incremark 的惊人实力
昨天发布了周日开发的 incremark,没想到实际体验性能远超预期,本想作为自己产品内部的一个小工具,但想了想,开源未尝不是一个好的方向。
先看结果:普通比较短的 markdown 在线测试结果
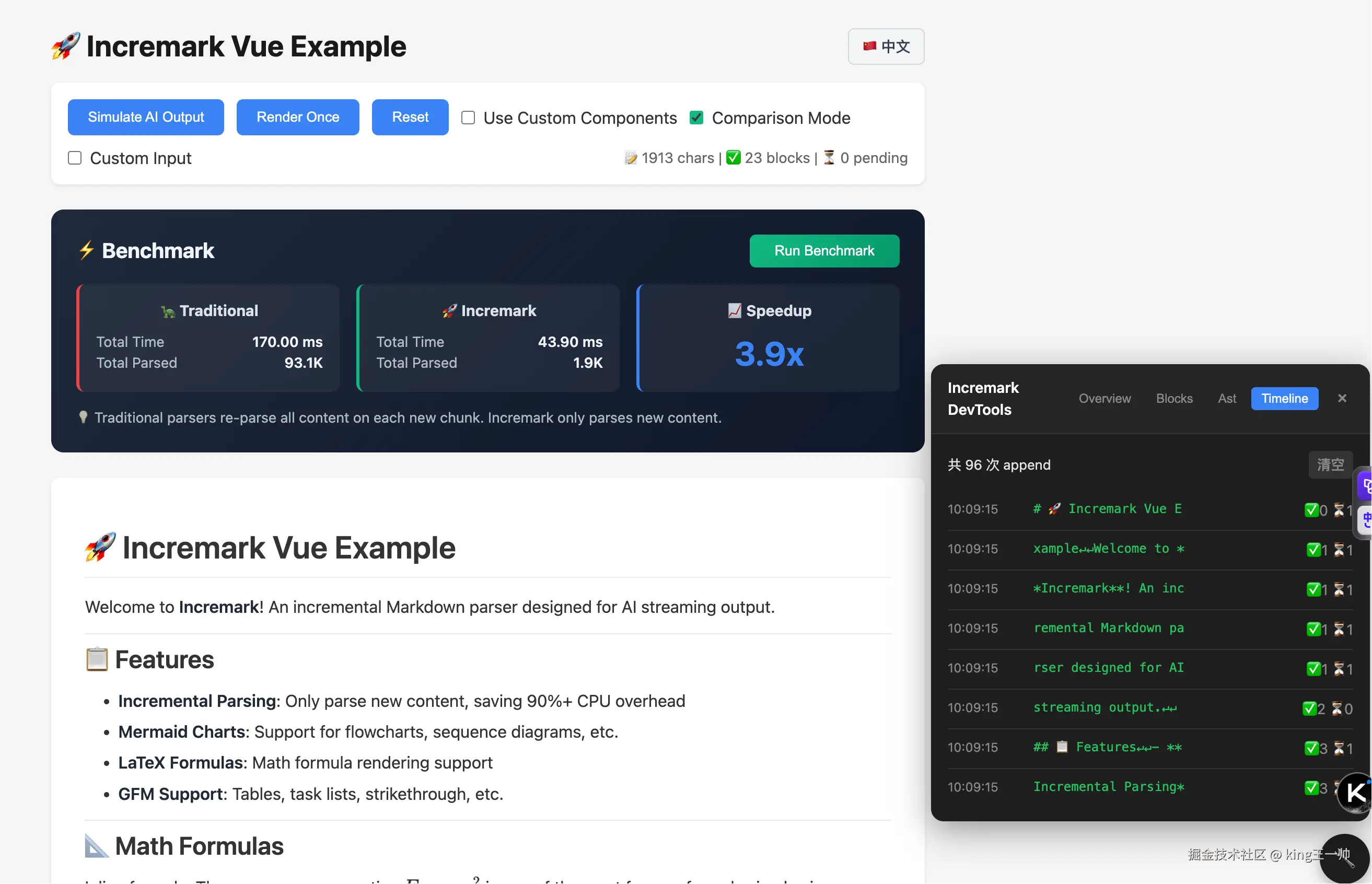
稍长的 markdown 在线测试结果
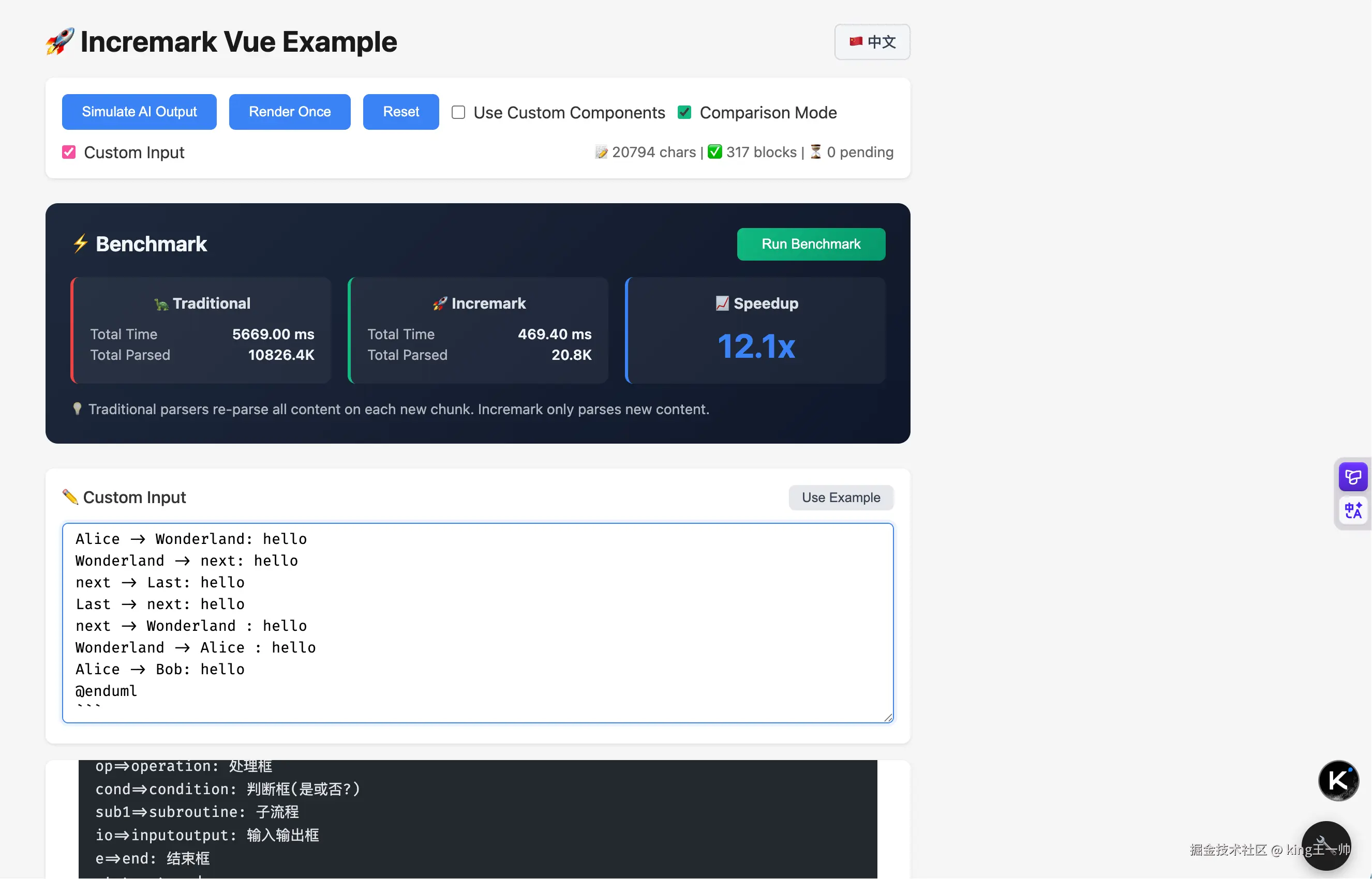
说明:网站每次 benchmark 测试每次提升倍数可能不一样,这是由于分块策略导致的,demo 页面每次分块的 markdown 字符串长度是随机的
const chunks = content.match(/[\s\S]{1,20}/g) || [],分块会影响稳定块的生成,这样也更符合真实场景,某个块可能会有上一个块的内容跟下一个块的内容。但无论怎样分,性能提升是必然的,demo 网站未通过迎合自身利益的手段进行 chunk 拆分。
vue demo 在线链接:incremark-vue.vercel.app/
react demo 在线链接:incremark-react.vercel.app/
文档链接:incremark-docs.vercel.app/
超长的 markdown 输出会来更更加离谱的速度,20k 的 markdown benchmark 可以达到恐怖的 46 倍速度提升。
为什么它会有如此提升?
传统解析方案弊端
做过 AI 聊天应用的人可能都知道,AI 的流式输出在前端每次获取到的都是一个个简短的 chunk,每次 chunk 过来后,都需要将完整的 markdown 字符串喂给 markdown 解析器,可能是 remark、 markedjs,也可能是 markdown-it。它们每次都需要将所有的 markdown 进行解析,最后在进行渲染,在此过程中会有一部分性能浪费,即已经稳定渲染的块也要被重复解析。
vue-stream-markdown 这类型工具在渲染层也做了努力,将稳定的 token 渲染为稳定的组件,每次只更新不稳定的组件,以此达到渲染层的平滑流式输出。
但、这仍无法解决性能浪费的本质问题,也就是 markdown 文本的重复解析,这一步才是吃掉 cpu 性能的怪兽,输出文档越长,则性能浪费越高。
incremark 核心性能优化原理
incremark 除了做到了 UI 渲染层的组件复用平滑更新,最主要的是在 markdown 解析上做了文档,只解析不稳定的 markdown,不再重复解析稳定的块。因此将解析性能从 O(n²) 拉到了 O(n),理论上输出越长,提升越多。
1. 增量解析:从 O(n²) 到 O(n)
传统解析器每次都重新解析整个文档,导致解析量呈平方增长。Incremark 的 IncremarkParser 类采用增量解析策略,见代码 IncremarkParser.ts
ts
// 设计思路:
// 1. 维护一个文本缓冲区,接收流式输入
// 2. 识别"稳定边界",将已完成的块标记为 completed
// 3. 对于正在接收的块,每次重新解析,但只解析该块的内容
// 4. 复杂嵌套节点作为整体处理,直到确认完成2. 智能边界检测机制
append 方法中的 findStableBoundary() 是关键优化点
ts
append(chunk: string): IncrementalUpdate {
this.buffer += chunk
this.updateLines()
const { line: stableBoundary, contextAtLine } = this.findStableBoundary()
if (stableBoundary >= this.pendingStartLine && stableBoundary >= 0) {
// 只解析新完成的块,不重复解析已完成内容
const stableText = this.lines.slice(this.pendingStartLine, stableBoundary + 1).join('\n')
const ast = this.parse(stableText)
// ...
}
}3. 状态管理避免重复计算
解析器维护多个关键状态来避免重复工作
buffer: 累积的未解析内容completedBlocks: 已完成且永不重新解析的块数组lineOffsets: 行偏移量前缀和,支持 O(1) 行位置计算context: 跟踪代码块、列表等嵌套状态
4. 增量行更新优化
updateLines() 方法只处理新增内容,避免全量 split 操作
ts
private updateLines(): void {
// 找到最后一个不完整的行(可能被新 chunk 续上)
const lastLineStart = this.lineOffsets[prevLineCount - 1]
const textFromLastLine = this.buffer.slice(lastLineStart)
// 重新 split 最后一行及之后的内容
const newLines = textFromLastLine.split('\n')
// 只更新变化的部分
}性能对比数据
这种设计在实际测试中表现优异 :
| 文档大小 | 传统解析字符量 | Incremark 解析字符量 | 减少比例 |
|---|---|---|---|
| 1KB | 1,010,000 | 20,000 | 98% |
| 5KB | 25,050,000 | 100,000 | 99.6% |
| 20KB | 400,200,000 | 400,000 | 99.9% |
关键不变量
Incremark 的性能优势源于一个关键不变量:一旦块被标记为 completed,就永远不会被重新解析。这确保了每个字符最多只被解析一次,实现了 O(n) 的时间复杂度。
小结
昨天在掘金发布了 # AI 时代真正流式解析+渲染双重优化的 Incremark 并没有获得推流,在 V 站随意发帖下,github 意外收获了 35 颗 star,npm 收获 92 下载量,突然感觉它似乎应该是能对一些小伙伴产生作用的,所以尝试当个事来做,如果你也感兴趣,欢迎试用以及代码贡献。