🎯 学习目标
完成本课程后,学习者将能够:
-
LLM 大语言模型概念以及核心特点
-
LLM 工作流程、价值与市场需求
-
LLM 大数据模型对程序员职业影响
-
LLM 应用开发专有名词、交互模式、结合模式介绍
LLM 大语言模型
LLM(Large Language Model,大语言模型) 是一种基于深度学习的人工智能模型,核心目标是理解和生成人类语言,并能完成翻译、问答、创作、代码编写等多样化的语言相关任务。
它的本质是通过海量文本数据训练,学习语言的语法、语义、逻辑甚至常识,从而具备模拟人类语言交互的能力。
核心特点:
规模巨大 :参数量大一般指的是7b100b+,即70亿1000亿+参数,参数其实就是一个浮点数(2字节或4字节),比如3.1415,所以一个7b的模型,本质上就是一坨70亿以上的数字而已。
基于 Transformer 架构 :目前主流 LLM 都基于 Transformer (2017 年由谷歌提出)架构,其核心是 自注意力机制,可以让模型在处理一句话时,同时关注到每个词与其他词的关联(比如 "它" 指代的是前文的哪个对象),从而更准确地理解上下文。
Token:
- Token其实就是文本的片段,是大模型计算长度的单位,对于汉字,可以是字、词、甚至是半个字或者三分之一个字。
- 对于一个仅支持英语的模型,它的词表可以只有a-z26个字母,加上逗号句号空格等标点符号,Token 数可以非常少。
- 汉字字词更多,语义更复杂多样,所以包含的Token 数会更多,很多语言模型都支持多语言,包含各种符号、单词、单词片段等,所以往往会有几十万个 Token 甚至更多。
大语言模型词表: 就是这个模型的所有 Token 映射,每个 Token 有其对应的 id,一般从 0开始,如下:
javascript
"vocab": {
"<unk>": 0, //开头是一些特殊符号
"<|startoftext|>": 1, //这是字节token,如果出现不在词表中的特殊符号会回退到字节表示
"<0x00>": 305,
"<x01>": 306, //下面是正常的英文token,有的表示是单词的开头,没有的是单词中间
"ct": 611,
"_re": 612,
"安徽省": 8560, //有中文token出现
"子和": 28561
}LLM 工作流程
- 输入处理:用户输入文本经过分词器转换为模型可理解的token序列。特殊token(如开始、分隔、结束标记)被添加以指导模型处理。
- 模型推理:Transformer架构通过自注意力机制和前馈神经网络处理token序列,生成每个位置的下一个token概率分布。
- 文本生成:基于模型输出的概率分布,使用采样策略(如温度采样、top-p采样)选择下一个token,以自回归方式生成完整响应。
- 输出后处理:生成的token序列被转换回文本,并进行格式化、清理和安全性检查,确保输出质量与合规性。
- 最后用户接收响应
txt
# 输入处理:
用户输入文本 -> 文本清洗与标准化 -> 分词器 Tokenizer -> 添加特殊标记BOS/SEP/EOS等 -> 转换为Token ID序列
# 模型推理:
Token嵌入层将ID映射为向量 -> 位置编码正弦/学习位置编码 -> Transformer编码器层 -> 自注意力机制 -> 前馈神经网络 -> 残差连接与层归一化 -> 编码器输出
上下文表示
#文本生成
解码器初始输入起始标记 -> Transformer解码器层 -> Token添加到序列 -> 生成完整Token序列
#输出后处理
Detokenization Token转文本 -> 文本后处理 -> 格式化与清理 -> 安全性检查 -> 最终响应输出大语言模型 预测Token机制
- 如何快速预测下一个 token 是什么呢?一种最简单的办法就是基于统计,通过大量数据的统计,找到下一个 token。
- 采集大量文本进行扫描计算,并记录所有片段的输入以及下个文本出现的次数,得到一张巨大的分布表。
- 将输入的文本对照分布表查询,找到所有 token 的出现次数或概率,找到出现次数最大的 token 即为预测结果。
模型训练
月训练指的是将大量文本输入给模型,进而得到模型参数前LLM训练一般用到了大量文本,一般在 2T token 以上
价值与市场需求
通用人工智能(AGI)将是 AI 的终极形态,几乎已成为业界共识。类比之,构建智能体 Agent 则是 AI 工程应用当下的"终极形态。
大模型出现后,Al Agents衍生出一种新的架构模式,将最重要的规划/决策部分或全部交由LLM完成。
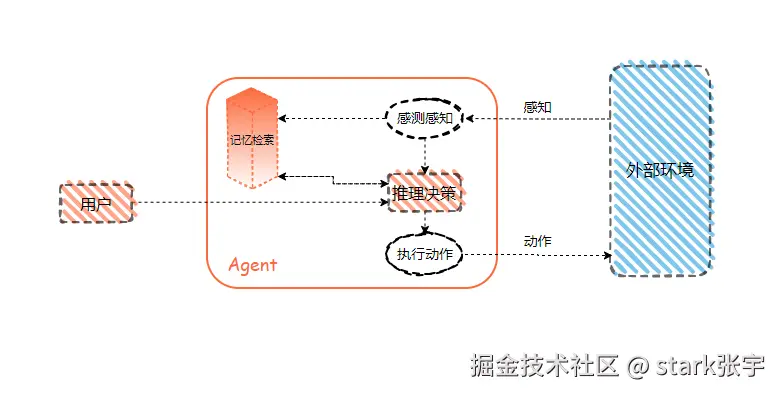
Agent/LLM:智能体指代具有自主性和智能的程序或系统,能够通过感知规划、决策并执行相关任务。
案例:基于Agent/LLM的智能客服
- 企业的传统客服存在效率低、培养成本大、工作压力大、提供服务参差不齐等问题,在线客服是企业和客户沟通的桥梁可以为企业带来更多的商机。
- 利用 LLM+企业知识库搭建 AI智能客服,对比传统客服可以实现智能沟通、无间断工作、智能分析、自动分类、跨语言沟通等。
案例:基于Agent/LLM的数据分析
- 几乎所有企业每天都会产生大量的数据,除了新数据,还有海量的历史沉淀数据,涉及:日志、历史代码、订单、会员信息、行业数据等。
- 这些数据量庞大、结构差异明显、利用率低,导致企业很难精确获知和建立各项数据之间的关联。
- 利用Agent/LLM参与数据的自动分类、信息提取、数据分析等,建立起各项数据之间的关联。
案例:人工智能即服务-AlaaS
- Alas a Service(AlaaS,Al 即服务)是一项非常新颖的变革将 AI视为应用后端服务,让公司发布一款产品变得及其简单,无需投入昂贵的硬件、专业人才或耗时的开发流程。
- 翻译服务=限定的预设 Prompt + LLM 规范化输出
- 自动化运维 =日志采集 + LLM 推理决策 + 工具包
LLM 职业影响
- 技术领先:掌握更高效的Prompt编写技巧,让LLM更清楚你的需求,更高效完成工作上的任务、疑难杂症等。
- 薪资水平:由于LLM是一个相对新兴的领域,人才短缺,具备相关技能的人才往往能够获得更具竞争力的薪酬。
- 扩充职业前景:随着人工智能的发展和普及,LLM应用的前景非常广阔,不一定所有公司都需要训练LLM,但绝大部分公司都会基于LLM开发应用
LLM在软件开发过程中的单点提效
- 智能代码提示
- SQL语句的智能生成
- 重复代码检查
- 跨端代码快速转换
- 静态代码检查与自动修复
- 代码注释生成
- 单元/接口测试代码生成
- 更精准的技术问答
- 代码评审与代码重构
- 失败用例自动分析与归因
AI时代的自动化编程5个等级
- C1:基于当前代码自动补全。
- C2:编写代码时AI可以预测下一行代码。
- C3:基于自然语言生成代码与编程语言的翻译
- C4:高度自动化编程包括自然语言生成代码及注释、自动化测试、编程语言互译、代码补全与生成、调试及检查,
- C5:完全自动编程,AI可以看成是一个任意的软件,甚至无需代码,基于AI本身即可提供对应的服务。
对程序员有什么影响
1、短期影响
- AI可以帮助程序员完成代码的自动化测试、代码审查等重复容易出错的工作,但是自动化测试、代码审查只是程序员的一小部分工作。
- 在创造性问题上,例如在项目的需求分析、设计和策划过程中,需要程序员进行创造性思考和判断,AI技术还没有完全达到这一点。
- 对于目前的AI进展来说,并不会导致程序员的完全失业,而是在一定程度上提高了程序员工作的效率和准确性。
2、长期影响
- 不久的将来AI有望取代一些低水平(比如仅会CURD)的程序员,但是以目前的进展来说,还有一段路需要走。
- 长远的未来,人人都具备编程能力,但是程序员不太应该被单独拿出来讨论,实际上对大模型来说,编程仍然是最具挑战的任务之一。
LLM 应用开发专有名词
LLM 大语言模型
- LLM是基于深度学习技术构建的人工智能模型,由具有数以亿计参数的人工神经网络组成,通过自监督学习或半监督学习在大量无标签文本上上进行训练。
- LLM于2018年左右出现,并在各种任务上表现出色,LLM改变了自然语言处理研究的重点,使其不再是以训练特定任务的专门监督模型为范式。
AIGC AI生成内容
- AIGC(Al-Generated Content)通过对已有数据进行学习和模式识别,以适当的泛化能力生成相关内容的技术。
- AIGC生成的内容很多,涵盖文字、图像、视频、音频、游戏、虚拟人等等。
- AIGC是AI大模型,而ChatGPT则是AIGC在聊天对话场景的-个具体应用。
AGI 人工通用智能
- AGl (Artificial General Intelligence)全称人工通用智能是指能够理解、学习和应用广泛的知识和技能的人工智能系统。
- 以人类角度来看,AGI就是一种能够"思考"和"理解"各种问题的智能生命体,就像人类一样。
Agent 智能代理
- Agent (智能代理)一个能够自主感知环境并采取行动的计Agent算实体,其目标是最大化某种预定义的效用或实现特定的目标。
- AGI可以看成是一种非常高级的Agent,具备广泛适应性和自我学习能力,Agent也是现阶段AGI的最佳实现方式。
Prompt-提示词
- Prompt是指给定的一段文本或问题用于引导和启发人工智能模型生成相关的回答或内容。
- Prompt是目前人类与LLM大语言模型交互的核心方式。
GPT 生成型预训练变换模型
- GPT(Generative Pre-trained Transformer)是一种基于深度学习的大型语言模型。
- GPT模型最初由OpenAI开发,旨在通过训练模型预测下一个单词或字符来学习自然语言的统计规律。
Token 文本基础单元
- Token是指在自然语言处理和文本处理任务中,将文本分解成较小单元的基本单位。这些单元可以是单词、字符、子词或其他语言单位,具体取决于任务和处理方式。
- 大语言模型中的上下文长度计算一般都是基于Token,而不是字符,例如GPT-4的16K上下文意味着传递的消息不能超过16K个Token。
LoRA 插件式微调
- LoRA(Low-Rank Adaptation of LLM)即插件式微调用于对大语言模型进行个性化的特定任务的定制。
- LoRA通过将模型的权重矩阵分解成低秩的相似矩阵,降低了参数空间的复杂性,从而减少微调的计算成本和模型存储要求。
矢量/向量数据库
- 矢量数据库是一种用于存储矢量/向量数据的数据库。
- 矢量数据库可以存储和管理大量的矢量数据例如图像、视频、音频、文本等,同时提供高效检索功能。
数据蒸馏
- 数据蒸馏指将给定的原始大数据集浓缩并生成一个小型数据使得在小数据集上训练出来的模型与原数据集上训练的模型相似。
- 数据蒸馏在深度学习领域被广泛应用,可以帮助将复杂的模型转换成更轻量级的模型,提高模型的鲁棒性和泛化能力。
LLM & AI Agent交互模式
传统人机交互范式的缺点:
- 交互接口复杂繁杂且多样化,要使用多一款软件,要专门花时间去学习,每个软件之间接口差异巨大。
- 人在环境中进行一些行为,会产生各类的数据,涵盖结构化和非结构化数据,而人不能和数据直接发生关系,需要一个中介,这个中介就是软件。
- 处理不同的数据需要不同的软件,而有些软件非专业人士很难上手,比如说PhotoShop。
大模型时代新交互的缺点:
- 过去通过某个应用软件与某种数据进行交互,现在变成人和大模型交互,即大语言模型站到了人机交互的中心位置。
- 本质上还是人和数据的关系,只是由于大模型的出现,应用软件被屏蔽到了幕后。
- 短期来看,LLM可以代替一些应用软件,比如多模态大模型对PhotoShop的取代;长期来看,大模型可能会逐步替代各种功能的软件。
LLM 结合模式
- 嵌入(Embedding)模式:用户通过与AI交流,AI协助完成,如创作小说、音乐、3D内容等,此模式下,AI是执行工具,人类是决策者和指挥者。
- 副驾驶(Copilot)模式:在这种模式下,人类与AI作为合副驾驶作伙伴,共同完成任务,AI提供建议并协助任务,二者互补AI更像知识丰富的伙伴而非工具。
- 智能体(Agent)模式:人类设定目标并提供资源,AI独立完成大部分工作,最后人类监督和评估结果。