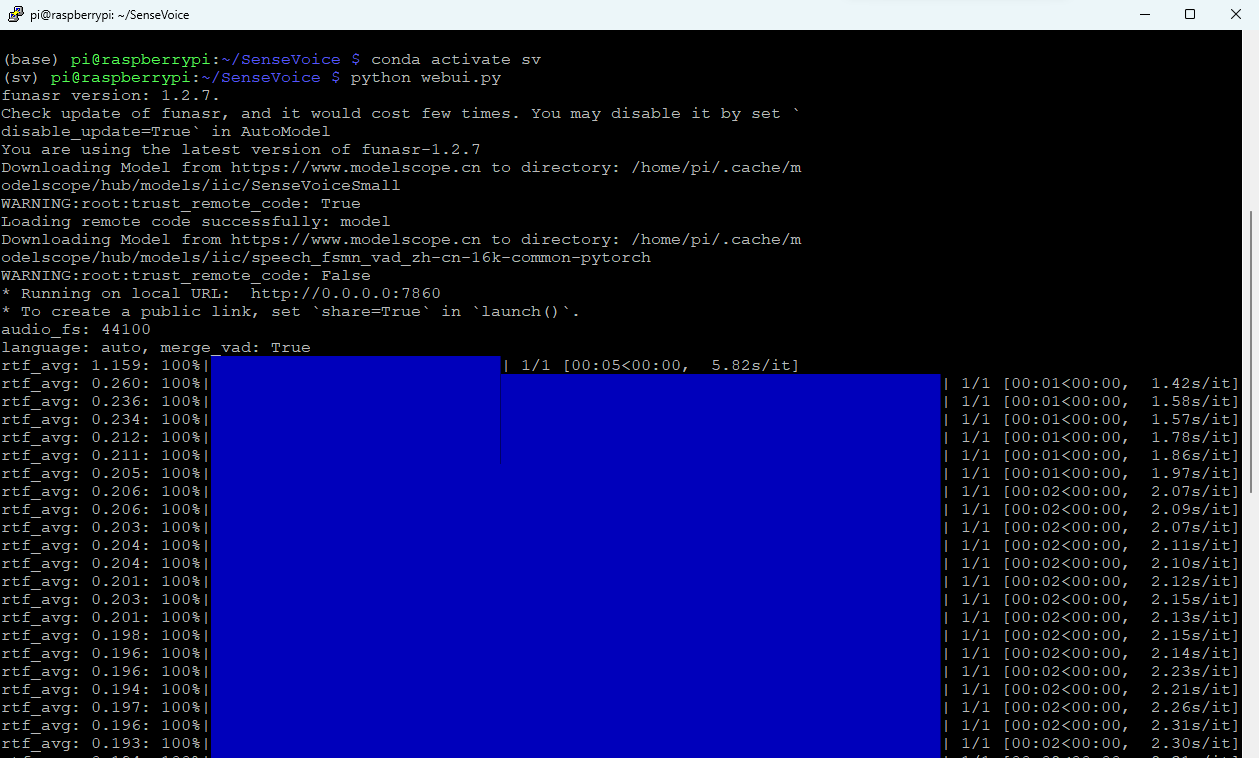
首先声明,树莓派上跑这个项目仅是演示其可行性,性能上别太较真。实测10分钟的英语MP3,从开始识别到出结果返回到UI上大约需要2分钟。作为对比,同样的文件在我PC上用了不到30秒。
SenseVoice的一些操作依赖于ffmpeg,因此需要先sudo apt install ffmpeg。使用最新版的Raspberry OS应该已经自带了。
我是使用Anaconda维护python环境的。树莓派下可以先把Anaconda装了:
bash
cd
wget https://repo.anaconda.com/archive/Anaconda3-2025.12-1-Linux-aarch64.sh
sh Anaconda3-2025.12-1-Linux-aarch64.sh一路yes,除非默认no。(当然全部打yes也不是不可以,只是每次重启后默认都会进conda环境)
启动conda环境:
bash
source ~/anaconda3/bin/activate创建名为sv的虚拟环境并安装SenseVoice:
bash
conda create -n sv python=3.10 -y
conda activate sv
git clone https://github.com/FunAudioLLM/SenseVoice.git
cd SenseVoice
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
#如果在有N卡的PC上装(以CUDA 12.4 为例),
pip install -r requirements.txt \
-i https://pypi.tuna.tsinghua.edu.cn/simple \
--extra-index-url https://download.pytorch.org/whl/cu124成功装完后运行很简单:python webui.py 即可。第一次运行时会继续下载一些必备的组件和模型。
但这样只能在树莓派本机上开浏览器操作。如果想在别的PC上访问这个树莓派,可以在启动webui前先修改一下webui.py。打开webui.py,找到快结束的地方的"demo.launch()",修改为:
demo.launch(server_name="0.0.0.0",server_port=7860)
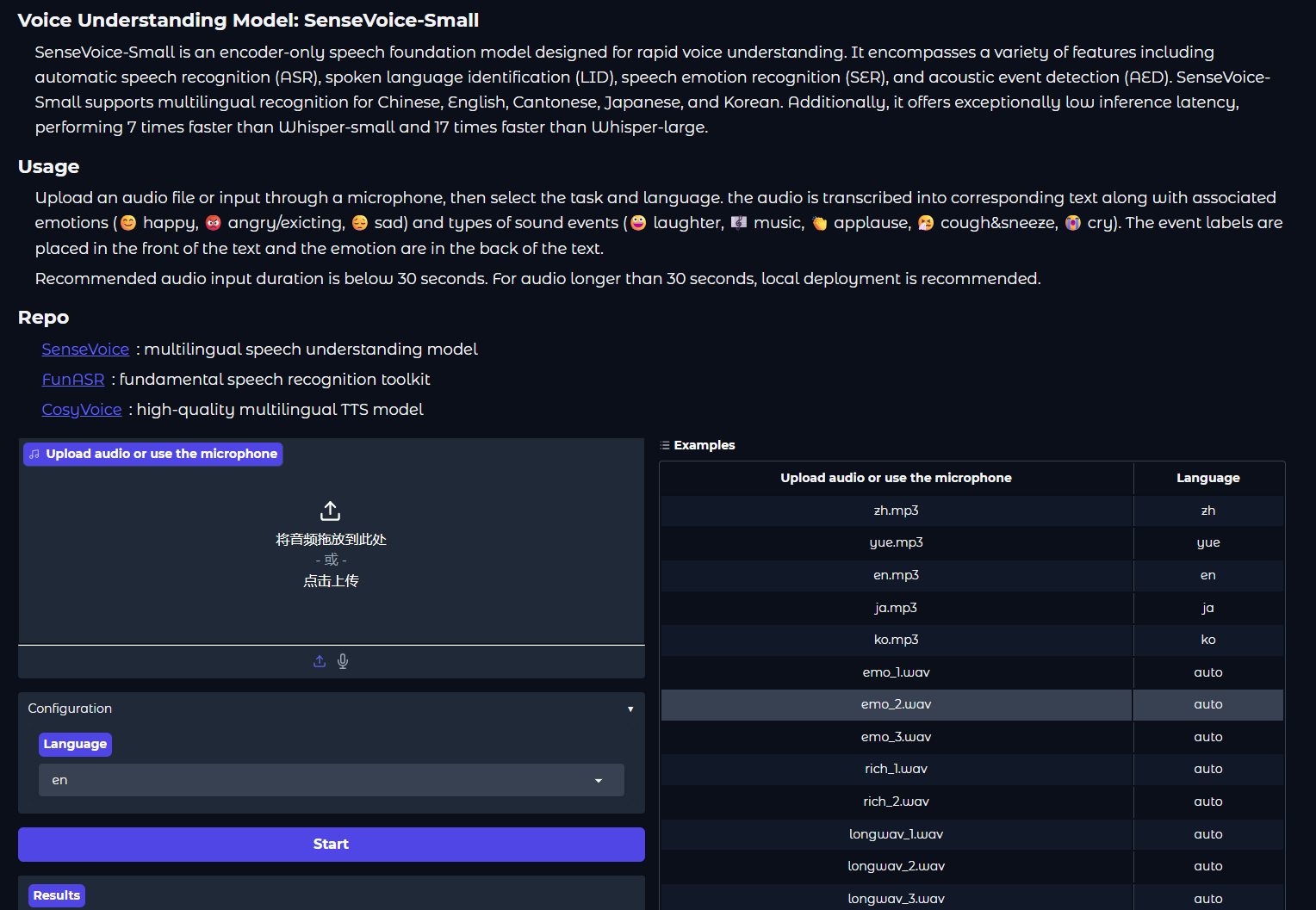
这样就可以让任意一台IP可达的PC访问了。SenseVoice使用起来也超简单的:浏览器里输入网址(http://树莓派的IP:7860)、上传mp3文件、选择语言、按下"Start"。稍等片刻后在Result框中复制文本就行了。
后台可以监视到活动。
经测试,x86_64的windows和linux也同样支持。