一、Flink ML 的基石:Table API
1. Table API 是什么?
Flink ML 的 API 完全是基于 Flink Table API 构建的。
Table API 是 Flink 提供的一套语言集成的关系查询 API ,支持 Java / Scala / Python。
它允许你用一种类似 SQL 的方式组合:
- 选择(select)
- 过滤(filter)
- 连接(join)
- 聚合(groupBy / aggregate)
......等关系运算。
简单理解:
- DataStream API:更加"流式编程"的风格,操作的是一条条事件。
- Table API:更加"关系查询"的风格,操作的是有 schema 的表。
而 Flink ML 选择站在 Table API 之上,因为:
- 机器学习中的训练数据、特征表,本质上都是"表结构数据";
- 使用 Table API 更利于表达特征列、标签列、模型输出列等。
2. 支持数据类型与向量类型
Table API 支持非常丰富的数据类型(字符串、数值、时间、数组、Map 等),具体可以查 Flink 文档的 Data Types 部分。
在此基础上,Flink ML 额外引入了向量类型(Vector Type),用于表示特征向量,比如:
- 稀疏向量 / 稠密向量
- 二维 / 多维特征组合
在 Java / Python API 中,你会看到类似:
- Java:
DenseVector/Vectors.dense(...) - Python:
DenseVectorTypeInfo/Vectors.dense([...])
这个向量类型是很多 ML 算法(如 KMeans、线性回归、分类模型)默认的输入形式。
3. Table 与 DataStream 的无缝转换
Table API 并不是"取代" DataStream,而是与其无缝集成:
- 你可以将 DataStream 转为 Table,用于 ML 训练和预测;
- 也可以将 Table 输出再次转回 DataStream,交给其他流式逻辑处理。
典型流程:
java
// Java 大致示意
DataStream<MyRecord> stream = env.fromSource(...);
// stream -> table
Table t = tableEnv.fromDataStream(stream);
// 在 table 上使用 Flink ML,再输出结果
Table result = model.transform(t)[0];
// result -> stream
DataStream<Row> outStream = tableEnv.toDataStream(result);这也是 Flink ML 能够很好嵌入到复杂流式系统中的关键:中间只不过是一张 Table。
二、Stage:Flink ML 的最小组成单位
在 Flink ML 里,Stage 是所有算法组件的统一抽象,它本身是一个接口(没有具体功能),但它的子类构成了 ML 任务的核心积木。
Stage 的几个主要子类:
- Estimator
- AlgoOperator
- Transformer
- Model
下面逐一拆开解释。
1. Estimator:负责"训练"的 Stage
Estimator 表示"可训练的算法",它负责:
接收训练数据,执行 fit(),输出一个 Model。
特征:
- 提供
fit()方法; - 输入通常是一张或多张 Table(训练数据表);
- 输出是一个 Model 实例。
示例(伪代码):
java
Table trainData = ...;
SumEstimator estimator = new SumEstimator();
SumModel model = estimator.fit(trainData);映射到常见 ML 框架的概念:
Estimator≈ scikit-learn 里的Estimator/Classifier的类定义;fit()后得到的Model≈ "训练好后的模型实例"。
2. AlgoOperator:泛化的计算逻辑
AlgoOperator 表示一种"通用的多输入、多输出算子",本质是封装了一段表上的计算逻辑。
- 提供
transform()方法; - 接受一个或多个输入 Table;
- 输出一组结果 Table。
和 Transformer 的区别在于:
AlgoOperator 不强调"输入输出一一对应",适合用来表达聚合/汇总这类逻辑------例如:
- 根据用户行为 log 聚合统计
- 从多张中间表中拼出一张特征表
3. Transformer:一条记录变一条记录
Transformer 是一种语义更明确的 AlgoOperator:
它依然通过
transform()做转换,但语义上表示"一条输入记录 → 对应一条输出记录"。
典型用法:
- 特征标准化(StandardScaler)
- 特征拼接(VectorAssembler)
- one-hot 编码等
对比:
- Transformer:更像"逐行 Transformation",一进一出;
- AlgoOperator:更偏向"自由度更高的算子",可以是聚合、多表 join 等,可能出现 N 条输入 → 1 条输出 或反之。
4. Model:带"模型数据"的 Transformer
Model 是 Transformer 的子类,但多了两点很关键的能力:
- 携带"模型参数 / 模型数据"(如权重、聚类中心)
- 提供
getModelData()/setModelData()API
通常模型由 Estimator 训练产生:
java
Table trainData = ...;
Table predictData = ...;
SumEstimator estimator = new SumEstimator();
SumModel model = estimator.fit(trainData);
Table predictResult = model.transform(predictData)[0];特点:
getModelData()可以把模型内部的数据导出为 Table;setModelData()可以从 Table 中恢复模型参数,例如加载离线训练好的模型;- 模型数据可以是一张流式表(unbounded stream),支持模型在线更新。
工程意义:
你可以把模型数据持久化到外部存储(如 Hive / Kafka / 文件),然后通过
setModelData()把它"注入"到线上模型实例中,实现离线训练、在线加载。
三、Builders:Pipeline 与 Graph 的拼装方式
单个 Stage 只能完成一个小片段的处理,而真实项目往往需要:
- 先做特征工程(N 个 Transformer / AlgoOperator)
- 再训练模型(Estimator)
- 然后部署预测链路(Model + Transformer 等)
要把这些东西串在一起,Flink ML 提供了两套"装配 API":
- Pipeline:线性、有序链式结构
- Graph:通用 DAG 结构
四、Pipeline:线性 ML 流水线
1. 什么是 Pipeline?
Pipeline 本身是一个 Estimator。
它由一组按顺序排列的 Stage 列表组成,每个 Stage 可以是:
- Estimator
- Model
- Transformer
- AlgoOperator
Pipeline 的两个角色:
- 作为 Estimator:提供
fit(),训练 pipeline 中所有 Estimator,输出 PipelineModel。 - 得到的 PipelineModel:作为 Model,提供
transform(),串行执行所有阶段。
2. Pipeline.fit() 的执行流程
当你调用 Pipeline 的 fit() 时,内部会:
-
从第一个 Stage 开始,顺序遍历所有 Stage,直到"最后一个 Estimator"为止;
-
对每个 Stage:
-
如果是 Estimator:
- 调用该 Estimator 的
fit()得到一个 Model; - 如果后面还有 Estimator,则立刻用这个 Model 对当前表做
transform(),得到新的表,作为下一个 Stage 的输入;
- 调用该 Estimator 的
-
如果是 AlgoOperator 且后面还有 Estimator:
- 用该 AlgoOperator 对当前表做
transform(),得到新的表,传给下一个 Stage。
- 用该 AlgoOperator 对当前表做
-
-
所有 Estimator 训练完之后,构造一个 PipelineModel:
- PipelineModel 的 Stage 列表与原 Pipeline 一致;
- 但所有的 Estimator 都被"训练好的 Model"替换掉了。
换句话说:
Pipeline.fit() = 按顺序执行:
"若是 Estimator 就训练 + transform,若是 AlgoOperator 就 transform",
最终生成的是一个"全是 Transformer/Model/AlgoOperator 的链"。
3. PipelineModel.transform() 的执行流程
PipelineModel 是一个 Model。
当你调用 PipelineModel.transform() 时:
- 从第一层 Stage 开始,执行
transform(); - 上一个 Stage 的输出 Table 作为下一个 Stage 的输入;
- 一直执行到最后一个 Stage,输出最终结果表。
这跟 sklearn 的 Pipeline 非常类似:
fit():训练流水线中所有可训练的部分;transform()/predict():串行执行所有环节。
4. 一个简单示例
java
// 假设 SumModel 是 Model 子类,SumEstimator 是 Estimator 子类
Model modelA = new SumModel().setModelData(tEnv.fromValues(10));
Estimator estimatorA = new SumEstimator();
Model modelB = new SumModel().setModelData(tEnv.fromValues(30));
List<Stage<?>> stages = Arrays.asList(modelA, estimatorA, modelB);
Estimator<?, ?> estimator = new Pipeline(stages);这个 Pipeline 的 Stage 顺序是:
text
modelA -> estimatorA -> modelB执行 pipeline.fit(trainTable) 时会:
- 先用
modelAtransform 一次 - 再训练
estimatorA,得到modelA2 - 最后得到的 PipelineModel 中的顺序类似:
text
modelA (原来的)
modelA2 (由 estimatorA 训练得到)
modelB (原来的)在之后的预测中,PipelineModel.transform() 会按这个顺序逐个执行。
五、Graph:适用于复杂 DAG 的建模方式
Pipeline 对于线性流程非常好用,但现实中的 ML 系统经常会出现:
- 多路输入(用户画像表、行为序列表、多源数据);
- 中间分支 / 汇聚;
- 某些模型共享部分前置特征工程阶段。
这种场景下,线性的 Pipeline 就比较吃力了,这时就可以用 Graph。
1. Graph 是什么?
Graph 也是一个 Estimator,但内部结构是一个 DAG(有向无环图) 的 Stage 网络。
Graph 的行为:
-
Graph.fit():- 按拓扑排序顺序执行所有 Stage;
- Estimator:调用
fit()得到 Model,再用该 Model transform 输入表,输出给后继节点; - AlgoOperator:直接
transform()输入表,输出给后继节点; - 最终产生一个 GraphModel(里面是训练好的 Model + 固定的 AlgoOperator/Transformer)。
-
GraphModel.transform():- 同样按拓扑排序的顺序执行 DAG 中每个 Stage 的
transform(); - 输入来自前驱节点的输出 Table,经由 DAG 传播到终点,输出结果表。
- 同样按拓扑排序的顺序执行 DAG 中每个 Stage 的
2. GraphBuilder 与 TableId
为方便构建 DAG,Flink ML 提供了:
- GraphBuilder:用来逐步添加 Stage 和连接关系;
- TableId:用来表示 Stage 的输入/输出"占位符"。
这两者的设计有一个重要意义:
你可以在还没有真实 Table 对象的情况下,先把 DAG 拓扑结构定义好,然后再在构建 Model 时指定真实的输入输出 Table。
3. 官方示例代码解析
示例:
java
// 假设 SumModel 是 Model 子类
GraphBuilder builder = new GraphBuilder();
// 创建节点
SumModel stage1 = new SumModel().setModelData(tEnv.fromValues(1));
SumModel stage2 = new SumModel();
SumModel stage3 = new SumModel().setModelData(tEnv.fromValues(3));
// 创建输入和 modelData 输入
TableId input = builder.createTableId();
TableId modelDataInput = builder.createTableId();
// 连接各个节点,构建 DAG
TableId output1 = builder.addAlgoOperator(stage1, input)[0];
TableId output2 = builder.addAlgoOperator(stage2, output1)[0];
builder.setModelDataOnModel(stage2, modelDataInput);
TableId output3 = builder.addAlgoOperator(stage3, output2)[0];
TableId modelDataOutput = builder.getModelDataFromModel(stage3)[0];
// 构建 Model
TableId[] inputs = new TableId[] {input};
TableId[] outputs = new TableId[] {output3};
TableId[] modelDataInputs = new TableId[] {modelDataInput};
TableId[] modelDataOutputs = new TableId[] {modelDataOutput};
Model<?> model = builder.buildModel(inputs, outputs, modelDataInputs, modelDataOutputs);逻辑图大致是:
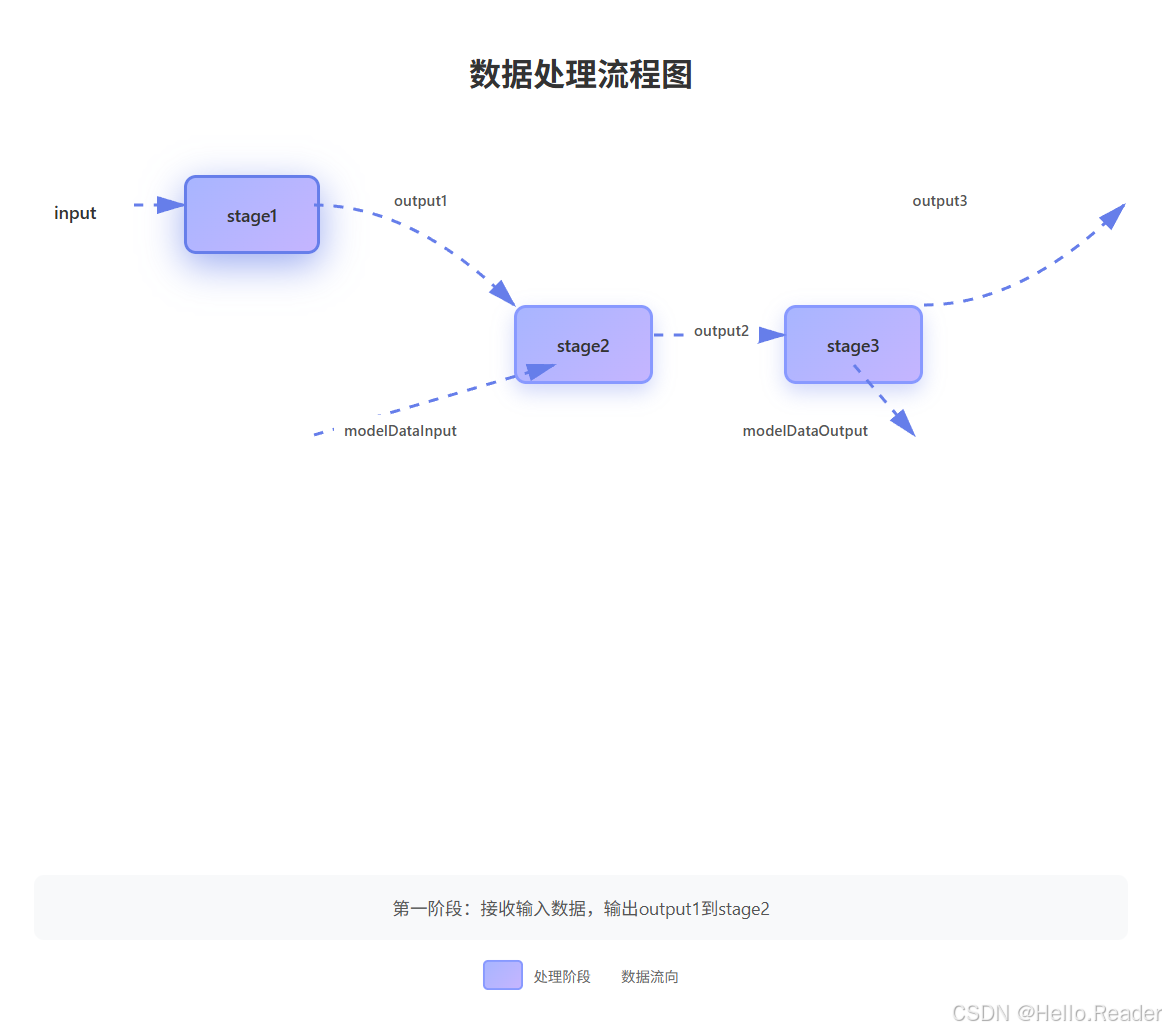
你可以看到:
input/outputN/modelDataInput/modelDataOutput都是TableId,用来表示数据流的连接关系;stage2的模型数据来自modelDataInput;stage3的模型数据输出到modelDataOutput。
工程实践中,Graph 适合:
- 多路输入、多路输出的复杂特征加工 / 模型流水线;
- 多个模型共享某些中间 Stage;
- 需要在 DAG 中管理模型数据流向(modelData 输入/输出)。
六、参数系统:WithParams & Param
Flink ML 的所有 Stage 都是 WithParams 的子类,这意味着:
所有算法的参数(如
k、maxIter、featuresCol等)都通过一套统一的Param系统来管理。
1. Param 是什么?
一个 Param 定义了一个"参数"的全部信息,包括:
- 参数名(name)
- 参数类型(class)
- 描述(description)
- 默认值(default value)
- 校验器(validator,用来检查取值是否合法)
这种统一的参数定义方式,保证了:
- 参数有统一的文档描述;
- 参数值可以被自动校验;
- 可以通过通用的方式批量设置和获取参数。
2. 设置参数的几种方式
Flink ML 支持至少两种常见的设置方式:
方式一:调用专用 setter 方法
例如设置 KMeans 的聚类数:
java
KMeans kmeans = new KMeans().setK(3).setSeed(42L);这种方式语义最清晰,也是最常用、最推荐的方式。
方式二:通过参数 Map 批量更新
可以构造一个参数 Map,然后通过工具方法一次性更新:
java
// 伪代码示意
Map<Param<?>, Object> paramMap = new HashMap<>();
paramMap.put(KMeans.K, 3);
paramMap.put(KMeans.SEED, 42L);
ParamUtils.updateExistingParams(paramMap, kmeans);适用场景:
- 从配置文件 / 数据库中读出一批参数,然后统一灌到 Stage 中;
- 或者做自动调参与网格搜索时,要动态调整同一批参数。
3. Estimator 与 Model 的参数继承
一个非常实用的设计:
当你通过
Estimator.fit()生成 Model 时,Model 会自动继承 Estimator 上的参数设置。
这意味着:
java
KMeans kmeans = new KMeans().setK(2).setSeed(1L);
KMeansModel model = kmeans.fit(trainTable);
// 通常不需要再对 model 重复 setK / setSeed除非你刻意要对 Model 做额外参数设置,否则不用再重复一遍参数配置,这在 pipeline/graph 中可以显著减少重复代码。
七、总结与实践建议
这篇文章系统梳理了 Flink ML 的核心概念:
-
Table API:
- Flink ML 的底层基础,适合表达特征表、训练数据表、预测输出表;
- 支持丰富数据类型 + 专门的 Vector 类型;
- 与 DataStream API 无缝转换。
-
Stage 系列(Estimator / AlgoOperator / Transformer / Model):
- Estimator:负责训练,提供
fit(),输出 Model; - AlgoOperator:通用多输入多输出算子,用
transform()表达任意计算; - Transformer:语义上"一条输入对应一条输出"的变换算子;
- Model:带模型数据的 Transformer,可通过
getModelData()/setModelData()管理模型参数。
- Estimator:负责训练,提供
-
Pipeline:
- 线性流水线,本身是一个 Estimator;
fit()训练其中所有 Estimator,生成 PipelineModel;- PipelineModel 的
transform()串行执行所有阶段。
-
Graph:
- DAG 形式的流水线,更适合多路输入、多分支、多汇聚的复杂 ML 拓扑;
GraphBuilder + TableId支持在没有具体 Table 的情况下先定义拓扑结构;GraphModel用于预测阶段的 DAG 执行。
-
参数系统(WithParams & Param):
- 所有 Stage 都支持统一的参数 get/set;
- 支持专用 setter、参数 Map 更新等方式;
- Model 会自动继承 Estimator 的参数配置,避免重复设置。