1. 纹理尺寸是4的倍数
1. 纹理尺寸是4的倍数
csharp
1).内存对齐
计算机(CPU/GPU)读取内存时不是逐字节读取, 而是按固定"对齐块"(比如4字节、16 字节、64 字节)批量读取 ------ 这是硬
件层面的优化, 能大幅提升访问效率
csharp
Unity在导入非4倍数纹理时, 即使现代GPU支持非对齐读取, 也会在内存中自动填充到最近的2的幂次尺寸(比如 127×127
→ 128×128), 这一步本身就会增加导入时间和内存占用
csharp
2).GPU 的纹理块(Tile)处理机制
GPU渲染纹理时, 会将纹理分割成固定大小的块(Tile)并行处理(常见块尺寸: 4×4、8×8、16×16), 这是GPU并行计算的核
心逻辑(每个SP流处理器处理一个块)
csharp
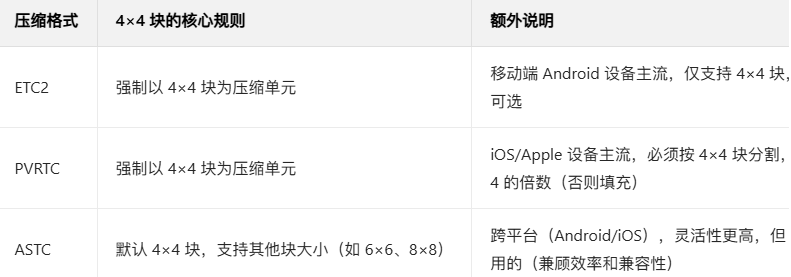
3).纹理压缩格式
Unity常用的纹理压缩格式(ETC2、ASTC、PVRTC)"基于4×4块压缩/解压", 先把纹理图像分割成一个个「4×4 像素的独立小
方块(Block/Tile)」, 再以这个4 × 4块为最小压缩/解压单元------ 每个块单独编码(压缩)、单独解码(解压), GPU硬件也针
对4×4块的并行处理做了深度优化
csharp
若纹理尺寸是4的倍数(如: 128 × 128): 整张纹理能被完整分割为4 × 4块(128 / 4 = 32, 即 32 × 32个4 × 4 块), 无
任何零碎块
若纹理尺寸非4的倍数(如: 127 × 127)最后一行 / 列会出现不完整的4 × 4块(比如 1×127、127×1), 压缩算法会先把纹
理填充到最近的4的倍数尺寸(128×128), 再分割块压缩; 解压后还要把填充的像素裁剪掉 ------ 多了填充 + 裁剪两步, 既浪
费存储空间, 又增加处理开销