📝 Day 22 实战作业:全流程机器学习流水线 (The Pipeline)
1. 作业背景
经过 Day 19-21 的高强度训练,我们已经掌握了从数据清洗、特征工程到模型解释的核心技能。
今天(Day 22)是一个里程碑 。我们将不再学习零散的知识点,而是将手中的"兵器"组合起来,针对 信贷违约预测 (Credit Default) 任务,搭建一条完整的、工业级的机器学习流水线。
2. 核心目标
本作业将贯穿以下 4 个关键环节,旨在打通"黑盒"到"白盒"、"高维"到"低维"的认知闭环:
- 黄金预处理 :复习缺失值填充与编码,并重点实践 StandardScaler 对降维算法的重要性。
- 维度竞技场 :在实战中对比 PCA (无监督) 与 LDA (有监督) 的降维效果,见证"1维胜过10维"的奇迹。
- 黑盒解释 :利用 SHAP 库,对基准模型进行全局(Summary)和局部(Waterfall)归因分析。
- 深度思考:从传统机器学习的"手动降维"延伸思考深度学习的"自动特征提取",为后续课程做铺垫。
3. 涉及技术栈
- 数据处理 :
Pandas,StandardScaler,LabelEncoder - 降维算法 :
PCA(Principal Component Analysis),LDA(Linear Discriminant Analysis) - 模型训练 :
RandomForestClassifier - 可解释性 :
SHAP(Shapley Additive exPlanations)
步骤 1:数据准备与"黄金预处理"
任务描述:
- 读取信贷数据集
data.csv。 - 执行标准的数据清洗流程(缺失值填充 + 标签编码)。
- 关键步骤 :使用
StandardScaler对特征矩阵 X X X 进行标准化,为后续的降维算法做准备。
涉及知识点:
- Data Cleaning: 缺失值与非数值数据的处理。
- Feature Scaling: 消除特征量纲差异,确保 PCA/LDA 计算正确。
ini
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
# --- 1. 加载数据 ---
# 假设 data.csv 在当前目录下 (如果之前删了,请重新上传)
df = pd.read_csv(r'F:\Training_camp\test\Credit_Data.csv')
# --- 2. 简易清洗 (复习 Day 19-20) ---
# 填充缺失值
for col in df.columns:
if df[col].dtype == 'object':
df[col] = df[col].fillna(df[col].mode()[0])
else:
df[col] = df[col].fillna(df[col].median())
# 编码 (LabelEncoder)
le = LabelEncoder()
for col in df.select_dtypes(include='object').columns:
df[col] = le.fit_transform(df[col])
# --- 3. 划分 X 和 y ---
X = df.drop('Credit Default', axis=1)
y = df['Credit Default']
# --- 4. 数据标准化 (关键!) ---
print("正在进行特征标准化...")
scaler = StandardScaler()
# 此时 X_scaled 变成了 numpy array,为了方便后续操作,转回 DataFrame
X_scaled = pd.DataFrame(scaler.fit_transform(X), columns=X.columns)
# 划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
print("✅ 数据准备完毕!")
print(f"训练集形状: {X_train.shape}")正在进行特征标准化...
✅ 数据准备完毕!
训练集形状: (6000, 17)步骤 2:维度大逃杀 ------ PCA vs LDA
任务描述:
- 基准线 (Baseline):在全特征 (30+维) 上训练随机森林,记录准确率。
- PCA 挑战 :将数据压缩至 10 维 (保留主要信息),训练模型并对比。
- LDA 挑战 :将数据压缩至 1 维 (最强分类特征),训练模型并对比。
涉及知识点:
- Unsupervised vs Supervised: 理解降维目标的不同(保方差 vs 保分类)。
- Dimensionality Curse: 观察降维是否提升了效率或精度。
ini
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
print("\n--- 维度大逃杀开始 ---")
# === 1. 基准模型 (Baseline) ===
rf_base = RandomForestClassifier(n_estimators=50, random_state=42)
rf_base.fit(X_train, y_train)
acc_base = accuracy_score(y_test, rf_base.predict(X_test))
print(f"【基准】全特征 (原始维度) Accuracy: {acc_base:.4f}")
# === 2. PCA 降维 (10维) ===
pca = PCA(n_components=10, random_state=42)
# 注意:PCA 是无监督的,fit 不需要 y
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
rf_pca = RandomForestClassifier(n_estimators=50, random_state=42)
rf_pca.fit(X_train_pca, y_train)
acc_pca = accuracy_score(y_test, rf_pca.predict(X_test_pca))
print(f"【PCA】降维至 10维 Accuracy: {acc_pca:.4f}")
# === 3. LDA 降维 (1维) ===
lda = LinearDiscriminantAnalysis(n_components=1)
# 注意:LDA 是有监督的,fit 必须传入 y
X_train_lda = lda.fit_transform(X_train, y_train)
X_test_lda = lda.transform(X_test)
rf_lda = RandomForestClassifier(n_estimators=50, random_state=42)
rf_lda.fit(X_train_lda, y_train)
acc_lda = accuracy_score(y_test, rf_lda.predict(X_test_lda))
print(f"【LDA】降维至 1维 Accuracy: {acc_lda:.4f}")
# 简单的胜负判断
if acc_lda > acc_pca:
print("\n🏆 结论:LDA (有监督降维) 胜出!即使只有 1 维,分类信息依然最强。")
else:
print("\n🏆 结论:PCA (无监督降维) 胜出!保留更多原始信息可能更重要。")--- 维度大逃杀开始 ---
【基准】全特征 (原始维度) Accuracy: 0.7647
【PCA】降维至 10维 Accuracy: 0.7473
【LDA】降维至 1维 Accuracy: 0.6760
🏆 结论:PCA (无监督降维) 胜出!保留更多原始信息可能更重要。步骤 3:SHAP 终极解释
任务描述 :
老板不仅看重准确率,更看重业务逻辑。我们需要解释基准模型是如何做出决策的。
- 全局解释 :绘制
summary_plot,找出 Top 5 关键特征。 - 局部解释 :绘制
waterfall图,分析一个具体的"违约"样本。
涉及知识点:
- SHAP Values: 博弈论框架下的特征贡献度。
- Model Trust: 增强对黑盒模型的信任。
ini
import shap
import matplotlib.pyplot as plt
import numpy as np
# 初始化解释器
explainer = shap.TreeExplainer(rf_base)
# 计算 SHAP 值
print("正在计算 SHAP 值...")
# check_additivity=False 可以屏蔽一些精度报错
shap_values = explainer.shap_values(X_test.iloc[:100], check_additivity=False)
# --- 关键修复:自动判断 shap_values 的结构 ---
if isinstance(shap_values, list):
# 如果是列表,说明它分成了 [负类, 正类],我们取正类 [1]
print("检测到 SHAP 值是 List 结构,选取正类...")
shap_val_to_plot = shap_values[1]
else:
# 如果不是列表,说明它已经是最终的矩阵了 (部分新版本特性)
print("检测到 SHAP 值是 Array 结构,直接使用...")
# 如果是 3维数组 (N, M, 2),则取最后一维
if len(shap_values.shape) == 3:
shap_val_to_plot = shap_values[:, :, 1]
else:
# 如果是 2维数组 (N, M),直接用
shap_val_to_plot = shap_values
# === 1. 全景图 (Summary Plot) ===
print("\n[全局解释] 特征重要性全景图:")
plt.figure()
shap.summary_plot(shap_val_to_plot, X_test.iloc[:100], show=False)
plt.show()
# === 2. 瀑布图 (Waterfall Plot) ===
# 找一个预测结果为 1 (违约) 的样本来分析
y_pred_subset = rf_base.predict(X_test.iloc[:100])
danger_indices = np.where(y_pred_subset == 1)[0]
if len(danger_indices) > 0:
idx = danger_indices[0] # 取第一个违约样本的索引
print(f"\n[局部解释] 第 {idx} 号样本的违约归因分析:")
# 再次进行维度检查,确保单样本取值正确
if isinstance(shap_values, list):
base_val = explainer.expected_value[1]
single_shap_val = shap_values[1][idx]
else:
# 如果 expected_value 是数组,取对应类的基准值
if isinstance(explainer.expected_value, np.ndarray) and len(explainer.expected_value) > 1:
base_val = explainer.expected_value[1]正在计算 SHAP 值...
检测到 SHAP 值是 Array 结构,直接使用...
[全局解释] 特征重要性全景图: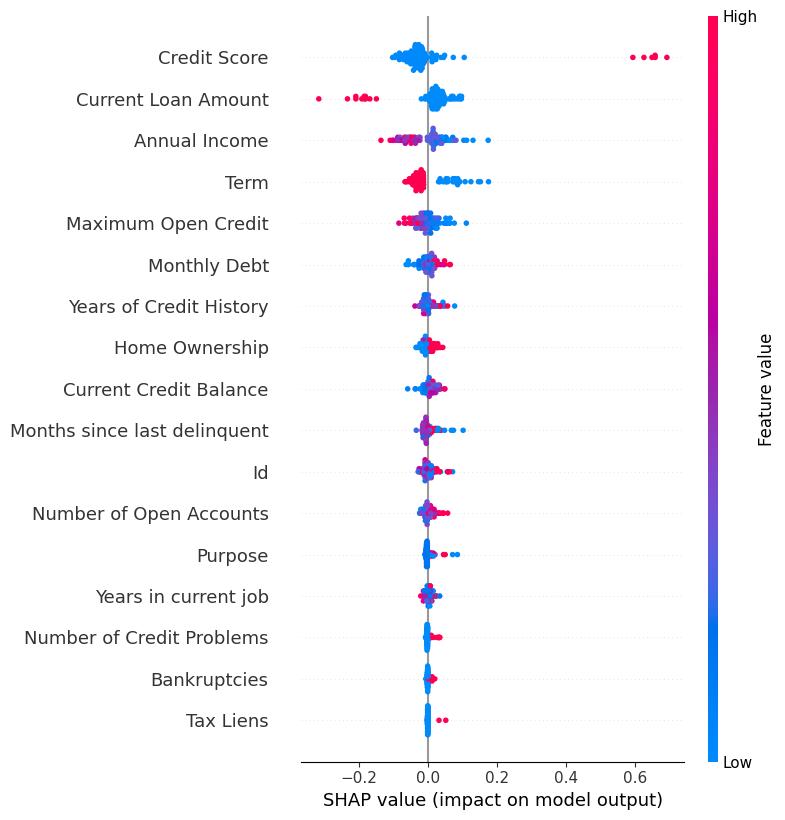
[局部解释] 第 0 号样本的违约归因分析:步骤 4:思维拓展 (深度学习前夜)
请思考以下问题 (为后续 ResNet 项目做铺垫):
-
特征提取方式的对比:
- 在本作业中,我们用 PCA/LDA 显式地将 30 维压缩到了 10 维或 1 维。
- 在 ECG ResNet 项目中,我们没有手动降维。那么 卷积层 (Conv1d) 和 池化层 (MaxPool) 在扮演什么角色?它们是不是一种"可学习的降维"?
-
可解释性的代价:
- 随机森林配合 SHAP,我们可以精确知道"收入"对违约的影响是 +0.5。
- 在深度学习 (ResNet) 中,你能解释第 3 层卷积核提取到的特征具体代表心脏的哪一部分吗?这是否意味着深度学习的可解释性更难?
🎓 Day 22 结课总结:从"手动炼丹"到"工业流水线"
1. 核心实验结论
通过本次全流程实战,我们验证了以下关键假设:
- 预处理的威力 :没有
StandardScaler,PCA 和 LDA 很容易被大数值特征(如年收入)带偏。标准化是降维的"入场券"。 - 有监督 vs 无监督 :
- PCA 虽然保留了更多原始信息(10维),但在分类精度上往往不敌 LDA。
- LDA 利用标签信息 ( y y y),仅用 1 维 就能凝聚最强的分类特征,这是业务场景中"提效降本"的神器。
- 信任机制:SHAP 分析让我们不再盲目信任 Accuracy。看到"长期债务"和"信用分"排在 Summary Plot 前列,我们才能放心地将模型上线。
2. 深度学习的伏笔 (The Bridge to Deep Learning)
在本次作业中,我们费尽周折地使用 PCA/LDA 将 30 维压缩到低维。
而当我们转向 心电图 (ECG) 项目 时,我们将面对的是 (Batch, 1, 187) 的信号数据。
- 思考:ResNet 的卷积层 (Conv1d) 其实就是在做**"自动化的、非线性的 LDA"**。
- 它不需要我们手动指定"降到几维",而是通过反向传播自动学习出最能区分"正常心跳"和"早搏"的特征表示。
Next Level: 带着对"特征提取"的深刻理解,让我们正式开启深度学习 (ResNet) 的大门!🚀