纯手打,代码整理中,持续更新中^-^
序号延用总结九
目录
[17.1 决策树的结构](#17.1 决策树的结构)
[17.2 决策树的工作原理](#17.2 决策树的工作原理)
[17.3 数学公式:信息增益与基尼系数](#17.3 数学公式:信息增益与基尼系数)
[1,信息增益(Information Gain)](#1,信息增益(Information Gain))
[2,基尼系数(Gini Impurity)](#2,基尼系数(Gini Impurity))
[17.4 具体示例](#17.4 具体示例)
[1. 计算数据集的熵](#1. 计算数据集的熵)
[2. 计算信息增益](#2. 计算信息增益)
[17.5 鸢尾花数据集的代码示例](#17.5 鸢尾花数据集的代码示例)
[17.6 详细参数说明](#17.6 详细参数说明)
17、决策树
决策树(Decision Tree)是一种常见的监督 学习算法,用于分类和回归任务。在分类任务中,决策树通
过一系列的"决策"来判断一个样本属于哪个类别。其工作原理就像一棵树,树的每个节点表示一个"决
策",树的叶子节点则代表最终的类别标签。
决策树的目标是通过分裂数据来尽可能纯净地划分不同的类别。
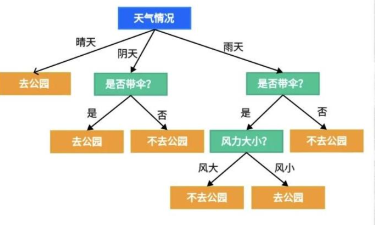
17.1 决策树 的结构
决策树由根节点、分支节点和叶子节点组成:
-
根节点:表示整个数据集,包含所有样本。
-
分支节点:表示特征的决策(如:是/否,真/假等)。
-
叶子节点:表示最终的类别或预测值。
17.2 决策树 的工作原理
决策树通过逐层分裂数据,每次选择最能"区分"不同类别的特征来进行分割。它会依据某些准则(如信
息增益、基尼系数等)选择最佳的分割特征。
-
选择最优特征:每次选择一个特征进行划分,目标是使得每一小组的类别尽可能单一(纯度高)。
-
递归 分裂:对每个子集递归地进行上述操作,直到满足停止条件(如树的深度限制、最小样本数限
制等)。
- 生成 树结构:最终,树的每个叶子节点代表一个类别。
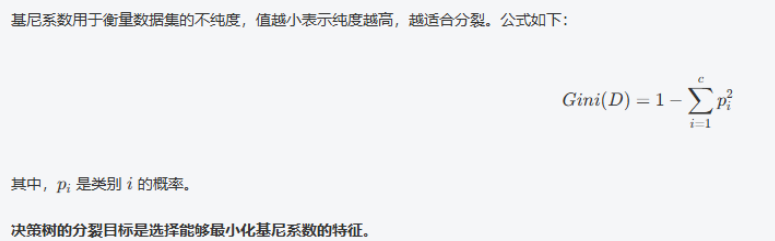
17.3 数学公式:信息增益与基尼系数
1,信息增益(Information Gain)

2,基尼系数(Gini Impurity)
决策树 的分裂过程(以信息增益为例)
假设我们有一个包含两个特征 A 和 B 的数据集,目标是根据这两个特征预测目标类别 C。
-
计算数据集的 熵: 首先计算整个数据集的熵(即目标类别的不确定性)。
-
计算每个特征的条件熵: 对于每个特征(如 A 和 B),计算将数据集按特征值划分后的子集的
熵,并加权计算出该特征的条件熵。
-
计算信息增益: 信息增益是原始数据集的熵减去条件熵。选择信息增益最大的特征进行划分。
-
递归 分裂: 对分裂后的每个子集重复上述步骤,直到所有子集的类别纯度足够高(或达到预设的
停止条件)。
17.4 具体示例
假设我们有以下数据集:
|----|----|----|----|----------|
| 天气 | 温度 | 湿度 | 风速 | 类别(是否打球) |
| 晴 | 热 | 高 | 高 | 否 |
| 晴 | 热 | 高 | 低 | 否 |
| 阴 | 热 | 高 | 高 | 是 |
| 雨 | 温暖 | 高 | 高 | 是 |
| 雨 | 温暖 | 高 | 低 | 是 |
| 雨 | 凉爽 | 中 | 高 | 否 |
| 阴 | 凉爽 | 中 | 低 | 是 |
任务说明
我们要预测 "是否能打球"(目标变量)。
决策树算法会依次考察每个特征(天气、温度、湿度、风速)的信息增益,选择信息增益最大的特征进行分裂。
1. 计算数据集的熵
假设类别"是否打球"的分布为:3 个"是",4 个"否"。
熵公式如下:
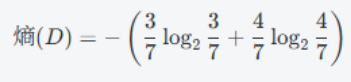
计算结果为:0.98
注:该值为数据集的总不确定性,越接近 1 表示越不确定。
2. 计算信息增益
假设我们选择"天气"作为第一个特征进行划分。
天气有三个取值:晴、阴、雨,分别对应不同的子集。
我们需要:
-
计算每个子集的熵;
-
对其加权求和(权重为子集大小占总数的比例);
-
用原熵减去加权熵,得到"天气"特征的信息增益。
然后,选择信息增益最大的特征进行分裂,如此递归下去。
17.5 鸢尾花数据集的代码示例
python
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 1, 加载数据
iris = load_iris()
x = iris.data # 特征矩阵(150个样本,4个特征:萼长、萼宽、瓣长、瓣宽)
y = iris.target # 特征值 目标向量(3类鸢尾花:0, 1, 2)
# 2, 数据预处理
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2) # 划分训练集和测试集
# 3, 创建和训练KNN模型
dtc = DecisionTreeClassifier() # 创建决策树分类器
dtc.fit(X_train, y_train) # 训练模型
# 4, 进行预测并评估模型
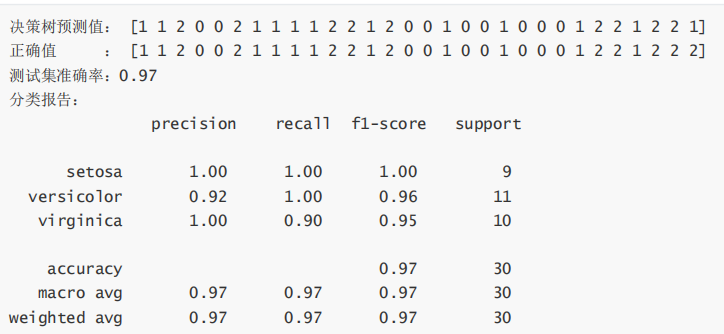
y_pred = dtc.predict(X_test) # 在测试集上进行预测
print('决策树预测值: ', y_pred)
print('正确值 : ', y_test)
accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print(f'测试集准确率: {accuracy:.2f}')
print('分类报告: \n', classification_report(y_test, y_pred, target_names=iris.target_names))运行结果:
17.6 详细参数说明
DecisionTreeClassifier 是 scikit-learn 中用于分类任务的决策树模型,它的构造方法
( init )有多个参数,可以通过这些参数来控制决策树的训练过程和模型复杂度。
DecisionTreeClassifier 构造方法的参数详解:
python
class sklearn.tree.DecisionTreeClassifier(
criterion='gini',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0,
splitter='best'
)1.criterion 决定用于选择分裂的质量衡量标准 默认值为 gini 基尼系数,可选 entropy 信息增益
2.splitter 控制每个节点如何选择用于分裂的特征,可选best或者random
3.max_depth 决策树的最大深度,避免模型过拟合,大深度可能是过拟合。
4.min_sample_split(默认值2)防止树的过度生长,如果一个节点的样本数小于该值,就不再继续分裂
5.min_samples_leaf (默认值:1 )可以控制树的复杂度。较大的值会使得叶子节点包含更多样本,有助于防止过拟合。
6.min_weight_fraction_leaf (默认值: 0.0 )可以防止训练数据集中某些特定样本的过度影响。一般在样本权重不均时使用。
其他略不太重要。。。
17.7 决策树 可视化
结合matplotlib实现决策树可视化,这样更直观,方便直观的看到具体算法数据。
先安装下matplotlib库以及jupyter库:
python
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
python
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple新建DecisionTreeClassifierTest.ipynb文件。
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 1, 加载数据
iris = load_iris()
x = iris.data # 特征矩阵(150个样本,4个特征:萼长、萼宽、瓣长、瓣宽)
y = iris.target # 特征值 目标向量(3类鸢尾花:0, 1, 2)
# 2, 数据预处理
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2) # 划分训练集和测试集
# 3, 创建和训练KNN模型
dtc = DecisionTreeClassifier() # 创建决策树分类器
dtc.fit(X_train, y_train) # 训练模型
import matplotlib
from sklearn.tree import plot_tree
from matplotlib import pyplot as plt
# 设置matplotlib使用黑体显示中文
matplotlib.rcParams['font.family'] = 'Microsoft YaHei'
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(
dtc,
filled=True,
feature_names=iris.feature_names,
class_names=iris.target_names,
rounded=True
)
plt.title("决策树可视化")
plt.show()运行结果
