
目录
[一、核心创新:三大模块破解 SAM+FSS 融合难题](#一、核心创新:三大模块破解 SAM+FSS 融合难题)
[1.1 收缩映射先验模块:数学保证下的位置先验优化](#1.1 收缩映射先验模块:数学保证下的位置先验优化)
[1.1.1 初始先验构建:从语义匹配到概率分布](#1.1.1 初始先验构建:从语义匹配到概率分布)
[1.1.2 结构转移矩阵:捕捉查询图像的内在关联](#1.1.2 结构转移矩阵:捕捉查询图像的内在关联)
[1.1.3 收缩映射迭代:收敛保证下的先验精炼](#1.1.3 收缩映射迭代:收敛保证下的先验精炼)
[1.1.4 收敛性证明:数学理论支撑的可靠性](#1.1.4 收敛性证明:数学理论支撑的可靠性)
[1.2 自适应分布对齐模块:打通连续先验与 SAM 的 "任督二脉"](#1.2 自适应分布对齐模块:打通连续先验与 SAM 的 "任督二脉")
[1.2.1 双先验表征: foreground 与 background 的互补](#1.2.1 双先验表征: foreground 与 background 的互补)
[1.2.2 轻量适配器与动态融合](#1.2.2 轻量适配器与动态融合)
[1.3 前景 - 背景解耦精炼模块:精准分割的最后一公里](#1.3 前景 - 背景解耦精炼模块:精准分割的最后一公里)
[1.3.1 多尺度特征解耦](#1.3.1 多尺度特征解耦)
[1.3.2 边界感知与多源特征融合](#1.3.2 边界感知与多源特征融合)
[1.3.3 跨尺度优化与最终聚合](#1.3.3 跨尺度优化与最终聚合)
[1.4 损失函数设计:双阶段优化的损失组合](#1.4 损失函数设计:双阶段优化的损失组合)
[二、实验验证:全方位碾压 SOTA,性能与泛化双优](#二、实验验证:全方位碾压 SOTA,性能与泛化双优)
[2.1 实验设置:数据集与实现细节](#2.1 实验设置:数据集与实现细节)
[2.1.1 数据集介绍](#2.1.1 数据集介绍)
[2.1.2 评价指标](#2.1.2 评价指标)
[2.1.3 实现细节](#2.1.3 实现细节)
[2.2 与 SOTA 方法的性能对比](#2.2 与 SOTA 方法的性能对比)
[2.2.1 PASCAL-5ᵢ数据集结果](#2.2.1 PASCAL-5ᵢ数据集结果)
[2.2.2 COCO-20ᵢ数据集结果](#2.2.2 COCO-20ᵢ数据集结果)
[2.2.3 FSS-1000 数据集结果](#2.2.3 FSS-1000 数据集结果)
[2.2.4 与同类 SAM-based 方法的深度对比](#2.2.4 与同类 SAM-based 方法的深度对比)
[2.3 消融实验:各模块的贡献分析](#2.3 消融实验:各模块的贡献分析)
[2.4 敏感性分析:关键参数的影响](#2.4 敏感性分析:关键参数的影响)
[2.4.1 支持样本数量 K 的影响](#2.4.1 支持样本数量 K 的影响)
[2.4.2 适配器网络复杂度的影响](#2.4.2 适配器网络复杂度的影响)
[2.5 可视化结果分析](#2.5 可视化结果分析)
[2.6 复杂度分析](#2.6 复杂度分析)
[三、相关工作:少样本分割与 SAM-based 方法的演进](#三、相关工作:少样本分割与 SAM-based 方法的演进)
[3.1 少样本分割方法分类](#3.1 少样本分割方法分类)
[3.2 SAM-based 分割方法的三大发展方向](#3.2 SAM-based 分割方法的三大发展方向)
[4.1 模型局限性](#4.1 模型局限性)
[4.2 未来研究方向](#4.2 未来研究方向)
前言
在计算机视觉的领域中,图像分割始终是支撑众多实际应用的核心基石 ------ 从医疗影像中病灶的精准定位,到遥感图像的地物分类,再到工业质检中的缺陷检测,分割技术的精度直接决定了系统的可用性。然而,传统全监督分割方法却面临着两道难以逾越的鸿沟:一是像素级标注的高昂成本,标注一张医学影像可能需要资深医生花费数小时;二是泛化能力的匮乏,在训练集中未见过的新类别面前往往束手无策。
少样本分割(Few-shot Segmentation, FSS) 的出现,为解决这一困境带来了曙光。它旨在仅利用少量标注样本(通常 1-5 张),就能让模型具备分割新类别的能力,极大降低了对标注数据的依赖。近年来,随着**Segment Anything Model(SAM)**的横空出世,少样本分割领域迎来了新的发展机遇 ------SAM 凭借海量数据预训练获得的强大零样本泛化能力,与 FSS 的 "少量标注驱动新类别分割" 理念形成了完美互补。
但理想与现实之间总有差距。将 SAM 与 FSS 结合的过程中,研究者们发现了两个致命问题:其一,信息丢失严重。FSS 生成的位置先验是连续概率分布,包含丰富的不确定性信息,而 SAM 需要的是离散的点、框或二值掩码提示,传统 "生成粗掩码→提取离散点" 的转换方式会导致大量关键信息流失;其二,结构相关性利用不足。现有方法大多依赖支持集与查询集的全局语义匹配,却忽略了查询图像内部的固有结构关联,导致分割结果边界精度不足、抗干扰能力弱。
正是在这样的背景下,来自电子科技大学和太行实验室的团队提出了 CMaP-SAM 框架 ------ 一种将收缩映射理论与 SAM 深度融合的少样本分割新方案。该方法不仅在 PASCAL-5ᵢ数据集上实现了 71.1mIoU、在 COCO-20ᵢ上达到 56.1mIoU 的 SOTA 性能,更从理论层面解决了 SAM 与 FSS 融合的核心矛盾。本文将带大家深度拆解 CMaP-SAM 的技术细节,揭秘其背后的创新思路与实现逻辑。下面就让我们正式开始吧!

一、核心创新:三大模块破解 SAM+FSS 融合难题
CMaP-SAM 的成功并非偶然,其核心在于围绕上述两大痛点,设计了三个功能互补、协同工作的关键模块:收缩映射先验模块(Contraction Mapping Prior Module)、自适应分布对齐模块(Distribution Alignment Module)和前景 - 背景解耦精炼模块(Foreground-Background Decoupled Refinement Module)。这三个模块如同精密仪器的齿轮,环环相扣,共同构建起高效的少样本分割流水线。
1.1 收缩映射先验模块:数学保证下的位置先验优化
位置先验是少样本分割的核心指引,它告诉模型 "目标可能在哪里"。传统方法生成的位置先验往往存在噪声多、结构不一致的问题,而 CMaP-SAM 创新性地将位置先验优化问题转化为 Banach 收缩映射问题,通过数学理论保证优化过程的收敛性,同时兼顾语义引导与结构相关性。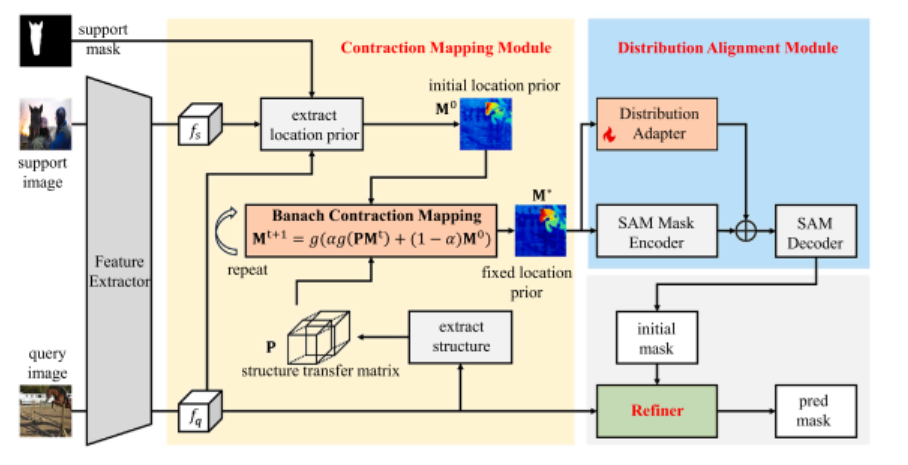
1.1.1 初始先验构建:从语义匹配到概率分布
初始位置先验的构建基于支持集与查询集的特征匹配。首先,通过预训练骨干网络(比如 DINOv2)提取支持图像()和查询图像(
)的高维特征:
其中,和
分别为支持集和查询集的特征图。为了精准表征目标类别,通过掩码引导的特征聚合构建类别原型:
这里是支持集的分割掩码,
表示元素 - wise 乘法,该操作能有效分离目标特征与背景干扰。
随后,利用查询特征与类别原型的余弦相似度计算原始位置先验,并通过 min-max 归一化将其映射到 0,1 区间,增强前景与背景的区分度:
此时得到的初始先验已经包含了支持集的语义引导,但缺乏查询图像内部的结构信息,边界精度较低。
1.1.2 结构转移矩阵:捕捉查询图像的内在关联
为了利用查询图像内部的结构相关性,CMaP-SAM 构建了结构转移矩阵(其中
为像素总数)。该矩阵的构建过程包含三步关键操作:
- 相似度计算 :将查询特征 reshape 为序列形式后,通过点积计算像素间的原始相似度
,并除以温度系数t调节相似度分布;
- 稀疏化 :采用 Top-k 选择函数
- 归一化:对稀疏后的矩阵应用 softmax,得到概率型转移矩阵。
这种设计不仅能捕捉像素间的局部结构关联,还能将计算复杂度从降低到
,有效缓解高分辨率图像的计算压力。稀疏化操作的数学表达为:
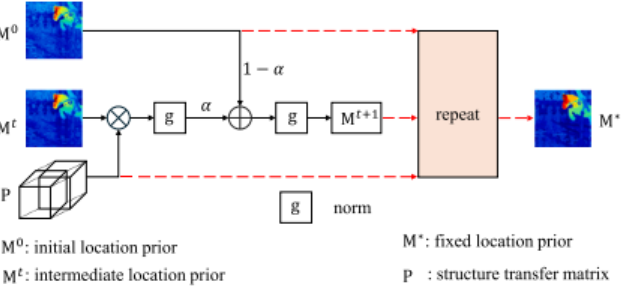
1.1.3 收缩映射迭代:收敛保证下的先验精炼
这是 CMaP-SAM 最核心的创新点。团队将位置先验优化表述为 Banach 收缩映射问题,通过迭代精炼得到收敛的高质量位置先验。迭代公式如下:
其中包含三个关键部分:
- 结构一致性传播项
- 初始语义锚定项
- 分段仿射归一化函数
1.1.4 收敛性证明:数学理论支撑的可靠性
CMaP-SAM 的一大亮点是为迭代过程提供了严格的收敛性证明。根据Banach 不动点定理 ,只要迭代映射满足收缩映射条件 (Lipschitz 常数),序列就会收敛到唯一不动点
。
团队通过理论推导得出迭代映射的 Lipschitz 常数:
当设置、
时,
的条件成立,保证迭代过程必然收敛到固定先验
:
这种基于数学理论的设计,让位置先验优化具备可靠收敛保证的严谨过程。从下图的可视化结果来看,初始先验噪声较多,经过迭代后,注意力区域逐渐集中,最终实现了对目标的精准定位,同时有效抑制了背景干扰。
1.2 自适应分布对齐模块:打通连续先验与 SAM 的 "任督二脉"
SAM 的掩码提示编码器是只接受二值掩码输入的,而收缩映射模块生成的是连续概率先验 ------ 这是导致传统方法信息丢失的核心原因。CMaP-SAM 设计了自适应分布对齐模块,在保留概率分布上的丰富信息的同时,实现了与 SAM 提示编码器的无缝对接。
1.2.1 双先验表征: foreground 与 background 的互补
模块首先将收敛后的前景先验与背景先验
(由
得到)进行拼接,构建增强型双先验表征:
。
这种设计充分利用了前景与背景信息的互补性,为后续特征对齐提供更全面的信息。
1.2.2 轻量适配器与动态融合
为了将双先验表征适配到 SAM 的特征空间,模块引入了轻量级适配器网络 (由 3×3 卷积、ReLU 激活和 1×1 卷积组成),对进行特征转换:
随后,通过可学习的融合系数,实现 SAM 预训练掩码特征与适配特征的动态融合 :
,其中
是 SAM 掩码编码器的嵌入提取操作,
是前景先验的二值化版本。而
能够动态调节预训练特征与适配特征的贡献比例,确保融合特征既符合 SAM 的输入要求,又保留了连续先验中的不确定性信息。
与传统**"连续→二值→离散点"**的转换方式相比,该模块的设计从根源上避免了信息丢失,让 SAM 能够充分利用位置先验中的丰富语义,这也是 CMaP-SAM 性能提升的关键因素之一。
1.3 前景 - 背景解耦精炼模块:精准分割的最后一公里
少样本分割中,前景物体通常具有连贯的语义结构和一致的特征分布,而背景区域则呈现复杂多变的特点 ------ 这种内在不对称性 决定了对两者的处理需要有所区别。CMaP-SAM 设计了前景 - 背景解耦精炼模块,通过多尺度特征融合 和边界感知,进一步提升分割精度。
1.3.1 多尺度特征解耦
模块构建了四尺度特征金字塔 (尺度),在每个尺度下,通过特征解耦网络分别提取前景和背景的判别性特征:
其中是输入特征图,
是特征解耦网络,
是缩放后的收敛先验,
是 SAM 解码器输出的掩码。这种解耦设计让模型能够针对前景和背景的不同特性分别优化,避免了两者特征相互干扰。
1.3.2 边界感知与多源特征融合
边界定位的准确性直接影响分割质量。模块引入了专门的边界感知单元,通过收敛先验与 SAM 掩码的差异图生成边界注意力权重:
其中,是边界感知模块,差异图
能够精准定位边界模糊区域。
随后,将解耦后的前景 / 背景特征与边界特征进行多源融合:
这里的 表示通道维度拼接 ,
是多模态融合函数 ,通过门控注意力单元计算各特征的权重系数
:
其中是 Sigmoid 激活函数,
用于提取全局上下文信息。这种融合机制能够自动强化有效特征,抑制冗余信息。
1.3.3 跨尺度优化与最终聚合
模块通过级联架构 实现跨尺度特征精炼,将低尺度特征上采样后与高尺度特征校准融合:
其中是跨尺度特征校准操作,
是上采样,
由三个级联的深度可分离卷积组成,在保证计算效率的同时增强局部 - 全局特征交互。
最终的分割结果通过多尺度特征聚合得到:
其中,是尺度自适应卷积层,
是通过注意力机制学习的尺度权重矩阵,实现语义一致性与边界精度的最优平衡。
1.4 损失函数设计:双阶段优化的损失组合
CMaP-SAM 的总损失函数是初始分割损失 与精炼损失 的加权组合(权重分别为 0.3 和 0.7),每个阶段的损失都包含二元交叉熵(BCE)损失和Dice 损失:
- Dice 损失 :优化分割结果的空间连续性,通过最大化预测与真实掩码的重叠度提升区域一致性:
- BCE 损失 :提升像素级分类准确性,惩罚错误预测:
二、实验验证:全方位碾压 SOTA,性能与泛化双优
为了充分验证 CMaP-SAM 的有效性,团队在三大主流少样本分割数据集(PASCAL-5ᵢ、COCO-20ᵢ、FSS-1000)上进行了全面实验,并与当前的 SOTA 方法进行了深度对比。
2.1 实验设置:数据集与实现细节
2.1.1 数据集介绍
- PASCAL-5ᵢ:基于 PASCAL VOC 2012+SBD 构建,包含 20 个类别,分为 4 组(每组 5 类),10582 张训练图和 1449 张验证图,是少样本分割的基准数据集;
- COCO-20ᵢ:基于 MS COCO 构建,包含 80 个类别,分为 4 组(每组 20 类),82081 张训练图和 40137 张验证图,具有密集标注、复杂场景和小目标多的特点,难度更高;
- FSS-1000:专注于细粒度分割,包含 1000 个类别,10000 个样本,类间相似度高且每个类别样本稀少,对模型泛化能力要求极高。
2.1.2 评价指标
- 平均交并比(mIoU):所有测试类别的 IoU 平均值,是分割任务的核心指标;
- 前景 - 背景 IoU(FB-IoU):前景 IoU 与背景 IoU 的平均值,衡量模型对前景和背景的整体分割能力。
2.1.3 实现细节
- 框架与硬件:基于 PyTorch 实现,使用 4 块 NVIDIA RTX 3090 GPU 训练;
- 骨干网络:采用 DINOv2(ViT-Base-P14)作为特征提取器,输入图像尺寸调整为 896×896;
- SAM 配置:SAM 运行在 1024×1024 分辨率,输出 64×64 特征图以保持空间一致性;
- 训练参数:AdamW 优化器,学习率 1e-4,批次大小 2;PASCAL-5ᵢ和 FSS-1000 训练 20 个 epoch,COCO-20ᵢ训练 5 个 epoch;
- 数据增强:随机水平翻转、尺度变换(0.8-1.2×)、旋转(±10°)和亮度 / 对比度调整。
2.2 与 SOTA 方法的性能对比
2.2.1 PASCAL-5ᵢ数据集结果
在 PASCAL-5ᵢ数据集上,CMaP-SAM 无论是 1-shot 还是 5-shot 设置下,都展现出压倒性优势:
- 1-shot 设置:mIoU 达到 71.1,FB-IoU 达到 80.8,超过此前最佳专用模型 ABCNet 5.5 个百分点,超过最佳通用模型 FSS-SAM 2.6 个百分点;
- 5-shot 设置:性能进一步提升,mIoU 达到 76.3,FB-IoU 达到 85.1,持续领跑所有对比方法。
从类别 - wise 性能分布(图 6)可以看出,CMaP-SAM 在大多数类别上都能取得高 IoU 分数,分布呈现右偏特性,证明其在不同类别上的稳定性和鲁棒性。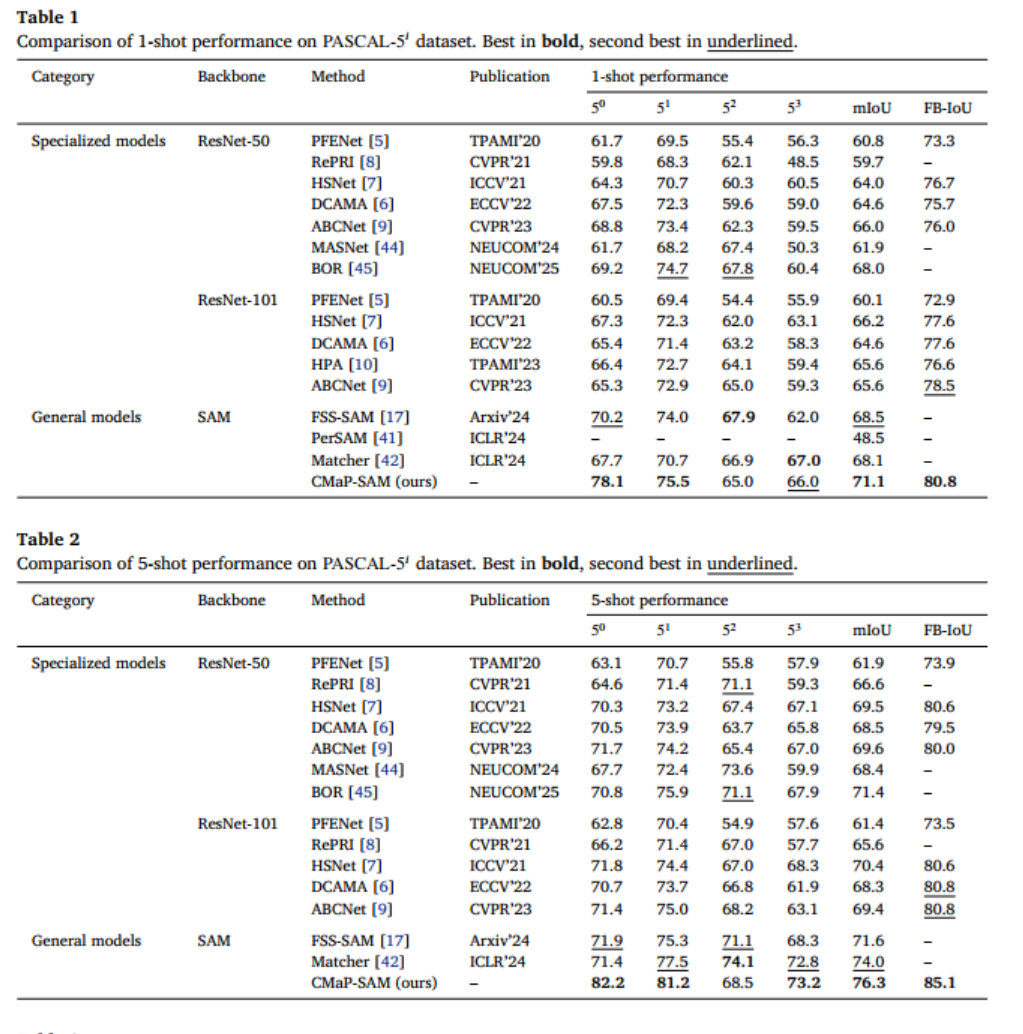
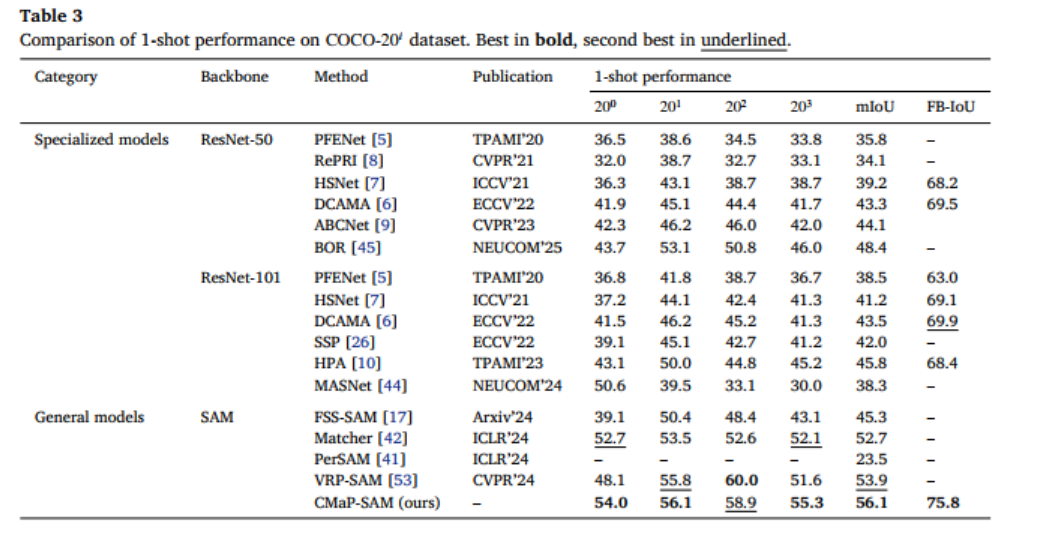
2.2.2 COCO-20ᵢ数据集结果
COCO-20ᵢ数据集因场景复杂、目标密集,对模型的挑战更大,但 CMaP-SAM 依然表现出色:
- 1-shot 设置:平均 mIoU 达到 56.1,FB-IoU 达到 75.8,显著优于 FSS-SAM 等通用模型;
- 5-shot 设置:mIoU 飙升至 65.3,超过最佳通用模型 FSS-SAM 16.1 个百分点,展现出强大的少样本学习能力。
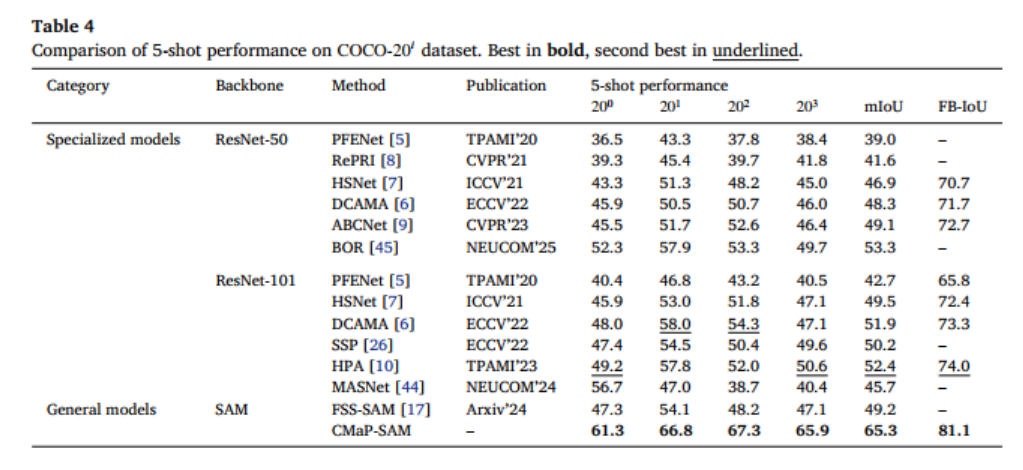
2.2.3 FSS-1000 数据集结果
在细粒度的 FSS-1000 数据集上,CMaP-SAM 同样保持领先:
- 1-shot 任务:mIoU 达到 90.2;
- 5-shot 任务:mIoU 达到 90.5,超过 HSNet、VAT 等经典方法,证明其在细粒度类别上的强泛化能力。
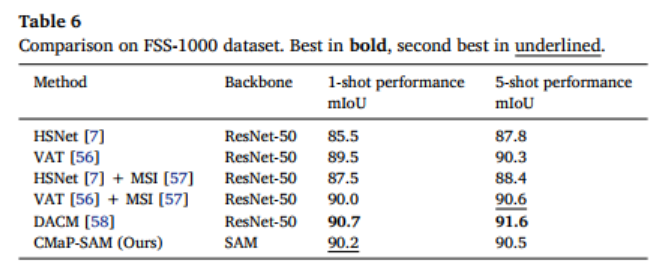
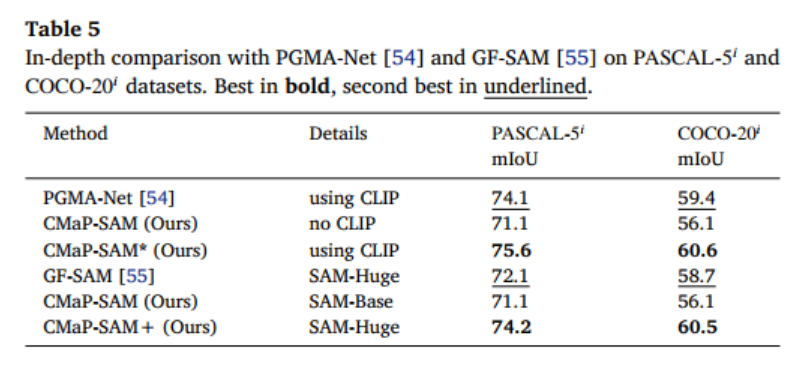
2.2.4 与同类 SAM-based 方法的深度对比
将 CMaP-SAM 与 PGMA-Net、GF-SAM 等先进 SAM-based 方法对比发现:
- 使用 CLIP 时,CMaP-SAM 在 PASCAL-5ᵢ上达到 75.6mIoU,COCO-20ᵢ上达到 60.6mIoU,超越 PGMA-Net;
- 使用 SAM-Huge 时(CMaP-SAM+),在 PASCAL-5ᵢ上超越 GF-SAM 2.1 个百分点,COCO-20ᵢ上超越 1.8 个百分点,充分验证了其架构设计的优越性。
2.3 消融实验:各模块的贡献分析
为了明确每个核心模块的作用,团队在 PASCAL-5ᵢ数据集(fold-0)上进行了消融实验:
- 移除收缩映射模块:1-shot mIoU 下降 1.3 个百分点,5-shot 下降 0.9 个百分点,证明其对位置先验优化的有效性;
- 移除适配器模块:性能下降最为显著(1-shot 下降 5.1 个百分点,5-shot 下降 4.3 个百分点),凸显了分布对齐在 SAM 与 FSS 融合中的关键作用;
- 移除精炼模块:1-shot mIoU 下降 0.6 个百分点,5-shot 下降 0.9 个百分点,且随着支持样本数量增加,贡献更加明显;
- 模块组合消融:同时移除多个模块时,性能下降幅度远大于单个模块移除的总和,证明三大模块存在协同效应,共同支撑起模型的高性能。
2.4 敏感性分析:关键参数的影响
2.4.1 支持样本数量 K 的影响
随着支持样本数量 K 从 1 增加到 5,模型性能持续提升(PASCAL-5ᵢ上 mIoU 从 78.1 提升至 82.2,FB-IoU 从 88.2 提升至 90.9),但 K 超过 5 后性能提升逐渐趋缓,K=7 时达到峰值(mIoU=82.5)。这一结果表明,3-5 个代表性样本足以在性能与效率之间取得平衡,为实际应用提供了参考。
2.4.2 适配器网络复杂度的影响
增加适配器网络中卷积块的数量(从 1 到 5),mIoU 仅从 78.1 提升至 78.4,提升幅度微小。这说明单个卷积块已能满足特征对齐需求,模型在效率与性能之间实现了良好平衡,无需过度增加网络复杂度。
2.5 可视化结果分析
从下图的分割结果可视化可以看出,CMaP-SAM 在多种复杂场景下都能保持精准分割:

- 简单场景:目标边界分割精准,前景与背景区分清晰;
- 尺度变化:能够有效处理羊等存在显著尺度差异的目标,即使是灰度图像也能准确分割;
- 遮挡场景:在椅子被遮挡的情况下,仍能精准分割被遮挡部分,甚至能修正 ground truth 中的错误标注(如排除误标的手部区域);
- 复杂背景:在背景杂乱的场景中,依然能准确锁定目标(如椅子、汽车)。
当然,模型也存在一定局限性:当查询图像中前景与背景外观高度相似,或支持集与查询集目标外观差异过大时(如不同形态的植物),分割性能会受到影响。
2.6 复杂度分析
CMaP-SAM 的可学习参数仅为 2.0M,远少于 DCAMA(14.2M)等对比方法,体现了其参数高效性。但由于继承了 SAM 的 ViT-based 编码器,模型的总参数量(179.2M)和计算量(87.6G MACs)相对较大,推理速度(1.9 FPS)较慢。这表明,CMaP-SAM是更适合离线处理场景的(比如医学影像后处理),而实时部署则需要结合轻量化 SAM 变体(如 EfficientSAM)、模型剪枝或蒸馏等技术进一步优化。
三、相关工作:少样本分割与 SAM-based 方法的演进
3.1 少样本分割方法分类
现有少样本分割方法主要分为两大类:
- 原型基方法:从支持集中提取代表性特征(原型),引导查询集分割。早期方法采用单一全局原型,后续发展出多原型、动态原型生成等机制,兼顾计算效率但空间细节不足;
- 匹配基方法:建立支持集与查询集的像素级对应关系,从直接特征相似性计算,到引入图模型、注意力机制,能够保留结构信息但计算复杂度较高。
CMaP-SAM 融合了两类方法的优势:通过原型匹配构建初始语义先验,通过结构转移矩阵捕捉像素级关联,实现了效率与精度的平衡。
3.2 SAM-based 分割方法的三大发展方向
SAM 的出现推动了分割领域的变革,相关研究主要沿着三个方向演进:
- 语义增强:通过联合训练、引入文本提示等方式,提升 SAM 的类别理解能力(如 Semantic-SAM、OV-SAM);
- 领域专业化:针对遥感、医疗、海洋动物等特定领域,优化 SAM 的提示编码器和适配策略(如 RSPrompt、SAM-Med2D、SurgicalSAM);
- 少样本集成:将 SAM 与少样本学习结合,实现自动化分割(如 PerSAM、Matcher、FSS-SAM)。
CMaP-SAM 属于少样本集成方向的创新,其核心突破在于解决了连续先验与 SAM 离散提示之间的表征鸿沟,同时引入收缩映射理论保证先验优化的可靠性,填补了现有研究的空白。
四、局限性与未来展望
4.1 模型局限性
- 计算开销较大:继承 SAM 的 ViT 编码器导致推理速度较慢,难以满足实时场景需求;
- 性能饱和现象:随着支持样本数量增加,性能提升逐渐趋缓,这是少样本分割领域的共性挑战;
- 相似外观干扰:在前景与背景外观相似或支持 - 查询集目标差异过大的场景下,分割性能仍有提升空间。
4.2 未来研究方向
- 轻量化优化:结合 EfficientSAM 等轻量化变体,或通过剪枝、蒸馏等技术,在保持精度的同时降低计算开销,实现实时部署;
- 元学习提示生成:开发元学习驱动的提示生成器,进一步提升模型对新类别的适应能力和效率;
- 多模态融合:引入文本、深度等多模态信息,缓解外观相似带来的分割歧义;
- 领域自适应:针对更多专业领域(如遥感、工业质检)进行定制化优化,拓展应用场景。
总结
CMaP-SAM 作为一种融合收缩映射理论与 SAM 的少样本分割框架,从理论和实践层面都实现了重要突破。其核心创新在于:将位置先验优化转化为 Banach 收缩映射问题,提供严格的收敛保证;通过自适应分布对齐模块,打通连续先验与 SAM 离散提示的表征鸿沟;借助前景 - 背景解耦精炼,实现精准的最终分割。
实验结果表明,CMaP-SAM 在 PASCAL-5ᵢ、COCO-20ᵢ、FSS-1000 三大数据集上均取得 SOTA 性能,充分验证了其有效性和泛化能力。尽管模型在实时性方面存在不足,但为少样本分割与基础模型的融合提供了全新思路。
随着轻量化技术的发展和多模态融合的深入,CMaP-SAM 的设计理念有望在更多实际场景中落地应用,为解决 "标注稀缺、类别新颖" 的分割难题提供强有力的技术支撑。对于研究者而言,该工作中 "数学理论指导模型设计" 的思路,也为后续研究提供了重要的借鉴。