Change3D:从视频建模视角重新审视变化检测与描述
作者 :Duowang Zhu1, Xiaohu Huang2, Haiyan Huang1, Hao Zhou3, and Zhenfeng Shao1*
1武汉大学 2香港大学 3字节跳动
项目地址:https://zhuduowang.github.io/Change3D
📝 摘要
在本文中,我们提出了 Change3D,这是一个通过视频建模重新概念化变化检测和描述任务的框架。最近的方法通过将每一对双时相图像视为独立的帧,取得了显著的成功。它们通常采用共享权重的图像编码器来提取空间特征,然后使用变化提取器来捕捉两幅图像之间的差异。然而,图像特征编码作为一个与任务无关的过程,无法有效地关注变化区域。此外,针对不同变化检测和描述任务设计的不同变化提取器,使得难以拥有一个统一的框架。
为了解决这些挑战,Change3D 将双时相图像视为包含两个帧的微型视频 。通过在双时相图像之间整合可学习的感知帧(perception frames),视频编码器使感知帧能够直接与图像交互并感知其差异。因此,我们可以摆脱复杂的变化提取器,为不同的变化检测和描述任务提供一个统一的框架。
我们在多个任务上验证了 Change3D,包括变化检测(含二值变化检测、语义变化检测和建筑物损伤评估)以及变化描述,涵盖八个标准基准测试。无需繁琐的设计,这个简单而有效的框架就能取得优越的性能,且仅使用了一个超轻量级的视频模型,其参数量仅为最先进方法的 ∼6%−13%\sim 6\% -13\%∼6%−13%,FLOPs 仅为 ∼8%−34%\sim 8\% -34\%∼8%−34%。我们希望 Change3D 能成为基于 2D 模型的方法的替代方案,并促进未来的研究。
1. 引言
变化检测和描述在遥感领域发挥着至关重要的作用,它利用在不同时间对同一地理区域拍摄的双时相图像对来追踪和分析地表随时间的变化 63。
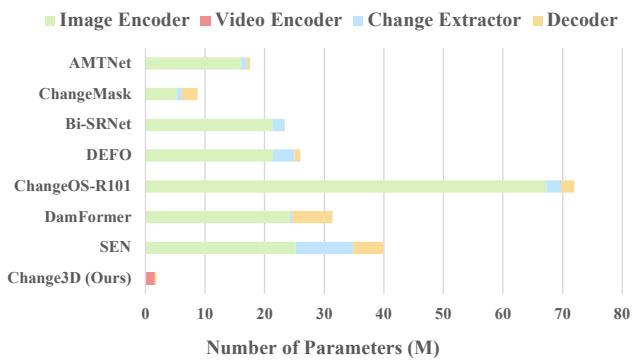
图 1. 现有变化检测和描述方法中的参数分布表明,大多数参数集中在图像编码上,而分配给变化提取的参数很少。这种不平衡表明对任务相关参数学习的重视不足。相比之下,我们的方法主要关注视频编码,这是一个能有效提取变化的特定任务过程。
该技术已广泛应用于各种场景,如损伤评估 8, 86、城市规划 74、耕地保护 55 和环境管理 38。现有的研究探索了各种用于双时相变化检测和描述建模的 2D 模型,例如基于卷积神经网络 (CNN) 的模型 24, 79, 85, 88、基于 Transformer 的模型 1, 8, 48, 83 以及它们的混合模型 7, 50, 88。
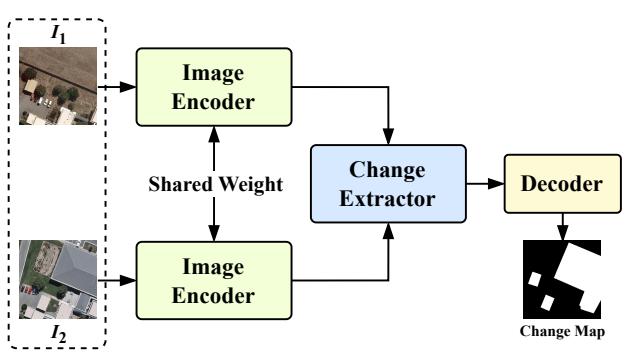
如图 2 (a) 所示,大多数方法通常遵循这样的范式:
- 独立编码:将一对双时相图像视为不同的输入,通过共享权重的图像编码器(如 ResNet 29、UNet 64、Swin Transformer 52)分别处理每张图像以进行空间特征提取。
- 变化提取:然后,引入一个精心设计的变化提取器,主要利用注意力机制 70(如交叉注意力 5 或空间通道注意力 78)进行双时相特征交互,以检测它们之间的差异。
- 解码预测:最后,使用解码器将特征图恢复到其原始分辨率。
虽然已经观察到了令人鼓舞的结果,但这些方法存在以下问题:
(a) 之前的范式
(b) 我们的范式
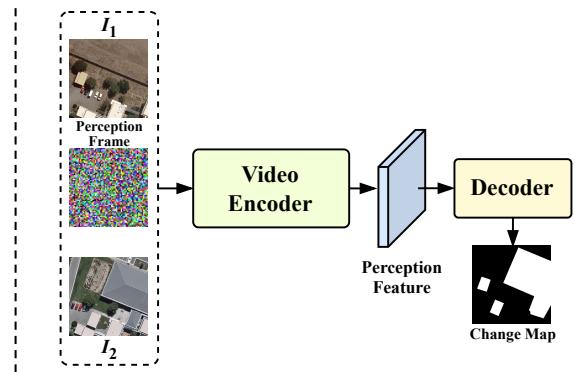
图 2. 之前的范式与我们的范式对比。 (a) 之前的范式将双时相图像对视为单独的输入,每个输入由共享权重的图像编码器单独处理以提取空间特征,随后是一个专用的变化提取器来捕捉差异,最后是解码器进行预测。(b) 我们提出的范式从视频建模的角度重新思考变化检测和描述任务。通过在双时相图像之间加入可学习的感知帧,视频编码器促进了感知帧与图像之间的直接交互以提取差异,消除了对复杂变化提取器的需求,并为多任务提供了一个统一的框架。
- 缺乏任务特异性与参数分布不合理:图像编码器旨在独立学习双时相图像的空间特征,缺乏建模变化的任务特异性。虽然之前的方法 20 在图像编码期间引入了帧间特征交互,但它无法提取变化,仍然需要专用的变化提取器。此外,如图 1 所示,这种范式导致参数分布不合理,大部分参数集中在独立的图像编码上,很少用于变化提取,没有强调变化检测和描述任务的参数学习。
- 缺乏统一框架:当前方法需要针对不同任务单独设计变化提取器,阻碍了利用统一框架有效解决所有变化检测和描述任务。
受视频建模方法 21, 22, 40 有效建模图像间关系能力的启发,我们试图将双时相图像重新视为一个微型视频,利用视频模型固有的时空学习能力来捕捉变化。
为此,我们提出了一个名为 Change3D 的统一框架,作为基于 2D 模型方法的有力替代方案。我们的核心思想是通过视频建模技术的视角重新思考双时相变化的提取。如图 2 (b) 所示,我们通过加入一个可以学习感知的可学习帧,巧妙地将双时相变化检测和描述重新定义为类似于视频建模的任务。具体来说,我们将双时相图像与可学习的感知帧对齐,沿时间维度排列,创建一个 3D 体积。然后,Change3D 利用视频编码器处理此输入,使感知帧能够观察并辨别双时相图像之间的差异。最终,源自感知帧的特征被输入到解码器中,生成指示变化的概率图或描述。
Change3D 可以解决上述基于双时相图像的方法所面临的挑战:
- 首先,Change3D 中的模型参数分布主要集中在视频特征编码上,这是一个擅长有效提取变化的特定任务过程。
- 其次,可以消除复杂的变化提取器,为各种变化检测和描述任务提供统一的框架。
我们在四个变化检测和描述任务(即二值变化检测、语义变化检测、建筑物损伤评估和变化描述)以及八个广泛认可的数据集(即 LEVIR-CD 6, WHU-CD 34, CLCD 49, HRSCD 14, SECOND 81, xBD 28, LEVIR-CC 47, 和 DUBAI-CC 30)上进行了广泛的实验,结果表明 Change3D 全面达到了最先进的性能。同时,我们采用了各种视频模型,包括基于 CNN 的(如 I3D 3, SlowFast 22, X3D 21)和基于 Transformer 的(如 UniFormer 40),并使用了不同的预训练权重(如 AVA 27, Charades 65, Something-Something V2 26, 和 Kinetics-400 37)来确认所提范式的有效性。值得注意的是,尽管与先进的 2D 模型相比,所提出的方法非常简单,但 Change3D 优于利用这些复杂结构设计的方法,展示了所提范式在双时相变化检测和描述任务中的有效性。
本文的主要贡献总结如下:
- 我们从视频建模的角度重新审视了双时相变化检测和描述任务,并引入了一种名为 Change3D 的范式,这是一种简单而有效的双时相变化检测和描述的 3D 建模方法。
- 通过在输入中注入感知帧,Change3D 利用 3D 模型高效地提取变化,无需精心设计的结构或复杂的框架。
- Change3D 利用高效的视频模型(即 X3D-L)在多个基准测试中实现了最先进的性能,证明了所提方法的优越性。此外,定量和定性分析都验证了我们引入的新范式的功效,进一步巩固了我们方法的有效性。
2. 相关工作
变化检测与描述。长期以来,基于 CNN 的方法一直是文献中的主流框架 4, 12, 13, 15, 20, 23-25, 44, 47, 51, 66, 85,以其分层特征建模能力而闻名。这些工作主要集中在多尺度特征提取、差异建模、前景-背景类别不平衡等方面。例如,12-14 中的方法利用全卷积网络捕捉分层特征以进行多尺度特征表示。为了进行充分的差异特征建模,4, 15, 20, 23, 24, 44, 46, 66, 72 中的方法结合了注意力机制 70 或特征交换来建立双时相特征之间的关系依赖。一些研究 84, 85 通过开发创新的损失函数解决了前景-背景类别不平衡带来的重大挑战。受 Vision Transformer 17 及其变体 52, 53, 75 在各种视觉任务 10, 42, 80, 82 中取得成就的启发,一些工作 1, 7, 8, 16, 36, 48, 50, 56, 83, 88 探索了 Transformer 在变化检测和描述任务中的应用。其中一些方法 1, 8, 11, 83, 90 利用纯 Transformer,而其他方法 7, 16, 36, 50, 56, 88 采用 CNN-Transformer 混合架构。
与上述方法不同,我们提出的方法将变化检测和描述任务视为一个视频理解过程。它整合了可学习的感知帧,利用视频编码器高效地捕捉变化,从而无需精心设计的变化提取器,并提供了一个统一的框架。
视频理解。动作识别 21, 22, 32 和检测 18, 40, 43, 54 中的视频理解涉及分析视频数据以识别和定位视频帧内对象执行的动作。在过去几年中,视频理解的进步主要由 3D 卷积神经网络 (CNN) 22, 33, 67 推动。然而,它们面临优化困难和计算成本高的问题。为了解决这个问题,I3D 3 膨胀了预训练的 2D 卷积核以获得更好的优化。其他方法 21, 62, 68, 69, 71 尝试在不同维度分解 3D 卷积核以降低复杂性,还有一些方法 35, 41, 45, 73 引入精心设计的时序建模模块以增强 2D CNN 的时序建模能力,同时节省计算成本。最近,一些工作 2, 18, 32, 40, 43, 54 探索了 Vision Transformer 17 在时空学习方面的潜力,验证了其捕捉长期依赖关系的杰出能力。
在先前研究的基础上,我们将双时相图像重新概念化为包含两个帧的微型视频。通过整合感知帧,采用视频编码器促进了变化的有效捕捉。
3. 方法
Change3D 的整体架构如图 3 所示,包括两个主要组件:(1) 用于提取感知特征的视频编码器,以及 (2) 一个或多个负责将感知特征转换为变化图或描述的解码器。接下来,我们在 3.1 节首先介绍问题表述,随后在 3.2 节详细阐述我们的方法。
3.1. 问题表述
本文重点关注遥感领域的两个关键任务:变化检测(包括二值变化检测 BCD、语义变化检测 SCD 和建筑物损伤评估 BDA)和变化描述(CC)。这些任务的公式化如下:
变化检测 。变化检测涉及识别和分析在不同时间捕获的双时相图像之间的变化。给定两幅图像 I1,I2∈RH×W×CI_1, I_2 \in \mathcal{R}^{H \times W \times C}I1,I2∈RH×W×C,变化检测过程可公式化为:(Mbinary,Msemantic,Mdamage)=FCD(I1,I2)(\mathcal{M}{\mathrm{binary}}, \mathcal{M}{\mathrm{semantic}}, \mathcal{M}{\mathrm{damage}}) = \mathcal{F}{\mathrm{CD}}(I_1, I_2)(Mbinary,Msemantic,Mdamage)=FCD(I1,I2)。其中,FCD\mathcal{F}{\mathrm{CD}}FCD 是变化检测器,Mbinary∈{0,1}H×W\mathcal{M}{\mathrm{binary}} \in \{0, 1\}^{H \times W}Mbinary∈{0,1}H×W 代表指示变化或无变化的二值变化图,Msemantic∈{0,1,...,Nsemantic−1}H×W\mathcal{M}{\mathrm{semantic}} \in \{0, 1, \dots, N{\mathrm{semantic}} - 1\}^{H \times W}Msemantic∈{0,1,...,Nsemantic−1}H×W 是将土地覆盖分类为 NsemanticN_{\mathrm{semantic}}Nsemantic 个类别的语义变化图,Mdamage∈{0,1,...,Ndamage−1}H×W\mathcal{M}{\mathrm{damage}} \in \{0, 1, \dots, N{\mathrm{damage}} - 1\}^{H \times W}Mdamage∈{0,1,...,Ndamage−1}H×W 表示具有 NdamageN_{\mathrm{damage}}Ndamage 个损伤等级的建筑物损伤图。
变化描述 。变化描述涉及生成解释双时相图像之间差异的自然语言描述。给定一对双时相图像 I1,I2∈RH×W×CI_1, I_2 \in \mathcal{R}^{H \times W \times C}I1,I2∈RH×W×C 和一个词汇集 V\mathcal{V}V,变化描述过程表示为:W=FCC(I1,I2)∈VL\mathcal{W} = \mathcal{F}{\mathrm{CC}}(I_1, I_2) \in \mathcal{V}^LW=FCC(I1,I2)∈VL。其中,FCC(⋅)\mathcal{F}{\mathrm{CC}}(\cdot)FCC(⋅) 是变化描述器,W\mathcal{W}W 代表描述变化的单词序列,LLL 为描述的长度。
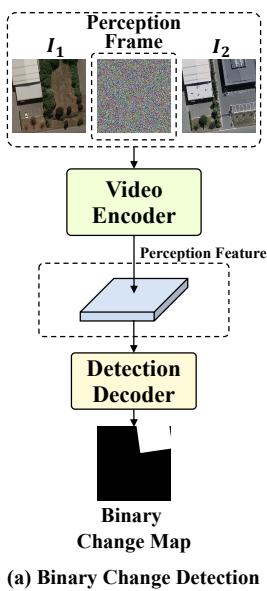
图 3. Change3D 用于二值变化检测、语义变化检测、建筑物损伤评估和变化描述的整体架构。
(a) 二值变化检测需要获取一个代表变化目标的特征,因此加入了一个感知帧进行感知。
(b) 语义变化检测涉及表示 T1T_{1}T1 和 T2T_{2}T2 中的语义变化以及二值变化。为了实现这一点,集成了三个感知帧以促进语义变化学习。
© 建筑物损伤评估需要表达两个感知特征用于建筑物定位和损伤分类。因此,插入了两个感知帧来捕捉建筑物损伤。
(d) 变化描述涉及生成一个代表改变内容的特征,因此加入了一个感知帧来解释内容变化。
3.2. Change3D
为了探索我们所提方法的通用性,我们将 Change3D 应用于变化检测和描述任务。如图 3 所示,我们首先初始化一定数量的感知帧,对应于每个任务的解码器数量。随后,这些帧与双时相图像沿时间维度堆叠,组成输入视频帧。然后,使用视频编码器促进感知帧与双时相图像之间的交互以产生感知特征。最后,相应的解码器将感知特征转换为变化图或描述。
3.2.1 感知特征提取
给定一对双时相图像 I1,I2I_{1}, I_{2}I1,I2,以及可学习的感知帧 IP={IP1,...,IPK}I_{P} = \{I_{P}^{1}, \dots, I_{P}^{K}\}IP={IP1,...,IPK},每个维度为 (H,W,3)(H, W, 3)(H,W,3),其中 KKK 表示感知帧的长度,对于 BCD、SCD、BDA 和 CC,其可能的值分别为 1、3、2 或 1。感知帧的功能类似于 Vision Transformers 17 中的 CLS token,捕捉整个帧序列中的基本信息。这些帧沿时间维度连接以构建一个视频。然后,使用视频编码器提取多层特征 fff,如公式 (1) 所示:
f=Fe n c(I1(⊙)IP(⊙)I2),(1) f = \mathcal {F} _ {\text {e n c}} \left(I _ {1} (\odot) I _ {P} (\odot) I _ {2}\right), \tag {1} f=Fe n c(I1(⊙)IP(⊙)I2),(1)
其中 Fenc(⋅)\mathcal{F}{\mathrm{enc}}(\cdot)Fenc(⋅) 是视频编码器,⊙\odot⊙ 表示沿时间维度的连接,f∈{RT×Ci×H2i+1×W2i+1}i=03f\in \{\mathcal{R}^{T\times C_i\times \frac{H}{2^{i + 1}}\times \frac{W}{2^{i + 1}}}\}{i = 0}^3f∈{RT×Ci×2i+1H×2i+1W}i=03,其中 T=K+2T = K + 2T=K+2,CiC_iCi 是通道维度。fitf_{i}^{t}fit 表示从第 iii 个编码器层提取的第 ttt 帧的特征。我们使用多层感知特征来检测不同大小的变化,表示为 pdeti,j∈{fi1,...,fiT−2}p_{\mathrm{det}}^{i,j}\in \{f_i^1,\dots ,f_i^{T - 2}\}pdeti,j∈{fi1,...,fiT−2},其中 pdeti,jp_{\mathrm{det}}^{i,j}pdeti,j 表示第 iii 层中的第 jjj 个感知特征。并且我们利用高层感知特征 f31f_{3}^{1}f31 来描述变化,表示为 pcapp_{\mathrm{cap}}pcap。
为了增强感知特征的表示能力,利用一个核大小为 1×11 \times 11×1 的卷积层后接 ReLU,将双时相特征 fi0f_{i}^{0}fi0 和 fiT−1f_{i}^{T-1}fiT−1 的差异特征整合到其中。
3.2.2 解码器与优化
变化解码器 。现有方法 4, 9, 11, 24, 50, 60 利用复杂的方法来捕捉双时相变化并预测变化图。为了更有力地突显 Change3D 的学习能力,我们选择实现一个更简单的解码器。具体来说,我们采用级联卷积层后接上采样操作,逐步将感知特征从深层聚合到浅层,最终将其恢复到 H×WH \times WH×W 的原始分辨率,如公式 (2) 所示:
pdeti,j←Deconv4×4(Conv1×1(pdeti+1,j))+pdeti,j,(2) p _ {\det} ^ {i, j} \leftarrow \operatorname {D e c o n v} _ {4 \times 4} \left(\operatorname {C o n v} _ {1 \times 1} \left(p _ {\det} ^ {i + 1, j}\right)\right) + p _ {\det} ^ {i, j}, \tag {2} pdeti,j←Deconv4×4(Conv1×1(pdeti+1,j))+pdeti,j,(2)
其中 Conv1×1\mathrm{Conv}{1\times 1}Conv1×1 是核大小为 1×11\times 11×1 的 2D 卷积,Deconv4×4\mathrm{Deconv}{4\times 4}Deconv4×4 表示核大小为 4×44\times 44×4、步幅为 2×22\times 22×2 的转置 2D 卷积。
最后,应用分类层将最浅层的特征 pdet0,jp_{\mathrm{det}}^{0,j}pdet0,j 转换为变化图 M\mathcal{M}M,公式化为 (3):
M=argmax(Conv3×3(pdet0,j)),(3) \mathcal {M} = \arg \max \left(\operatorname {C o n v} _ {3 \times 3} \left(p _ {\det } ^ {0, j}\right)\right), \tag {3} M=argmax(Conv3×3(pdet0,j)),(3)
其中 Conv3×3\mathrm{Conv}_{3\times 3}Conv3×3 是核大小为 3×33\times 33×3 的 2D 卷积,M∈{0,...,N−1}H×W\mathcal{M}\in \{0,\dots ,N - 1\}^{H\times W}M∈{0,...,N−1}H×W,NNN 表示土地覆盖类别或损伤等级的数量,arg max 操作沿通道维度执行。
描述解码器 。遵循惯例,如 47, 48, 89 所采用的,我们使用基于 Transformer 17 的解码器来描述变化。具体来说,输入单词 www 最初通过词嵌入层以及可学习的位置嵌入,以获得特征嵌入 ew∈RL×De_w \in \mathcal{R}^{L \times D}ew∈RL×D,其中 LLL 代表单词长度,DDD 表示嵌入维度。接下来,应用掩码自注意力和交叉注意力块,基于感知特征对变化进行建模,如公式 (4) 描述:
ew′=CrossAttn(SelfAttn(ew),pcap)+ew,(4) e _ {w} ^ {\prime} = \operatorname {C r o s s A t t n} (\operatorname {S e l f A t t n} (e _ {w}), p _ {\mathrm {c a p}}) + e _ {w}, \tag {4} ew′=CrossAttn(SelfAttn(ew),pcap)+ew,(4)
其中掩码操作在注意力矩阵上执行,以防止后续位置的单词泄漏。最深层特征 pcapp_{\mathrm{cap}}pcap 作为键 (keys) 和值 (values),而由 SelfAttn(⋅\cdot⋅) 增强的特征嵌入 ewe_wew 作为查询 (queries)。
最后,将全连接 (FC) 层后接 softmax 函数应用于 ew′e_w'ew′ 以预测变化描述的概率,表示为公式 (5):
W=softmax(FC(ew′)).(5) \mathcal {W} = \operatorname {s o f t m a x} (\mathrm {F C} (e _ {w} ^ {\prime})). \tag {5} W=softmax(FC(ew′)).(5)
与现有方法 44, 48, 85, 87 类似,我们采用联合损失函数来优化四个任务。损失函数的公式如下:
LBCD=Lce+Ldice,LSCD=Lce+Ldice+Lsim, \mathcal {L} _ {\mathrm {B C D}} = \mathcal {L} _ {\mathrm {c e}} + \mathcal {L} _ {\mathrm {d i c e}}, \mathcal {L} _ {\mathrm {S C D}} = \mathcal {L} _ {\mathrm {c e}} + \mathcal {L} _ {\mathrm {d i c e}} + \mathcal {L} _ {\mathrm {s i m}}, LBCD=Lce+Ldice,LSCD=Lce+Ldice+Lsim,
LBDA=Lce+Ldice,LCC=Lce,(6) \mathcal {L} _ {\mathrm {B D A}} = \mathcal {L} _ {\mathrm {c e}} + \mathcal {L} _ {\mathrm {d i c e}}, \mathcal {L} _ {\mathrm {C C}} = \mathcal {L} _ {\mathrm {c e}}, \tag {6} LBDA=Lce+Ldice,LCC=Lce,(6)
其中 Lce\mathcal{L}{\mathrm{ce}}Lce、Ldice\mathcal{L}{\mathrm{dice}}Ldice 和 Lsim\mathcal{L}_{\mathrm{sim}}Lsim 分别表示交叉熵损失、Dice 损失 57 和余弦相似度损失 15。
4. 实验
4.1. 实验设置
数据集和评估指标 :我们在八个公共数据集上进行了广泛的实验:LEVIR-CD 6, WHU-CD 34, CLCD 49, HRSCD 14, SECOND 81, xBD 28, LEVIR-CC 47, 和 DUBAI-CC 30。LEVIR-CD, WHU-CD 和 CLCD 是三个二值变化检测数据集。HRSCD 和 SECOND 用于语义变化检测。xBD 是建筑物损伤评估数据集。LEVIR-CC 和 DUBAI-CC 是变化描述数据集。我们使用 F1 分数、交并比 (IoU)、总体精度 (OA) 和 SeK 系数报告变化检测性能,并使用 BLEU-N (N=1,2,3,4)(N = 1,2,3,4)(N=1,2,3,4)、METEOR、ROUGE-L 和 CIDEr 评估变化描述性能。
实现细节:我们采用 I3D 3, Slow-R50 22, UniFormer-XS 40, 和 X3D-L 21 作为视频编码器来验证我们方法的有效性。除非另有说明,我们使用 X3D-L 进行实验,并在最大的公开开源数据集 xBD 28 上进行诊断性研究。所有视频编码器均在 Kinetics-400 37 上预训练,解码器和感知帧随机初始化。此外,我们在表 6 中探索了在其他视频数据集上预训练的初始化权重。模型使用 PyTorch 59 框架在 NVIDIA GeForce RTX 3090 GPU 上训练。
4.2. 与最先进方法的比较
表 1-4 展示了在八个数据集上与变化检测和描述任务的最先进方法的比较。值得注意的是,所有比较的方法都采用共享权重的图像编码器和变化提取器进行特征提取。相比之下,我们的方法使用视频编码器直接捕捉变化。
表 1. 不同二值变化检测方法在 LEVIR-CD, WHU-CD 和 CLCD 数据集上的性能比较。 † 表示我们复现的结果。最佳结果加粗,次佳结果加下划线。括号中的值表示相对于 SOTA 方法 (AMTNet) 的百分比。
| Method | #Params(M) | FLOPs(G) | Inference (s/sample) | LEVIR-CD (F1/IoU/OA) | WHU-CD (F1/IoU/OA) | CLCD (F1/IoU/OA) |
|---|---|---|---|---|---|---|
| AMTNet 50 | 16.44 (100%) | 24.67 (100%) | 0.032 | 90.76 / 83.08 / 98.96 | 92.27 / 85.64 / 99.32 | 75.10 / 60.12 / 96.45 |
| Change3D | 1.54 (9%) | 8.29 (34%) | 0.015 | 91.82 / 84.87 / 99.17 | 94.56 / 89.69 / 99.57 | 78.03 / 63.97 / 96.87 |
(注:为简洁起见,表格仅展示了对比最强 SOTA 的关键数据,完整数据请参考原文图片)
表 2. 不同语义变化检测方法在 HRSCD 和 SECOND 数据集上的性能比较。
| Method | #Params(M) | FLOPs(G) | HRSCD (F1/mIoU/OA/SeK) | SECOND (F1/mIoU/OA/SeK) |
|---|---|---|---|---|
| Bi-SRNet † 15 | 23.39 (100%) | 189.91 (100%) | 71.72 / 67.83 / 82.06 / 24.59 | 61.85 / 72.08 / 87.20 / 21.36 |
| Change3D | 1.66 (7%) | 15.19 (8%) | 73.29 / 68.67 / 82.57 / 26.85 | 62.83 / 72.95 / 87.42 / 22.98 |
表 3. 不同建筑物损伤评估方法在 xBD 数据集上的性能比较。
| Method | #Params(M) | FLOPs(G) | F1locF_1^{loc}F1loc | F1clsF_1^{cls}F1cls | F1overallF_1^{overall}F1overall |
|---|---|---|---|---|---|
| PCDASNet 72 | 26.00 (100%) | 95.9 (100%) | 85.48 | 73.83 | 77.33 |
| Change3D | 1.60 (6%) | 11.74 (12%) | 85.74 | 76.71 | 79.42 |
表 4. 不同变化描述方法在 LEVIR-CC 和 DUBAI-CC 数据集上的性能比较。
| Method | #Params(M) | FLOPs(G) | LEVIR-CC (B-4/M/R/C) | DUBAI-CC (B-4/M/R/C) |
|---|---|---|---|---|
| SEN 89 | 39.90 (100%) | 24.04 (100%) | 64.09 / 39.59 / 74.57 / 136.02 | 31.01 / 23.67 / 48.19 / 65.15 |
| Change3D | 5.05 (13%) | 2.39 (10%) | 64.38 / 40.03 / 75.12 / 138.29 | 36.80 / 27.06 / 56.04 / 86.19 |
从表 1-4 中,我们可以总结出以下关键发现:
- Change3D 在所有数据集和评估指标上均取得了优于或具有竞争力的性能。
- 与最先进的方法相比,我们提出的方法参数量减少了 ∼6%−13%\sim 6\% - 13\%∼6%−13%,FLOPs 减少了 ∼8%−34%\sim 8\% - 34\%∼8%−34%,并且推理速度最快。
- 我们提出的方法适用于 BCD, SCD, BDA 和 CC,无需重新设计架构,证明了 Change3D 的通用性。
4.3. 诊断性研究
不同架构的有效性。为了研究 Change3D 在不同 3D 架构下的有效性,我们使用基于 CNN 的(即 I3D, Slow-R50, X3D-L)和基于 Transformer 的(即 UniFormer-XS)模型进行了实验。表 5 显示,所有视频模型在与我们提出的方法集成时都表现出令人满意的性能,其中 X3D-L 表现最佳。
表 5. 在 xBD 数据集上研究不同 3D 架构的有效性。
| Method | F1_loc | F1_cls | F1_overall |
|---|---|---|---|
| I3D 3 | 84.45 | 74.32 | 77.36 |
| Slow-R50 22 | 85.52 | 74.36 | 77.71 |
| UniFormer-XS 40 | 85.56 | 76.11 | 78.94 |
| X3D-L 21 | 85.74 | 76.71 | 79.42 |
预训练权重的影响。如表 6 所示,我们探索了预训练权重对 Change3D 的影响。结果表明:(1) 不使用预训练权重,性能较差;(2) 尽管是在动作识别数据上训练的,但所有初始化权重都表现出优越的性能,表明 Change3D 能够有效地从动作识别领域迁移知识;(3) 利用 K400 的预训练权重取得了最佳结果。
表 6. 在 xBD 数据集上研究不同预训练权重的影响。
| Pre-trained | F1_overall |
|---|---|
| Random Init | 74.38 |
| AVA 27 | 77.94 |
| Charades 65 | 78.05 |
| SSv2 26 | 77.89 |
| K400 37 | 78.67 |
感知帧插入位置的影响。如表 7 所示,位于中间的"三明治式"感知帧表现出最佳性能。这主要归因于视频编码允许感知帧与其相邻的双时相图像有效地交互。
表 7. 在 xBD 数据集上研究感知帧插入位置的影响。
| Position | F1_overall |
|---|---|
| {IP1, IP2, I1, I2} | 78.58 |
| {I1, I2, IP1, IP2} | 78.53 |
| {I1, IP1, IP2, I2} | 79.42 |
获取感知特征的不同方式的影响。表 8 表明,选择(Selected)方法产生了优越的结果,通过感知帧和双时相图像之间的特征交互有效地捕捉了变化。
表 8. 在 xBD 数据集上研究获取感知特征的不同方式的影响。
| Method | F1_overall |
|---|---|
| FC | 78.79 |
| Max | 78.47 |
| Mean | 77.88 |
| Selected | 79.42 |
感知帧的有效性。我们在 HRSCD 和 SECOND 数据集上进行了实验。如表 9 所示,整合感知帧后性能有所提高,证明了其有效性。
注意力可视化。图 4 展示了注意力图。观察结果表明:(1) Change3D 的感知特征可以通过与双时相特征的交互有效地辨别变化,无需专用的变化提取器;(2) Change3D 有效地集中在变化区域。
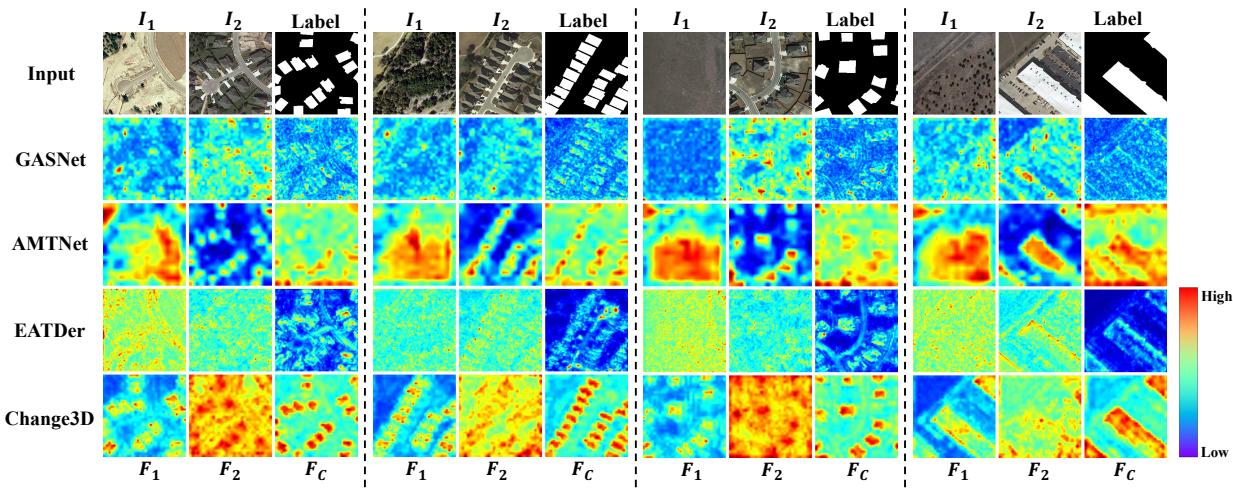
图 4. 双时相特征 F1F_{1}F1、F2F_{2}F2 和提取的变化 FCF_{C}FC 的可视化。我们的方法在视频编码期间直接关注变化,无需复杂的变化提取器。右侧的颜色条指示不同颜色的注意力分布。
5. 结论
本文介绍了一种名为 Change3D 的新范式,从视频建模的角度重新思考变化检测和描述。它将双时相图像视为由两帧组成的微型视频。通过在双时相图像之间整合可学习的感知帧,具有帧间建模能力的视频编码器实现了感知帧与图像之间的直接交互,使其能够辨别差异。此外,这种方法消除了对复杂的、特定任务的变化提取器的需求,提供了一个统一的框架。我们在八个公认的数据集上使用各种模型架构证明了 Change3D 的有效性。我们希望本文的见解能激发更多相关计算机视觉任务(如深度补全和图像抠图)的进一步研究。