文章目录
[Q: 为什么将功能分得这么细?](#Q: 为什么将功能分得这么细?)
[Q: 底层为什么使用vector<char> ,而不使用string?](#Q: 底层为什么使用vector
[Q:为什么把 Write 和 MoveWriteOffset 拆开?](#Q:为什么把 Write 和 MoveWriteOffset 拆开?)
[Q:关于muduo 的 prepend、readv 和 zero-copy 优化](#Q:关于muduo 的 prepend、readv 和 zero-copy 优化)
前言
路漫漫其修远兮,吾将上下而求索;
一、引言
TCP 协议本身拥有发送缓冲区和接收缓冲区(内核态,用于解决"可靠传输 + 流量控制"), 在应用层再实现一个网络缓冲区Buffer 为了解决粘报与半包问题。在高并发网络服务器中(eg.muduo),socket 的读写往往是不完整的。一次 read 可能读取不到完整业务数据,也可能读取多个请求。因此在 Reactor 模型中,须设计一个高效、可复用的网络缓冲区来管理数据的接收与发送。
**Buffer 的设计目标:**支持高效读写、减少内存拷贝、避免频繁扩容、接口与业务解耦
整体内存模型设计:
| 已读 | 可读 | 可写 |
↑r ↑w-
_reader_idx 指向可读的位置
-
_writer_idx 指向可写的位置
-
vector<char> 保存数据,自适应写空间保障机制
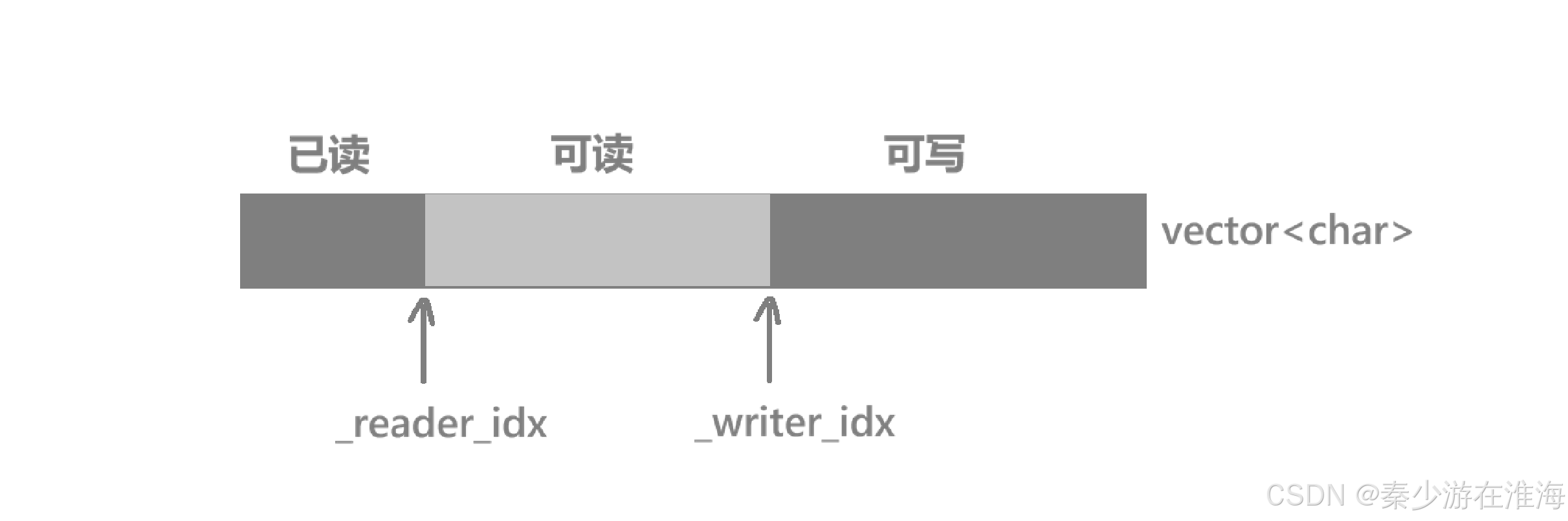
注:自适应写空间保障机制,实现一个接口( EnsureWriteSpace**),** 其逻辑为:判断尾部空间是否足够,尾部空间足够,直接返回;如果尾部空间不够,看头部空间+尾部空间是否能满足len;都不够的话就扩容;简单来说就是:尽量不扩容,实在不行才扩容;
二、实现
#pragma once
#include<iostream>
#include<vector>
#include<string>
#include<unistd.h>
#include<cstdint>
#include<assert.h>
#include<algorithm>
#include<string.h>
#define BUFFER_DEFAULT_SIZE 1024
//向buffer 中写入数据、读取数据的功能
class Buffer
{
public:
Buffer():_reader_idx(0),_writer_idx(0),_buffer(BUFFER_DEFAULT_SIZE)
{}
char* Begin(){return &(*_buffer.begin());}
char* WritePostion(){return _writer_idx + Begin();}
char* ReadPosition(){return _reader_idx + Begin();}
uint64_t TailIdleSize(){return _buffer.size()-_writer_idx;}
uint64_t HeadIdleSize(){ return _reader_idx;}
uint64_t ReadAbleSize(){ return _writer_idx - _reader_idx;}
void MoveReadOffset(uint64_t len){
if(len == 0) return;
assert(len <= ReadAbleSize());
_reader_idx += len;
}
void MoveWriteOffset(uint64_t len){
if(len == 0) return;
assert(len <= TailIdleSize());
_writer_idx += len;
}
//确保写入数据的时候空间足够
void EnsureWriteSpace(uint64_t len){
//判断尾部空间是否足够,尾部空间足够,直接返回;如果尾部空间不够,看头部空间+尾部空间是否能满足len;都不够的话就扩容
if(len <= TailIdleSize()) return;
else if( len <= TailIdleSize() + HeadIdleSize())
{
//挪动数据
uint64_t rez = ReadAbleSize();
std::copy(ReadPosition() , ReadPosition() + rez, Begin());
_reader_idx = 0;
_writer_idx = rez;
}
else{
//扩容
_buffer.resize(_writer_idx+len);
}
}
//写 - 写入void*数据、写并移动指针、写入string、写并移动指针、写入Buffer、写并移动指针
void Write(const void* data , uint64_t len)
{
if(len == 0) return;
EnsureWriteSpace(len);
const char* d = (const char*)data;
std::copy(d , d+len , WritePostion());
}
void WriteAndPush(const void* data , uint64_t len)
{
Write(data ,len);
MoveWriteOffset(len);
}
void WriteString(const std::string& data)
{
Write(data.c_str() , data.size());
}
void WriteStringAndPush(const std::string& data)
{
WriteString(data);
MoveWriteOffset(data.size());
}
void WriteBuffer(Buffer& data)
{
Write(data.ReadPosition(), data.ReadAbleSize());
}
void WriteBufferAndPush(Buffer& data)
{
WriteBuffer(data);
MoveWriteOffset(data.ReadAbleSize());
}
//读 - 读void* 数据、读并移动指针、读出string、读并移动指针、读取一行的数据、读并移动指针
void Read(void* buf , uint64_t len)
{
if(len <= 0) return;
assert(len <= ReadAbleSize());
std::copy(ReadPosition() , ReadPosition() + len, (char*)buf);
}
void ReadAndPop(void* buf , uint64_t len)
{
Read(buf , len);
MoveReadOffset(len);
}
std::string ReadAsString(uint64_t len)
{
// if(len <=0 ) return "";
assert(len <= ReadAbleSize());
std::string str;
str.resize(len);
Read(&str[0] , len);
return str;
}
std::string ReadAsStringAndPop(uint64_t len)
{
std::string str = ReadAsString(len);
MoveReadOffset(len);
return str;
}
//找到分隔符
char* FindCRLF()
{
char* res = (char*)memchr(ReadPosition(),'\n' ,ReadAbleSize());
return res;
}
std::string GetLine()
{
char * pos = FindCRLF();
if(pos == NULL)
{
return " ";
}
return ReadAsString(pos-ReadPosition()+1);
}
std::string GetLineAndPop()
{
std::string str = GetLine();
MoveReadOffset(str.size());
return str;
}
//清空缓冲区
void Clear()
{
_reader_idx = 0;
_writer_idx = 0;
}
private:
std::vector<char> _buffer;
uint64_t _reader_idx;
uint64_t _writer_idx;
};三、细节补充
Q:如何理解零拷贝?
工程里说的 zero-copy ≠ 完全没有拷贝,通常指的是:避免不必要的用户态内存 memcpy
zero-copy 这个"思想"主要由上层使用方式来完成,Buffer 只负责"不给你添乱",并提供实现 zero-copy 的可能性。
Q: 为什么将功能分得这么细?
细粒度接口可以把「数据操作」与「状态推进」解耦,从而提升正确性、灵活性和可维护性(更好实现协议解析部分的功能,网络 IO 的不确定性决定了接口必须解耦);
Buffer **不是vector<char>**的封装,也不是string 的替代品,而是一个:
维护读写状态的有限状态机
核心状态只有两个:_reader_idx、writer_idx
一切行为,都是围绕这两个状态是否推进、何时推进展开的;
Q:什么是状态机?
状态机 = 一个对象的行为,不取决于"你调用了什么函数",而取决于"它当前处于什么状态"
Buffer 的行为依赖"当前状态"
我们来看同一个函数,在不同状态下,行为完全不同:
例子:EnsureWriteSpace(len)
if (len <= TailIdleSize()) {
// 什么都不做
}
else if (len <= TailIdleSize() + HeadIdleSize()) {
// 整理数据
}
else {
// 扩容
}从上述代码中不难发现:**调用的是同一个函数,但做的事完全取决于当前状态 ,**这就是状态机的核心特征。
可以这么说,Buffer 管理的是「数据 + 状态」;
Q: 底层为什么使用vector<char> ,而使用不string?
- **网络中数据以二进制流的形式传输,**使用vector<char> 符合"字节流"直觉,且可以精准控制,而string的接口与使用习惯,围绕"文本"设计的,容易被误用为 C 字符串,在混用 c_str() 或 C 接口时,遇到'\0' 会引入隐性 bug;
- string 中存在标准库未定义的SSO (Small String Optimization 小字符串优化),基于这点string 的扩容是隐性的,对于使用者来说不好控制,易出错;而vector<char> 的扩容会走我们实现的接口 EnsureWriteSpace, 显性扩容,即便是扩容后指针失效,上层因为知道这点那么就可以自行解决,不容易出错;
Q:为什么把 Write 和 MoveWriteOffset 拆开?
- 在网络协议解析中,写入数据和提交数据不是同一件事。可以先写入数据,再判断是否构成完整协议包,只有确认无误后才推进写指针。这样可以避免半包情况下破坏 Buffer 状态。
Clear
将两个指针置空就行了,不用释放空间;
Q:此网络缓冲区与muduo库中的区别
设计思想是一致的,都是三段式内存模型。muduo 额外支持 prepend、readv 和 zero-copy 优化,本文的网络缓冲区更偏向基础版,结构更清晰,方便理解和扩展
Q:关于muduo 的 prepend、readv 和 zero-copy 优化
muduo 的 Buffer 不只是"能用",而是围绕高性能网络 IO 做了三类关键优化:prepend、readv 以及 zero-copy(零拷贝) ,分别解决协议封装、系统调用效率和数据拷贝成本问题。
prepend: 为"协议头"而生的前置空间设计(例如:Tcp协议的body 往往是先生成的,header 需要在最后才能确定(例如长度字段)); 带来的好处:不移动已有数据, O(1) 添加协议头
readv:减少系统调用 + 避免盲目扩容 ; 使用 read() 从 socket 读取数据时,不知道内核会返回多少字节,Buffer 尾部空间可能不够;传统方案中,要么提前扩容(浪费内存),要么读到临时缓冲区再拷贝;readv 一次系统调用将数据优先写入 Buffer,溢出数据暂存在栈空间,再统一 append;本质上是把"是否扩容"的决策推迟到 read 之后,用最小成本适配不确定的 IO 数据量。
zero-copy: 减少不必要的数据拷贝(避免用户态之间的 memcpy,不追求硬件级 DMA zero-copy)
总结
Buffer 的设计是对网络 IO 本质的尊重,看到这里就去动手写写吧~