进程优先级
基本概念
是什么?
进程优先级是进程得到CPU资源的先后顺序。
为什么?
目标资源稀缺,导致要通过优先级确认谁先谁后的问题!
怎么实现的?
在一般的OS内,优先级也是一种数字,并且也是进程task_struct内的一个属性。几乎在所有OS里面,都有一个要求:值越低,优先级越高。我们现在用到的多数OS都是基于时间片的分时操作系统,这种OS考虑一定的公平性(进程的优先级未来可能变化,但变化幅度不能太大)。
总的来说,cpu资源分配的先后顺序,就是指进程的优先权(priority)。优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。还可以把进程运行到指定的CPU上,这样⼀来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
补充:优先级vs权限
优先级本质上决定的是我已经能得到这个资源,只不过是先后的问题!权限的本质是我能不能得到某种资源!
查看系统进程
在Linux系统中,使用ps -al 的如下两种方式可以查看到如下信息:


我们很容易就注意到其中的几个重要信息,有:
UID(user id):代表执行者的身份
PID:代表这个进程的编号
PPID:代表该进程的父进程编号
PRI:代表这个进程执行优先级,值越小优先级越高,默认80
NI:表示该进程的nice值,是进程优先级的修正数据,默认0
补充:
1、UID
系统怎么知道我访问文件的时候,是拥有者、所属组还是Other?
在Linux系统中,系统识别我这个用户,不是通过名字去识别的,而是根据用户的UID去识别。通过ls -ln我们也可以看到用户的UID值为1000,和上面图中的UID一致,也就是说文件在创建时就已经写入了用户的UID属性,进程在启动的时候也会把文件对应的UID保存起来表明这个进程是哪个用户启动的。
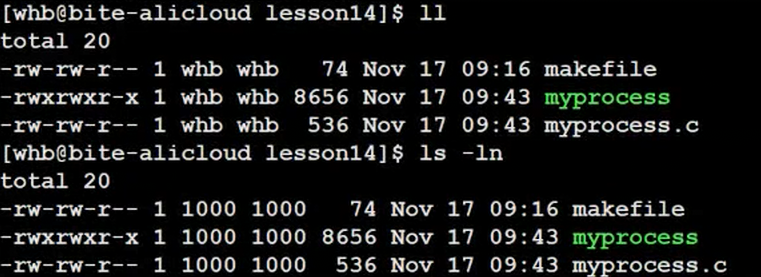
在Linux系统中,访问任何资源都是进程访问,进程就代表用户。因为这个进程在启动时,保留有用户的UID,所以是谁启动的它就有了。这个文件是谁创建的,也保留有用户的UID。当进程在访问或启动文件时,两个UID会进行对比匹配,如果一致,表明拥有者相同,如果不一致则会继续查看所属组,若还不是就表明是other。所以说识别权限并不是识别用户的,而是识别进程和文件之间的权限。
2、PRI 和 NI (并不建议大家去修改优先级,只是为了讲这个知识点)
PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。而NI就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值。PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice这样,nice值的修改不是一个累计的过程,而是基于PRI(old)的基础上进行的加减,举例PRI=80,我们将NI修改为10,那么PRI就变成了90,接着我将NI改成-10,那么PRI就变成了70(这样设计避免了我们而二次修改优先级时查找上一次的优先级值问题)。当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行。所以,调整进程优先级,在Linux下,就是调整进程nice值。需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。
存在NI的原因:优先级设立不合理,会导致优先级低的进程长时间得不到CPU资源,进而导致进程饥饿,因此设立NI允许用户小范围调整进程的优先级。
查看进程优先级的命令
用top命令可以更改已存在进程的nice值:进入top后按"r"->输入进程PID->输入nice值
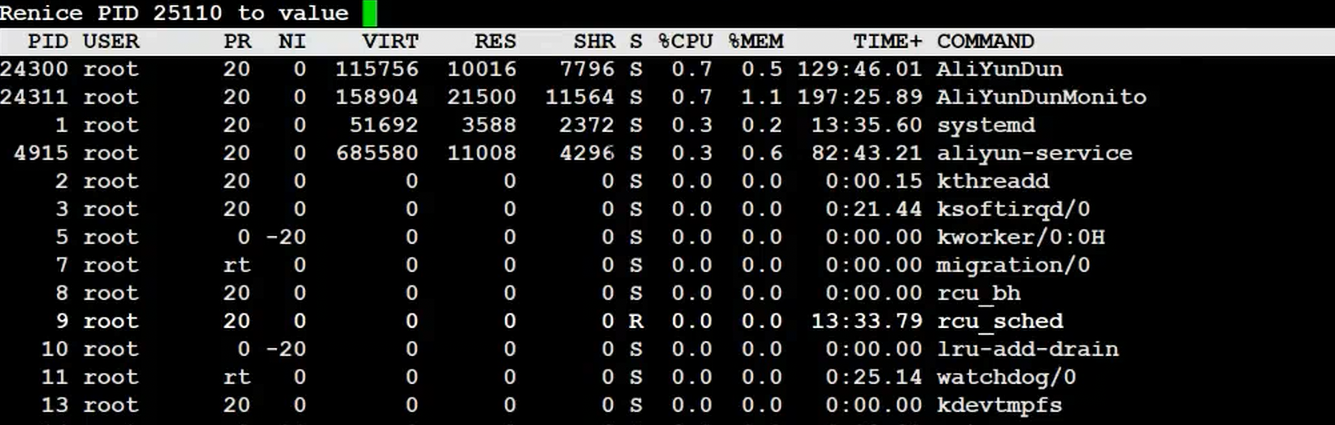
注意:
其他调整优先级的命令:nice,renice
补充:
nice其取值范围是-20到19,一共40个级别。所以Linux进程的优先级范围是60,99


同时C语言中还存在获取和修改NI值的系统函数:
cpp
#include<sys/time.h>
#include<sys/resource.h>
int getpriority(int which, int who);
int setpriority(int which, int who, int prio);补充概念 - 竞争、独立、并行、并发
竞争性:系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级。
独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰。
并行:多个进程在多个CPU下分别,同时进行运行,这称之为并行。
并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发。目前大多数的电脑都是单CPU的,我们在电脑上打开了很多程序,这些程序看似是并行执行的,但这是错觉,实际上是每个进程只执行一个时间片(极短的时间)再进行进程快速切换,也就是说理论上一个时刻仍然只有一个进程在运行,在一段时间内我们看到的就好像是多个程序一起执行,这种就是并发。
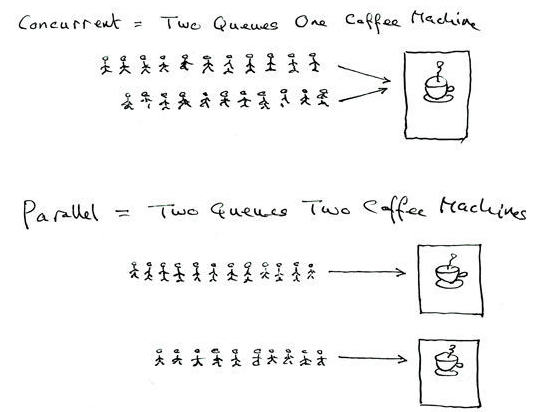
进程切换
讲进程切换前,我们先来聊聊死循环的进程是如何运行的 ?
一旦一个进程占有CPU,会把自己的代码跑完吗?答案除非这个进程在单个时间片内就能跑完,否则是不会的。每一个进程,系统都会给它分配一个叫时间片的东西,每个进程单次只能运行一个时间片的时间,然后就会被剥离下来,换另一个进程去执行,这样就不会出现一个进程死占CPU的情况。
如果一个进程可以一直占有CPU,直到运行结束才切换到下一个进程,而这个进程恰好又是死循环进程,那么在系统层面看这个进程会一直运行下去,在用户层面来看电脑就卡死了,因为我们关闭进程的操作也是一个进程,这个进程也只能等待CPU完成执行才能占用。从上面我们可知死循环不会打死系统,因为死循环进程不会一直都占有CPU!除非未来你在电脑上运行了相当多的死循环进程,否则不会卡死(或许会略卡)。
接下来再聊聊CPU和寄存器:
当一个进程在持有CPU的时候,就和进程的PCB关系不大了,CPU主要访问的是对应进程的代码和数据,CPU也不是把代码数据一股脑全部塞进去,而是通过CPU内部的寄存器将代码数据一点一点运进去。CPU内会存在很多的寄存器,其中有pc/EIP、ebp/esp、eax/ebx/ecx/edx、cs/ds/es/fg/gs等等(这里看看即可),这些寄存器内保存的是正在运行的进程在运行过程中的临时数据。
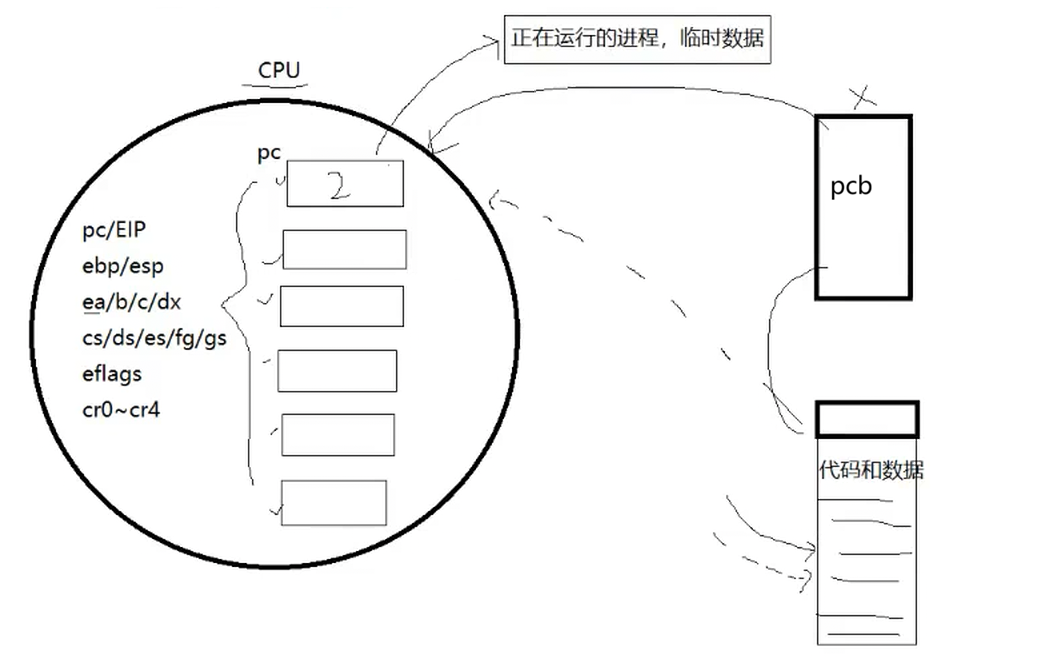
结论 :
1、寄存器就是CPU内部的临时空间!
2、寄存器不等于寄存器里面的数据,寄存器是一块空间,而里面的数据是内容。空间只有一份且不变,而内容是可以变化的且多份的。
如何进行进程切换 ?
我们先来举个栗子,有一位同学被选中当兵入伍,他要做的第一件事是去保留学籍,然后才能去当兵,一年后你退伍回归校园,第一件事是去恢复学籍。保留学籍的目的是为了一年后恢复学籍,当兵是你的目的,类比到操作系统中,学校扮演的是OS,导员扮演的是调度器(调度和切换共同构成了调度器),同学扮演的是进程,学籍代表的是进程运行的临时数据(即CPU内寄存器中的内容),保留学籍表示的是保存上下文数据,恢复学籍表示的是恢复上下文数据(把保存起来内容恢复到CPU寄存器中),去当兵就是进程被CPU剥离下来的操作。从主线上看,学生从校园离开后去当兵一年后回到校园的过程被称为一次进程切换,也就是说一次进程切换是保存上下文数据,被CPU剥离,随后恢复上下文数据,这是CPU中只有一个进程的情况,如果有多个,则会切换到其他进程。
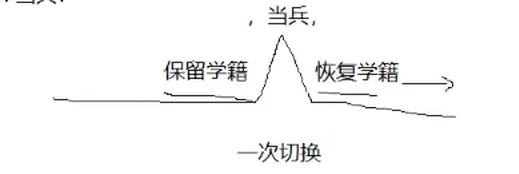
CPU上下文切换 :
其实际含义是任务切换,或者CPU寄存器切换。当多任务内核决定运行另外的任务时,它保存正在运行任务的当前状态,也就是CPU寄存器中的全部内容。这些内容被保存在任务自己的堆栈中,入栈工作完成后就把下一个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器,并开始下一个任务的运行,这一过程就是contextswitch。本质就是一次进程切换。
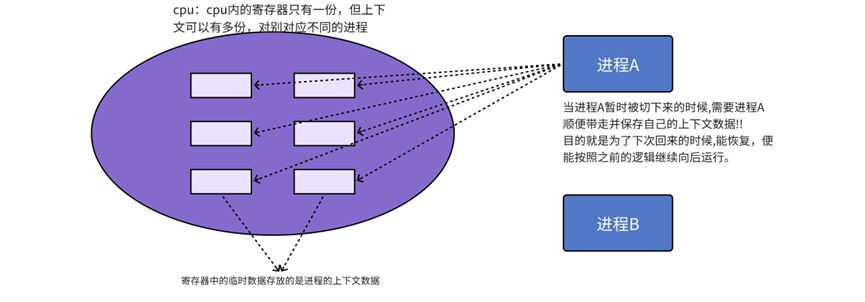
进程切换最核心的就是保存和恢复当前进程的硬件和上下文的数据,即CPU内寄存器的内容!!
1、所以当前进程要把自己的进程硬件上下文数据保存起来,保存到哪里呢 ?
保存到进程的task_struct里面的tss任务状态段中!实际上进程的上下文数据依然在系统中,task_struct里只存了类似编号的识别码,等当前进程再次被调度时,使用这个编号找到之前的上下文数据就可以了。
参考一下Linux老内核0.11版本代码:

2、全新的进程和已经调度过的进程怎么区分呢 ?
在老内核版本中体现不出来,在新内核版本中,task_struct中新增了一个标记为,如果该标记为的状态为is running,表示已经被调度过了,否则就是全新的进程。
补充 :
时间片:当代计算机都是分时操作系统,没有进程都有它合适的时间片(其实就是⼀个计数器)。时间片到达,进程就被操作系统从CPU中剥离下来。
实际上在内核层面我们OS内部存在一个全局的指针 struct task_struct* current,这个指针永远会指向当前进程,只要OS选择好进程了,就会把当前进程的地址填到这个指针里,在有些架构下,为了加快寻找进程速度,可能会把current放在寄存器内部,后续会详细讲解。
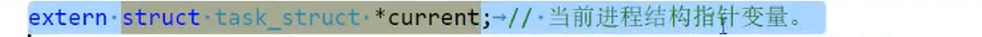
Linux下的真实调度算法
我们之前讲过调度,但那是基于课本理论的调度,而真正的调度算法会随着不同的系统作出不同的变化,下面我们来看看Linux内核下的调度算法是什么样的。
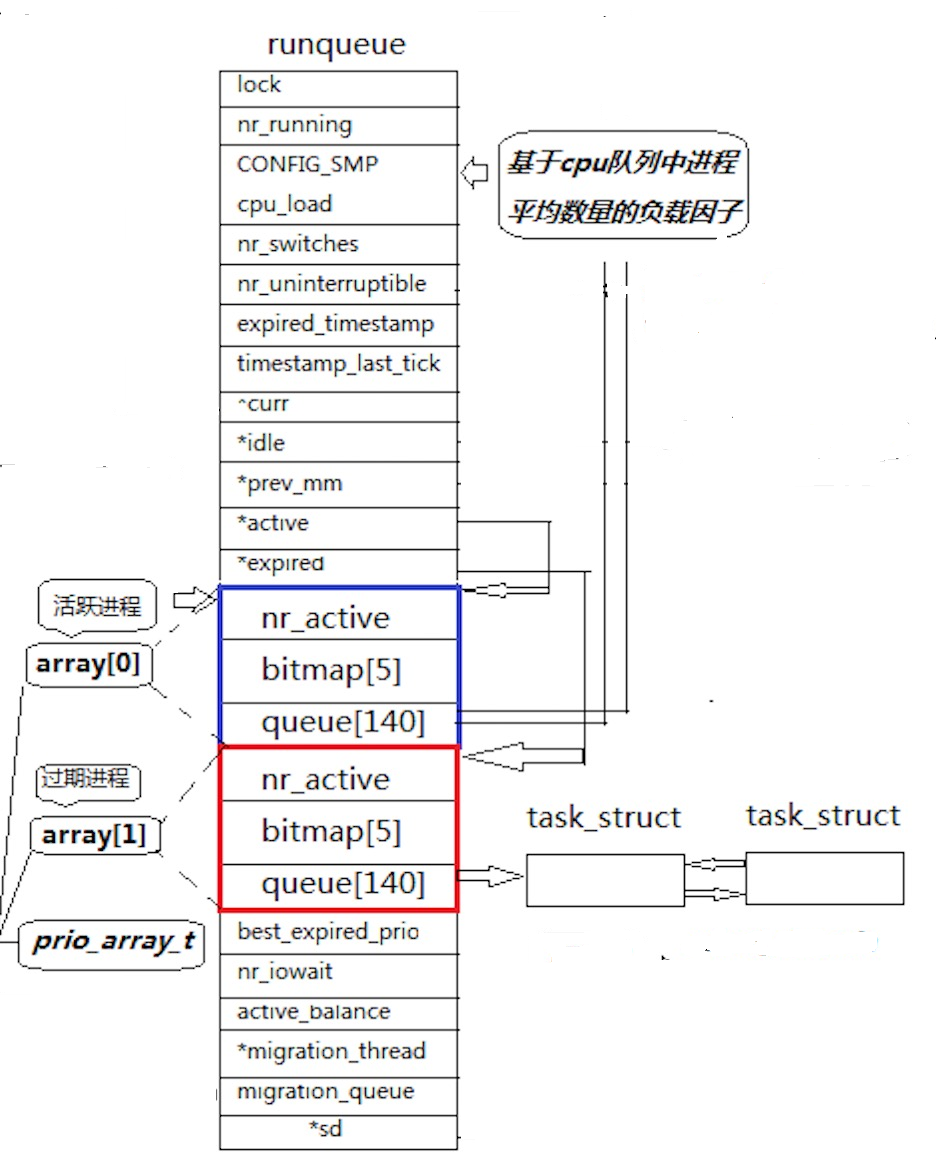
上图就是一个运行队列,每个CPU都有一个运行队列。我们先来看到array数组中的queue140,queue的类型是struct task_struct* ,也就是说这是一个指针数组,数组的第一部分用于存储实时优先级(占用100),OS被分为分时操作系统和实时操作系统,分时是按照时间片进行公平调度,常用于计算机互联网领域;实时是一旦来了个进程就必须立即响应,没处理完之前不会处理下一个,常用于工业和制造业领域,如智能驾驶汽车。所以对于实时优先级,我们并不考虑,剩下的40个优先级就是我们要考虑的分时优先级。
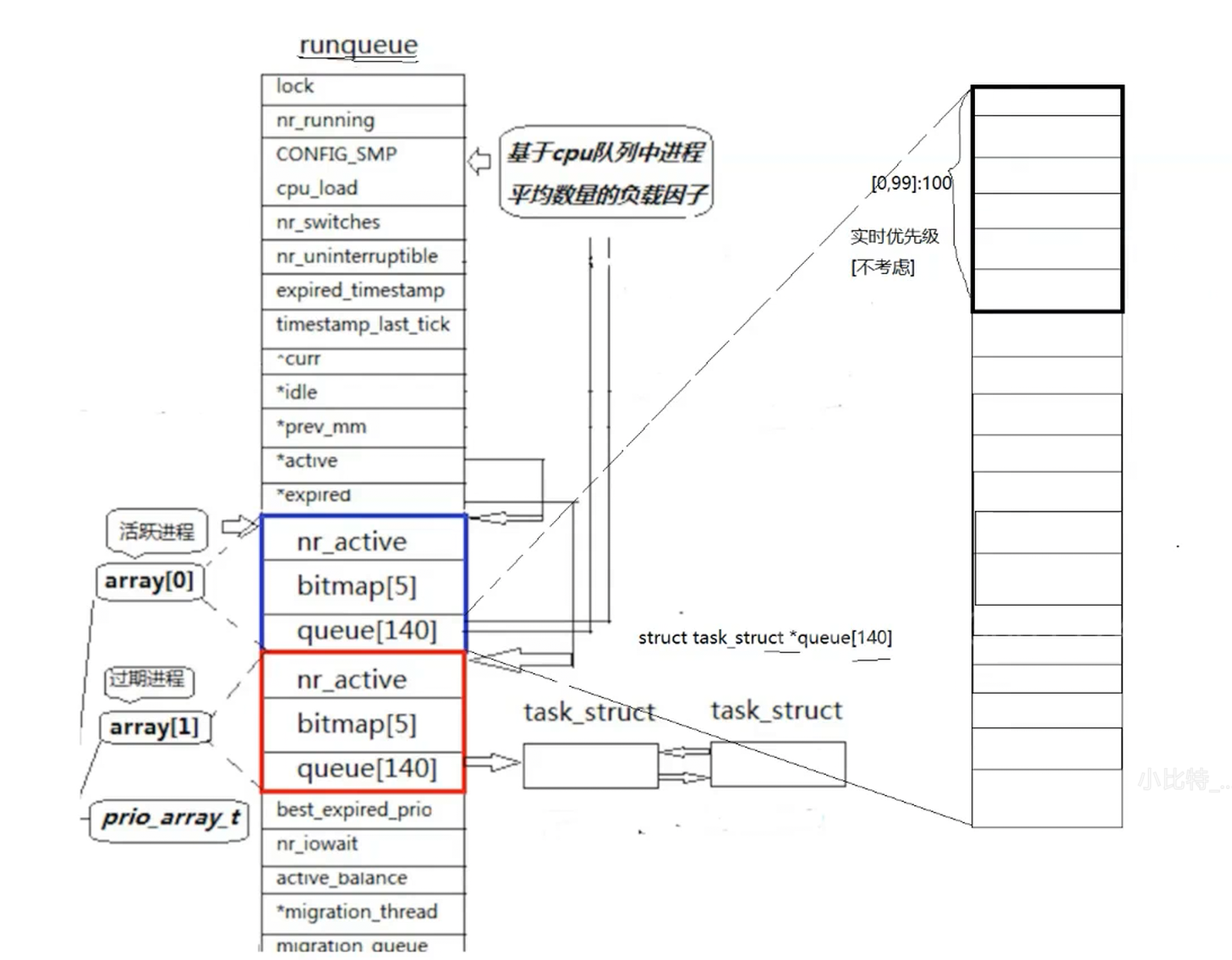
除开上面0-99的位置,100是分时优先级的开始,也是分时优先级的最低值(优先级最高),属于该优先级的进程会被全部连接到这个队列中,优先级低的依次往下寻找等与它的优先级的位置进行链接。当有新进程时,OS会根据该进程的优先级把进程连接到相应的队列中,计算方式是基于地址映射原理,也就是说这40个队列本质就是一个基于链表的哈希表,根据优先级的值不断将新进程连接进去
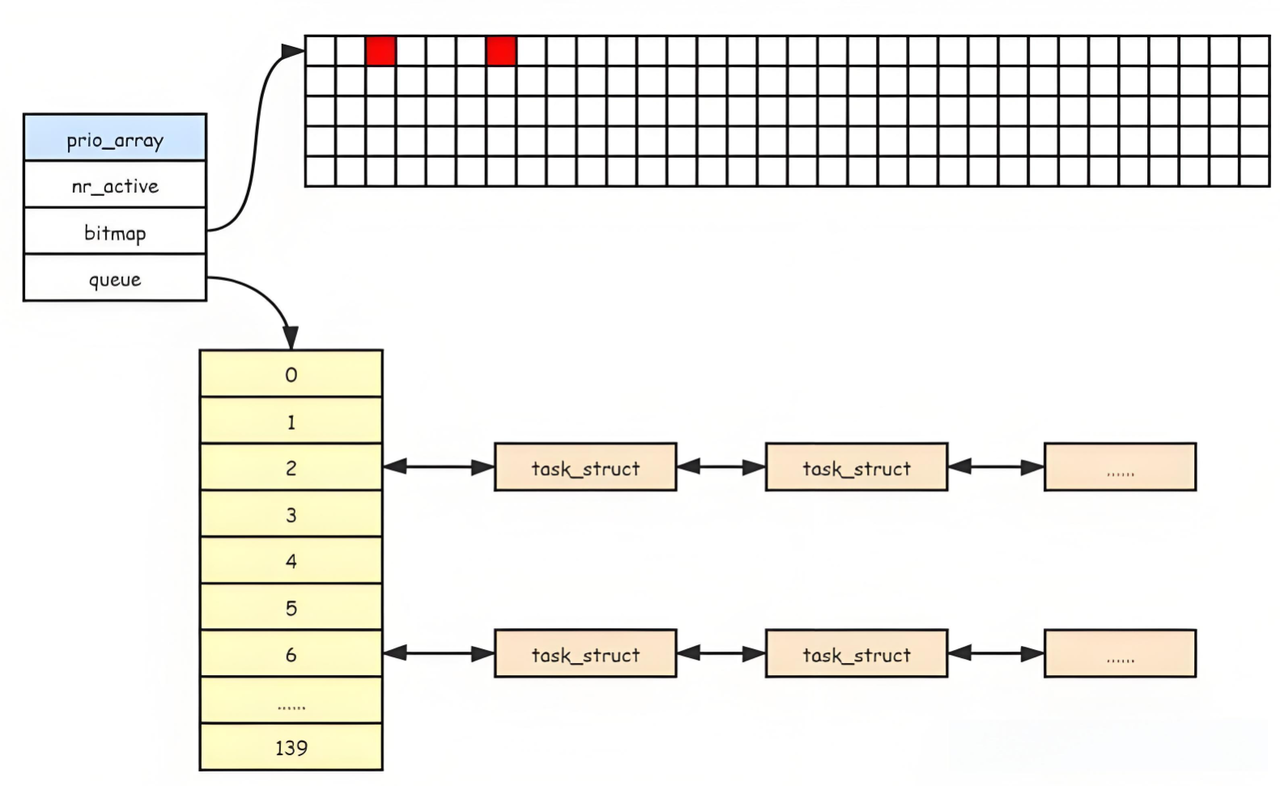
当进程全部连接入队列后,运行时,OS就会在这个优先级队列中从上往下进行遍历拿进程,当前位置为空后继续向下寻找。同一队列中的进程遵循先进先出。
如果某次我们队列中的进程的优先级都比较低,OS就需要数组遍历一遍才能找到第一个进程,虽然40是个常数,但还是浪费了不少时间,那么调度器如何快速地挑选一个进程呢?加下来就用到了array数组中的另一个数组bitmap5,它的类型是unsigned int,我们叫做位图。为什么要占用5呢,因为unsigned int 是32位,乘5就是160,是接近140最近的方式。在位图中每一位都存储的是1/0,1代表该位置上存在进程,0代表没有进程,这样我们就可以在O(1)的时间复杂度内快速找到第一个存在进程的数组的位置了。
nr_active表示的是整个队列中一共有多少个进程,当值>0时,OS才会开始执行。也就是说OS访问的顺序是先访问nr_active的值,然后在访问bitmap找到第一个进程,然后开始在第一个进程的数组往下遍历拿出进程开始运行。
这里还有一个问题,如果在高优先级队列中有一个死循环进程,这个进程执行完一个时间片后进行切换,仍然在高优先级队列的末尾,下一次还是要执行死循环进程,低优先级就轮不到了,会造成进程饥饿问题。所以我们如果单纯这样设计并不能满足一个非常卓越的调度过程,怎么办呢?在runqueue中,又设计了一个array1,结构和array0的结构完全一样,本质上就是做成了一个结构体数组,而两个数组的首地址分别被active和expired指针存了起来,都放在runqueue的结构体中。

如此设计,未来在OS进行进程切换时,被剥离下来的未执行完的进程会被放到过期队列中,直到活跃队列中的全部进程都被执行一轮,这样就避免了进程饥饿的形成,宏观上保护了优先级低的进程。当活跃队列全部被调完之后,OS就会执行swap(&active,&expired),直接完成了转换,进行下一轮调度。
总结 :在系统当中查找一个最合适调度的进程的时间复杂度是一个常数,不随着进程增多而导致时间成本增加,我们称之为进程调度O(1)算法!
Linux源码:
cpp
struct rq {
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
unsigned long raw_weighted_load;
#ifdef CONFIG_SMP
unsigned long cpu_load[3];
#endif
unsigned long long nr_switches;
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
unsigned long expired_timestamp;
unsigned long long timestamp_last_tick;
struct task_struct *curr, *idle;
struct mm_struct *prev_mm;
struct prio_array *active, *expired, arrays[2];
int best_expired_prio;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct sched_domain *sd;
/* For active balancing */
int active_balance;
int push_cpu;
struct task_struct *migration_thread;
struct list_head migration_queue;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
/* sys_sched_yield() stats */
unsigned long yld_exp_empty;
unsigned long yld_act_empty;
unsigned long yld_both_empty;
unsigned long yld_cnt;
/* schedule() stats */
unsigned long sched_switch;
unsigned long sched_cnt;
unsigned long sched_goidle;
/* try_to_wake_up() stats */
unsigned long ttwu_cnt;
unsigned long ttwu_local;
#endif
struct lock_class_key rq_lock_key;
};
/*
* These are the runqueue data structures:
*/
struct prio_array {
unsigned int nr_active;
DECLARE_BITMAP(bitmap, MAX_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_PRIO];
};