目录
引入Flume
在现代大数据系统中,应用程序、服务器和网络设备每时每刻都在产生海量的日志数据(如点击流、交易记录、系统日志等)。这些数据通常分散在不同的机器上,需要被可靠、高效、实时地收集起来,并传输到像HDFS、HBase、Kafka这样的集中存储或处理系统中进行分析。
传统方法(如使用scp、脚本拷贝)在数据量剧增时面临诸多挑战:
- 可靠性差:网络或目标系统故障易导致数据丢失。
- 效率低下:无法满足实时或准实时收集需求。
- 扩展性差:难以应对数据源和数据量的动态增长。
- 缺乏统一管理:配置分散,运维复杂。
Flume应运而生,它正是为了解决海量日志数据的采集、聚合和传输问题而设计的分布式系统。
Flume定义
Apache Flume 是一个高可用、高可靠、分布式的海量日志采集 、聚合 和传输系统。
其设计理念基于流式数据流,具有以下特性:
- 可靠性:提供端到端的可靠性保障(通过事务机制)。
- 可扩展性:水平扩展架构,支持添加更多的代理(Agent)。
- 可管理性:配置驱动,易于管理和监控。
- 高性能:能够处理来自多个数据源的海量数据。
- 声明式配置:无需编写复杂代码,通过配置文件即可定义数据流。
Flume架构及组件
Flume的核心是Agent。一个Agent是一个JVM进程,它是Flume数据流的基本工作单元。复杂的流可以通过多个Agent级联形成。
Agent内部三大组件
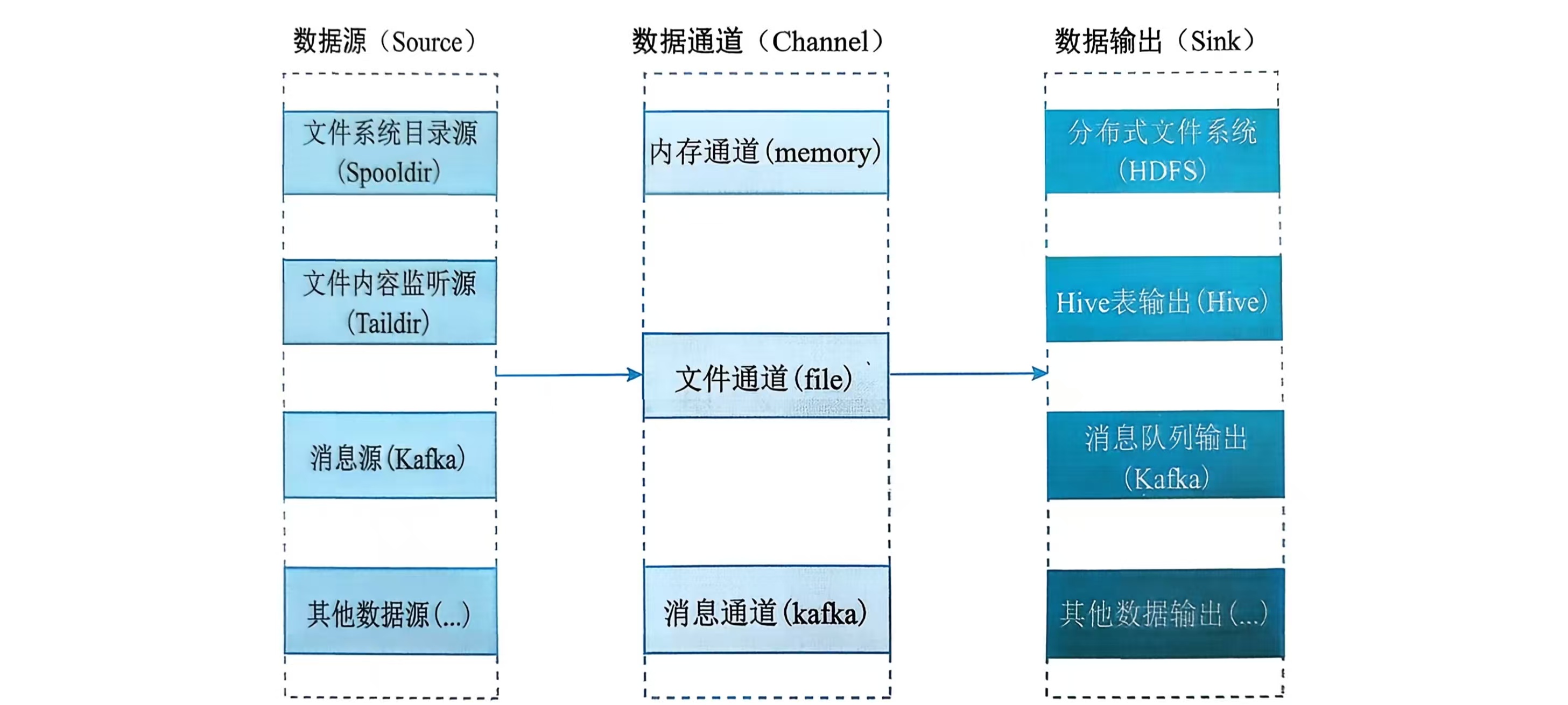
①Source (源)
职责:从数据发生器(如Web Server、日志文件)接收或抓取数据。
工作机制:主动轮询数据源或被动等待数据推送。
常见类型:
- exec:执行一个命令(如tail -F),采集命令输出。
- netcat:监听指定端口,接收TCP/UDP数据。
- avro:监听Avro端口,接收来自其他Flume Agent的数据,用于构建多级流。
- spooldir:监控一个目录,采集其中新增的文件。
- kafka:从Kafka主题中消费消息作为数据源。
②Channel (通道)
职责:是Source和Sink之间的缓冲区。临时存储Event,直到被Sink消费。
作用:解耦Source和Sink的速率差异,提供可靠性。
常见类型:
- Memory Channel:将事件存储在内存队列中。吞吐量高,但故障时可能丢失数据。
- File Channel:将事件持久化到本地磁盘。可靠性高,但速度较慢。
- JDBC Channel:使用嵌入式数据库存储事件,实验性功能。
- Kafka Channel:使用Kafka作为缓冲,兼具高吞吐和持久性。
Sink (汇)
职责:从Channel中取出事件,并将其传输到下一个目的地或最终存储系统。
工作机制:定期轮询Channel,批量取出事件进行传输。
常见类型:
- logger:将事件作为日志信息输出到控制台(主要用于调试)。
- hdfs:将事件写入Hadoop HDFS,支持文本、序列文件等多种格式。
- avro:将事件发送到指定的Avro端口,通常用于传递给下一个Flume Agent。
- hbase:将事件写入HBase数据库。
- kafka:将事件发布到Kafka主题。
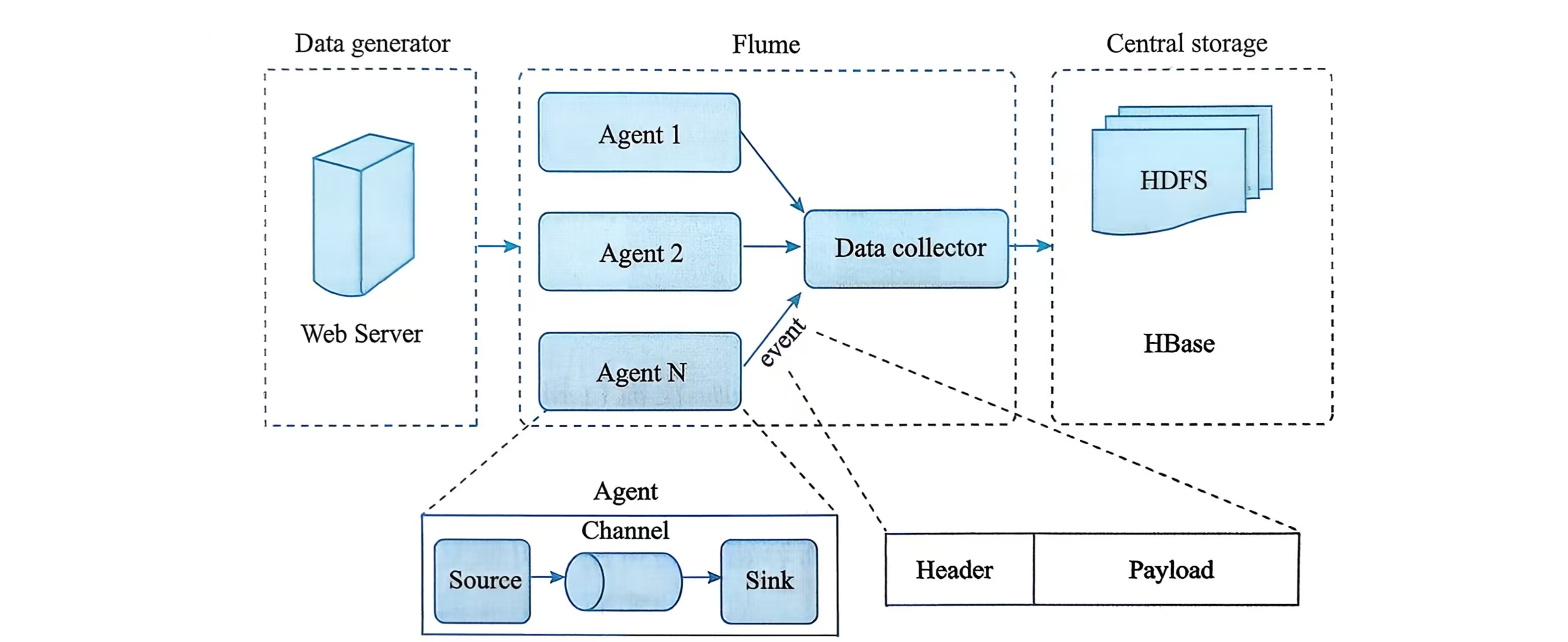
数据模型Event
Event是Flume传输的基本数据单元。
一个Event由Header(头信息)和Body(负载)组成。
- Header:一个Map<String, String>结构,用于存放元数据(如来源、类型、优先级等),可用于路由和过滤。
- Body:一个字节数组,承载实际的数据负载(如一行日志内容)。
多Agent流与复用
多级串联:多个Agent可以连接起来,形成复杂的数据流管道(例如:Agent1(收集) -> Agent2(聚合) -> HDFS)。
- 扇入:多个第一层Agent可以将数据汇聚到一个第二层Agent,实现日志聚合。
- 扇出 :一个Agent的Sink可以将数据同时发往多个目的地(如同时写入HDFS和Kafka)。通过Sink组和选择器(复制或多路复用选择器)实现。
Flume采集流程
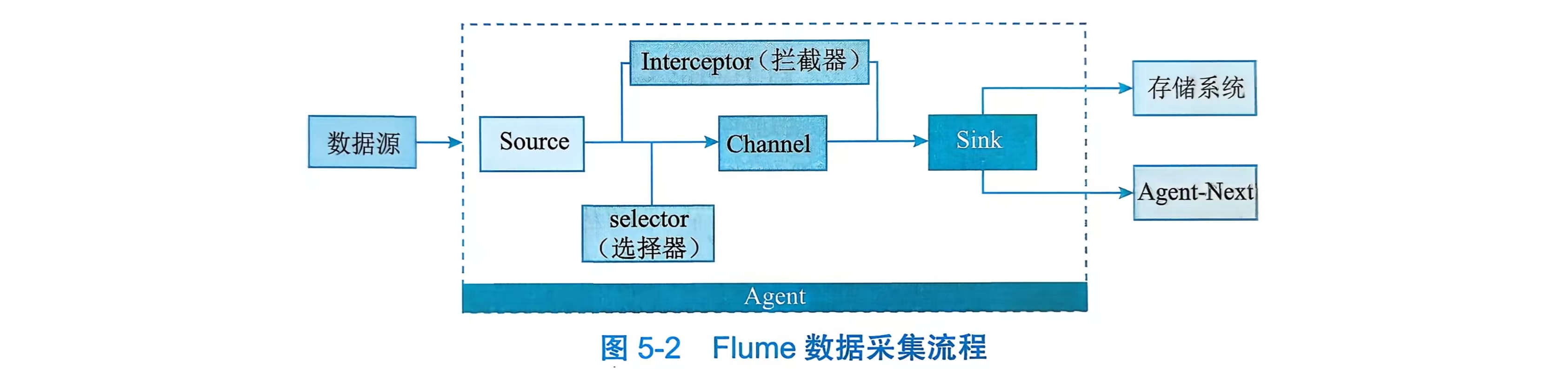
- 数据输入:数据源→Source
- 数据源(比如日志文件、消息队列等)产生的数据,首先会被 Flume 的Source组件接收。
- Agent 内部流转:Source→Interceptor→Selector→Channel
- 数据进入 Source 后,会在 Agent 内部经过以下组件处理:
-
Interceptor(拦截器):对数据做预处理(比如过滤、格式转换、添加标记),可以有多个拦截器按顺序执行。
-
Selector(选择器):决定数据要发送到哪个Channel(如果有多个 Channel 的话);默认是 "复制所有数据到所有 Channel",也可以自定义规则(比如按数据内容分流)。
-
Channel(通道):是 Agent 内部的 "临时存储缓冲",负责缓存数据(避免 Source 和 Sink 速度不匹配导致数据丢失),常见的有内存 Channel、文件 Channel 等。
-
数据输出:Channel→Sink→目标系统
- Channel 中的数据会被Sink组件消费,最终发送到目标系统:
- Sink 从 Channel 中读取数据,然后将数据输出到存储系统(比如 HDFS、HBase)或下一个 Agent(Agent-Next),实现跨 Agent 的分布式数据传输。
简单总结就是:数据源 → Source → (Interceptor预处理)→ (Selector选Channel)→ Channel缓存 → Sink输出 → 存储系统/下一个Agent
使用Flume
Flume的使用精髓在于编写*.conf配置文件。
运行
# 1.创建配置文件
vi job.conf
# 2.启动Agent(最常用命令)
bin/flume-ng agent \
--conf conf \ # 配置文件目录
--conf-file job.conf \ # 你的配置文件
--name a1 \ # Agent名称(必须和配置文件里一致)
-Dflume.root.logger=INFO,console # 控制台输出日志
# 3.后台运行(生产环境)
nohup bin/flume-ng agent --conf conf --conf-file job.conf --name a1 &Source
①执行命令
# 实时监控日志文件(最常用)
agent.sources.src.type = exec
agent.sources.src.command = tail -F /var/log/application.log
# 执行任意shell命令
agent.sources.src.command = /bin/bash -c "cat /tmp/data.txt"②监控目录
# 监控目录,有新文件就采集
agent.sources.src.type = spooldir
agent.sources.src.spoolDir = /data/logs # 监控目录
agent.sources.src.fileSuffix = .COMPLETED # 处理完的文件加后缀
agent.sources.src.deletePolicy = never # 不删除原文件③网络端口
# 监听端口,接收网络数据(测试用)
agent.sources.src.type = netcat
agent.sources.src.bind = localhost
agent.sources.src.port = 44444④接收其他Flume数据
# 接收其他Agent发来的数据
agent.sources.src.type = avro
agent.sources.src.bind = 0.0.0.0
agent.sources.src.port = 41414Channel
①Memory Channel(内存,性能好)
agent.channels.ch.type = memory
agent.channels.ch.capacity = 10000 # 最大存10000个事件
agent.channels.ch.transactionCapacity = 1000 # 每次事务处理1000个②File Channel(文件,更可靠)
agent.channels.ch.type = file
agent.channels.ch.checkpointDir = /data/checkpoint # 检查点目录
agent.channels.ch.dataDirs = /data/channel # 数据存储目录③ Kafka Channel(用Kafka当缓冲)
agent.channels.ch.type = org.apache.flume.channel.kafka.KafkaChannel
agent.channels.ch.kafka.bootstrap.servers = kafka1:9092
agent.channels.ch.kafka.topic = flume-channelSink
① Logger Sink(输出到控制台,调试用)
agent.sinks.sk.type = logger② HDFS Sink(写入HDFS,最常用)
agent.sinks.sk.type = hdfs
agent.sinks.sk.hdfs.path = hdfs://namenode:8020/flume/events/%Y-%m-%d/%H
agent.sinks.sk.hdfs.filePrefix = data-
agent.sinks.sk.hdfs.rollInterval = 3600 # 1小时切一个新文件
agent.sinks.sk.hdfs.rollSize = 134217728 # 128MB切一个新文件
agent.sinks.sk.hdfs.rollCount = 0 # 不按事件数切文件③ Kafka Sink(写入Kafka)
agent.sinks.sk.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.sk.kafka.bootstrap.servers = kafka1:9092,kafka2:9092
agent.sinks.sk.kafka.topic = mytopic④ Avro Sink(发给其他Flume)
agent.sinks.sk.type = avro
agent.sinks.sk.hostname = 192.168.1.100 # 目标机器IP
agent.sinks.sk.port = 41414 # 目标端口Interceptor
用作做数据处理
# 添加时间戳
agent.sources.src.interceptors = i1
agent.sources.src.interceptors.i1.type = timestamp
# 添加主机名
agent.sources.src.interceptors = i2
agent.sources.src.interceptors.i2.type = host
agent.sources.src.interceptors.i2.hostHeader = hostname
# 还可以用户自定义拦截器:构建maven项目并添加flume依赖包
# 多个拦截器按顺序执行
agent.sources.src.interceptors = i1 i2
agent.sources.src.interceptors.i1.type = timestamp
agent.sources.src.interceptors.i2.type = host常用命令与操作
①启动命令
# 基础启动
bin/flume-ng agent -n a1 -c conf -f job.conf
# 带日志输出
bin/flume-ng agent -n a1 -c conf -f job.conf -Dflume.root.logger=INFO,console
# 后台启动
nohup bin/flume-ng agent -n a1 -c conf -f job.conf > flume.log 2>&1 &②监控查看
# 查看运行状态(如果开启了监控)
curl http://localhost:41414/metrics
# 查看进程
ps aux | grep flume
# 查看日志
tail -f logs/flume.log③停止Agent
# 找到进程ID并停止
ps -ef | grep flume
kill [PID]
# 或者用pkill
pkill -f flume配置文件
基本结构
# 1. 定义组件
[agent名].sources = [source名]
[agent名].channels = [channel名]
[agent名].sinks = [sink名]
# 2. 配置Source
[agent名].sources.[source名].type = [类型]
[agent名].sources.[source名].[其他属性] = [值]
# 3. 配置Channel
[agent名].channels.[channel名].type = [类型]
[agent名].channels.[channel名].[其他属性] = [值]
# 4. 配置Sink
[agent名].sinks.[sink名].type = [类型]
[agent名].sinks.[sink名].[其他属性] = [值]
# 5. 绑定
[agent名].sources.[source名].channels = [channel名]
[agent名].sinks.[sink名].channel = [channel名]选择组合
| 场景 | Source类型 | Channel类型 | Sink类型 |
|---|---|---|---|
| 测试/学习 | netcat或exec | memory | logger |
| 采集日志文件 | spooldir | file | hdfs |
| 实时监控日志 | exec | memory | hdfs |
| 高可靠性采集 | spooldir | file | hdfs |
| 数据传输给Kafka | exec或spooldir | memory或kafka | kafka |
示例1:本地日志→HDFS
# 定义Agent a1的各个组件名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置Source (r1):监控目录 /var/log/applogs/
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /var/log/applogs/
a1.sources.r1.fileHeader = true
# 配置Channel (c1):使用文件通道,更可靠
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/flume/data/checkpoint
a1.channels.c1.dataDirs = /opt/flume/data/data
# 配置Sink (k1):写入HDFS
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://namenode:8020/flume/events/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = logs-
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.rollInterval = 3600 # 每隔1小时滚动生成新文件
a1.sinks.k1.hdfs.rollSize = 134217728 # 文件达到128MB滚动
a1.sinks.k1.hdfs.rollCount = 0 # 不按事件数量滚动
a1.sinks.k1.hdfs.fileType = DataStream # 文本格式
a1.sinks.k1.hdfs.writeFormat = Text
# 将Source和Sink绑定到Channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1示例2:实时tail日志→HDFS
# 实时监控日志文件变化
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# Exec Source实时监控
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/nginx/access.log
# 内存通道(实时性要求高)
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
# 写入HDFS
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop102:8020/flume/nginx/%Y-%m-%d/%H
a1.sinks.k1.hdfs.filePrefix = access
a1.sinks.k1.hdfs.rollInterval = 3600 # 每小时一个文件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1示例3:多级Agent架构
# Agent1(收集层)
agent1.sources = src1
agent1.channels = ch1
agent1.sinks = sink1
agent1.sources.src1.type = exec
agent1.sources.src1.command = tail -F /app/logs/app.log
agent1.channels.ch1.type = memory
agent1.sinks.sink1.type = avro
agent1.sinks.sink1.hostname = 192.168.1.200 # 发给聚合层
agent1.sinks.sink1.port = 41414
# Agent2(聚合层)
agent2.sources = src2
agent2.channels = ch2
agent2.sinks = sink2
agent2.sources.src2.type = avro # 接收agent1的数据
agent2.sources.src2.bind = 0.0.0.0
agent2.sources.src2.port = 41414
agent2.channels.ch2.type = file
agent2.sinks.sink2.type = hdfs
agent2.sinks.sink2.hdfs.path = hdfs://hadoop102:8020/flume/events/%Y-%m-%d