1.因为使用的是hadoop用户进行scp远程分发之前需要在node2节点和node3节点下面操作如下命令:
bash
连接成功
Last login: Mon Dec 15 09:19:28 2025
(base) [root@node3 ~]# sudo useradd -m -s /bin/bash hadoop
(base) [root@node3 ~]# vim /etc/hosts
您在 /var/spool/mail/root 中有新邮件
(base) [root@node3 ~]# sudo passwd hadoop
更改用户 hadoop 的密码 。
新的 密码:
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
您在 /var/spool/mail/root 中有新邮件
(base) [root@node3 ~]# sudo groupadd hadoopgroup
您在 /var/spool/mail/root 中有新邮件
(base) [root@node3 ~]# sudo usermod -aG hadoopgroup hadoop
(base) [root@node3 ~]# sudo mkdir -p /export/server
(base) [root@node3 ~]# sudo chgrp -R hadoopgroup /export/server
(base) [root@node3 ~]# sudo chmod -R 775 /export/server
您在 /var/spool/mail/root 中有新邮件
(base) [root@node3 ~]# cd /export/server
您在 /var/spool/mail/root 中有新邮件
(base) [root@node3 server]# ll
总用量 4
drwxrwxr-x 28 root hadoopgroup 4096 12月 11 15:08 anaconda3
drwxrwxr-x 10 root hadoopgroup 201 8月 6 15:29 apache-hive-3.1.2-bin
drwxrwxr-x 11 root hadoopgroup 227 7月 21 15:58 hadoop-3.3.0
drwxrwxr-x 7 root hadoopgroup 245 7月 21 14:53 jdk1.8.0_241
drwxr-xrwx 13 hadoop hadoop 211 12月 15 11:08 spark-3.2.0-bin-hadoop3.2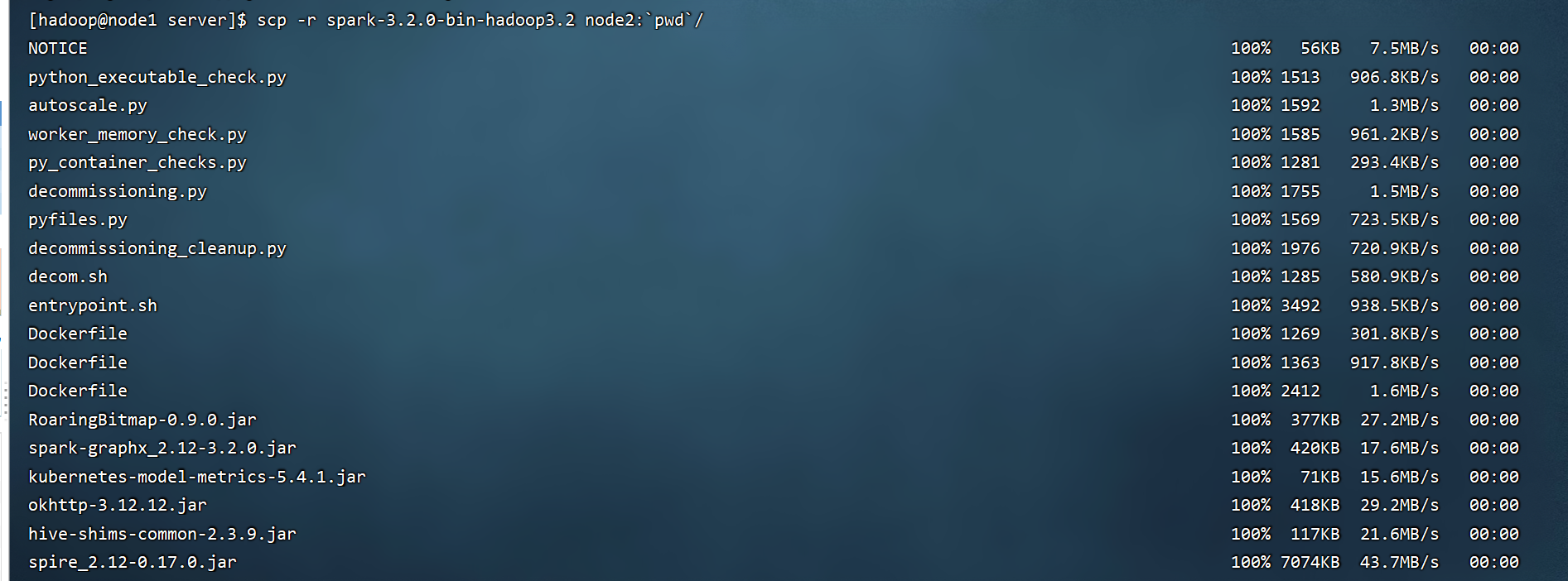
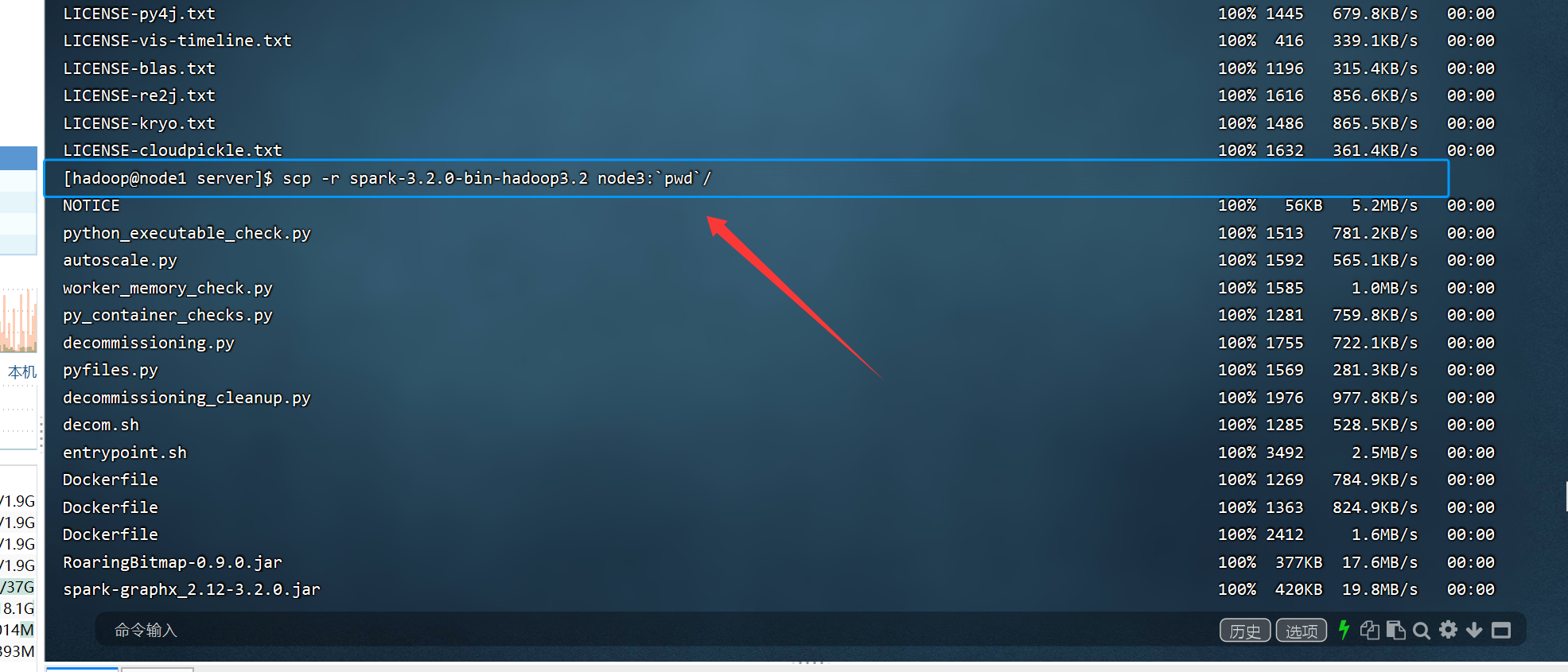
看到上面的截图,证明node2和node3节点均分发spark完毕
2.接下来分别在node2和node3上面创建spark的软链接,操作方式相同,下面是node3节点上操作过程
bash
(base) [root@node3 server]# su - hadoop
[hadoop@node3 ~]$ cd /export/server
[hadoop@node3 server]$ ll
total 4
drwxrwxr-x 28 root hadoopgroup 4096 Dec 11 15:08 anaconda3
drwxrwxr-x 10 root hadoopgroup 201 Aug 6 15:29 apache-hive-3.1.2-bin
drwxrwxr-x 11 root hadoopgroup 227 Jul 21 15:58 hadoop-3.3.0
drwxrwxr-x 7 root hadoopgroup 245 Jul 21 14:53 jdk1.8.0_241
drwxr-xrwx 13 hadoop hadoop 211 Dec 15 11:08 spark-3.2.0-bin-hadoop3.2
[hadoop@node3 server]$ ln -s /export/server/spark-3.2.0-bin-hadoop3.2/ /export/server/spark
[hadoop@node3 server]$ ll
total 4
drwxrwxr-x 28 root hadoopgroup 4096 Dec 11 15:08 anaconda3
drwxrwxr-x 10 root hadoopgroup 201 Aug 6 15:29 apache-hive-3.1.2-bin
drwxrwxr-x 11 root hadoopgroup 227 Jul 21 15:58 hadoop-3.3.0
drwxrwxr-x 7 root hadoopgroup 245 Jul 21 14:53 jdk1.8.0_241
lrwxrwxrwx 1 hadoop hadoop 41 Dec 15 14:06 spark -> /export/server/spark-3.2.0-bin-hadoop3.2/
drwxr-xrwx 13 hadoop hadoop 211 Dec 15 11:08 spark-3.2.0-bin-hadoop3.2
[hadoop@node3 server]$ 3.检查环境变量配置 主要看JAVA_HOME YARN HDFS配置
bash
[hadoop@node3 server]$ ll
total 4
drwxrwxr-x 28 root hadoopgroup 4096 Dec 11 15:08 anaconda3
drwxrwxr-x 10 root hadoopgroup 201 Aug 6 15:29 apache-hive-3.1.2-bin
drwxrwxr-x 11 root hadoopgroup 227 Jul 21 15:58 hadoop-3.3.0
drwxrwxr-x 7 root hadoopgroup 245 Jul 21 14:53 jdk1.8.0_241
lrwxrwxrwx 1 hadoop hadoop 41 Dec 15 14:06 spark -> /export/server/spark-3.2.0-bin-hadoop3.2/
drwxr-xrwx 13 hadoop hadoop 211 Dec 15 11:08 spark-3.2.0-bin-hadoop3.2
[hadoop@node3 server]$ cd spark
[hadoop@node3 spark]$ ll
total 124
drwxr-xrwx 2 hadoop hadoop 4096 Dec 15 11:08 bin
drwxr-xrwx 2 hadoop hadoop 161 Dec 15 11:08 conf
drwxr-xrwx 5 hadoop hadoop 50 Dec 15 11:08 data
drwxr-xrwx 4 hadoop hadoop 29 Dec 15 11:08 examples
drwxr-xrwx 2 hadoop hadoop 12288 Dec 15 11:08 jars
drwxr-xrwx 4 hadoop hadoop 38 Dec 15 11:08 kubernetes
-rwxr-xr-x 1 hadoop hadoop 22878 Dec 15 11:08 LICENSE
drwxr-xrwx 2 hadoop hadoop 4096 Dec 15 11:08 licenses
-rwxr-xr-x 1 hadoop hadoop 57677 Dec 15 11:08 NOTICE
drwxr-xrwx 9 hadoop hadoop 327 Dec 15 11:08 python
drwxr-xrwx 3 hadoop hadoop 17 Dec 15 11:08 R
-rwxr-xr-x 1 hadoop hadoop 4512 Dec 15 11:08 README.md
-rwxr-xr-x 1 hadoop hadoop 167 Dec 15 11:08 RELEASE
drwxr-xrwx 2 hadoop hadoop 4096 Dec 15 11:08 sbin
drwxr-xrwx 2 hadoop hadoop 42 Dec 15 11:08 yarn
[hadoop@node3 spark]$ cd conf
[hadoop@node3 conf]$ ll
total 36
-rwxr-xr-x 1 hadoop hadoop 1105 Dec 15 11:08 fairscheduler.xml.template
-rwxr-xr-x 1 hadoop hadoop 2471 Dec 15 11:08 log4j.properties
-rwxr-xr-x 1 hadoop hadoop 9141 Dec 15 11:08 metrics.properties.template
-rwxr-xr-x 1 hadoop hadoop 1518 Dec 15 11:08 spark-defaults.conf
-rwxr-xr-x 1 hadoop hadoop 5364 Dec 15 11:08 spark-env.sh
-rwxr-xr-x 1 hadoop hadoop 874 Dec 15 11:08 workers
[hadoop@node3 conf]$ vim spark-env.sh4.启动Spark集群
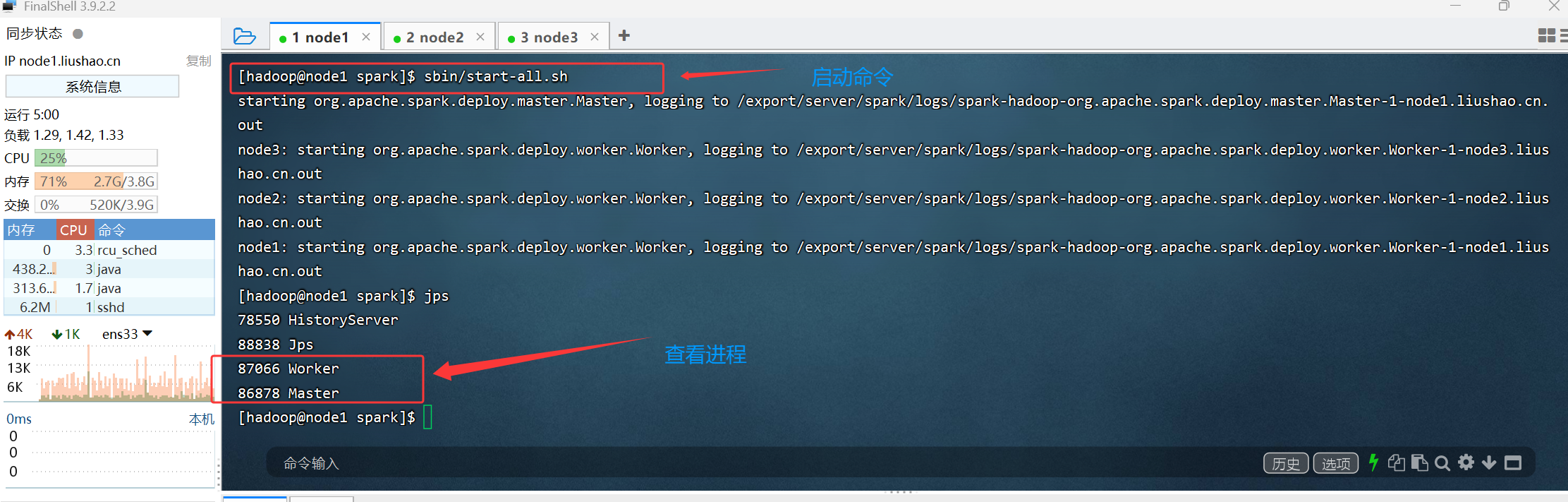
bash
[hadoop@node1 spark]$ sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.liushao.cn.out
node3: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node3.liushao.cn.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.liushao.cn.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node1.liushao.cn.out
[hadoop@node1 spark]$ jps
78550 HistoryServer
88838 Jps
87066 Worker
86878 Master
[hadoop@node1 spark]$ 通过vim conf/spark-env.sh 查看webUI的端口
使用浏览器访问
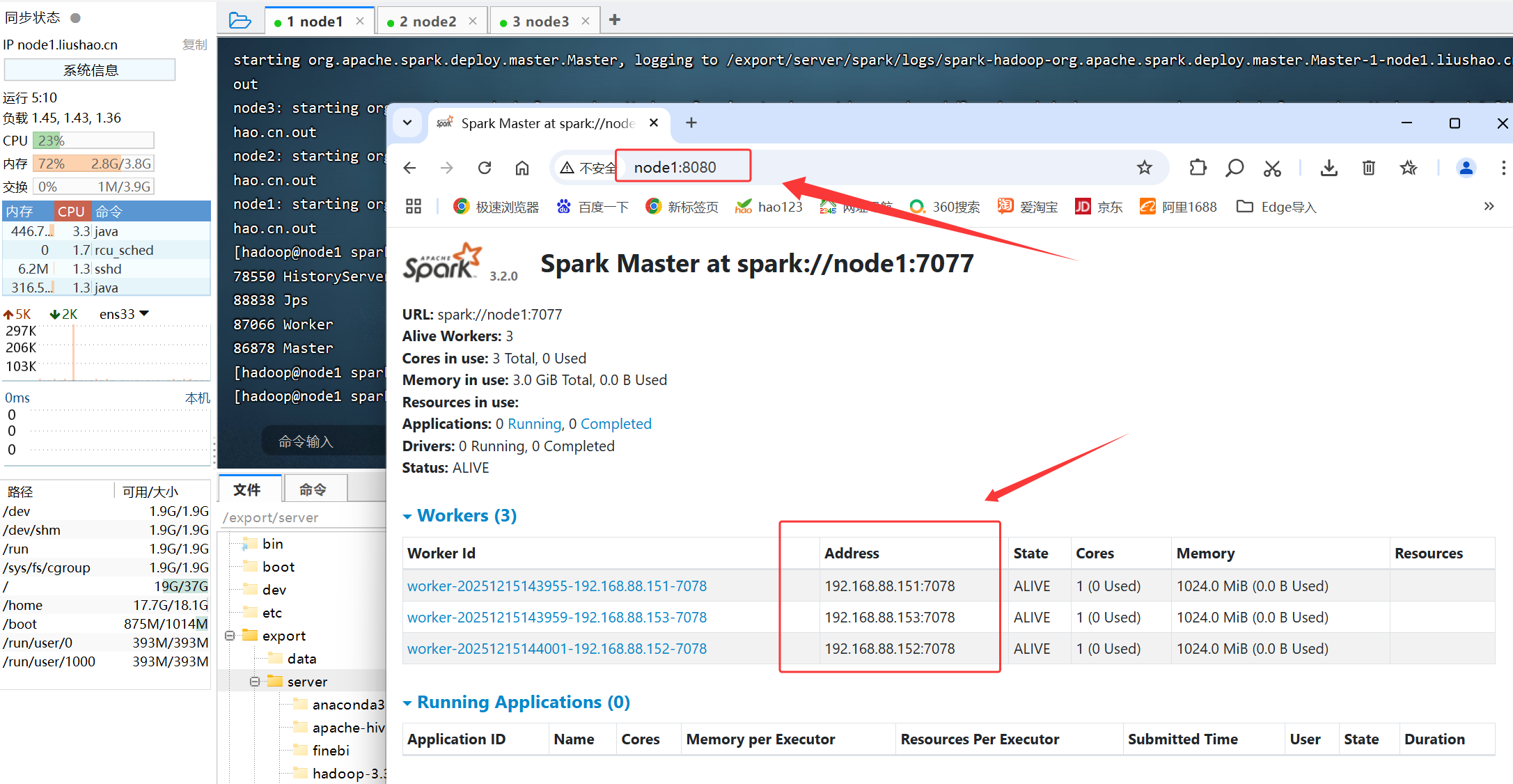
看到这里,恭喜你集群启动成功了!