今日总结
- java随笔录------什么是聚簇索引,什么是非聚簇索引?什么是覆盖索引?
- AI随探录------NLP中RNN到Attention机制的演进
- 代码随想录------n皇后,贪心算法---分发饼干
目录
详细内容
java随笔录
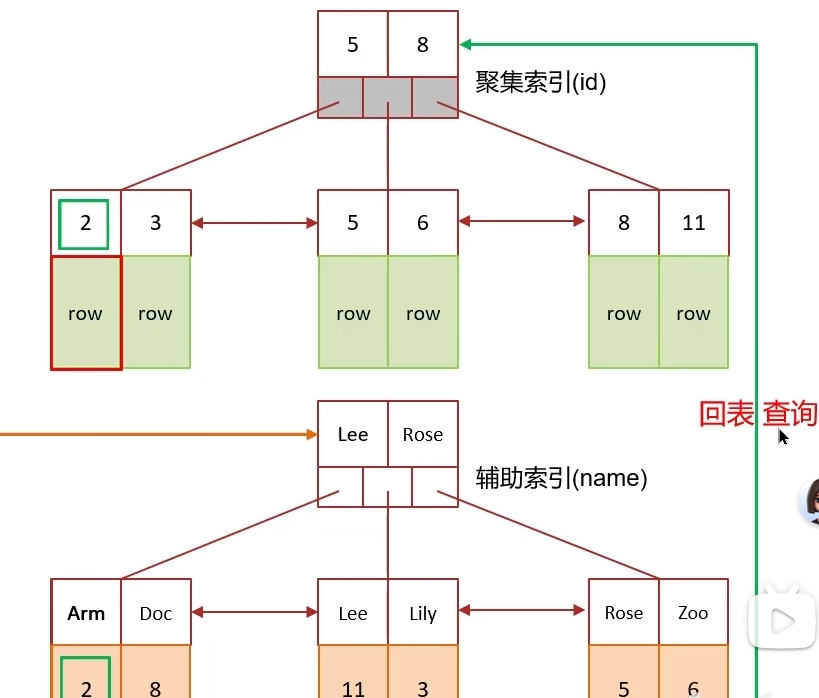
1、什么是聚簇索引,什么是非聚簇索引?
聚集索引,非聚集索引(二级索引) 与回表操作息息相关
聚集索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据,必须有,而且只有一个
二级索引:将数据索引分开存储,索引结构的叶子结点关联的是对应的主键,找到主键值后,到聚集索引中查找整行数据,该过程就叫 回表查询。该索引可以存在多个
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
2、什么是覆盖索引?
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到。
例子如下:
如果一个表中将id设为主键,他即是主键索引,也是聚集索引,将name设置为普通索引。
有三个语句
- select * from user where id = 2;
- select id,name from user where name = 'liliya';
- select id, name ,gender from user where name = 'liliya';
其中a,b属于覆盖索引,因为经过索引查询后,可以找到所有的所需数据。但是c中gender不在索引查询中的范围中,需要进行回表查询,通过二级索引,找到主键id的值,在聚集索引中的叶子节点查找到数据。
因此,覆盖索引是直接走聚集索引查询,一次索引扫描直接返回数据,性能高。但是如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select *
AI随探录
NLP中RNN到Attention机制的演进
1、循环神经网络RNN
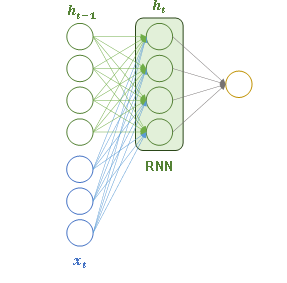
通过隐藏状态传递历史信息,(h_t = tanh(W_{ih} * x_t + W_{hh} * h_{t-1} + b_h)),其中(h_{t-1})是上一时刻的隐藏状态,负责传递历史信息;tanh是激活函数,限制输出范围(-1~1)。仅通过一个循环单元实现时序依赖建模。
但是对于早期时刻的信息难以捕捉,会造成梯度消失或梯度爆炸问题。
通过隐藏状态传递历史信息,(h_t = tanh(W_{ih} * x_t + W_{hh} * h_{t-1} + b_h)),其中(h_{t-1})是上一时刻的隐藏状态,负责传递历史信息;tanh是激活函数,限制输出范围(-1~1)。仅通过一个循环单元实现时序依赖建模。
但是对于早期时刻的信息难以捕捉,会造成梯度消失或梯度爆炸问题。
2、长短期记忆网络(LSTM)
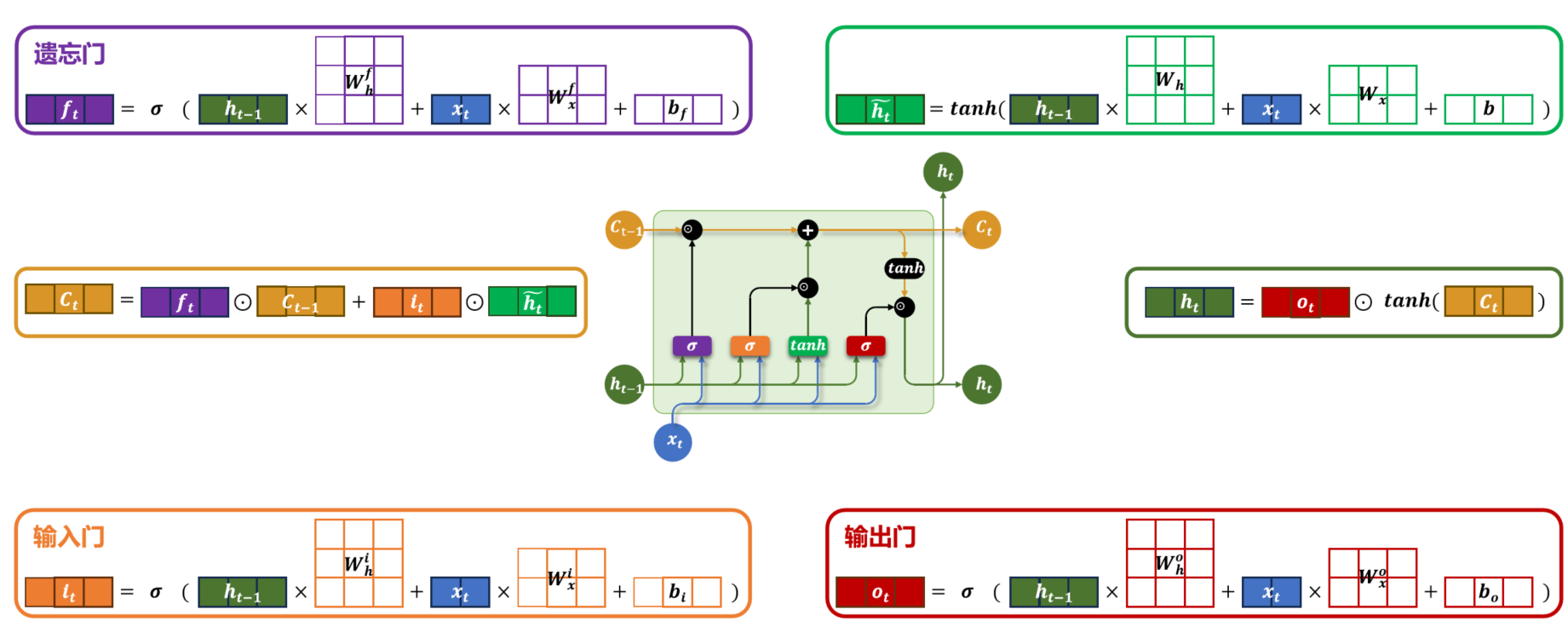
针对 RNN 的 "梯度消失" 和 "长记忆缺失" 问题,提出**结构化记忆单元,**通过三大门控机制(遗忘门、输入门、输出门)精确控制信息的存储更新遗忘。解决了长依赖问题,但是参数数量暴增,训练成本变高,结构变得很复杂。
3、门控循环单元(GRU)
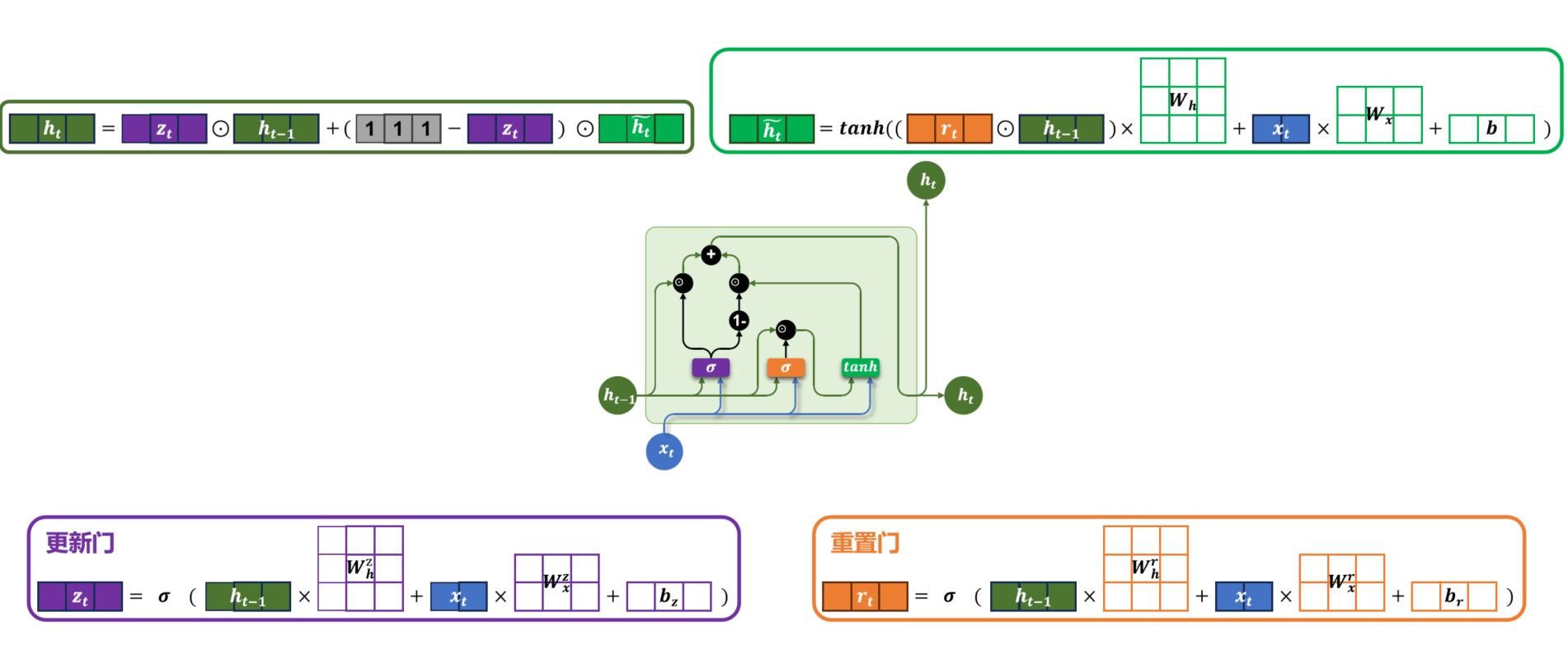
在 LSTM 的基础上简化结构,保留核心门控逻辑,同时减少参数和计算量,将遗忘门和输入门合并为更新门,用重置门替代输出门。
4、Seq2Seq(Encoder-Decoder)模型
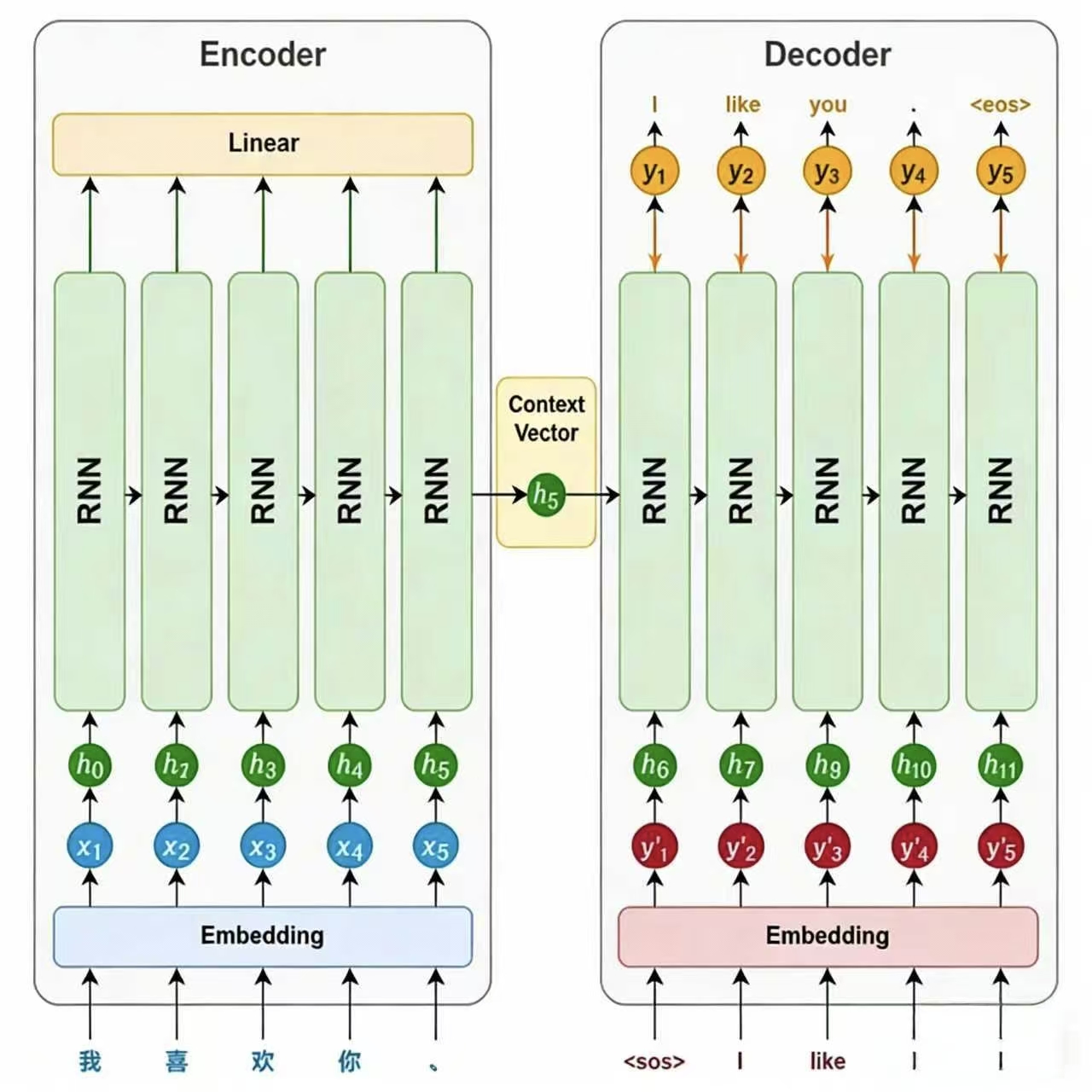
编码器主要由一个循环神经网络(RNN/LSTM/GRU)构成,其任务是将输入序列的语义信息提取并压缩为一个上下文向量。
在模型处理输入序列时,循环神经网络会依次接收每个token的输入,并在每个时间步步更新隐藏状态。每个隐藏状态都携带了截止到当前位置为止的信息。随着序列推进,信息不断累积,最终会在最后一个时间步形成一个包含整句信息的隐藏状态。
这个最后的隐藏状态就会作为上下文向量(context vector),传递给解码器,用于指导后续的序列生成。
解码器主要也由一个循环神经网络(RNN / LSTM / GRU)构成,其任务是基于编码器传递的上下文向量,逐步生成目标序列。
在生成开始时,循环神经网络以上下文向量作为初始隐藏状态,并接收一个特殊的起始标记 <sos>(start of sentence)作为第一个时间步的输入,用于预测第一个 token。
随后,在每一个时间步,模型都会根据前一时刻的隐藏状态和上一步生成的 token,预测当前的输出。这种"将前一步的输出作为下一步输入"的方式被称为自回归生成(Autoregressive Generation),它确保了生成结果的连贯性。
生成过程会持续进行,直到模型生成了一个特殊的结束标记 <eos>(end of sentence),表示句子生成完成。
说明:起始标记和结束标记会在训练数据中显式添加,模型会在训练中学会何时开始、如何续写,以及何时结束,从而掌握完整的生成流程。
5、Attention 机制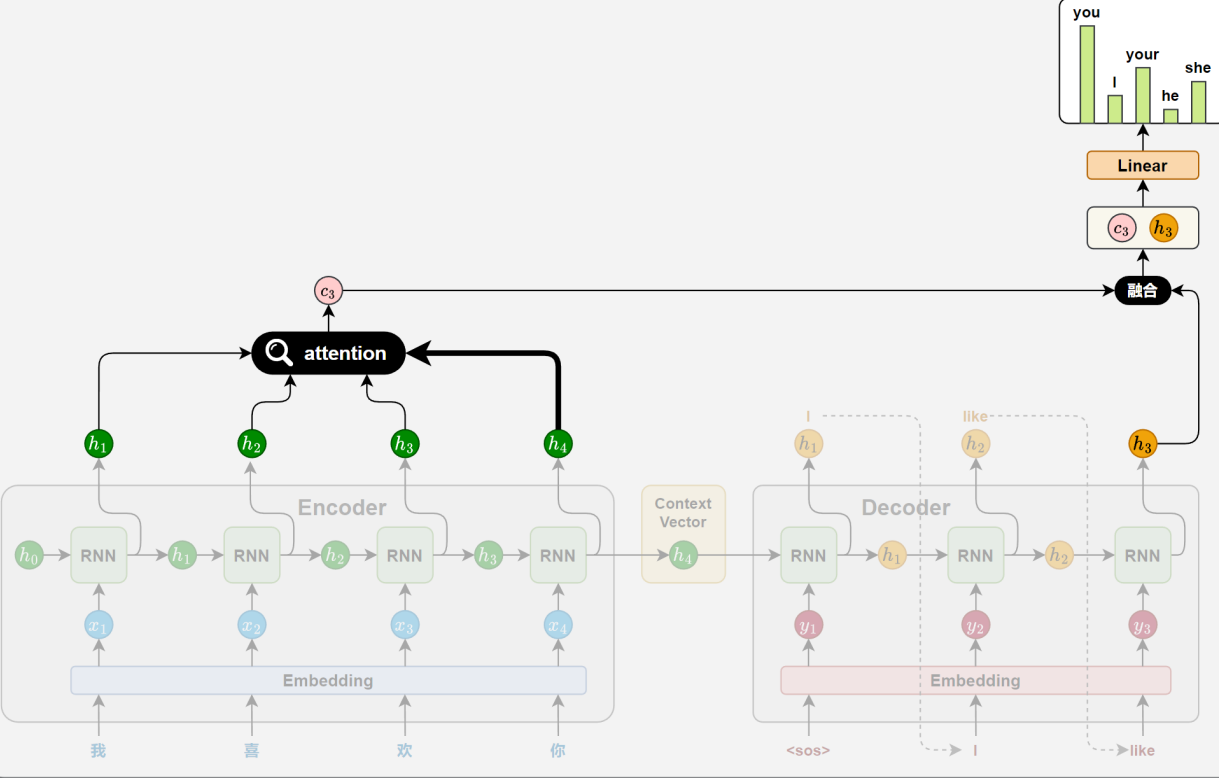
传统的 Seq2Seq 模型中,编码器在处理源句时,无论其长度如何,最终都只能将整句信息压缩为一个固定长度的上下文向量,用作解码器的唯一参考。这种设计存在两个显著问题:
- 信息压缩困难:固定向量难以完整表达长句或复杂语义,容易丢失关键信息;
- 缺乏动态感知:解码器在每一步生成中都只能依赖同一个上下文向量,难以根据不同位置的生成需要灵活提取信息。
为了解决上述问题,研究者引入了 Attention 机制。其核心思想是:
解码器在生成目标序列的每一步时,不再依赖于一个静态的上下文向量,而是根据当前的解码状态,动态地从编码器各时间步的隐藏状态中选取最相关的信息,以辅助当前步的生成。
代码随想录
回溯算法---n皇后
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将
n个皇后放置在n×n的棋盘上,并且使皇后彼此之间不能相互攻击。给你一个整数
n,返回所有不同的 n皇后问题 的解决方案。每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中
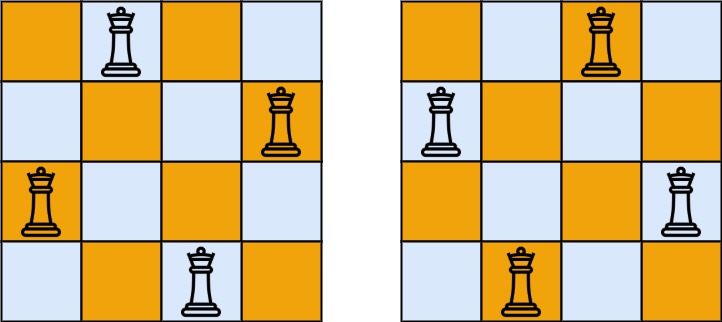
'Q'和'.'分别代表了皇后和空位。示例 1:
输入:n = 4 输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]] 解释:如上图所示,4 皇后问题存在两个不同的解法。示例 2:
输入:n = 1 输出:[["Q"]]
java
class Solution {
List<List<String>> result = new ArrayList<>();
private void back(int n, int row,char[][] chessboard) {
if(row == n) {
result.add(ArraytoList(chessboard));
return;
}
for(int i = 0; i < n; i++) {
if(isValue(row,i,n,chessboard)) {
chessboard[row][i] = 'Q';
back(n,row + 1, chessboard);
chessboard[row][i] = '.';
}
}
}
public List ArraytoList(char[][] chessboard) {
List<String> list = new ArrayList<>();
for (char[] c : chessboard) {
list.add(String.copyValueOf(c));
}
return list;
}
public boolean isValue(int row,int col, int n, char[][] chessboard ) {
for (int i=0; i<row; ++i) {
if (chessboard[i][col] == 'Q') {
return false;
}
}
for (int i=row-1, j=col-1; i>=0 && j>=0; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
for (int i=row-1, j=col+1; i>=0 && j<=n-1; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}
public List<List<String>> solveNQueens(int n) {
char[][] chessboard = new char[n][n];
for (char[] c : chessboard) {
Arrays.fill(c, '.');
}
back(n, 0, chessboard);
return result;
}
}贪心算法------分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子
i,都有一个胃口值g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干j,都有一个尺寸s[j]。如果s[j] >= g[i],我们可以将这个饼干j分配给孩子i,这个孩子会得到满足。你的目标是满足尽可能多的孩子,并输出这个最大数值。示例 1:
输入: g = [1,2,3], s = [1,1] 输出: 1 解释: 你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1,2,3。 虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。 所以你应该输出 1。示例 2:
输入: g = [1,2], s = [1,2,3] 输出: 2 解释: 你有两个孩子和三块小饼干,2 个孩子的胃口值分别是 1,2。 你拥有的饼干数量和尺寸都足以让所有孩子满足。 所以你应该输出 2。
java
class Solution {
public int findContentChildren(int[] g, int[] s) {
reverse(g);
reverse(s);
int sum = 0;
for(int i = 0, j = 0; i < g.length && j < s.length;) {
if(s[j] >= g[i]) {
j++;
sum++;
}
i++;
}
return sum;
}
void reverse(int[] arr) {
Arrays.sort(arr);
for (int i = 0; i < arr.length / 2; i++) {
int temp = arr[i];
arr[i] = arr[arr.length - 1 - i];
arr[arr.length - 1 - i] = temp;
}
}
}