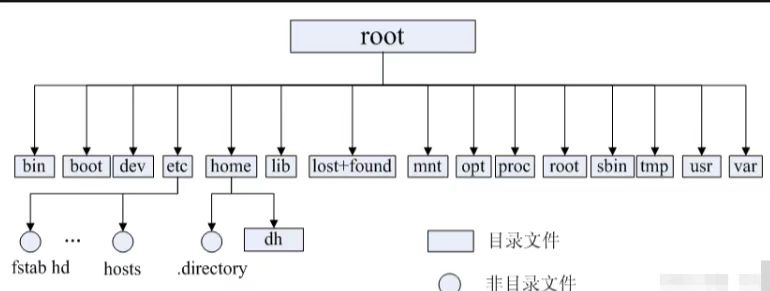
1.软硬链接
1.1 基本认知
硬链接:同一个文件的「多个文件名」,共享同一个inode(相当于给文件起别名)。
软链接(符号链接):一个「特殊文件」,内容是目标文件的路径(相当于Windows的快捷方式)。
1.2 软链接
1.2.1 软链接的建立
cpp
ln -s 文件名1 文件名2 //软的英文就是soft使用ln -s就可以给文件建立软链接,上面相当于给文件名1建立软连接,文件名2是文件名1的软链接。
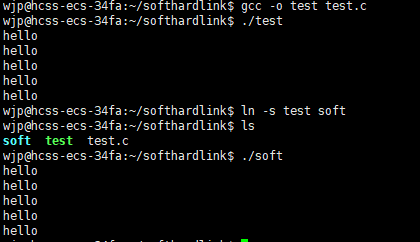
给test可执行程序建立软链接soft,执行soft和test得出来的结果是一样的。
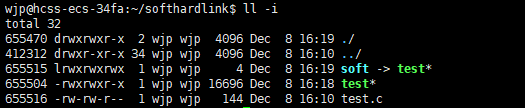
通过查看文件的inode发现它们的inode值并不一样,所以它们是两个不同的文件,并且软链接的文件内容很小
1.2.2 软链接的解除
cpp
unlink
rm软链接的解除可以通过
- rm删除文件
- unlink解除链接关系
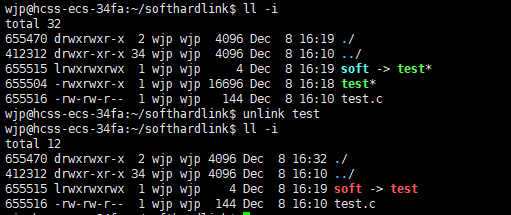
1.2.3 软链接的实现原理
软链接又称为符号链接,它是一个单独存在的文件,拥有属于自己的 inode 属性及相应的文件内容,不过在软连接的 Data block 中存放的是源文件存放的地址,因此软连接很小,并且非常依赖于源文件。
因此如果源文件被删除了,那么在执行软连接文件时,其中的地址就是一个无效地址(目标文件已丢失),此时就会报错 **No such file or directory,**假设只是单纯的删除软连接文件,那么对源文件的内容没有丝毫影响,
1.2.4 应用场景
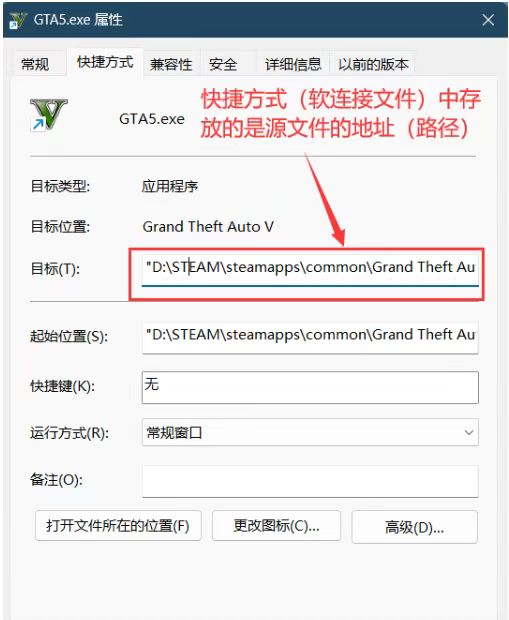
Windows 桌面上的快捷方式就相当于一种软链接,大小只有几十或者几百字节,里面存放的就是可执行程序的地址,有的人以为将快捷方式(软链接)文件删除了,就是在 "卸载" 软件,其实不是,如果想卸载软件,需要将其源文件相关文件夹全部删除。
1.3 硬链接
1.3.1 硬链接的建立
cpp
ln 文件名1 文件名2 
通过ln建立硬链接,同样可以达到执行结果一样的效果。
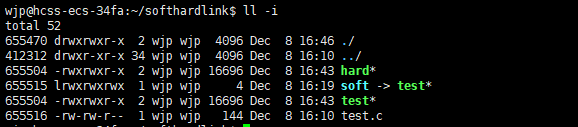
可以看到硬链接和链接的对象的inode值是一样的,内容大小也一样。
1.3.2 硬链接的解除
cpp
unlink
rm硬链接的解除可以通过
- rm删除文件
- unlink解除链接关系
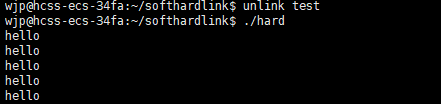
可以看到哪怕删除了硬链接的链接对象,硬链接还是可以执行,软链接就不行。
1.3.3 硬链接的实现原理
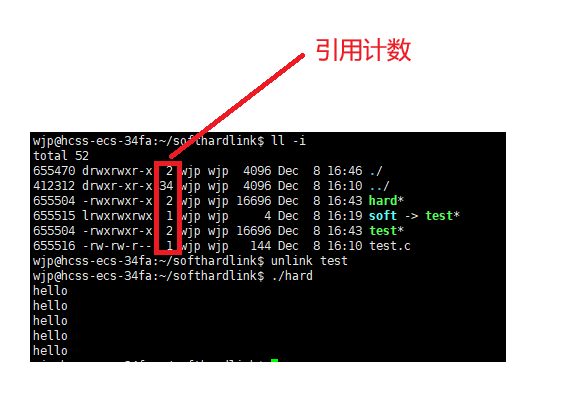
因为硬链接的方法是一种引用计数的实现,在每一个文件的inode里面会有一个引用计数的东西,也就是这个inode是多个文件共享的,当删除一个文件,是删除文件名和inode的对应关系,然后对文件的inode里面的引用计数--,当等于0时,这个inode里面的数据才会被删除。
上一节博客介绍过,目录的inode里面存储的是目录的属性,和目录下的文件和inode的映射,所以建立硬链接,也就是在当前目录的inode里面增加文件名和指向的文件的inode编号的映射关系,对inode里面的引用计数++。
1.3.4 应用场景
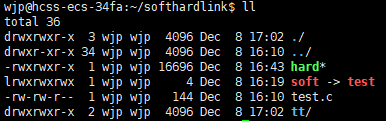
可以看到我们新建一个目录的引用计数就是2,这是因为目录下面都会有**./** 和**../** 两个文件,一个指向当前目录,一个指向上级目录,所以tt目录就是有自己和目录下的./指向,所以引用计数为2,**./**也就是一种硬链接。
1.4 目录的软硬链接
为了避免因用户的误操作而导致的目录环状问题,规定用户不能手动给目录建立硬链接关系,只能由 OS 自动建立硬链接,比如新目录后,默认与上级目录和当前目录建立硬链接文件,在当目录下创建新目录后,当前目录的硬链接数 + 1
目录可以软链接都是不可以硬链接:
- 防止循环引用:如果允许硬链接目录,可能会形成循环(例如,目录 A 链接到目录 B,目录 B 又链接回目录 A),这会导致程序像 find 等工具无法正确处理,可能会进入死循环。
- 破坏目录结构:目录在文件系统中是树状结构,允许硬链接会让目录结构变得复杂,不再是树形的,而是可能变成一个图,导致文件系统变得混乱。
- 防止错误操作:目录的操作(如删除)需要谨慎。如果允许硬链接目录,删除一个目录时可能会影响其他目录,导致文件系统出现错误或者数据丢失。
2 动静态库
库分为 动态库 和 静态库
常见的库文件:stdio.h、stdlib.h、string.h 等
Linux 中,.a 后缀为静态库,.so 后缀为动态库,Windows 中,.lib 后缀为静态库,.dll 后缀为动态库,虽然不同环境下的后缀有所不同,但其工作原理是一致的。
库命名:
比如libstdc++.so.6,去掉前缀跟后缀,最终库名为 stdc++
ldd + 程序名:查看程序的链接情况
- 静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库
- 动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
- 一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码
- 在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)
- 动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
2.1 库的作用
所以,库文件到底有什么用?
提高开发效率
系统已经预装了 C/C++ 的头文件和库文件,头文件提供说明,库文件提供方法的实现
- 头和库是有对应关系的,需要组合使用
- 头文件在预处理阶段就已经引入了,链接的本质就是在链接库,简言之,如果没有库文件,那么你在开发时,需要自己手动将 printf 等高频函数编写出来,因此库文件可以提高我们的开发效率,比如 Python 中就有很多现成的库函数可以使用,效率很高
语法提示是如何做到的?安装开发环境
实际上是在安装编译器、开发语言配套的库和头文件,编译器的 语法提示功能来源于头文件**(语法提示其实就是搜索)**
我们在写代码时,开发环境是怎么知道语法错误或其他错误的?
编译器有命令行模式,还有其他自动化模式,编写代码时,不断进行主动编译,排查错误
2.2 静态库的制作
mymath.c
cpp
#include"mymath.h"
int myerrno=0;
int add(int x,int y)
{
return x+y;
}
int sub(int x,int y)
{
return x-y;
}
int mul(int x,int y)
{
return x*y;
}
int div(int x,int y)
{
if(y==0)
{
myerrno=1;
return -1;
}
return x/y;
}mymath.h
cpp
#pragma once
#include<stdio.h>
extern int myerrno;
int add(int x,int y);
int sub(int x,int y);
int mul(int x,int y);
int div(int x,int y);main.c
cpp
#include"mymath.h"
#include<stdio.h>
int main()
{
int n=add(1,2);
printf("%d\n",n);
int m=sub(2,1);
printf("%d\n",m);
int i=mul(1,2);
printf("%d\n",i);
int j=div(2,1):
printf("%d\n",j);
return 0;
}2.2.1 静态库的打包
静态库的打包主要分为以下两步:
1.将源文件进行 预处理->编译->汇编,生成可链接的二进制 .o 文件。
2.通过指令将 .o 文件打包为静态库。
cpp
gcc -c mymath.c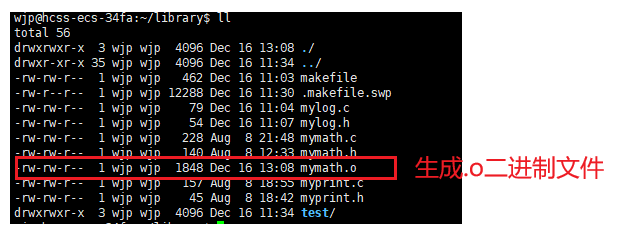
cpp
ar -rc libmymath.a mymath.oar是生成静态库的指令,rc:replace,create,有就替换,没有就创建
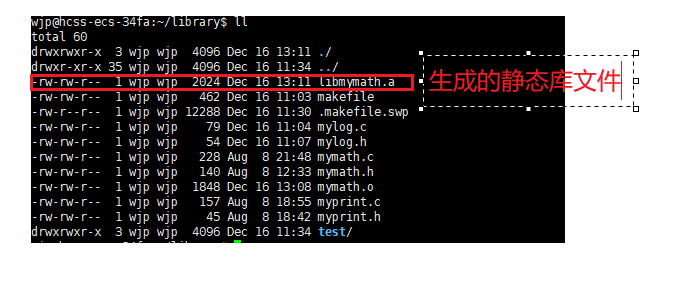
一句话总结:静态库原理也就把那些.c 文件生成.o 然后把这些打包(用 ar 命令) 生成.a,最后和你自己的 main.c 生成的.o 结合成了 exe
2.2.3 静态库的连接
1.通过指定路径连接静态库
对于第三方库,库里面并不知道路径和库名,需要我们去告诉编译器。
cpp
gcc -o a.out main.c -I ./mylib/include -L ./mylib/lib -lmymath对于自己写的的第三库的使用,需要标注三个参数:
-I(大i) 所需头文件的路径 需要将所需头文件的路径加上
-L(大l) 所需库文件的路径 这里加的是库文件的路径
-l(小l) 待链接静态库名 所需要链接的静态库名字,去掉头部和尾部,中间部分就是静态库名字
ps:这里把库头文件放入到mylib目录的include目录,库文件放入到mylib目录的lib目录下。

2.将头文件和静态库文件安装到系统目录中
/usr/include存放系统头文件
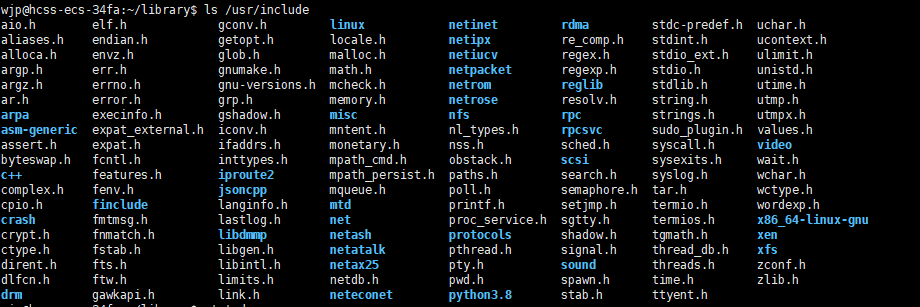
/lib64存放64位库文件

将第三方库添加到系统头文件中和库文件里面
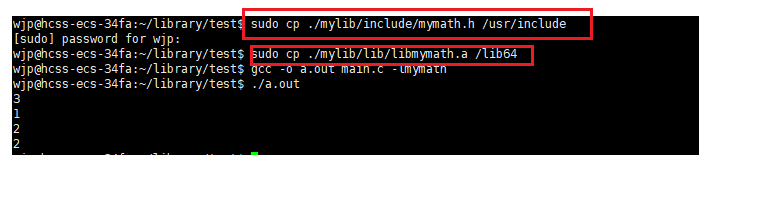
注意: 将自己写的文件安装到系统目录下是一件危险的事(导致系统环境被污染),用完后记得手动删除。
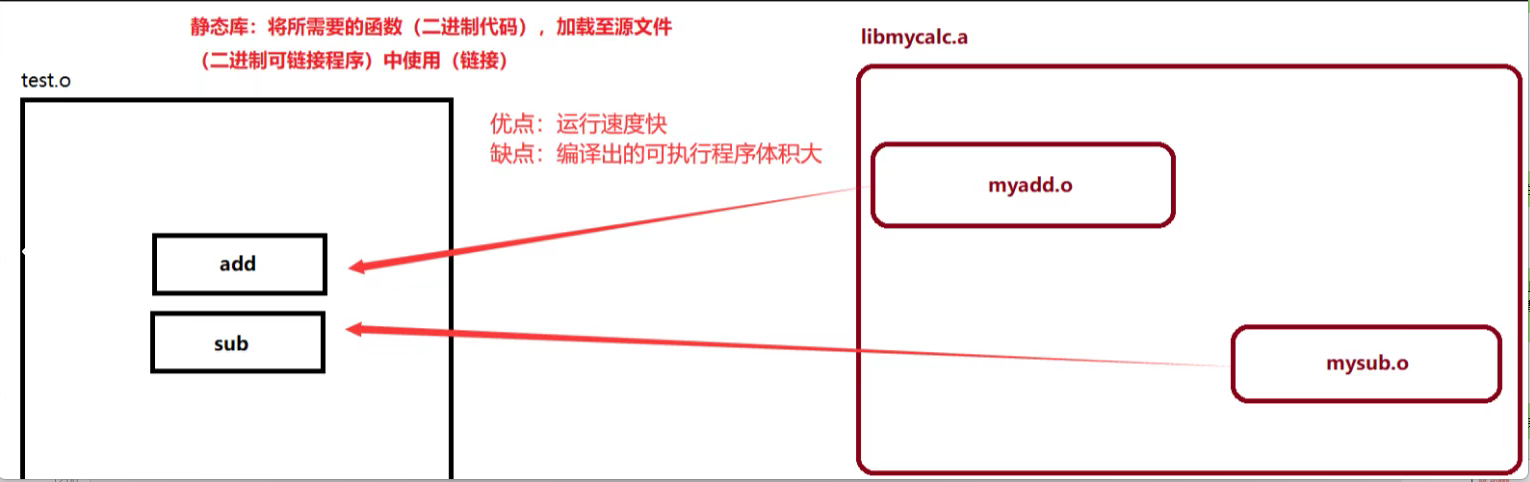
因为静态文件是会把自己的库文件内容拷贝到主函数里面的,所以哪怕在编译之后,把静态库删除了都没有关系,还是可以运行。
3.在系统头文件和库文件下建立软连接
(动态库也可以,操作放在动态库)
2.3 动态库的制作
mylog.c
cpp
#include"mylog.h"
void rog(const char*info)
{
printf("warning :%s\n",info);
}mylog.h
cpp
#pragma once
#include<stdio.h>
void rog(const char*);main.c
cpp
#include"mylog.h"
#include"myprint.h"
int main()
{
print();
rog("hello hello\n");
return 0;
}2.3.1 动态库的打包
动态库不同于静态库,动态库中的函数代码不需要加载到源文件中,而是通过 与位置无关码 ,对指定函数进行链接使用
动态库的打包也同样分为两步:
- 编译源文件,生成二进制可链接文件,此时需要加上 -fPIC 与位置无关码
- 通过 gcc/g++ 直接目标程序(此时不需要使用 ar 归档工具)
cpp
gcc -c -fPIC myprint.c mylog.c
将所有的 .o 文件打包为动态库(借助 gcc/g++)
cpp
gcc -o libmymethod.so mylog.o myprint.o -shared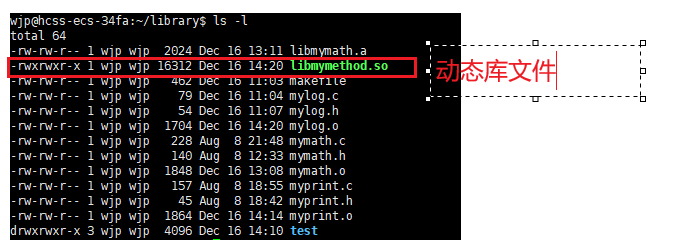
2.3.2 动态库的连接

可以看到我们告诉编译器去哪里找头文件,去哪理找库文件,都是还是显示库文件没有找到?
那为什么静态库就找得到呢?
因为静态库在运行的时候,已经把库里面代码和数据拷贝一份到程序里面,最终合并得到可执行代码,所有操作系统也就不需要找到库文件的位置了,所有的代码和数据已经在里面了。
但是动态库不同,动态库是共享复用和延迟加载,运行到库文件里面的内容是,操作系统才会去动态库里面去查找,所以也需要告诉操作系统动态库的位置,不需要告诉头文件的位置,编译器会记录头文件的位置。
2.3.2 操作系统连接动态库的方法:
1.通过添加环境变量
添加动态库路径至 LD_LIBRARY_PATH 环境变量中
cpp
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/wjp/library/test/mylib/lib
2.拷贝到系统默认的库文件路径/usr/lib/x86_64-linux-gnu/ld-2.31.so下
操作可以按照静态库的操作
ps:静态库的搜索路径是有包含/usr/lib64的,但是动态库是没有的,需要添加到
/usr/lib/x86_64-linux-gnu中
3.将动态库的软连接文件存入系统目录下
在/usr/lib/x86_64-linux-gnu创建软连接
cpp
sudo ln -s /home/wjp/library/test/mylib/lib/libmymethod.so /usr/lib/x86_64-linux-gnu
4.更改配置文件的内容
进入到/etc/ld.so.conf.d 这个路径 在里面创建文件,然后存放自己库的路径,文件名字要以.conf 结尾,关机了也不会消失。
3.使用makefile便于生成
cpp
1 dy-lib=libmymethod.so
2 static-lib=libmymath.a
3 .PHONY:all
4 all: $(dy-lib) $(static-lib)
5 $(static-lib):mymath.o
6 ar -rc $@ $^
7 mymath.o:mymath.c
8 gcc -c -o $@ $^
9 $(dy-lib):mylog.o myprint.o
10 gcc -shared -o $@ $^
11 mylog.o:mylog.c
12 gcc -fPIC -c -o $@ $^
13 myprint.o:myprint.c
14 gcc -fPIC -c -o $@ $^
15 .PHONY:clean
16 clean:
17 rm -rf *.o *.a *.so mylib
18 .PHONY:output
19 output:
20 mkdir -p mylib/include
21 mkdir -p mylib/lib
22 cp *.h mylib/include
23 cp *.a mylib/lib
24 cp *.so mylib/lib
25 4.两个小问题
1.动态库为什么叫共享库
从宏观上面来说,当一个进程运行时,比如一个可执行程序,它需要用到对应的库时,磁盘中就会把动态库的内容加载到物理内存中,通过页表来映射,在虚拟地址中共享区有一部分就是用来映射动态库的,当你的正文代码需要用到动态库时,就去去共享区中去运行,最后再返回即可,所以所有的代码都是在虚拟地址空间中运行的。当另一个进程也需要使用到动态库时,那么它得页表也映射一份出来,指向动态库,所以动态库也就叫做共享库。
2.动态库是被共享的,那么一个变量被多个进程使用,会不会出现进程中间干扰?
物理内存以页来做划分,每个页都会一个结构体,里面有一个引用计数,当动态库里面的变量被多个进程使用时,为了避免影响进程之间的使用,操作系统发现结构体里面的引用计数不为 1, 那么对应的页里面的数据就会发生写时拷贝,写实拷贝以页为单位。