上一篇写了日常工作中如何与AI对话完成需求,然而,随着我们试图将 AI 更深入地集成到复杂的项目和日常工作流中,这种纯对话模式的弊端也日益凸显。你是否也曾经历过:
- 上下文丢失 :在连续多轮对话后,AI 开始"遗忘"之前的关键设定,导致后续生成的内容偏离了最初的目标。一个简单的需求变更,可能需要你从头开始解释一遍。
- 缺乏可追溯的"唯一事实源":需求和规范散落在长长的聊天记录中,难以管理和审查。当项目需要交接或团队协作时,这段对话历史几乎无法作为有效的技术文档。
- 低效的迭代与评审 :对于一个复杂的变更,你可能需要花费数十轮对话进行微调。这个过程难以被团队其他成员评审,因为它缺乏一个明确、稳定的计划基线。
- 结果不稳定且难以复现 :同样的提示,两次运行的结果可能完全不同。当出现问题时,你很难定位是哪一步的"沟通"出了偏差,也无法稳定复现整个生成过程。
本文将向你介绍一种全新的、基于规范驱动的 AI 开发工作流------OpenSpec 。它通过将需求转化为结构化的规范(Specs),为我们和 AI 之间建立了一份明确的"契约"。这套工作流旨在将开发过程从混乱的对话,转变为一个清晰、可控的工程实践。 由于 OpenSpec 的官方文档已经对其理念和用法做了详尽的阐述,本文将重点结合实践中的痛点,将其核心概念和流程进行翻译和解读,帮助你快速理解并上手这套工作流,让 AI 成为你真正可靠的开发"合伙人"。
OpenSpec 是什么?它的核心价值是什么?
简单来说,OpenSpec 是一套规格驱动 (Spec-driven) 的 AI 开发工作流。它通过引入一个轻量级的规范流程,确保在AI动手写代码之前,人类开发者和 AI 就"要做什么"和"怎么做"达成共识。
它的核心价值体现在以下几个方面:
-
告别模糊,拥抱确定性 :将散落在聊天记录中的需求,固化为结构化的规范 (Specs) 。AI 的输出不再是基于模糊的上下文猜测,而是基于这份明确的"契约",从而提供可预测、可审查的结果。
-
专为真实项目(1→n)设计 :与许多适用于全新项目(0→1)的工具不同,OpenSpec 通过分离事实源 和变更提案来管理复杂性。
openspec/specs/:存放项目当前状态的"唯一事实源"。openspec/changes/:存放每一次独立的、提议中的变更。
这使得修改现有功能或跨多个模块的更新变得异常清晰。
-
清晰的变更追踪:每个功能变更(包含提案、任务列表、设计决策和规范增量)都被组织在同一个文件夹下。这让代码审查(Code Review)和项目追溯变得前所未有的简单。
-
轻量且兼容你已有的工具 :它无需 API 密钥 ,配置极简。最棒的是,它原生支持 GitHub Copilot, Cursor, Amazon Q 等几十种主流 AI 工具,通过简单的斜杠命令(如
/openspec-proposal)即可集成。
OpenSpec 的核心工作流
- 起草 (Draft) :你用自然语言向 AI 提出一个需求,AI 会为你生成一个结构化的变更提案,包含初步的规范和任务清单。
- 评审与对齐 (Review & Align):这是关键的人机协作环节。你和 AI 一起迭代这份提案,细化需求、补充验收标准,直到规范完全符合你的预期。这个过程有一个明确的"中间产物",便于团队评审。
- 执行 (Apply):实施引用已批准规格的任务。
- 归档 (Archive) :所有任务完成后,执行归档命令。此时,本次变更中涉及的规范更新会自动合并回
openspec/specs/目录,成为项目新的"事实源",为下一次变更提供准确的上下文。
如何在你的项目中使用 OpenSpec (上手实践指南)
让我们通过一个真实的例子,看看如何在项目中引入并使用 OpenSpec。
第一步:安装与初始化
首先,确保你已安装 Node.js,然后在你的项目根目录下执行以下命令:
bash
# 全局安装 OpenSpec CLI
npm install -g @fission-ai/openspec@latest
# 在你的项目目录中初始化
cd your-project
openspec init选择你正在用的AI工具,确认好之后会为你创建 openspec/ 目录结构和相应的配置文件:
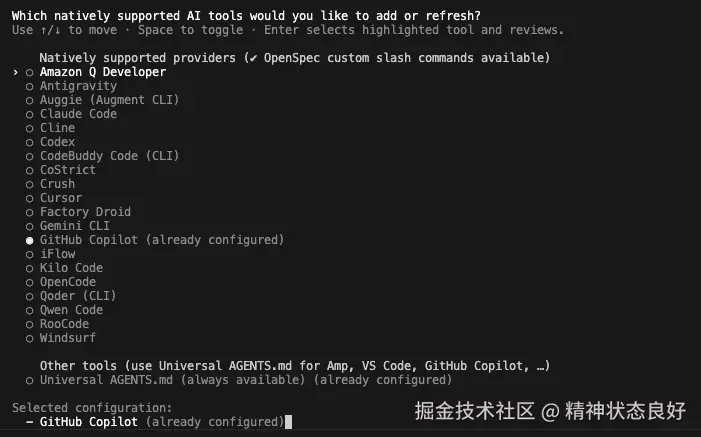
第二步:起草你的第一个变更提案
现在,你可以直接在 AI 助手的聊天框里提出你的需求。
你 :
/openspec-proposal(或者用自然语言:"创建一个 OpenSpec 提案"),为用户个人资料页添加按角色和团队搜索的过滤器。
AI 会理解这个指令,并为你创建如下的文件结构。注意:你无需手动创建任何文件!
csharp
openspec/
└── changes/
└── add-profile-filters/ # AI 创建的变更文件夹
├── proposal.md # 变更的目标和原因
├── tasks.md # AI 生成的实现步骤清单
└── specs/
└── profile/
└── spec.md # 描述本次变更的"规范增量"第三步:评审、对齐与迭代
在 AI 写代码前,先审查它生成的计划。你可以使用命令行工具查看:
csharp
# 查看所有活跃的变更
openspec list
# 查看具体变更的详细内容
openspec show add-profile-filters如果发现规范不够完善,可以直接在对话中要求 AI 修改:
你:这份规范看起来不错,但请为角色和团队过滤器添加具体的验收标准和场景描述。
AI 会自动更新 .../specs/profile/spec.md 和 tasks.md 文件。这个迭代过程确保了最终执行方案的准确性。
第四步:执行与归档
当你对规范和任务列表感到满意后,就可以让 AI 开始干活了。
你 :
/openspec-apply add-profile-filters(或者:"开始执行 add-profile-filters 这个变更")
AI 会根据 tasks.md 开始编写代码、修改文件,并像一个真正的开发者一样,完成一项任务后打一个勾。
所有任务完成后,最后一步是归档。
你 :
/openspec-archive add-profile-filters(或者:"归档这个变更")
AI 会执行归档命令,将 add-profile-filters/specs/ 中的规范增量合并到 openspec/specs/ 中,完成整个闭环。你的项目知识库也随之更新,为下一次 AI 协作做好了准备。
结语
说到底,OpenSpec 解决的就是那个我们都头疼的问题:AI 记性太差,聊着聊着就跑偏了。
我们都体验过,为了一个小功能和 AI 反复拉扯几十个回合,最后生成的代码还是得自己大改。这不叫提效,这叫"AI 陪聊"。
OpenSpec 的价值就在于,它强迫我们和 AI 在动手前"立下字据"。这份"字据"(就是 specs 和 tasks)让 AI 没法耍赖忘事,也让我们自己想得更清楚。你不再是一个"提示词保姆",而是一个真正的架构师,把图纸交给一个(虽然不知疲倦但有点傻的)施工队。
所以,别把它想得太复杂。它就是一个简单的约定,让你能把 AI 当成一个真正的初级程序员来用,而不是一个聊天机器人。下次再开发新功能或者改 bug 时,试试用它来开个头,你会发现,省下来的时间和精力,绝对值得。