bash
[hadoop@node1 export]$ cd /export/server/spark/bin
[hadoop@node1 bin]$ ll
total 116
-rwxr-xrwx 1 hadoop hadoop 1089 Oct 6 2021 beeline
-rwxr-xrwx 1 hadoop hadoop 1064 Oct 6 2021 beeline.cmd
-rwxr-xrwx 1 hadoop hadoop 10965 Oct 6 2021 docker-image-tool.sh
-rwxr-xrwx 1 hadoop hadoop 1935 Oct 6 2021 find-spark-home
-rwxr-xrwx 1 hadoop hadoop 2685 Oct 6 2021 find-spark-home.cmd
-rwxr-xrwx 1 hadoop hadoop 2337 Oct 6 2021 load-spark-env.cmd
-rwxr-xrwx 1 hadoop hadoop 2435 Oct 6 2021 load-spark-env.sh
-rwxr-xrwx 1 hadoop hadoop 2636 Oct 6 2021 pyspark
-rwxr-xrwx 1 hadoop hadoop 1542 Oct 6 2021 pyspark2.cmd
-rwxr-xrwx 1 hadoop hadoop 1170 Oct 6 2021 pyspark.cmd
-rwxr-xrwx 1 hadoop hadoop 1030 Oct 6 2021 run-example
-rwxr-xrwx 1 hadoop hadoop 1223 Oct 6 2021 run-example.cmd
-rwxr-xrwx 1 hadoop hadoop 3539 Oct 6 2021 spark-class
-rwxr-xrwx 1 hadoop hadoop 2812 Oct 6 2021 spark-class2.cmd
-rwxr-xrwx 1 hadoop hadoop 1180 Oct 6 2021 spark-class.cmd
-rwxr-xrwx 1 hadoop hadoop 1039 Oct 6 2021 sparkR
-rwxr-xrwx 1 hadoop hadoop 1097 Oct 6 2021 sparkR2.cmd
-rwxr-xrwx 1 hadoop hadoop 1168 Oct 6 2021 sparkR.cmd
-rwxr-xrwx 1 hadoop hadoop 3122 Oct 6 2021 spark-shell
-rwxr-xrwx 1 hadoop hadoop 1818 Oct 6 2021 spark-shell2.cmd
-rwxr-xrwx 1 hadoop hadoop 1178 Oct 6 2021 spark-shell.cmd
-rwxr-xrwx 1 hadoop hadoop 1065 Oct 6 2021 spark-sql
-rwxr-xrwx 1 hadoop hadoop 1118 Oct 6 2021 spark-sql2.cmd
-rwxr-xrwx 1 hadoop hadoop 1173 Oct 6 2021 spark-sql.cmd
-rwxr-xrwx 1 hadoop hadoop 1040 Oct 6 2021 spark-submit
-rwxr-xrwx 1 hadoop hadoop 1155 Oct 6 2021 spark-submit2.cmd
-rwxr-xrwx 1 hadoop hadoop 1180 Oct 6 2021 spark-submit.cmd
-- 地址使用webUI中的地址 spark://node1:7077
[hadoop@node1 bin]$ ./pyspark --master spark://node1:7077
Python 3.8.20 (default, Oct 3 2024, 15:24:27)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
25/12/15 15:36:06 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.2.0
/_/
Using Python version 3.8.20 (default, Oct 3 2024 15:24:27)
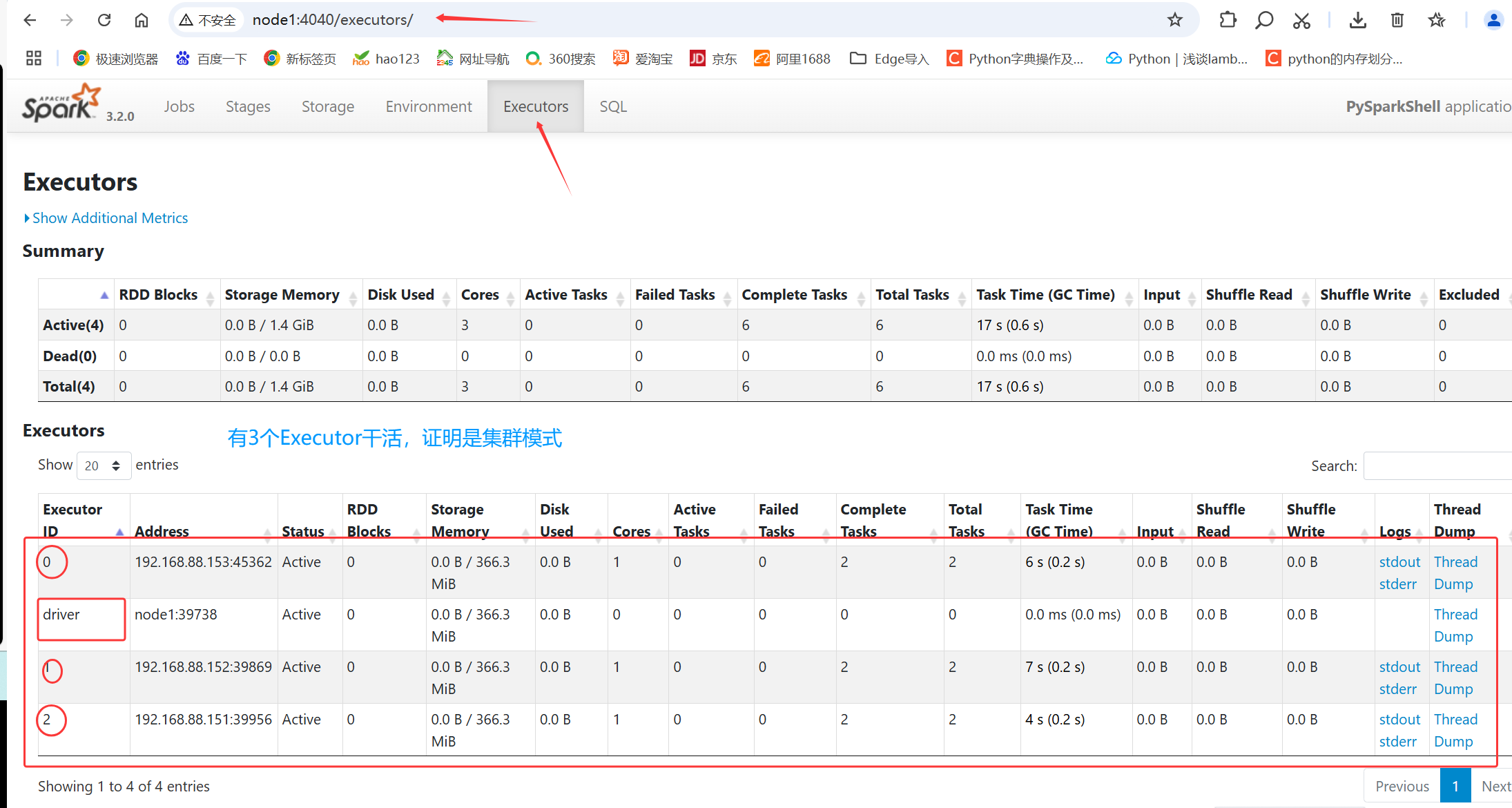
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = spark://node1:7077, app id = app-20251215153610-0000).
SparkSession available as 'spark'.
>>> sc.parallelize([1,2,3,4,5]).map(lambda x:x *10).collect()
[10, 20, 30, 40, 50]
>>> sc.parallelize([1,2,3,4,5]).map(lambda x:x *10).collect()
[10, 20, 30, 40, 50]
>>> 
通过ctrl+d退出程序
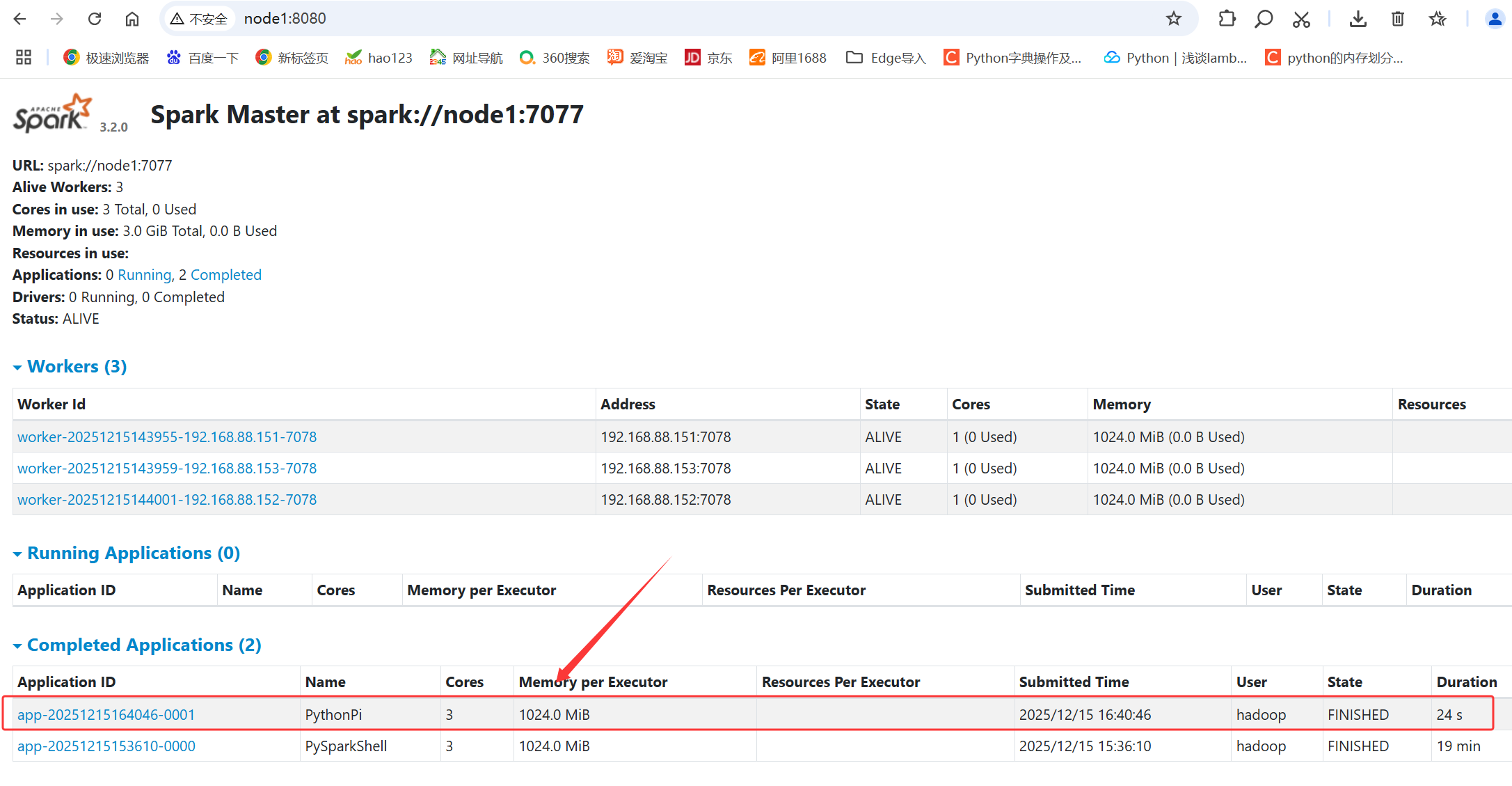
我们在浏览器中打开node1:4040 发现无法打开,因为刚刚听错ctrl+d退出了,我们通过node1:8080发现可以正常打开
通过测试我们发现 Standalone 环境和 Local环境完全不一样;因为Local将master和worker工作还有Driver的工作都做了;但是在 Standalone 中 master Driver worker都是独立的进程。当我们结束 ./pyspark的时候,仅仅是结束了Driver进程,其他的进程没有结束!
再一次测试:
bash
[hadoop@node1 bin]$ ./spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 100
25/12/15 16:40:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Pi is roughly 3.138920
[hadoop@node1 bin]$ 注意检测端口是: node1:18080
停止spark服务:
bash
(base) [root@node1 ~]# jps
72448 Jps
78550 HistoryServer
87066 Worker
86878 Master
(base) [root@node1 ~]# cd /export/server/spark
(base) [root@node1 spark]# sbin/stop-history-server.sh
no org.apache.spark.deploy.history.HistoryServer to stop
(base) [root@node1 spark]# su - hadoop
Last login: Mon Dec 15 17:43:32 CST 2025 on pts/0
[hadoop@node1 ~]$ cd /export/server/spark
[hadoop@node1 spark]$ sbin/stop-history-server.sh
stopping org.apache.spark.deploy.history.HistoryServer
[hadoop@node1 spark]$ sbin/stop-workers.sh
node1: stopping org.apache.spark.deploy.worker.Worker
node3: stopping org.apache.spark.deploy.worker.Worker
node2: stopping org.apache.spark.deploy.worker.Worker
[hadoop@node1 spark]$ jps
77864 Jps
86878 Master
[hadoop@node1 spark]$ sbin/stop-master.sh
stopping org.apache.spark.deploy.master.Master
[hadoop@node1 spark]$ jps
78695 Jps
[hadoop@node1 spark]$