在数字化时代,数据已成为企业和组织的核心资产,但如何让非技术人员轻松获取数据 insights 一直是行业难题。传统的 SQL 查询要求使用者掌握专业的编程语言知识,这在很大程度上限制了数据的普及应用。而 Text-to-SQL 技术的出现,让用户可以用自然语言提问,系统自动生成对应的 SQL 语句,极大降低了数据访问的门槛。在这一领域,蚂蚁集团推出的 Agentar-Scale-SQL 凭借其卓越的性能和创新的技术方案,成为行业关注的焦点。
一、Agentar-Scale-SQL:Text-to-SQL 领域的佼佼者
Agentar-Scale-SQL 是蚂蚁集团研发的一套先进 Text-to-SQL 解决方案,旨在通过「编排式测试时扩展」技术提升自然语言到 SQL 转换的准确性和效率。从公开信息来看,它不仅在学术研究上取得了突破,更在实际应用中展现出强大的落地能力。
在权威的 BIRD 排行榜上,Agentar-Scale-SQL 以 81.67% 的执行准确率位居榜首,超过了 AskData + GPT-4o(80.88%)、LongData-SQL(77.53%)等知名方案。这一成绩并非偶然,背后是其在技术架构、模型设计和工程实现上的多重创新。
从项目定位来看,Agentar-Scale-SQL 并非单一工具,而是一套完整的技术体系。它包含了用于生成 SQL 的大模型、处理数据库结构的轻量 schema 引擎、离线数据预处理管道等核心组件,同时还延伸出商业化产品「Data Agent」------ 一款面向企业的 ChatBI 工具,让用户能通过自然语言直接与业务数据交互,无需编写任何代码。
二、核心优势:从技术创新到实用价值
Agentar-Scale-SQL 的竞争力体现在多个维度,既有底层技术的突破,也有贴近实际场景的设计考量。
1. 顶尖的执行准确率
在 Text-to-SQL 领域,执行准确率(EX)是衡量系统性能的核心指标,它代表生成的 SQL 语句能否正确执行并返回符合预期的结果。Agentar-Scale-SQL 在 BIRD 测试集上的 EX 达到 81.67%,这意味着在绝大多数场景下,用户的自然语言提问都能被准确转化为可执行的 SQL。
对比其他方案,这一成绩的优势明显。例如,基于 GPT-4o 的 AskData 方案准确率为 80.88%,而 LongData-SQL 等开源方案则在 77% 左右。更高的准确率意味着更低的人工校对成本,让用户可以更放心地依赖系统生成的结果。
2. 完整的技术生态
Agentar-Scale-SQL 构建了从模型到工具的完整生态。2025 年 11 月,蚂蚁集团发布了 Agentar-Scale-SQL-Generation-32B 大模型,分别在 Hugging Face 和 ModelScope 平台开源,供开发者使用。该模型专注于 SQL 生成任务,经过大规模数据训练,能理解复杂的自然语言问题并生成对应的 SQL 语句。
同时,项目还开源了「轻量 schema 引擎」和「离线数据预处理管道」。轻量 schema 引擎用于提取和简化数据库结构信息,帮助模型更好地理解表、列之间的关系;离线数据预处理管道则能对原始数据进行清洗、转换和索引构建,为后续的 SQL 生成提供高质量输入。
3. 贴近实际场景的设计
与一些仅关注学术指标的方案不同,Agentar-Scale-SQL 充分考虑了工业界的需求。例如,它支持 SQLite 等主流数据库方言,适配企业常用的数据库环境;提供了完整的部署和使用流程,包括环境配置、数据准备、模型推理等步骤,降低了开发者的使用门槛。
此外,项目还推出了商业化产品 Data Agent,将技术能力封装为易用的工具。用户只需在网页上输入自然语言问题,如"上个月销售额最高的三个产品是什么",系统就能自动生成 SQL 并返回结果,整个过程无需专业知识,极大提升了数据查询的效率。
三、技术解析:如何让自然语言精准转化为 SQL?
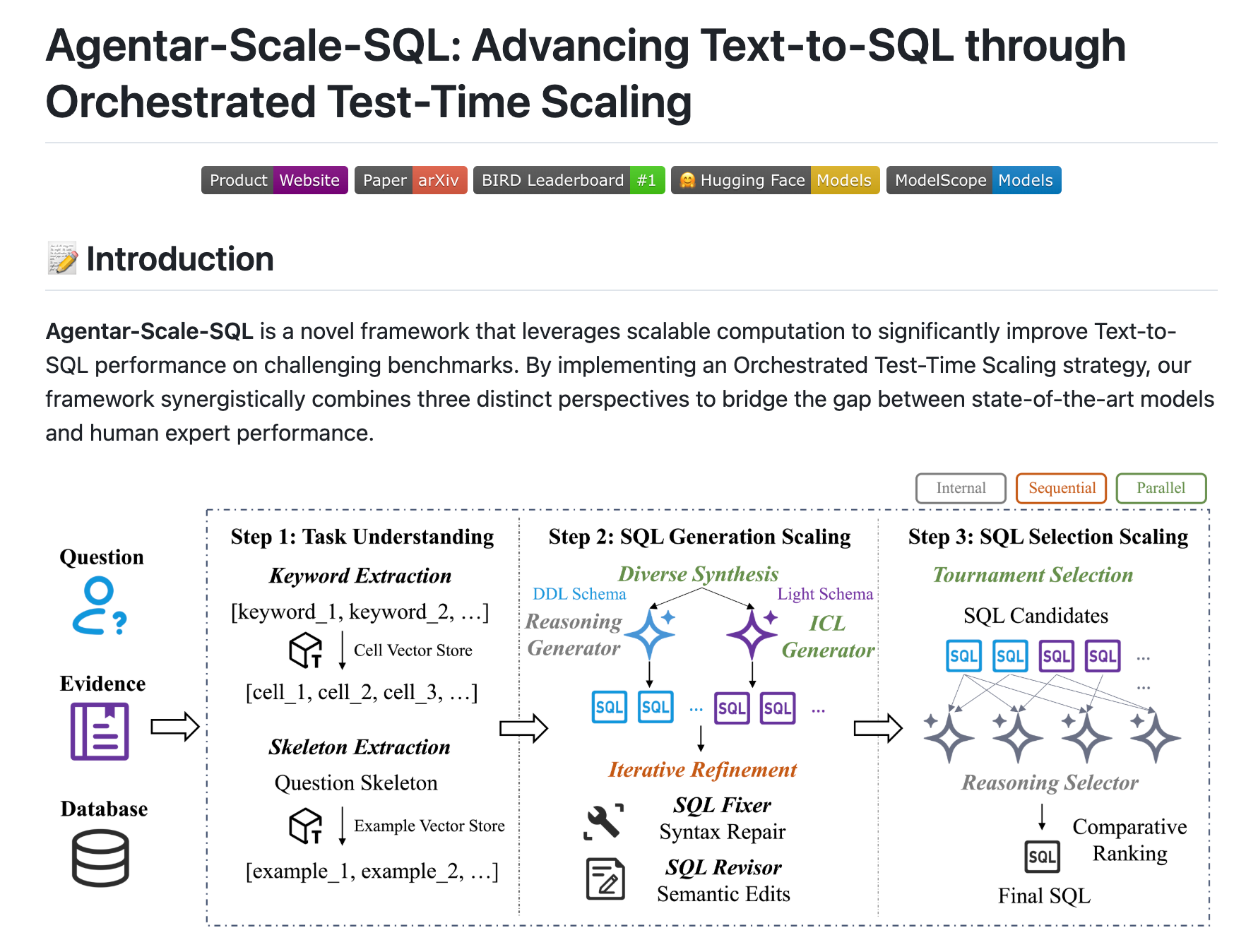
Agentar-Scale-SQL 的高准确率源于其创新的技术架构和精细的工程实现。从技术细节来看,它主要通过以下几个环节实现自然语言到 SQL 的高效转换。
1. 数据预处理:为模型提供高质量输入
数据预处理是提升 SQL 生成准确率的基础。Agentar-Scale-SQL 设计了多步骤的预处理流程,确保模型能获得清晰的数据库结构和相关信息。
首先是「轻量 schema 生成」。通过运行 python -m ScaleSQL.workflows.schema_generation --evaluation_type test 命令,系统会分析数据库中的表、列、数据类型、主键、外键等信息,生成简洁的 schema 描述。例如,它会为每个列添加示例值(如"性别列的示例值:男、女")和描述(如"用户 ID:唯一标识用户的编号"),帮助模型理解字段含义。
其次是「向量数据库构建」。项目使用 SentenceTransformer 模型对训练集中的 SQL 骨架(去除具体值后的抽象结构)和数据库单元格值进行编码,存储到 Chroma 向量数据库中。当处理新问题时,系统能快速检索相似的历史案例,为当前 SQL 生成提供参考。
最后是「BM25 索引构建」。通过运行 bash ddl_schema.sh 脚本,系统会对数据库中的文本内容(如产品名称、类别等)建立 BM25 索引,用于快速匹配自然语言中的实体(如"2023 年""北京")与数据库中的具体值,提升条件过滤的准确性。
2. 模型架构:分层处理复杂问题
Agentar-Scale-SQL 的核心是其分层的模型架构,通过多个模块协同处理自然语言到 SQL 的转换过程。
-
关键词提取模块 :该模块使用大模型(如 Gemini-Flash)从用户问题中提取数据库实体(如"销售额""2024 年")和问题骨架(如"查询 时间 的 指标 最大值")。骨架生成时会将具体值替换为占位符(如
<时间><指标>),保留问题的逻辑结构,为后续 SQL 生成提供指导。 -
SQL 生成模块:基于提取的关键词和骨架,该模块调用多个不同配置的大模型(如 Gemini、GPT-5)生成多个 SQL 候选。例如,有的模型设置较高的温度参数(1.8)以生成更多样的结果,有的则设置较低温度(0.5)以保证稳定性,通过多模型协作提升结果的覆盖性。
-
SQL 修正与选择模块:生成的候选 SQL 会经过修正(如语法检查、逻辑验证)和筛选。系统会模拟执行 SQL,检查是否存在语法错误或逻辑问题,并根据执行结果的合理性选择最优方案。这一过程类似于"多人解题后投票",进一步提升结果的可靠性。
3. 工程优化:提升效率与可扩展性
为了让技术方案能在实际场景中落地,Agentar-Scale-SQL 在工程实现上做了诸多优化。
例如,它使用 vLLM 进行推理加速,通过高效的内存管理和批处理技术,提升大模型的响应速度。在环境配置上,项目提供了清晰的步骤:使用 Conda 创建虚拟环境、安装 PyTorch 等依赖、下载预训练模型,即使是新手也能快速搭建运行环境。
此外,项目采用模块化设计,各组件(如 schema 生成、向量检索、模型推理)之间通过配置文件解耦,开发者可以根据需求替换其中的模块(如改用其他嵌入模型或向量数据库),提升了系统的可扩展性。
四、使用指南:从零开始体验 Agentar-Scale-SQL
对于开发者来说,体验和部署 Agentar-Scale-SQL 的过程并不复杂,只需按照以下步骤操作,即可快速搭建起一套 Text-to-SQL 系统。
1. 环境准备
首先需要创建一个独立的 Python 环境,避免依赖冲突。推荐使用 Conda 工具:
bash
conda create -n ScaleSQL python=3.10
conda activate ScaleSQL接着安装 PyTorch(需适配 CUDA 12.1,以支持 GPU 加速):
bash
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121然后安装项目依赖和 vLLM 推理引擎:
bash
pip install -r requirements.txt
pip install https://github.com/vllm-project/vllm/releases/download/v0.8.5.post1/vllm-0.8.5.post1+cu121-cp38-abi3-manylinux1_x86_64.whl最后下载嵌入模型(用于向量生成):
bash
modelscope download --model sentence-transformers/all-MiniLM-L6-v2 --local_dir ./ScaleSQL/model/all-MiniLM-L6-v22. 数据配置
修改配置文件 ScaleSQL/workflows/config/pipeline_config.yaml,指定数据集路径和列含义文件路径(列含义文件可从 TA-SQL 项目获取,用于补充字段描述):
yaml
dataset_folder: /path/to/your/dataset
column_meaning_path: /path/to/column_meaning.json其中,dataset_folder 需包含数据库文件(如 SQLite 格式)和表结构信息,column_meaning.json 则存储各字段的详细描述(如"order_date:订单创建日期,格式为 YYYY-MM-DD")。
3. 预处理执行
完成环境和数据配置后,执行预处理步骤:
生成轻量 schema:
bash
python -m ScaleSQL.workflows.schema_generation --evaluation_type test执行后会生成 bird_test_light_schema.json,包含简化后的数据库结构信息。
处理训练集示例并写入向量数据库:
bash
ANONYMIZED_TELEMETRY=False python -m ScaleSQL.workflows.train_skeleton_process该步骤会将训练集中的 SQL 骨架编码后存入 Chroma 数据库,用于后续相似案例检索。
处理数据库单元格值并写入向量数据库:
bash
ANONYMIZED_TELEMETRY=False python -m ScaleSQL.workflows.database_cell_process --evaluation_type test构建 BM25 索引(需 Java 环境支持):
bash
bash ddl_schema.sh完成后,系统会生成 bird_test_ddl_schema.json,包含用于文本检索的索引信息。
4. 运行与测试
预处理完成后,即可启动系统进行测试。通过调用相关 API 或脚本,输入自然语言问题(如"查询 2024 年第三季度每个地区的销售总额"),系统会返回生成的 SQL 语句及执行结果。
对于开发者,项目提供了详细的代码注释和模块化接口,可以根据需求进行二次开发,例如集成到自有数据平台或调整模型参数以适配特定场景。
五、成果与影响:从学术突破到产业价值
Agentar-Scale-SQL 的推出,不仅在学术领域推动了 Text-to-SQL 技术的发展,也为产业界提供了一套可落地的解决方案。
在学术方面,项目团队于 2025 年 9 月在 arXiv 上发表了论文《Agentar-Scale-SQL: Advancing Text-to-SQL through Orchestrated Test-Time Scaling》,详细阐述了其技术方案。论文中提出的"编排式测试时扩展"思路,通过多模型协作、多阶段处理的方式提升 SQL 生成准确率,为相关研究提供了新的方向。
在产业应用上,商业化产品 Data Agent 已在多个场景落地。例如,零售企业的市场人员可以通过自然语言查询不同区域的销售数据,无需等待数据分析师支持;金融机构的风控人员能快速检索客户的交易记录,提升风险识别效率。这种"人人可用数据"的模式,极大释放了数据的价值。
此外,项目的开源策略也促进了技术普及。Agentar-Scale-SQL-Generation-32B 模型、轻量 schema 引擎等组件的开源,让中小企业和研究机构可以低成本使用先进技术,推动了 Text-to-SQL 领域的整体发展。
六、未来展望:持续进化的 Text-to-SQL 技术
根据项目的发布路线图,Agentar-Scale-SQL 团队计划在未来推出更多功能。例如,即将开源的 Agentar-Scale-SQL-Selection-32B 模型将专注于 SQL 候选的筛选,进一步提升结果的准确性;同时,针对闭源模型的 SQL 候选生成代码、基于微调模型的生成代码也将逐步开放,丰富开发者的选择。
从技术趋势来看,Text-to-SQL 正朝着更智能、更易用的方向发展。未来,Agentar-Scale-SQL 可能会融合多模态输入(如表格、图表)、支持更复杂的逻辑推理(如嵌套查询、窗口函数),并进一步优化响应速度,让自然语言与数据库的对话更接近人类交互的体验。
对于企业而言,随着数据量的爆炸式增长,高效的数据访问工具将成为核心竞争力之一。Agentar-Scale-SQL 及其背后的技术理念,无疑为这一需求提供了可行的解决方案,推动数据驱动决策从口号走向实践。
结语
Agentar-Scale-SQL 的出现,不仅是技术上的一次突破,更代表了"让数据触手可及"的理念。从学术研究到产业应用,从模型开源到产品落地,它构建了一条完整的技术链路,让 Text-to-SQL 从实验室走向了真实世界。
对于开发者,它提供了一套可复用的技术框架,降低了构建高性能 Text-to-SQL 系统的门槛;对于企业,它让数据查询变得简单高效,释放了非技术人员的数据分析能力;对于整个行业,它推动了自然语言处理与数据库技术的融合,为智能化数据交互开辟了新的可能。
随着技术的不断迭代,我们有理由相信,未来人与数据的对话将更加自然、高效,而 Agentar-Scale-SQL 无疑会在这一进程中扮演重要角色。