文章目录
- 〇、预训练的作用
- 一、模型整体结构
- [1. 输入表示 (Input Representation)](#1. 输入表示 (Input Representation))
-
- [Segment Embeddings](#Segment Embeddings)
- [Position Embeddings](#Position Embeddings)
- [2. Transformer Encoder结构](#2. Transformer Encoder结构)
- 二、预训练任务
- 三、Bert的现有局限性
BERT (Bidirectional Encoder Representations from Transformers) 是由Google在2018年提出的预训练语言模型,它彻底改变了自然语言处理领域。
BERT的核心创新在于:
- 双向编码:与传统的从左到右或从右到左的单向模型不同,BERT能够同时利用上下文信息
- Transformer架构:基于Transformer的Encoder部分,能够并行处理序列
- 预训练+微调:先在大量无标注数据上预训练,再在特定任务上微调
论文链接:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
〇、预训练的作用
预训练语言模型(Pre-trained Language Model, PLM)是指在大规模无标注文本语料上提前训练好的语言模型,其核心是通过学习通用的语言规律、语义知识和上下文关联,为下游各类 NLP 任务提供 "知识底座",无需从零训练模型。
训练分为 "预训练" 和 "微调" 两个阶段:
预训练阶段:在海量无标注文本(如维基百科、书籍、网页语料)上,通过设计特定任务(如 Masked LM、下一句预测、自回归生成等)让模型学习语言的底层规律(语法、语义、实体关系、上下文依赖等);
微调阶段:将预训练好的模型参数作为初始值,用少量标注数据针对具体下游任务(如文本分类、命名实体识别、机器翻译)进行微调,快速适配任务需求。
核心作用
-
解决"数据稀缺"问题,降低标注成本
传统NLP模型需要大量标注数据才能训练出好效果(比如做情感分析需要上万条标注好的评论),但现实中很多任务(如专业领域的文本分类、小众语言处理)标注数据稀缺。
预训练模型已在海量无标注数据中学习了通用语言知识,微调时仅需少量标注数据(甚至几百条)就能达到不错的效果,大幅降低标注成本和时间。
-
捕捉通用语言规律,提升模型泛化能力
预训练过程中,模型会学习到:
- 语法结构(如主谓宾关系、修饰词与中心词的搭配);
- 语义关联(如"医生"与"医院"、"手机"与"充电"的关联,多义词在不同上下文的含义);
- 世界知识(如"北京是中国的首都"、"大象是哺乳动物"等常识);
这些通用知识让模型在面对未见过的文本时,也能做出合理判断,泛化能力远优于从零训练的模型。
-
统一NLP任务框架,简化模型设计
传统NLP任务需要为每个任务设计专属模型(比如文本分类用CNN/RNN,机器翻译用Seq2Seq),而预训练语言模型提供了统一的"底座":
- 无论下游任务是分类、匹配、生成还是抽取,都可以通过微调预训练模型实现,无需重新设计网络结构;
- 例如BERT通过调整输出层,可直接用于文本分类(取
[CLS]向量做分类)、命名实体识别(对每个token做标签预测)、问答(预测答案的起止位置)等任务,极大简化了NLP系统的开发流程。
-
突破任务上限,提升模型性能
预训练模型凭借海量语料和强大的架构,能捕捉到传统模型无法学习的深层语义信息:
- 比如理解复杂的歧义句("我看见拿着望远镜的人")、长文本的上下文依赖(如长篇文档中的实体指代);
- 在各类NLP基准测试(如GLUE、SuperGLUE)中,预训练模型的性能远超传统方法,甚至达到或接近人类水平。
-
支持低资源语言与专业领域适配
通过在特定领域的语料(如医疗、法律、金融文本)上继续预训练(即"领域自适应预训练"),预训练模型能快速掌握专业术语和领域知识,解决低资源领域/语言的NLP任务难题。
预训练语言模型的典型代表
- 自编码模型(双向上下文):BERT、RoBERTa、ALBERT(擅长理解类任务,如分类、抽取);
- 自回归模型(单向上下文):GPT系列、XLNet(擅长生成类任务,如文本生成、机器翻译);
- 混合模型:T5、BART(兼顾理解与生成,适配更多任务)。
一、模型整体结构
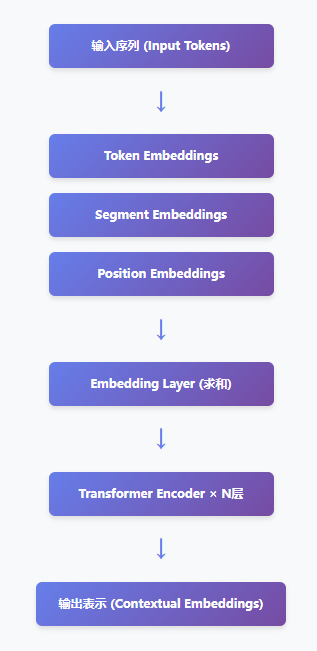
1. 输入表示 (Input Representation)
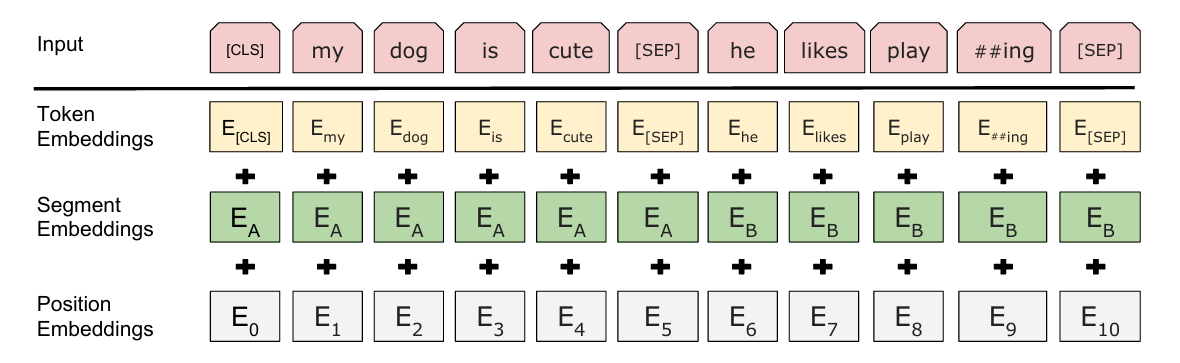
BERT的输入由三种嵌入向量相加组成:

Segment Embeddings
Segment 嵌入(也叫句子嵌入 / 段落嵌入)本质上是固定维度的可学习向量,作用是让模型区分输入中的不同句子(仅用于句子对任务,如文本匹配、问答)。
Segment 嵌入是与 Token 嵌入、Position 嵌入维度完全相同的稠密向量(BERT-Base 中维度为 768,BERT-Large 中为 1024),属于模型的可训练参数 ------ 初始化时为随机值,随模型训练不断更新优化,最终学习到能有效区分不同句子的特征。
Position Embeddings
Transformer 本身是无序模型(self-attention 对 token 顺序不敏感),必须通过位置编码注入序列的顺序信息,BERT 采用的是可学习的绝对位置嵌入,区别于原始 Transformer 的正弦余弦位置编码。
- 本质: 为每个位置(从 0 到最大序列长度 L_max,BERT 中 L_max=512)分配一个唯一的可训练向量,位置 i 对应的向量记为PE_i,维度与 Token 嵌入一致(H=768/1024);
- 学习方式: 位置嵌入作为模型参数初始化后,与其他参数一起通过反向传播更新,模型自动学习 "位置相近的 token 具有相似的位置向量""不同位置的向量能区分顺序" 等规律;
- 作用: 将 token 的位置信息转化为向量特征,叠加到 Token 嵌入中,让模型感知 "我喜欢 NLP" 与 "NLP 喜欢我" 的顺序差异。
- 位置嵌入的可视化与学习规律: 通过训练后位置向量的相似度分析,可发现:
- 相邻位置的向量相似度高(如位置 1 和位置 2),距离越远相似度越低;
- 相同相对位置的向量具有相似性(如位置 2 与位置 3 的差异 ≈ 位置 10 与位置 11 的差异);
- 模型学会了 "位置顺序" 的语义(如 "猫抓老鼠" 中 "猫" 在位置 1、"老鼠" 在位置 3 的依赖关系)。
2. Transformer Encoder结构
关于Transformer的详细架构解析可以看我的另一篇:跳转
BERT原论文中提供了两个主流版本,不同版本所使用的Transformer Encoder数量不同,具体如下:
- BERT-Base :该版本使用了12个Transformer Encoder进行堆叠。同时它搭配12个注意力头,隐藏层维度为768,整体模型参数约1.1亿,是兼顾性能与效率的基础版本,适用于多数常规NLP下游任务,比如文本分类、简单情感分析等。
- BERT-Large :该版本使用了24个Transformer Encoder。它的规模更大,配备16个注意力头,隐藏层维度提升至1024,总参数约3.4亿。更多的Encoder层让模型能捕捉更复杂的文本语义和深层上下文关联,但训练和推理时对硬件资源的要求更高,适合对语义理解精度要求高的复杂任务,例如复杂文本的语义匹配、多义词深层辨析等场景。
这两个版本的核心架构一致,仅通过Transformer Encoder层数、注意力头数量等参数差异来平衡模型性能与计算成本。
多头自注意力机制 (Multi-Head Self-Attention)
自注意力机制原理:对于序列中的每个位置,自注意力机制会计算它与其他所有位置的相关性,从而捕获上下文信息。


多头注意力:将Q、K、V分成多个头(heads),每个头独立计算注意力,最后拼接所有头的结果。

前馈神经网络 (Feed Forward Network)
每个Transformer层包含一个两层的前馈网络:
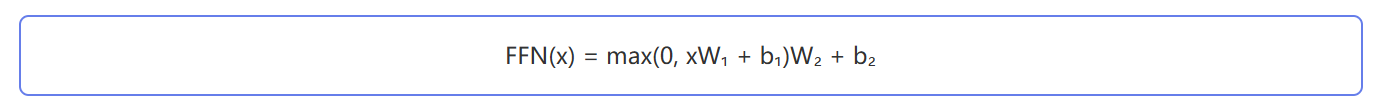
通常第一层将维度扩展到4倍(如768→3072),第二层再压缩回原始维度(3072→768)。
残差连接与层归一化
每个子层都包含:
- 残差连接 (Residual Connection):x + Sublayer(x),有助于梯度传播
- 层归一化 (Layer Normalization):稳定训练过程

二、预训练任务
BERT通过两个无监督任务进行预训练:
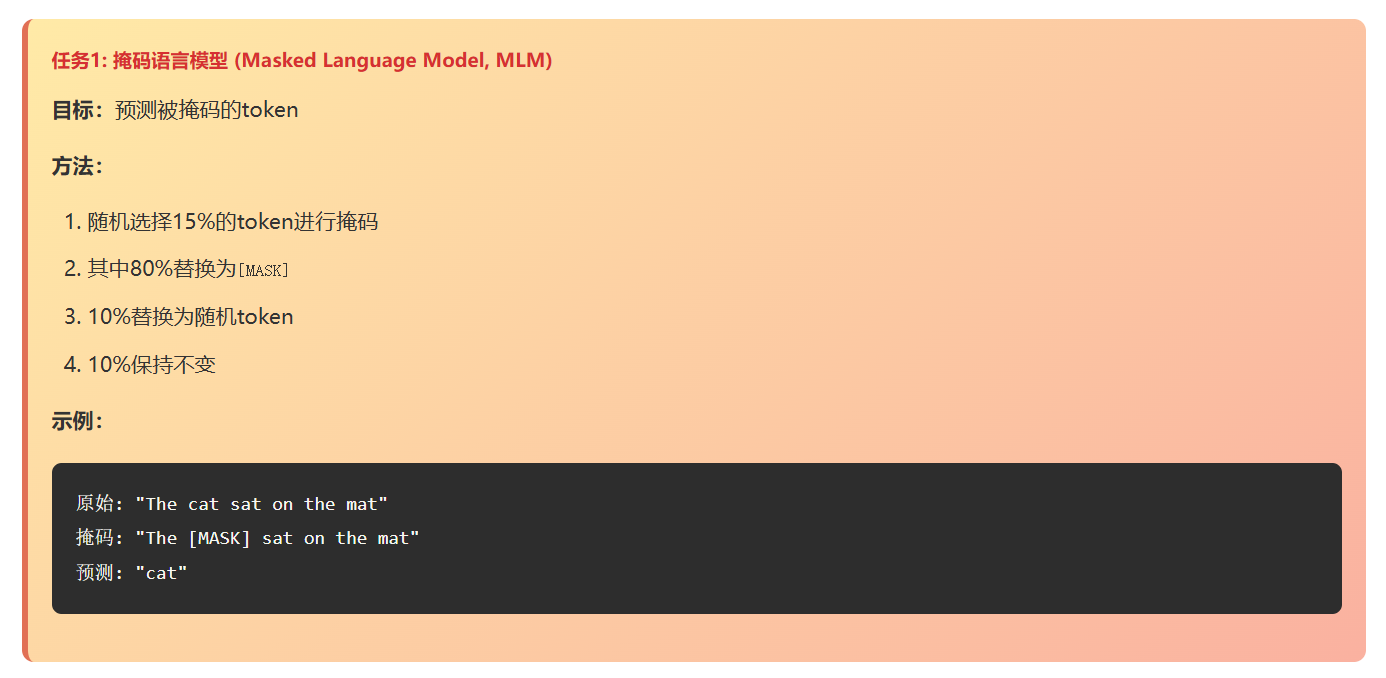
掩码语言模型 (Masked Language Model, MLM)
下一句预测 (Next Sentence Prediction, NSP)

三、Bert的现有局限性
尽管BERT是NLP领域的里程碑模型,但受限于架构设计与训练模式,仍存在以下5点核心不足:
1. 生成任务表现薄弱
BERT基于自编码架构(核心任务为Masked LM,预测被遮蔽的词),而非自回归架构,因此在文本生成、机器翻译等生成类任务中表现远不如GPT、T5等模型,难以生成连贯、流畅的长文本。
2. 序列长度限制严格BERT的最大序列长度固定为512个token(约300~400个中文字符),无法直接处理超长文本(如长篇文档、论文、小说),若强行截断会丢失关键上下文信息,需通过特殊策略(如滑动窗口)适配,效率与效果均受影响。
3. 计算资源消耗大BERT-Base版本参数约1.1亿,Large版本约3.4亿,预训练与微调均需高性能GPU/TPU支持,普通硬件难以承载;同时推理速度较慢,难以满足实时性要求高的场景(如在线对话系统、高频接口调用)。
4. 对噪声数据敏感BERT的预训练知识依赖于高质量语料,若下游任务数据中存在大量错别字、语法错误、口语化噪声(如网络俚语、方言),模型性能会明显下降,抗干扰能力弱于部分鲁棒性优化后的模型(如RoBERTa、ELECTRA)。
5. 缺乏领域知识深度适配通用预训练的BERT对专业领域(如医疗、金融)的术语、行业规则理解不足,若直接微调适配领域任务,效果有限;需额外进行领域预训练(使用大量领域无标注语料),增加了任务落地的复杂度与成本。