接请求,目标是云服务器公网 IP:22 |
| 2 | 云平台 NAT 网关将公网 IP 请求转发到服务器内网 IP:22,sshd主进程接收到连接 | - |
| 3 |sshd主进程调用fork()创建sshd子进程(继承主进程的网络连接) | - |
| 4 |sshd子进程与 Xshell 进行 SSH 加密握手:1. 协商加密算法(如 AES)2. 身份验证(密码 / 密钥校验)3. 建立加密通信通道(完成协议的初始化,后续协议进程好加密解密) | Xshell 响应加密握手,发送账号密码 / 密钥进行验证 |
| 5 | 验证通过后,sshd子进程调用 fork后,exec()系统调用:- 替换sshd的子进程的子进程的程序镜像为用户默认 Shell(如bash)- 进程权限从root降为登录用户权限 (如ubuntu) | Xshell 显示服务器的终端提示符(如ubuntu@server:~$),连接建立完成 |
执行了三次握手
会话本质就是一个客户端,主进程sshd 时刻 listen,来一个客户端就建立三次握手,三次握手完之后accept获取,然后创建一个新的sockfd给这个客户端和云服务器通信,然后fork(),sshd的子进程继承了父进程sshd的文件描述符,继承完之后父进程sshd就会删掉这个accept上来的fd,sshd主进程不需要处理数据传输,保留fd会浪费系统资源;(这里不明白的看我的Linux系统编程章节),子进程进行身份验证等等功能,验证完后初始化SSH加密协议的一些字段(后续作为协议层处理协议的加密解密)+创建子进程,exec(bash)替换程序,sshd的子进程和bash通过管道进行通信,sshd的子进程直接操控sockfd的接收和发送缓冲区,加密和解密,后续通过管道让bash拿到的数据是明文的,只担心处理命令的逻辑即可,bash会修改标准输入输出关联到这个管道。比如命令ls执行,客户端与云服务器之间经过这次建立好了连接,后续就是客户端和sshd子进程进行通信,ls执行,然后经过SSH协议加密,加密之后传输到了sockfd,此时sshd子进程通过sockfd读取到数据,然后解密,解密之后写进管道,bash直接从标准输入的接收缓冲区(因为之前重定向了)拿到解密的ls,之后fork创建bash子进程,exec(ls)程序替换执行ls,返回结果给bash,bash把结果经过管道交给sshd子进程加密,放到标准输出的发送缓冲区,客户端的接收缓冲区收到后进行解密然后呈现在标准输出(屏幕)
注意:外部命令通过 fork+exec 执行,内置命令(如 cd、export)直接在 Bash 主进程执行
再来一个客户端就在创建一个子进程在程序替换成bash程序(重复执行上述流程)
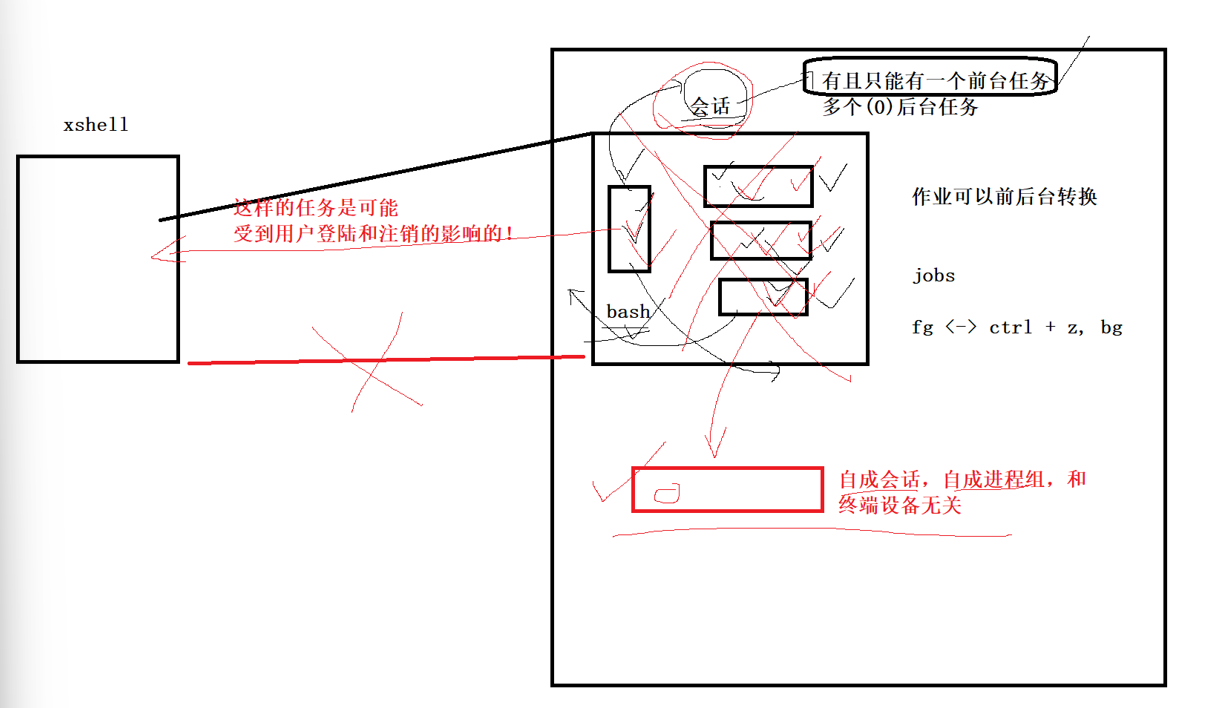
这期间来一个ls,vim,sleep我们都叫作业(bash 对 "当前会话中启动的进程 / 进程组" 的统称)前台任务:占用 bash 的标准输入 / 输出(管道),必须等它执行完,bash 才能接收新命令(比如
vim、ls);后台任务:不占用 bash 的标准输入,在后台运行,bash 可立即接收新命令(比如
sleep 100 &)。一个会话同一时间只有一个前台任务,可以有多个后台,本质就是你只有一个标准输入标准输出,来一个任务bash就fork+exec来执行
jobs:查询作业号ctrl+z:暂停任务
fg:把后台任务切换到前台
bg:把暂停任务切换到后台
先执行sleep,然后vim,vim的时候ctrl+z(暂停前台任务),后面jobs查询,可以看到状态,一个sleep后台一直再跑,前台暂停了,此时fg作业号
又回到了vim的界面,说明此时回到前台任务
注意:如果关闭终端,断开连接,此时所有的任务都会中断
守护进程:是脱离终端、在后台长期运行的系统级进程 ,完全独立于 SSH/Shell 会话 ------ 哪怕关闭所有 SSH 连接,守护进程依然会运行,这是它和普通后台任务(sleep 100 &)最核心的区别,并且不受bash控制,系统进程控制PID=1,自成会话自成进程组普通后台任务:关闭终端,直接就结束了,生命周期和bash同步
注意:创建的守护进程不能是组长比如bash,他去fork+exec(ls),那这个ls的组长是bash,那后面bash不能单独拉出来成为守护进程等
假设如果允许,那ls究竟是跟谁,bash成为了新的组的组长,ls要过去吗还是属于原来的组,如果两个都可以,那信号发送的话是两个都发送?
所以这里不允许组长再去创建守护进程


编写一个自己的守护进程
setsid():
作用:创建新会话,脱离原终端控制,成为新会话首进程(核心:脱离终端依赖)
由于我们一开始通过./test,允许程序,这个交给bash去创建子进程然后进行exec(test)允许,我们可以在其中调用setsid使其脱离bash的管理,成为守护进程
注意不能是组长即可
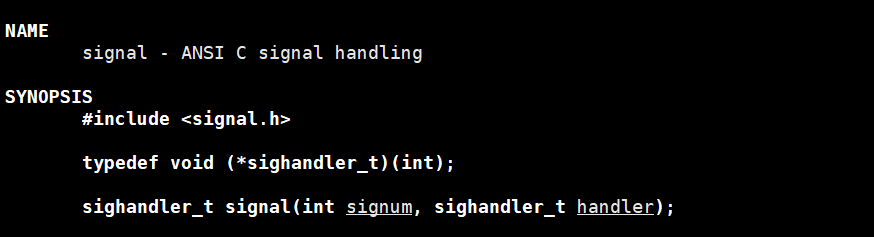
编写守护进程的时候需要忽略异常的信号,守护进程的核心特性是 "脱离终端 / SSH 会话",但内核仍可能向其发送终端相关信号(比如误判进程关联终端),忽略这些信号能杜绝 "无意义的终止",守护进程是 "系统级后台进程"(如sshd/nginx),其生命周期应由显式指令 (kill/systemctl stop)管理,而非随机的异常信号基本是忽略SIGHUP,SIGPIPE等
忽略信号的系统调用接口:signal()
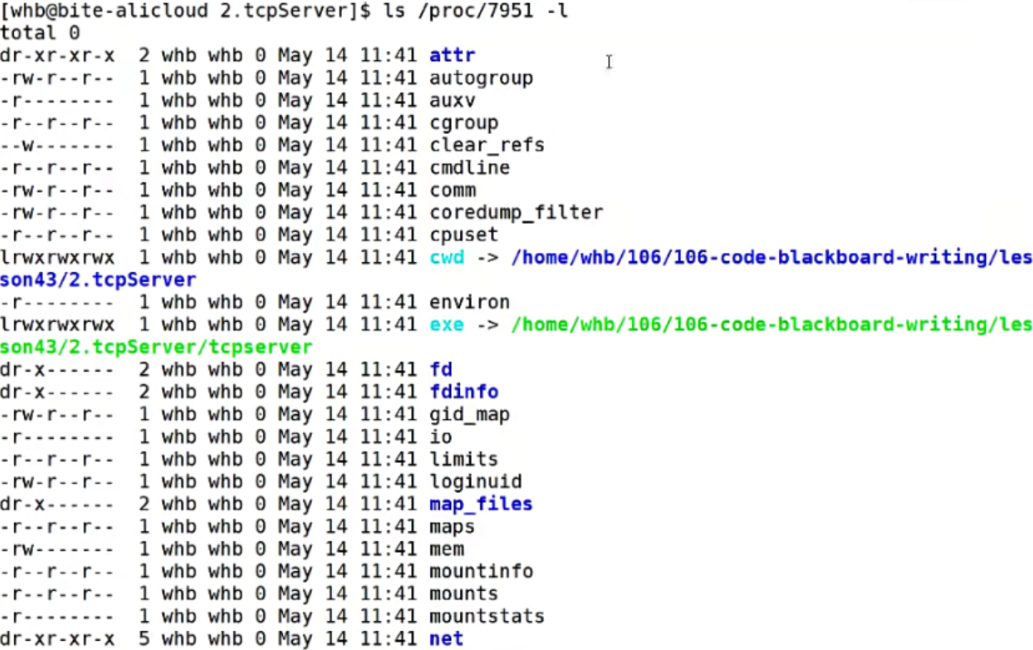
/proc/:此目录是系统进程级目录,一个伪文件系统,实际并不在硬盘当中存储,是内核映射出来的,方便你通过文件接口访问内核数据打开之后进入一个进程看,里面有个cwd,指向进程当前工作目录(Current Working Directory)的符号链接
对于我们之前别写的程序,为什么open不存在时创建是在当前目录下,因为cwd中记录了一个路径,会使用这个路劲创建
这个进程可执行路径发送更改你可选或者不可选都行
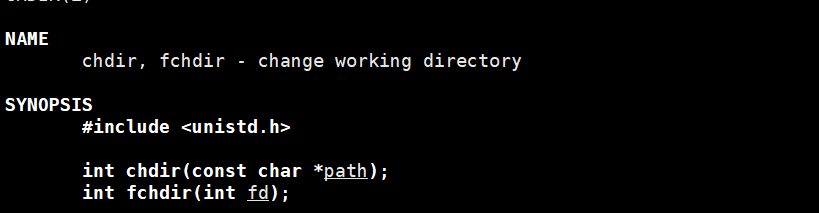
使用chdir函数
/dev/null:这个是 Linux 系统中的 **
/dev/null设备文件 **,它是一个特殊的 "空设备",核心作用是接收任何写入的数据并直接丢弃,读取它则返回空 。这是一个字符设备文件(和磁盘文件、目录的类型不同,是内核提供的虚拟设备);我们后面编写的守护进程是后台进程,跟终端没关系,所以我们需要把标准输入输出重定向到这个设备,相当于丢弃
如果不重定向,直接关闭,有些printf函数都是默认打印到0/1/2的,可能会阻塞
进程分配时会从低到高,所以read可能会占用0,后面你输入输出函数往里面写就不对了(数据污染)
思路:第一步先忽略掉一些影响守护进程的信号
第二步fork创建子进程(虽然说你的进程的组长是bash,可以直接setsid自成组长)
风险:
a. 在你setsid之前仍属于bash子进程,bash可能误发信号让你再调用setsid之前挂掉(可以先fork,然后直接exit父进程,此时fork之后的子进程就可以避免信号残留风险)
b. 有时候不是让bash启动,而是系统直接启动,此时你进程就是组长,那调用setsid就会失败,只有fork出来的子进程能够保证什么时候都不会是组长
c. 直接 setsid ():你的进程会成为 "新会话的首进程",若代码中误操作打开/dev/tty(比如日志输出到终端)这个设备不是dev/null,(如果是首进程打开时内核会强制分配一个终端,如果不是首进程会打开失败)内核会让该进程重新关联终端(违背守护进程 "脱离终端" 的核心诉求);
总结:两个fork能够规避所有情况, 第一次 fork+setsid () 让子进程成为会话首进程,第二次 fork () 让孙子进程成为 "非会话首进程"------ 即使打开/dev/tty,也不会关联终端,彻底杜绝风险。(第一次fork是防止组长,第二次fork是防止成为会话首进程)
一般来说生成环境是两次fork,当然如果你能保证代码不关联dev设备你也可以一次
第三步守护进程是脱离终端的,关闭或者重定向以前进程默认打开的文件
第四步可选:进程执行路径发送改变

总结:本次编写我们使用两次fork+重定向
cpp
#include <iostream>
#include <signal.h>
#include <sys/types.h>
#include <unistd.h>
#include <errno.h>
#include <cstring>
#include <sys/stat.h>
#include <fcntl.h>
// 编写成一个函数?或者类进行管理(但好像也不需要管理啥?后面可以自己改)
#define DEV "/dev/null"
void daemon(const char*path=nullptr)
{
// 第一步屏蔽信号
signal(SIGHUP, SIG_IGN); // 忽略SIGHUP信号
signal(SIGPIPE, SIG_IGN); // 忽略SIGPIPE信号
// 第二步,创建子进程
pid_t pid = fork();
if (pid < 0){
std::cout << "fork error:" << errno << strerror(errno) << std::endl;
exit(1); // 退出
}
if (pid > 0){
// 此时是父进程,直接关掉
exit(0);
}
// 走到这里绝对是创建出来的子进程
if (setsid() < 0)
{
// 创建失败
std::cout << "setsid error:" << errno << strerror(errno) << std::endl;
exit(1);
}
// 这里创建成功,我们选择两次次fork
pid = fork();
if(pid<0){
std::cout << "fork error:" << errno << strerror(errno) << std::endl;
}
if(pid>0){
// 父进程直接退出
exit(0);
}
//这里绝对不是首进程,避免终端tty的影响
// 第三步把关联的文件描述符关闭
int fd = open(DEV, O_RDWR);
if(fd>=0){
//打开成功,重定向到这个设备
dup2(fd, 0);//先关闭0,然后让0指向fd对应的设备
dup2(fd, 1);
dup2(fd, 2);
close(fd);
}
else{
//打开失败,直接关掉
close(0);
close(1);
close(2);
}
if(path){
//要求修改路径
chdir(path);
}
}使用ps可以查询进程相关信息

可以看到本次守护进程时第一条,第二条是我们执行ps这条命令
第一条中它的ppid是1,说明是孤儿进程,已经被内核接管了,PID和PGID不是同一个说明不是组长,并且终端没有打印消息,说明以后台守护进程一直再运行,TTY是?已经说明是脱离终端了


重定向到当前文件下,然后查看当前文件是否有helloworld

没问题直接重定向过去了
总结
辨析shell、ssh、bash呢???
Shell 是「操作系统的命令解释器总称」,Bash 是 Shell 的一种(最常用),SSH 是「远程通信协议 / 工具」,它依赖 Bash/Shell 完成远程命令的解析和执行。
如果你在云服务器本地直接敲命令,那就是由bash直接执行你的命令,解析你的命令
如果你是远端,那就是通过SSH协议加密后传输到远端,远端解析后给bash执行
Shell 是 "人机交互的命令解释器抽象层",Bash 是它最常用的具体实现;SSH 是 "加密的远程通信工具",它通过调用远程服务器的 Bash/Shell,把 "本地输入的命令" 转化为 "远程内核的执行动作"。
为什么bash需要创建子进程去执行命令呢???
Bash 作为「命令解释器」,需要保证自身 "不被替换、不退出、能持续接收新命令"------ 如果 Bash 直接执行命令(用 exec 替换自身),执行完命令后 Bash 就会消失,无法继续交互;而 fork 子进程执行命令,既能完成命令执行,又能保留 Bash 主进程的 "控制权"。
如果直接exec替身,每个命令的执行可能修改「工作目录、环境变量、文件描述符」等,如果 Bash 直接执行,这些修改会污染自身
- Bash 是 "公司老板",外部命令是 "员工"------ 老板不会自己去干活(否则公司没人管),而是派员工(子进程)去干,干完后员工离职,老板继续管公司;
- 内置命令是 "老板自己的事"(如调整公司地址、制定规则)------ 必须老板自己做,交给员工做没用。
至此关于shell的所有认知我们进行了重构,后续的学习会更加清晰
sshd 本身就是典型的守护进程,其运行机制与我们手动开发的守护进程一致 ------ 脱离终端、后台长期运行、由 PID=1 进程接管