文章目录
- 前言
- 一、Blackbox_exporter介绍
-
- [1.1 Blackbox_exporter介绍](#1.1 Blackbox_exporter介绍)
- [1.2 整体构建思路](#1.2 整体构建思路)
- 二、项目搭建过程
-
- [2.1 搭建Prometheus](#2.1 搭建Prometheus)
- [2.2 搭建Blackbox_exporter](#2.2 搭建Blackbox_exporter)
- [2.3 Prometheus完成数据存储](#2.3 Prometheus完成数据存储)
- [2.4 对接夜莺监控系统](#2.4 对接夜莺监控系统)
- 三、核心监控数据
-
- [3.1 核心监控指标](#3.1 核心监控指标)
- [3.2 网络时延与性能指标](#3.2 网络时延与性能指标)
- [3.3 补充指标](#3.3 补充指标)
前言
我们公司的服务器都部署在同一个IDC机房。由于物联网设备在绑定时只认单一IP地址,因此我们通过"内网IP+端口"映射到同一公网IP端口的方式,实现服务的对外访问。然而有一天,公司网络突然出现异常,导致物联网设备无法将数据上报至服务,造成服务整体中断。故障持续约半小时,期间出现了两次。我作为运维人员,在接到通知后第一时间进行排查,却发现所有服务器都已无法连接,这基本坐实了是网络层出了问题。
尽管问题的根源不在运维层面,而在于网络线路不稳定,但我并非在故障发生瞬间就察觉到的。为了在未来类似情况中能第一时间定位问题、并准确通知相关团队处理,我决定引入黑盒监控的思路。采用了 Blackbox Exporter 作为探测工具,并结合一台位于云端的高稳定性服务器,对关键服务进行持续性探测(之前大学期间写过一个类似的探测工具,但实现下来发现成熟稳定的 Blackbox Exporter哈哈哈哈有点冒昧了)。
一、Blackbox_exporter介绍

1.1 Blackbox_exporter介绍
Blackbox-exporter是Prometheus官方提供的一个黑盒监控解决方案,可以通过HTTP、HTTPS、DNS、ICMP、TCP和gRPC方式对目标实例进行检测。可用于以下使用场景:
-
HTTP/HTTPS:URL/API可用性检测
-
ICMP:主机存活检测
-
TCP:端口存活检测
-
DNS:域名解析
黑盒监控与白盒监控:
黑盒监控是业务可用性的守门员,我们无需关心服务内部如何实现,只需像真实用户一样验证其关键功能是否正常。这通常体现为使用自动化工具定期探测核心服务的端口状态、HTTP接口的返回状态码、响应时间以及SSL证书有效性等。
它的核心价值在于快速回答服务"通不通"和"快不快"的问题,能够在用户受到影响前发现网络中断、服务宕机或性能劣化等宏观故障,是一种面向现象的监控方式。
白盒监控则要求我们打开"盒子",基于系统内部暴露的指标、日志和链路追踪数据进行深度检查。当黑盒监控告警或指标数据提示系统存在潜在问题时,白盒监控能引导您定位根因。
1.2 整体构建思路
计划采用:Prometheus+Blackbox_exporter+夜莺告警系统+云服务器。
Prometheus:专职数据采集与存储
职责 :作为监控体系的核心底座,主动通过Pull模式 从部署在各个目标机器上的Exporter拉取(Scrape)监控指标数据,并存储在其内置的高效时序数据库中。
关键点在于它负责的是数据的"收"和"存",保证监控数据的完整性和可查询性。
Blackbox Exporter :外部探测执行器的角色。
它专精于黑盒监控 ,即从外部用户视角,模拟真实请求来探测目标服务(如HTTP/HTTPS页面、TCP端口、ICMP等)的可用性与性能,但并不关心目标服务内部的运行状态(如CPU使用率等,那属于白盒监控范畴)。其核心价值在于,当您的服务器因网络问题全部失联时,部署在稳定的云服务器上的Blackbox Exporter依然能从外部网络探测您的服务公网入口,从而快速定位故障域是否为机房外部网络。
夜莺:专注数据应用与告警管理
职责 :作为监控系统的"大脑",它不直接接收采集器的数据 ,而是将已有的Prometheus实例配置为一个数据源 。它通过Prometheus的API查询数据,进而实现统一可视化 提供强大的监控大盘和数据分析界面。 强大的告警管理,这是相比直接使用Prometheus的Alertmanager的一大优势。夜莺提供了基于Web UI的、功能丰富的告警规则管理、告警收敛、屏蔽、订阅、自愈等一系列企业级告警功能。
二、项目搭建过程
2.1 搭建Prometheus
bash
mv prometheus-3.5.0.linux-amd64/ prometheus
cd prometheus/
htpasswd -nBC 12 'password' | tr -d ':\n'
# 根据密码生成字符串
vim web-config.yml
basic_auth_users:
admin: # 根据密码生成字符串编写启动脚本,并启动Prometheus:
bash
vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus Monitoring
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=root
Group=root
# 工作目录
WorkingDirectory=/data/prometheus
# 启动命令
ExecStart=/data/prometheus/prometheus \
--config.file=/data/prometheus/prometheus.yml \
--storage.tsdb.path=/data/prometheus/data \
--web.config.file=/data/prometheus/web-config.yml \
--web.console.templates=/data/prometheus/consoles \
--web.console.libraries=/data/prometheus/console_libraries \
--web.enable-lifecycle #开启热加载
Restart=on-failure
RestartSec=5s
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start prometheus 为了可以动态加载配置,所以开启了web.enable-lifecycle参数,这样就可以用下面的命令进行动态加载了,无需重启Prometheus:
bash
# 热加载命令
curl -u "admin:password" -X POST http://192.168.16.2:9090/-/reload在web访问http://127.0.0.1:9090/即可查看Prometheus前端。
2.2 搭建Blackbox_exporter
bash
# 解压并进入服务目录
root@instance-wc5p3ngj:/data/prometheus/blackbox_exporter# ls
LICENSE NOTICE blackbox.yml blackbox_exporter
# 使用默认配置文件进行启动
vim /etc/systemd/system/blackbox_exporter.service
[Unit]
Description=Blackbox Exporter
Documentation=https://github.com/prometheus/blackbox_exporter
Wants=network-online.target
After=network-online.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/data/prometheus/blackbox_exporter/blackbox_exporter \
--config.file=/data/prometheus/blackbox_exporter/blackbox.yml
Restart=on-failure
RestartSec=5s
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start blackbox_exporter.service
netstat -lnpt | grep 91152.3 Prometheus完成数据存储
编写Prometheus配置文件:
bash
vim /data/prometheus/prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
# 对接Prometheus
- job_name: "prometheus"
basic_auth:
username: 'admin'
password: 'password'
static_configs:
- targets: ["192.168.16.2:9090"]
labels:
app: "prometheus"
- job_name: "blackbox_net_check"
metrics_path: /probe
params:
module: [http_2xx]
scrape_interval: 30s
scrape_timeout: 25s
static_configs:
- targets:
- https://www.baidu.com
labels:
env: "prod"
service: "web-test"
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- source_labels: [__param_target]
target_label: target
- target_label: __address__
replacement: 192.168.16.2:9115配置文件解读:
| 字段 | 含义 | 你的配置说明 |
|---|---|---|
job_name |
采集任务标识 | 标识为 "blackbox_net_check",查询时job="blackbox_net_check"筛选黑盒探测指标 |
metrics_path |
要拉取指标的路径(默认是/metrics,黑盒需改为/probe) |
访问 Blackbox_exporter 的/probe接口触发探测,而非默认的/metrics |
params |
访问metrics_path时携带的 URL 参数 |
传module=http_2xx,指定使用 Blackbox 的http_2xx模块(检测 HTTP 2xx 响应) |
scrape_interval: 30s |
覆盖全局的采集间隔,该任务每 30 秒探测一次 | 比全局 15 秒慢,适合网络探测 |
scrape_timeout: 25s |
采集超时时间(必须小于scrape_interval) |
探测超过 25 秒则判定为超时失败,避免卡住采集任务 |
static_configs |
定义 1 组探测目标,每组带自定义标签 | 第一组:探测https://www.baidu.com,标签env=prod(生产环境)、service=Web-NetTest(网站网络测试) |
relabel_configs |
重标签规则(采集前修改标签 / 参数),核心是 "把探测目标传给 Blackbox,把采集地址指向 Blackbox" | 逐个拆解: 1. source_labels: [__address__] → target_label: __param_target:把targets里的地址(如https://www.baidu.com)作为/probe?target=xxx的参数; 2. source_labels: [__param_target] → target_label: instance:把探测目标赋值给instance标签(查询时instance显示目标地址); 3. source_labels: [__param_target] → target_label: target:新增target标签,和instance互补,更清晰识别探测对象; 4. target_label: __address__ → replacement: 192.168.16.2:9115:把采集地址改为 Blackbox_exporter 的地址。 |
使用热加载命令重新加载Prometheus完成监控对接。

2.4 对接夜莺监控系统
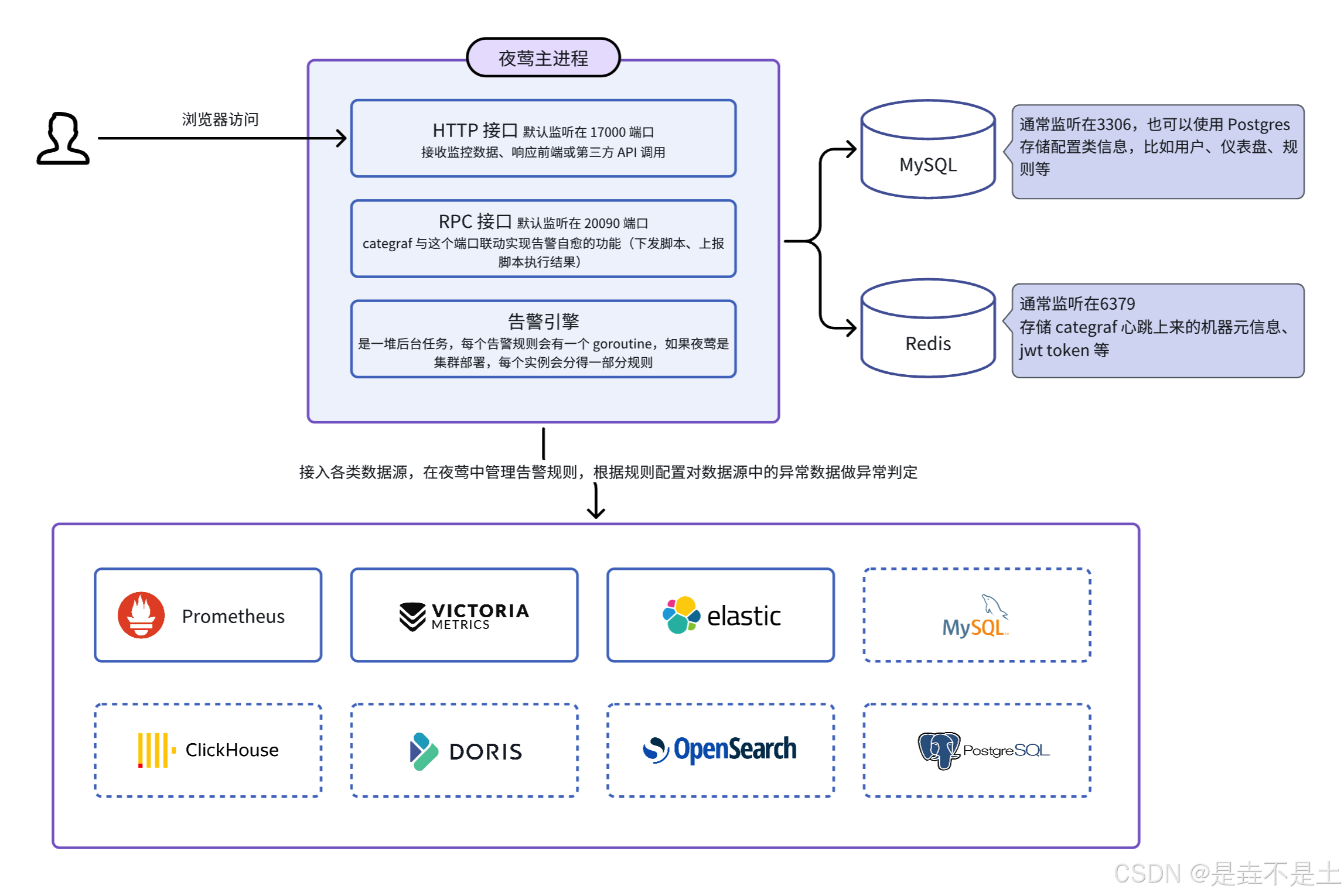
这里引入了一个夜莺官方给出的架构图,我们引入夜莺的作用也如上图所示。
Prometheus:专职数据采集与存储 职责 :作为监控体系的核心底座,主动通过Pull模式 从部署在各个目标机器上的Exporter拉取(Scrape)监控指标数据,并存储在其内置的高效时序数据库中。
关键点在于它负责的是数据的"收"和"存",保证监控数据的完整性和可查询性。
夜莺:专注数据应用与告警管理 职责 :作为监控系统的"大脑",它不直接接收采集器的数据 ,而是将已有的Prometheus实例配置为一个数据源 。它通过Prometheus的API查询数据,进而实现:
统一可视化 :提供强大的监控大盘和数据分析界面。
强大的告警管理:这是相比直接使用Prometheus的Alertmanager的一大优势。夜莺提供了基于Web UI的、功能丰富的告警规则管理、告警收敛、屏蔽、订阅、自愈等一系列企业级告警功能。
搭建流程如下:
bash
# 搭建n9e所需数据库并导入数据
sudo docker run -d \
--name mysql-n9e \
-p 3306:3306 \
-v /data/n9e/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=password \
mysql:8.0
# 导入数据库
cp n9e.sql mysql/
sudo docker exec -it mysql-n9e mysql -u root -p
# 导入数据库
source /var/lib/mysql/n9e.sql
# 启动redis
sudo docker run -d \
--name redis-n9e \
-p 6379:6379 \
-v /data/n9e/redis:/data \
redis:6.2.6 \
redis-server --appendonly yes --requirepass "password"编写n9e配置文件:
bash
mkdir /data/n9e/ && cd /data/n9e
tar -zxvf n9e-v8.4.1-linux-amd64.tar.gz -C /data/n9e
vim /data/n9e/etc/config.toml
[DB]
# mysql postgres sqlite
DBType = "mysql"
# postgres: host=%s port=%s user=%s dbname=%s password=%s sslmode=%s
# postgres: DSN="host=127.0.0.1 port=5432 user=root dbname=n9e_v6 password=1234 sslmode=disable"
# mysql: DSN="root:1234@tcp(localhost:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local"
#DSN = "n9e.db"
DSN = "root:password@tcp(127.0.0.1:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true"
# enable debug mode or not
Debug = false
# unit: s
MaxLifetime = 7200
# max open connections
MaxOpenConns = 150
# max idle connections
MaxIdleConns = 50
[Redis]
# address, ip:port or ip1:port,ip2:port for cluster and sentinel(SentinelAddrs)
Address = "127.0.0.1:6379"
# Username = ""
Password = "password"
# DB = 0
# UseTLS = false
# TLSMinVersion = "1.2"
# standalone cluster sentinel miniredis
RedisType = "miniredis"
# Mastername for sentinel type
# MasterName = "mymaster"
# SentinelUsername = ""
# SentinelPassword = ""
[[Pushgw.Writers]]
# Url = "http://127.0.0.1:8480/insert/0/prometheus/api/v1/write"
Url = "http://127.0.0.1:9090/api/v1/write"
# Basic auth username
BasicAuthUser = "admin"
# Basic auth password
BasicAuthPass = "password"
# timeout settings, unit: ms
Headers = ["X-From", "n9e"]
Timeout = 10000
DialTimeout = 3000
TLSHandshakeTimeout = 30000
ExpectContinueTimeout = 1000
IdleConnTimeout = 90000启动夜莺:
bash
vim /etc/systemd/system/n9e.service
[Unit]
Description=Nightingale Monitoring Service
After=network.target
[Service]
Type=simple
ExecStart=/data/n9e/n9e
WorkingDirectory=/data/n9e
Restart=always
RestartSec=5
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=n9e
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start n9e.service打开浏览器访问 http://localhost:17000。默认用户名是 root,默认密码是 root.2020。
至此,整个搭建工作基本完成了,接下来就是细化工作内容的部分了。
三、核心监控数据
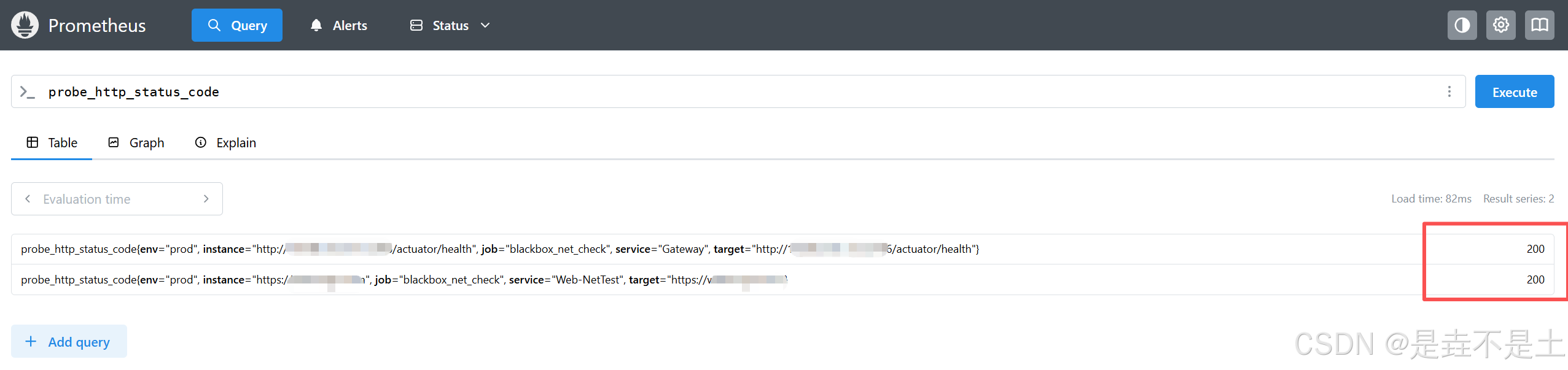
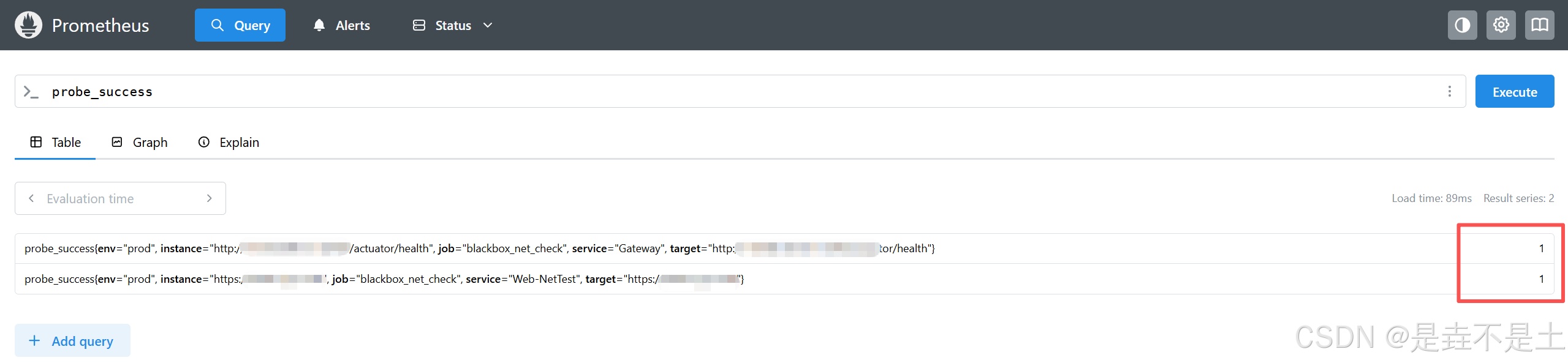
3.1 核心监控指标
判断 "网络是否通、服务是否可用" 的核心,告警优先级最高:
| 指标 | 含义 | 告警建议 |
|---|---|---|
probe_success |
探测是否成功(1 = 成功,0 = 失败) | 告警:当值 = 0 且持续 2 次(60 秒),触发 "网络 / 服务不可达" 告警 |
probe_http_status_code |
HTTP 响应状态码 | 告警:值≠200 时触发 "服务响应异常" 告警 |
3.2 网络时延与性能指标
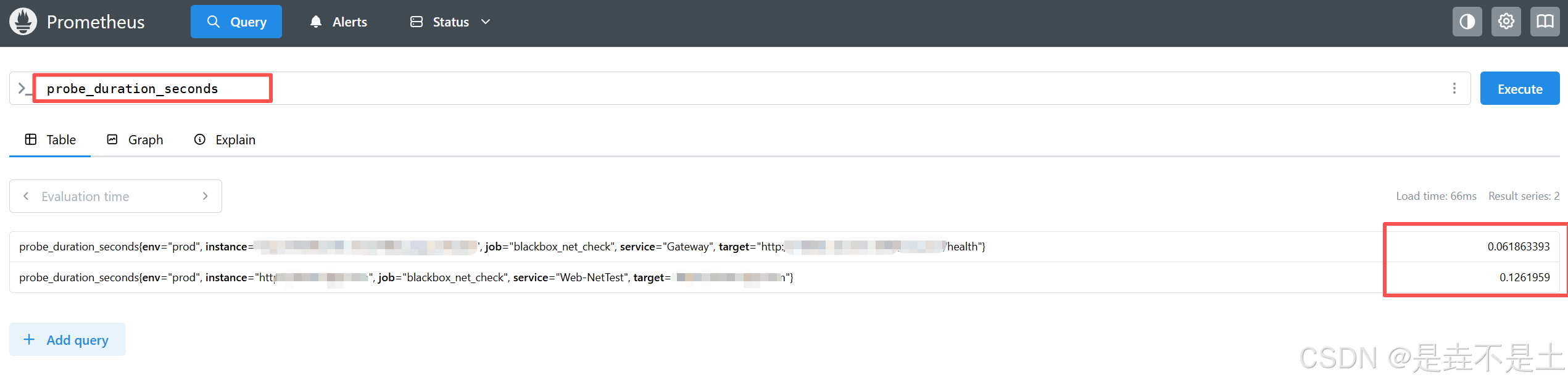
用于定位 "网络慢" 的具体环节(是 DNS、TCP 连接还是传输问题),区分 "网络故障" 和 "服务端故障":
| 指标 | 含义 | 告警建议 |
|---|---|---|
probe_duration_seconds |
探测总耗时(秒) | 告警:阈值建议(如 > 1 秒),触发 "访问总时延过高" 告警 |
probe_http_duration_seconds{phase="resolve"}(或probe_dns_lookup_time_seconds) |
DNS 解析耗时 | 告警:阈值建议(如 > 0.1 秒),触发 "DNS 解析超时 / 过慢" 告警(网关是 IP 直连,该值接近 0,属正常) |
probe_http_duration_seconds{phase="connect"} |
TCP 连接耗时 | 告警:阈值建议(如 > 0.2 秒),触发 "TCP 连接过慢(网络链路 / 端口问题)" 告警 |
probe_http_duration_seconds{phase="tls"} |
TLS 握手耗时(仅 HTTPS 目标有效) | 告警:阈值建议(如 > 0.1 秒),触发 "TLS 握手过慢(证书 / SSL 配置问题)" 告警(网关是 HTTP,该值 = 0,无需监控) |
probe_http_duration_seconds{phase="processing"} |
服务端处理耗时 | 告警:若该值占总耗时 80% 以上,触发 "服务端处理慢(非网络问题)" 告警 |
probe_http_duration_seconds{phase="transfer"} |
响应数据传输耗时 | 告警:阈值建议(如 > 0.1 秒),触发 "数据传输过慢(带宽 / 数据包过大)" 告警 |
如果使用Prometheus的监控告警的话,这里给出Prometheus+Alertmanager+PrometheusAlert方案的实现地址方式:
https://blog.csdn.net/2401_83649605/article/details/152605133?spm=1001.2014.3001.5501
参考告警规则:(github大佬的)
我的:(可以将文件直接导入夜莺,并使用夜莺的告警)
bash
groups:
- name: BlackboxExporter
rules:
# 1. 探测失败告警(减少误报,for=2m)
- alert: BlackboxProbeFailed
expr: probe_success == 0
for: 2m
labels:
severity: critical
annotations:
summary: "【{{ $labels.target }}】网络/服务不可达"
description: "探测目标 {{ $labels.target }} 连续失败,当前状态:probe_success={{ $value }}\n所属服务:{{ $labels.service }}"
# 2. HTTP状态码异常(仅监控200以外的状态码)
- alert: BlackboxProbeHttpFailure
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 1m
labels:
severity: critical
annotations:
summary: "【{{ $labels.target }}】HTTP状态码异常"
description: "目标 {{ $labels.target }} 返回状态码 {{ $value }},非预期200\n所属服务:{{ $labels.service }}"
# 3. 总探测耗时过高(全局慢)
- alert: BlackboxSlowProbe
expr: avg_over_time(probe_duration_seconds[1m]) > 1
for: 1m
labels:
severity: warning
annotations:
summary: "【{{ $labels.target }}】探测总耗时过高"
description: "目标 {{ $labels.target }} 平均探测耗时 {{ $value | humanizeDuration }},超过阈值1秒\n所属服务:{{ $labels.service }}"
# 4. 分阶段时延告警:DNS解析慢(仅非IP直连目标有效)
- alert: BlackboxDnsResolveSlow
expr: avg_over_time(probe_http_duration_seconds{phase="resolve"}[1m]) > 0.1
for: 1m
labels:
severity: warning
annotations:
summary: "【{{ $labels.target }}】DNS解析过慢"
description: "目标 {{ $labels.target }} DNS解析平均耗时 {{ $value | humanizeDuration }},超过阈值0.1秒\n所属服务:{{ $labels.service }}"
# 5. 分阶段时延告警:TCP连接慢
- alert: BlackboxTcpConnectSlow
expr: avg_over_time(probe_http_duration_seconds{phase="connect"}[1m]) > 0.2
for: 1m
labels:
severity: warning
annotations:
summary: "【{{ $labels.target }}】TCP连接过慢"
description: "目标 {{ $labels.target }} TCP连接平均耗时 {{ $value | humanizeDuration }},超过阈值0.2秒(网络链路/端口问题)\n所属服务:{{ $labels.service }}"
# 6. 分阶段时延告警:TLS握手慢(仅HTTPS目标,过滤HTTP目标)
- alert: BlackboxTlsHandshakeSlow
expr: avg_over_time(probe_http_duration_seconds{phase="tls", probe_http_ssl="1"}[1m]) > 0.1
for: 1m
labels:
severity: warning
annotations:
summary: "【{{ $labels.target }}】TLS握手过慢"
description: "目标 {{ $labels.target }} TLS握手平均耗时 {{ $value | humanizeDuration }},超过阈值0.1秒\n所属服务:{{ $labels.service }}"3.3 补充指标
用于验证网络 / 协议配置是否符合预期,兜底异常场景,可以根据自身去定义是否使用。
| 指标 | 含义 | 告警建议 |
|---|---|---|
probe_http_ssl |
是否使用 SSL(1=HTTPS,0=HTTP) | 告警:若 HTTPS 目标值 = 0/HTTP 目标值 = 1,触发 "协议类型异常" 告警 |
probe_tls_version_info{version="TLS 1.3"} |
TLS 版本(仅 HTTPS 目标) | 告警:若版本≠TLS1.2/1.3,触发 "TLS 版本过低(安全风险)" 告警 |
probe_ssl_last_chain_expiry_timestamp_seconds |
SSL 证书过期时间(时间戳) | 告警:剩余有效期 <7 天,触发 "SSL 证书即将过期" 告警 |
probe_http_redirects |
重定向次数 | 告警:值 > 1 时触发 "重定向次数过多(网络 / 配置异常)" 告警 |
probe_ip_protocol |
IP 协议版本(4=IPv4,6=IPv6) | 告警:若值≠预期(如预期 IPv4 但 = 6),触发 "IP 协议版本异常" 告警 |