目录
[1. 核心需求拆解](#1. 核心需求拆解)
[2. 非功能性需求](#2. 非功能性需求)
[阶段 1:全局配置模块开发](#阶段 1:全局配置模块开发)
[1.1 中文显示配置(核心痛点解决)](#1.1 中文显示配置(核心痛点解决))
[1.2 停用词表设计](#1.2 停用词表设计)
[1.3 可视化样式配置](#1.3 可视化样式配置)
[阶段 2:核心工具函数开发(基础依赖层)](#阶段 2:核心工具函数开发(基础依赖层))
[2.1 停用词加载函数(load_stopwords)](#2.1 停用词加载函数(load_stopwords))
[2.2 文本预处理函数(preprocess_text)](#2.2 文本预处理函数(preprocess_text))
[2.3 单块文本计数函数(count_chunk_freq)](#2.3 单块文本计数函数(count_chunk_freq))
[2.4 Counter 合并函数(merge_counters)](#2.4 Counter 合并函数(merge_counters))
[阶段 3:大规模文本处理模块开发](#阶段 3:大规模文本处理模块开发)
[阶段 4:多文本对比统计模块开发](#阶段 4:多文本对比统计模块开发)
[阶段 5:Plotly 动态可视化模块开发(核心难点)](#阶段 5:Plotly 动态可视化模块开发(核心难点))
[5.1 子图布局设计](#5.1 子图布局设计)
[5.2 各子图开发细节(核心痛点解决)](#5.2 各子图开发细节(核心痛点解决))
[(3)双字对关联网络:节点 / 边渲染优化](#(3)双字对关联网络:节点 / 边渲染优化)
[5.3 全局布局优化](#5.3 全局布局优化)
[阶段 6:多文本对比可视化模块开发](#阶段 6:多文本对比可视化模块开发)
[阶段 7:主函数开发(示例封装)](#阶段 7:主函数开发(示例封装))
[1. 单元测试(核心函数)](#1. 单元测试(核心函数))
[2. 集成测试(端到端)](#2. 集成测试(端到端))
[3. 边界测试](#3. 边界测试)
十、中文文本字频统计与交互式可视化工具的Python代码完整实现
一、引言
本文的项目是一个中文文本字频统计与交互式可视化工具的完整解决方案,开发过程遵循"需求拆解→技术选型→架构设计→模块实现→优化迭代→测试验证"的工程化思路,以下从全流程视角拆解每一步的开发决策、实现细节与问题解决思路。
二、开发前期:需求分析与核心目标
1. 核心需求拆解
开发前首先明确工具要解决的核心问题:
| 核心需求 | 具体描述 |
|---|---|
| 文本预处理 | 提取纯中文内容、过滤停用词(避免 "的 / 地 / 得" 等无意义词汇干扰统计) |
| 大规模文本处理 | 支持 GB 级大文本文件(避免一次性加载内存溢出),需分块 + 并行处理 |
| 多维度统计 | 统计单字出现频率、双字组合(邻接字对)频率 |
| 多文本对比 | 支持多份文本的字频 / 双字频对比分析 |
| 交互式可视化 | 生成可交互的图表(条形图、直方图、词云、热力图、关联网络),支持保存 HTML |
| 跨平台兼容 | 适配 Windows/Mac/Linux,解决中文显示、字体加载等兼容性问题 |
2. 非功能性需求
- 性能:大文本处理需多线程提速,时间复杂度控制在 O (n)(n 为文本长度);
- 易用性:函数封装化,参数可配置,示例代码直接运行;
- 鲁棒性:处理空文本、不存在的文件、异常字体路径等边界情况;
- 可扩展:停用词表支持自定义加载,可视化参数可配置。
三、技术选型阶段:库的选择与理由
基于需求,逐个确定核心依赖库,核心选型逻辑如下:
| 功能场景 | 选型结果 | 选型理由 |
|---|---|---|
| 基础数据处理 | numpy/pandas | pandas 擅长结构化数据透视(如热力图数据),numpy 辅助数值计算;轻量且高效 |
| 文本正则处理 | re | Python 内置库,无需额外安装,适配中文正则匹配([\u4e00-\u9fa5]+) |
| 频率统计 | collections.Counter | 内置高效的计数工具,支持增量更新、most_common () 排序,适配字频统计场景 |
| 大规模文本并行处理 | concurrent.futures.ThreadPoolExecutor | 线程池适配 IO 密集型任务(文件读取 + 文本处理),比多进程更轻量(避免进程开销) |
| 静态可视化基础 | matplotlib/seaborn | 作为 wordcloud 的底层依赖,同时解决基础绘图的中文配置问题 |
| 交互式可视化 | plotly(express/graph_objects) | 生成的 HTML 可交互(缩放、悬浮查看数值),支持复杂子图布局,跨平台展示 |
| 词云生成 | wordcloud | 成熟的词云生成库,支持自定义字体和颜色映射 |
| 关联网络分析 | networkx | 轻量的图论库,支持节点 / 边的构建与布局算法(spring_layout) |
四、架构设计阶段:代码模块划分
遵循"高内聚、低耦合"原则,将代码拆分为 6 个核心模块,模块间依赖关系如下:
bash
全局配置模块 → 核心工具函数模块 → 大规模文本处理模块
→ 多文本对比统计模块
→ Plotly动态可视化模块
→ 多文本对比可视化模块
→ 主函数(示例调用)模块设计的核心思路:
- 全局配置:抽离所有可配置参数(字体、颜色、停用词),避免硬编码;
- 核心工具函数:封装通用能力(停用词加载、文本预处理、计数、Counter 合并),作为基础依赖;
- 业务逻辑模块:基于工具函数实现 "大规模文本处理""多文本对比" 等场景化能力;
- 可视化模块:基于统计结果生成图表,与业务逻辑解耦(统计结果可单独使用);
- 主函数:提供示例调用,降低使用门槛。
五、分模块实现:从基础到核心,逐步开发
阶段 1:全局配置模块开发
目标:抽离所有可配置项,统一管理样式 / 常量,解决中文显示问题。
1.1 中文显示配置(核心痛点解决)
- 问题:matplotlib/plotly 默认不支持中文,直接绘图会出现 "□□□" 乱码;
- 解决方案:
- Matplotlib:设置
font.sans-serif为中文字体(SimHei / 微软雅黑),关闭负号显示异常(axes.unicode_minus=False); - Seaborn:强制绑定中文字体(
sns.set(font='SimHei')); - Plotly:自定义字体字典(PLOTLY_FONT),所有图表统一引用,避免重复配置。
- Matplotlib:设置
1.2 停用词表设计
- 需求:过滤无意义中文词汇,支持自定义加载;
- 实现:
- 内置基础停用词集合(STOPWORDS),覆盖代词、助词、数词、方位词等;
- 设计
load_stopwords函数,优先加载用户自定义文件,无文件时返回内置表; - 停用词使用
set类型(而非 list),因为in操作的时间复杂度为 O (1)(list 为 O (n)),提升过滤效率。
1.3 可视化样式配置
- 抽离颜色、字体大小、透明度等参数(如 PLOTLY_LINE_COLOR),后续可视化直接引用,便于统一修改样式。
阶段 2:核心工具函数开发(基础依赖层)
这是整个代码的 "地基",所有业务逻辑都依赖这些函数,开发时重点关注通用性、效率、鲁棒性。
2.1 停用词加载函数(load_stopwords)
python
def load_stopwords(file_path=None):
if file_path and os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f if line.strip()])
return stopwords
return STOPWORDS- 开发要点:
- 判空 + 文件存在性检查:避免传入空路径 / 不存在路径导致报错;
- 按行读取 + 去重:
strip()去除换行 / 空格,set自动去重; - 编码指定:强制
utf-8,避免不同系统默认编码(如 gbk)导致乱码。
2.2 文本预处理函数(preprocess_text)
python
def preprocess_text(text, stopwords=None):
chinese_pattern = re.compile(r'[\u4e00-\u9fa5]+')
chinese_chars = chinese_pattern.findall(text)
clean_text = ''.join(chinese_chars)
stopwords = stopwords or load_stopwords()
filtered_text = ''.join([char for char in clean_text if char not in stopwords])
return filtered_text- 核心问题解决:
- 只保留中文:用正则
[\u4e00-\u9fa5]+匹配所有中文字符,过滤标点、数字、英文; - 停用词过滤:遍历清洗后的中文字符,剔除停用词;
- 参数默认值:
stopwords=None时自动加载内置表,提升易用性。
- 只保留中文:用正则
2.3 单块文本计数函数(count_chunk_freq)
python
def count_chunk_freq(chunk_text, stopwords=None):
clean_chunk = preprocess_text(chunk_text, stopwords)
single_counter = Counter(clean_chunk)
pair_list = []
if len(clean_chunk) >= 2:
for i in range(len(clean_chunk) - 1):
pair = clean_chunk[i] + clean_chunk[i + 1]
pair_list.append(pair)
pair_counter = Counter(pair_list)
return single_counter, pair_counter- 开发思路:
- 先预处理再计数:保证计数的是 "纯中文无停用词" 内容;
- 单字计数:直接用
Counter(clean_chunk)(字符串可迭代); - 双字对计数:遍历文本,取相邻两个字符组成 "字对"(如 "人工""智能"),边界判断(长度≥2)避免索引越界;
- 返回双 Counter:分别对应单字 / 双字频,便于后续合并。
2.4 Counter 合并函数(merge_counters)
python
def merge_counters(counter_list):
merged = Counter()
for cnt in counter_list:
merged.update(cnt)
return merged- 核心作用:解决多线程分块处理后的计数合并问题,
Counter.update()支持增量合并(而非覆盖),是分块统计的关键。
阶段 3:大规模文本处理模块开发
目标:支持大文本文件分块 + 多线程处理,避免内存溢出,提升效率。
python
def count_large_text(file_path, chunk_size=1024 * 1024, max_workers=4, stopwords=None):
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在:{file_path}")
single_counter_list = []
pair_counter_list = []
with open(file_path, 'r', encoding='utf-8') as f, ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = []
while True:
chunk = f.read(chunk_size) # 分块读取(1MB/块)
if not chunk:
break
future = executor.submit(count_chunk_freq, chunk, stopwords)
futures.append(future)
for future in as_completed(futures):
single_cnt, pair_cnt = future.result()
single_counter_list.append(single_cnt)
pair_counter_list.append(pair_cnt)
global_single = merge_counters(single_counter_list)
global_pair = merge_counters(pair_counter_list)
return global_single, global_pair开发关键决策:
- 分块读取:
f.read(chunk_size)按 1MB 分块(可配置),避免一次性加载大文件到内存; - 线程池选择:
- 文本处理是 "IO 密集型"(文件读取 + 轻量计算),线程池比多进程更高效(无进程间通信开销);
max_workers=4:默认 4 线程,适配多数 CPU 核心数,可根据文件大小调整;
- 异步获取结果:
as_completed(futures)按任务完成顺序获取结果,而非提交顺序,提升效率; - 异常处理:先检查文件是否存在,抛出明确的
FileNotFoundError,避免模糊报错。
阶段 4:多文本对比统计模块开发
目标:支持 "文本内容 / 文件路径" 混合输入,统一统计多文本的字频 / 双字频。
python
def count_multi_texts(text_dict, stopwords=None):
result_dict = {}
for name, content in text_dict.items():
if os.path.exists(content):
file_size = os.path.getsize(content)
if file_size > 10 * 1024 * 1024: # 大于10MB的文件走大规模处理逻辑
single_cnt, pair_cnt = count_large_text(content, stopwords=stopwords)
else:
with open(content, 'r', encoding='utf-8') as f:
text = f.read()
clean_text = preprocess_text(text, stopwords)
single_cnt, pair_cnt = count_chunk_freq(clean_text, stopwords)
else:
clean_text = preprocess_text(content, stopwords)
single_cnt, pair_cnt = count_chunk_freq(clean_text, stopwords)
result_dict[name] = (single_cnt, pair_cnt)
return result_dict核心设计:
- 输入兼容:
text_dict的 value 可以是 "文本字符串" 或 "文件路径",自动识别; - 自适应处理逻辑:
- 小于 10MB 的文件:直接读取全量内容处理(减少分块开销);
- 大于 10MB 的文件:调用
count_large_text分块 + 多线程处理;
- 结果存储:用字典映射 "文本名称→(单字 Counter, 双字 Counter)",便于后续对比可视化。
阶段 5:Plotly 动态可视化模块开发(核心难点)
目标:基于统计结果生成 6 个子图的交互式仪表盘,解决中文、字体、布局等问题。
5.1 子图布局设计
首先确定子图的行列分布:
- 行数:2 行,列数:3 列;
- 子图 1(1 行 1 列):TopN 单字条形图;
- 子图 2(1 行 2 列):单字字频分布直方图;
- 子图 3(1 行 3 列):单字词云;
- 子图 4(2 行 1 列):TopN 双字条形图;
- 子图 5(2 行 2 列):双字对热力图;
- 子图 6(2 行 3 列):双字对关联网络;
通过make_subplots实现布局,核心代码:
python
fig = make_subplots(
rows=2, cols=3,
subplot_titles=(
f'Top{top_n}单字字频', '单字字频分布', '单字词云',
f'Top{top_n}双字字频', '双字对热力图', '双字对关联网络'
),
specs=[
[{"type": "bar"}, {"type": "histogram"}, {"type": "image"}],
[{"type": "bar"}, {"type": "heatmap"}, {"type": "scatter"}]
]
)specs参数:指定每个子图的类型(如 bar/heatmap/image),Plotly 会自动适配渲染逻辑;
5.2 各子图开发细节(核心痛点解决)
(1)词云子图:跨平台字体兼容
-
核心问题:不同系统的中文字体路径不同,wordcloud 默认无中文字体,直接生成会乱码;
-
解决方案:
pythonfont_path = None if os.name == 'nt': # Windows font_path = 'C:/Windows/Fonts/simhei.ttf' # 黑体路径 elif os.name == 'posix': # Linux/Mac mac_fonts = ['/System/Library/Fonts/PingFang.ttc', '/Library/Fonts/Arial Unicode.ttf'] linux_fonts = ['/usr/share/fonts/truetype/liberation/LiberationSans-Regular.ttf'] for f in mac_fonts + linux_fonts: if os.path.exists(f): font_path = f break # 兜底方案:无指定字体时使用默认配置 wc_kwargs = {"width": 800, "height": 400, "background_color": "white", "max_words": 100} if font_path and os.path.exists(font_path): wc_kwargs["font_path"] = font_path wc = WordCloud(**wc_kwargs).generate_from_frequencies(dict(single_counter)) -
逻辑:先判断系统类型,再匹配对应字体路径,最后兜底,确保词云能正常显示中文。
(2)双字对热力图:数据透视处理
-
核心问题:双字对是 "前字 + 后字" 的组合,需转换为二维矩阵(行 = 前字,列 = 后字,值 = 次数);
-
解决方案:
pythonpair_top10 = pair_counter.most_common(10) front = [p[0][0] for p in pair_top10] back = [p[0][1] for p in pair_top10] values = [p[1] for p in pair_top10] pivot_df = pd.DataFrame({ '前字': front, '后字': back, '次数': values }).pivot(index='前字', columns='后字', values='次数').fillna(0) -
关键:用
pd.pivot实现长表转宽表,fillna(0)填充无数据的单元格,避免热力图出现空值。
(3)双字对关联网络:节点 / 边渲染优化
- 核心问题:网络图节点重叠、边粗细无区分,可视化效果差;
- 解决方案:
- 节点布局:用
nx.spring_layout(G, seed=42, k=2),seed=42保证布局固定,k=2增大节点间距; - 边粗细:按双字对次数缩放(
weight=count/5),次数越多边越粗; - 边样式:用半透明灰色(PLOTLY_LINE_COLOR),避免边过多导致视觉杂乱;
- 节点标注:在节点中心显示汉字,提升可读性。
- 节点布局:用
5.3 全局布局优化
- 统一字体:所有子图的坐标轴、标题都引用全局配置的 PLOTLY_FONT,避免样式混乱;
- 尺寸适配:设置
height=1000, width=1400,平衡子图大小与整体可读性; - 保存与展示:
fig.write_html(save_html)保存为 HTML(可离线打开),fig.show()直接渲染。
阶段 6:多文本对比可视化模块开发
目标:生成分组条形图,对比多文本的 TopN 单字 / 双字频,解决 "字符对齐" 问题。
python
def plot_multi_texts_compare(result_dict, top_n=15, save_html="multi_text_compare.html"):
text_names = list(result_dict.keys())
# 单字对比数据:收集所有文本的TopN字符,统一维度
single_compare_data = {}
all_single_chars = set()
for name in text_names:
single_top = result_dict[name][0].most_common(top_n)
chars = [item[0] for item in single_top]
counts = [item[1] for item in single_top]
single_compare_data[name] = dict(zip(chars, counts))
all_single_chars.update(chars)
all_single_chars = list(all_single_chars)[:top_n] # 统一取前N个字符
# 双字对比数据:逻辑同上
# ...
# 分组条形图:每个文本对应一组条形
for i, name in enumerate(text_names):
y_vals = [single_compare_data[name].get(char, 0) for char in all_single_chars]
fig.add_trace(go.Bar(x=all_single_chars, y=y_vals, name=name), row=1, col=1)- 核心解决:不同文本的 TopN 字符可能不同,需收集所有文本的字符并统一维度,缺失的字符计数为 0,保证条形图 x 轴对齐。
阶段 7:主函数开发(示例封装)
目标:提供 3 个典型示例,降低用户使用门槛:
- 小文本基础统计 + 可视化;
- 多文本对比分析;
- 大规模文件处理(需替换实际路径);
- 示例代码覆盖所有核心函数,用户可直接运行,也可替换为自己的文本 / 文件路径。
六、优化迭代阶段:解决开发中的核心问题
开发过程中遇到的关键问题及优化方案:
| 问题场景 | 初始问题 | 优化方案 |
|---|---|---|
| 中文显示 | 词云 / 图表出现乱码 | 1. 统一配置中文字体路径;2. Plotly 所有文本引用自定义字体字典;3. 多字体兼容(SimHei / 微软雅黑) |
| 大文本处理效率 | 单线程处理 1GB 文件耗时 > 10 分钟 | 1. 分块读取 + 线程池;2. Counter 合并优化;3. 提前终止无效遍历 |
| 网络图节点重叠 | 节点挤在一起,无法区分 | 1. 设置 spring_layout 的 k 值增大间距;2. 固定 seed 保证布局可复现;3. 节点大小统一(20px) |
| 热力图空值报错 | 双字对无重叠时 pivot_df 有空值 | fillna(0)填充空值,避免 Plotly 渲染热力图时报错 |
| 跨平台兼容性 | Mac/Linux 无 simhei.ttf 字体 | 适配不同系统的默认中文字体路径(PingFang/Arial Unicode) |
| 可视化样式混乱 | 各子图字体 / 颜色不统一 | 抽离全局样式常量(PLOTLY_FONT/PLOTLY_LINE_COLOR),所有子图统一引用 |
七、测试验证阶段:覆盖全场景测试
1. 单元测试(核心函数)
preprocess_text:测试含标点 / 英文 / 数字的文本,验证仅保留中文且过滤停用词;count_chunk_freq:测试空文本、单字符文本、长文本,验证计数准确性;merge_counters:测试多 Counter 合并,验证增量更新正确;
2. 集成测试(端到端)
- 小文本测试:运行示例 1,验证可视化 HTML 生成正常,图表数据与手动统计一致;
- 多文本对比测试:运行示例 2,验证分组条形图对齐,数值正确;
- 大文件测试:用 100MB 中文文本测试
count_large_text,验证内存占用 < 500MB,耗时 < 2 分钟; - 跨平台测试:在 Windows10、MacOS 14、Ubuntu 22.04 分别运行,验证无乱码、无报错。
3. 边界测试
- 空文本:验证返回空 Counter,无报错;
- 不存在的文件:验证抛出明确的 FileNotFoundError;
- 纯停用词文本:验证计数为空,可视化正常(无崩溃);
- 自定义停用词表:验证加载后过滤逻辑生效。
八、最终交付:代码封装与易用性优化
- 注释完善:为所有函数添加 docstring,说明参数、返回值、功能;
- 变量命名:使用语义化命名(如
single_counter而非cnt1); - 示例丰富:提供 3 个典型示例,覆盖不同使用场景;
- 配置抽离:所有可调整参数(如 chunk_size、top_n)都作为函数参数,支持自定义;
- 错误提示:明确的异常信息,指导用户解决问题(如 "请替换为实际的大文本文件路径")。
九、中文文本
 中的中文文本(可以替换)如下:
中的中文文本(可以替换)如下:
bash
中国人工智能产业发展与社会变革
人工智能是引领新一轮科技革命和产业变革的核心驱动力,它的出现与发展,正在深刻改变我们的生产方式、生活形态,也重塑着你我他之间的连接方式。在这个快速迭代的时代,能否抓住人工智能发展的机遇,是关乎国家竞争力的关键,也是每个普通人都能感知到的变革。
从政策层面看,中国的人工智能发展之路,有顶层设计的指引,也有地方实践的探索。为了推动技术落地,国家先后出台了一系列政策,把人工智能纳入战略性新兴产业,为企业创新铺路,也为科研攻关赋能。你能看到,从东部的长三角到西部的成渝地区,从南部的粤港澳到北部的京津冀,人工智能的应用场景正在遍地开花,它的价值不仅体现在数字经济的增长上,也体现在民生服务的改善中。
在技术应用的层面,人工智能的能力早已突破了早期的语音识别、图像分类,它能处理海量数据,也能模拟人类的逻辑思维,甚至可以在医疗、教育、交通等领域替代人工完成复杂的工作。我们常说,科技的进步是为了让生活更美好,而人工智能恰恰做到了这一点:它让偏远地区的患者能得到一线城市专家的诊断,让不同年龄的学习者能获得个性化的教学方案,也让城市的交通系统变得更智能、更高效。
当然,人工智能的发展也有两面性。因技术迭代过快,部分传统岗位面临被替代的风险;果是,社会需要建立新的职业培训体系,帮助劳动者适应变革。如你所见,工厂里的流水线工人可能需要学习新的技能,办公室的文员也得掌握智能工具的使用方法,而这些变化,都需要时间和耐心去适应。若只看到人工智能的便利,而忽视其带来的社会挑战,那么技术的价值就会打折扣。
从微观的生活场景来看,人工智能已经融入了我们的日常:早晨醒来,你用语音助手打开窗帘、播放新闻;上班路上,智能导航为你规划最优路线,避开拥堵;工作中,智能办公软件帮你整理文档、分析数据;晚上回家,智能家居根据你的习惯调节温度、灯光。这些看似微小的细节,却实实在在地提升了生活的幸福感。他们常说,科技的温度体现在细节里,而人工智能的普及,正是把这种温度传递到了千家万户。
在产业生态方面,中国的人工智能企业既有百度、阿里、腾讯这样的巨头,也有无数深耕细分领域的初创公司。它们的竞争与合作,推动着技术的不断升级,也让中国在全球人工智能领域占据了一席之地。我们可以看到,从算法研发到算力支撑,从数据安全到伦理规范,中国的人工智能产业正在形成完整的闭环,而这一切,都离不开政策、资本、人才的共同发力。
虽人工智能的发展速度令人惊叹,但我们也必须保持理性:它是工具,而非万能的解决方案。但凡是技术,都有其局限性,比如在情感理解、创造性思维等方面,人工智能还无法与人类相比。也正因如此,人机协同才是未来的主流方向------让机器做擅长的事,让人发挥独特的价值,这样的模式,才能让人工智能真正服务于人类社会。
从时间维度看,人工智能的发展不过几十年,而它对人类文明的影响,却可能持续上百年、上千年。一万年太久,只争朝夕,我们既要把握当下的发展机遇,也要为长远的未来做好规划。百亿、千亿的投资背后,是国家对科技自立自强的追求;而每个普通人的参与和理解,才是人工智能产业行稳致远的基础。
在空间维度上,人工智能的应用没有地域的界限:上至太空探索,下至深海作业,左至工业制造,右至文创产业,前至城市规划,后至历史文化保护,里至家庭生活,外至国际合作,中至国家治理,间至社区服务,旁至乡村振兴,都能看到人工智能的身影。它让东与西、南与北的资源实现了高效调配,也让不同国家、不同文化之间的交流变得更便捷。
啊,人工智能的魅力,就在于它总能超出我们的想象!呀,当你第一次用智能翻译与外国友人顺畅交流时,当你看到人工智能画出的艺术作品时,当你体验到自动驾驶带来的轻松时,你会不会感叹科技的神奇?吗?或许会的。呢?因为它不仅改变了我们的生活方式,也拓展了人类认知的边界。吧,让我们以开放的心态拥抱人工智能,既不盲目追捧,也不刻意排斥,这样才能在技术变革中找到属于自己的位置。
哦,还有一点不能忽视:人工智能的伦理与安全问题。呵,随着技术的普及,数据泄露、算法偏见等问题也逐渐暴露,这些都需要法律法规来规范,也需要企业和开发者坚守底线。哈,技术本身没有对错,关键在于使用它的人。唉,我们见过太多因技术滥用而引发的问题,因此,在推动人工智能发展的同时,必须把伦理和安全放在首位。嗯,这既是对技术负责,也是对社会负责。
总结来说,人工智能的发展是时代的必然,它的价值不在于技术本身有多先进,而在于能否真正解决社会的痛点、满足人们的需求。我们、你们、他们,都是这场变革的参与者和受益者,而唯有保持理性、包容、创新的态度,才能让人工智能在推动社会进步的同时,守住人文的温度。在未来的日子里,人工智能还会不断进化,而我们所要做的,就是以不变的人文关怀,应对万变的技术变革,让科技与人性共生,让发展与温度同行。十、中文文本字频统计与交互式可视化工具的Python代码完整实现
python
# 基础库
import re
import os
import math
import numpy as np
import pandas as pd
from collections import Counter
from concurrent.futures import ThreadPoolExecutor, as_completed
# 可视化库
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
import networkx as nx
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# -------------------------- 全局配置 --------------------------
# ========== Matplotlib中文配置 ==========
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'] # 多字体兼容
plt.rcParams['axes.unicode_minus'] = False
sns.set_style("whitegrid")
sns.set(font='SimHei') # 强制Seaborn使用中文字体
# ========== Plotly中文配置 ==========
PLOTLY_FONT = dict(family="SimHei, Microsoft YaHei, sans-serif", size=12)
PLOTLY_TITLE_FONT = dict(family="SimHei, Microsoft YaHei, sans-serif", size=16, weight='bold') # 子图标题字体
PLOTLY_GLOBAL_TITLE_FONT = dict(family="SimHei, Microsoft YaHei, sans-serif", size=20, weight='bold') # 全局标题字体
PLOTLY_LINE_COLOR = 'rgba(128, 128, 128, 0.6)' # 灰色带60%透明度(替代line.opacity)
# 内置中文停用词表
STOPWORDS = {
'的', '地', '得', '我', '你', '他', '她', '它', '我们', '你们', '他们', '她们', '它们',
'是', '在', '有', '能', '会', '可以', '要', '把', '被', '为', '与', '和', '及', '或',
'之', '于', '而', '则', '因', '果', '如', '若', '虽', '但', '也', '还', '都', '只',
'了', '着', '过', '啊', '呀', '吗', '呢', '吧', '哦', '呵', '哈', '唉', '嗯',
'一', '二', '三', '四', '五', '六', '七', '八', '九', '十', '百', '千', '万', '亿',
'上', '下', '左', '右', '前', '后', '里', '外', '中', '间', '旁', '东', '西', '南', '北'
}
# -------------------------- 核心工具函数 --------------------------
def load_stopwords(file_path=None):
"""加载停用词表"""
if file_path and os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
stopwords = set([line.strip() for line in f if line.strip()])
return stopwords
return STOPWORDS
def preprocess_text(text, stopwords=None):
"""文本预处理:提取汉字+过滤停用词"""
chinese_pattern = re.compile(r'[\u4e00-\u9fa5]+')
chinese_chars = chinese_pattern.findall(text)
clean_text = ''.join(chinese_chars)
stopwords = stopwords or load_stopwords()
filtered_text = ''.join([char for char in clean_text if char not in stopwords])
return filtered_text
def count_chunk_freq(chunk_text, stopwords=None):
"""单块文本字频统计"""
clean_chunk = preprocess_text(chunk_text, stopwords)
single_counter = Counter(clean_chunk)
pair_list = []
if len(clean_chunk) >= 2:
for i in range(len(clean_chunk) - 1):
pair = clean_chunk[i] + clean_chunk[i + 1]
pair_list.append(pair)
pair_counter = Counter(pair_list)
return single_counter, pair_counter
def merge_counters(counter_list):
"""合并Counter列表"""
merged = Counter()
for cnt in counter_list:
merged.update(cnt)
return merged
# -------------------------- 1. 大规模文本处理 --------------------------
def count_large_text(file_path, chunk_size=1024 * 1024, max_workers=4, stopwords=None):
"""分块+多线程处理大文本"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在:{file_path}")
single_counter_list = []
pair_counter_list = []
with open(file_path, 'r', encoding='utf-8') as f, ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = []
while True:
chunk = f.read(chunk_size)
if not chunk:
break
future = executor.submit(count_chunk_freq, chunk, stopwords)
futures.append(future)
for future in as_completed(futures):
single_cnt, pair_cnt = future.result()
single_counter_list.append(single_cnt)
pair_counter_list.append(pair_cnt)
global_single = merge_counters(single_counter_list)
global_pair = merge_counters(pair_counter_list)
return global_single, global_pair
# -------------------------- 2. 多文本对比统计 --------------------------
def count_multi_texts(text_dict, stopwords=None):
"""多文本字频统计"""
result_dict = {}
for name, content in text_dict.items():
if os.path.exists(content):
file_size = os.path.getsize(content)
if file_size > 10 * 1024 * 1024:
single_cnt, pair_cnt = count_large_text(content, stopwords=stopwords)
else:
with open(content, 'r', encoding='utf-8') as f:
text = f.read()
clean_text = preprocess_text(text, stopwords)
single_cnt, pair_cnt = count_chunk_freq(clean_text, stopwords)
else:
clean_text = preprocess_text(content, stopwords)
single_cnt, pair_cnt = count_chunk_freq(clean_text, stopwords)
result_dict[name] = (single_cnt, pair_cnt)
return result_dict
# -------------------------- 3. Plotly动态可视化 --------------------------
def plotly_dynamic_visual(single_counter, pair_counter, top_n=20, save_html="char_freq_dynamic.html"):
"""交互式可视化"""
# 准备数据
single_top = single_counter.most_common(top_n)
single_chars = [item[0] for item in single_top]
single_counts = [item[1] for item in single_top]
pair_top = pair_counter.most_common(top_n)
pair_chars = [item[0] for item in pair_top]
pair_counts = [item[1] for item in pair_top]
fig = make_subplots(
rows=2, cols=3,
subplot_titles=(
f'Top{top_n}单字字频', '单字字频分布', '单字词云',
f'Top{top_n}双字字频', '双字对热力图', '双字对关联网络'
),
specs=[
[{"type": "bar"}, {"type": "histogram"}, {"type": "image"}],
[{"type": "bar"}, {"type": "heatmap"}, {"type": "scatter"}]
]
)
fig.update_annotations(
font=PLOTLY_TITLE_FONT,
align='center'
)
# 子图1:TopN单字条形图
fig.add_trace(
go.Bar(
x=single_chars, y=single_counts, name='单字字频',
marker_color='royalblue',
text=single_counts, textposition='auto'
),
row=1, col=1
)
fig.update_xaxes(tickangle=45, row=1, col=1, tickfont=PLOTLY_FONT)
fig.update_yaxes(title_text='出现次数', row=1, col=1, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
# 子图2:单字字频分布直方图
single_all = list(single_counter.values())
fig.add_trace(
go.Histogram(
x=single_all, nbinsx=20, name='字频分布',
marker_color='green', opacity=0.7
),
row=1, col=2
)
fig.update_xaxes(title_text='出现次数区间', row=1, col=2, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
fig.update_yaxes(title_text='汉字数量', row=1, col=2, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
# 子图3:单字词云(多系统兼容)
# 优化字体路径兼容性
font_path = None
if os.name == 'nt': # Windows
font_path = 'C:/Windows/Fonts/simhei.ttf'
elif os.name == 'posix': # Linux/Mac
mac_fonts = ['/System/Library/Fonts/PingFang.ttc', '/Library/Fonts/Arial Unicode.ttf']
linux_fonts = ['/usr/share/fonts/truetype/liberation/LiberationSans-Regular.ttf',
'/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf']
for f in mac_fonts + linux_fonts:
if os.path.exists(f):
font_path = f
break
# 兜底方案:如果找不到系统字体,使用wordcloud默认兼容
wc_kwargs = {"width": 800, "height": 400, "background_color": "white", "max_words": 100, "colormap": "viridis"}
if font_path and os.path.exists(font_path):
wc_kwargs["font_path"] = font_path
wc = WordCloud(**wc_kwargs).generate_from_frequencies(dict(single_counter))
wc_array = wc.to_array()
fig.add_trace(
go.Image(z=wc_array),
row=1, col=3
)
fig.update_xaxes(visible=False, row=1, col=3)
fig.update_yaxes(visible=False, row=1, col=3)
# 子图4:TopN双字条形图
fig.add_trace(
go.Bar(
x=pair_chars, y=pair_counts, name='双字字频',
marker_color='crimson',
text=pair_counts, textposition='auto'
),
row=2, col=1
)
fig.update_xaxes(tickangle=45, row=2, col=1, tickfont=PLOTLY_FONT)
fig.update_yaxes(title_text='出现次数', row=2, col=1, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
# 子图5:双字对热力图
pair_top10 = pair_counter.most_common(10)
front = [p[0][0] for p in pair_top10]
back = [p[0][1] for p in pair_top10]
values = [p[1] for p in pair_top10]
pivot_df = pd.DataFrame({
'前字': front, '后字': back, '次数': values
}).pivot(index='前字', columns='后字', values='次数').fillna(0)
fig.add_trace(
go.Heatmap(
x=pivot_df.columns, y=pivot_df.index, z=pivot_df.values,
colorscale='YlGnBu', text=pivot_df.values, texttemplate="%{text}",
xgap=2, ygap=2
),
row=2, col=2
)
fig.update_xaxes(title_text='后字', row=2, col=2, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
fig.update_yaxes(title_text='前字', row=2, col=2, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
# 子图6:双字对关联网络图(优化渲染)
G = nx.Graph()
for pair, count in pair_top:
G.add_edge(pair[0], pair[1], weight=count / 5)
pos = nx.spring_layout(G, seed=42, k=2) # 调整k值让节点分布更合理
node_x = [pos[node][0] for node in G.nodes()]
node_y = [pos[node][1] for node in G.nodes()]
fig.add_trace(
go.Scatter(
x=node_x, y=node_y, mode='markers+text',
marker=dict(size=20, color='skyblue', opacity=0.8),
text=list(G.nodes()), textposition='middle center',
textfont=PLOTLY_FONT,
name='节点',
hoverinfo='text'
),
row=2, col=3
)
for edge in G.edges():
x0, y0 = pos[edge[0]]
x1, y1 = pos[edge[1]]
fig.add_trace(
go.Scatter(
x=[x0, x1], y=[y0, y1], mode='lines',
line=dict(
width=G[edge[0]][edge[1]]['weight'],
color=PLOTLY_LINE_COLOR
),
name='边', showlegend=False,
opacity=0.6,
hoverinfo='none'
),
row=2, col=3
)
fig.update_xaxes(visible=False, row=2, col=3)
fig.update_yaxes(visible=False, row=2, col=3)
# 全局布局
fig.update_layout(
height=1000, width=1400,
title_text="单字+双字字频统计(交互式可视化)",
title_font=PLOTLY_GLOBAL_TITLE_FONT,
showlegend=False,
font=PLOTLY_FONT,
margin=dict(l=50, r=50, t=80, b=50)
)
fig.write_html(save_html)
fig.show()
# -------------------------- 4. 多文本对比可视化 --------------------------
def plot_multi_texts_compare(result_dict, top_n=15, save_html="multi_text_compare.html"):
"""多文本对比可视化(修复子图标题字体)"""
text_names = list(result_dict.keys())
# 单字对比数据
single_compare_data = {}
all_single_chars = set()
for name in text_names:
single_top = result_dict[name][0].most_common(top_n)
chars = [item[0] for item in single_top]
counts = [item[1] for item in single_top]
single_compare_data[name] = dict(zip(chars, counts))
all_single_chars.update(chars)
all_single_chars = list(all_single_chars)[:top_n]
# 双字对比数据
pair_compare_data = {}
all_pair_chars = set()
for name in text_names:
pair_top = result_dict[name][1].most_common(top_n)
pairs = [item[0] for item in pair_top]
counts = [item[1] for item in pair_top]
pair_compare_data[name] = dict(zip(pairs, counts))
all_pair_chars.update(pairs)
all_pair_chars = list(all_pair_chars)[:top_n]
fig = make_subplots(
rows=1, cols=2,
subplot_titles=(f'Top{top_n}单字对比', f'Top{top_n}双字对比'),
specs=[[{"type": "bar"}, {"type": "bar"}]]
)
fig.update_annotations(
font=PLOTLY_TITLE_FONT,
align='center'
)
# 单字对比条形图
for i, name in enumerate(text_names):
y_vals = [single_compare_data[name].get(char, 0) for char in all_single_chars]
fig.add_trace(
go.Bar(
x=all_single_chars, y=y_vals, name=name,
text=y_vals, textposition='auto'
),
row=1, col=1
)
# 双字对比条形图
for i, name in enumerate(text_names):
y_vals = [pair_compare_data[name].get(pair, 0) for pair in all_pair_chars]
fig.add_trace(
go.Bar(
x=all_pair_chars, y=y_vals, name=name,
text=y_vals, textposition='auto'
),
row=1, col=2
)
# 布局调整
fig.update_xaxes(tickangle=45, row=1, col=1, tickfont=PLOTLY_FONT)
fig.update_xaxes(tickangle=45, row=1, col=2, tickfont=PLOTLY_FONT)
fig.update_yaxes(title_text='出现次数', row=1, col=1, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
fig.update_yaxes(title_text='出现次数', row=1, col=2, titlefont=PLOTLY_FONT, tickfont=PLOTLY_FONT)
fig.update_layout(
height=600, width=1400,
title_text="多文本字频对比分析",
title_font=PLOTLY_GLOBAL_TITLE_FONT,
barmode='group',
font=PLOTLY_FONT,
legend=dict(font=PLOTLY_FONT)
)
# 核心修复:移除encoding参数
fig.write_html(save_html)
fig.show()
# -------------------------- 主函数 --------------------------
if __name__ == '__main__':
# 示例1:小文本处理
print("===== 示例1:小文本基础统计 =====")
sample_text1 = """
人工智能是引领新一轮科技革命和产业变革的重要驱动力,加快发展新一代人工智能是事关我国能否抓住新一轮科技革命和产业变革机遇的战略问题。
中国高度重视人工智能发展,先后出台一系列政策举措,推动人工智能领域的研发和应用。从语音识别到图像分类,从智能推荐到自动驾驶,人工智能技术已经深度融入人们的生产生活,带来了前所未有的便利。
"""
sample_text2 = """
大语言模型是人工智能的重要分支,基于海量文本数据训练,能够理解和生成自然语言。中国在大语言模型领域的研发投入持续加大,百度文心一言、阿里通义千问等模型不断迭代升级,推动人工智能应用场景进一步拓展。
"""
stopwords = load_stopwords()
clean_text1 = preprocess_text(sample_text1, stopwords)
single_cnt1, pair_cnt1 = count_chunk_freq(clean_text1, stopwords)
plotly_dynamic_visual(single_cnt1, pair_cnt1, top_n=15, save_html="single_text_dynamic.html")
# 示例2:多文本对比
print("\n===== 示例2:多文本对比 =====")
text_dict = {
"人工智能政策": sample_text1,
"大语言模型发展": sample_text2
}
multi_result = count_multi_texts(text_dict, stopwords)
plot_multi_texts_compare(multi_result, top_n=10, save_html="multi_text_compare.html")
# 示例3:大规模文件处理
print("\n===== 示例3:大规模文件处理 =====")
large_file_path = "large_text_file.txt"
if os.path.exists(large_file_path):
large_single, large_pair = count_large_text(large_file_path, stopwords=stopwords)
plotly_dynamic_visual(large_single, large_pair, top_n=20, save_html="large_text_dynamic.html")
else:
print("请替换为实际的大文本文件路径后运行此示例")十一、程序运行结果展示
===== 示例1:小文本基础统计 =====
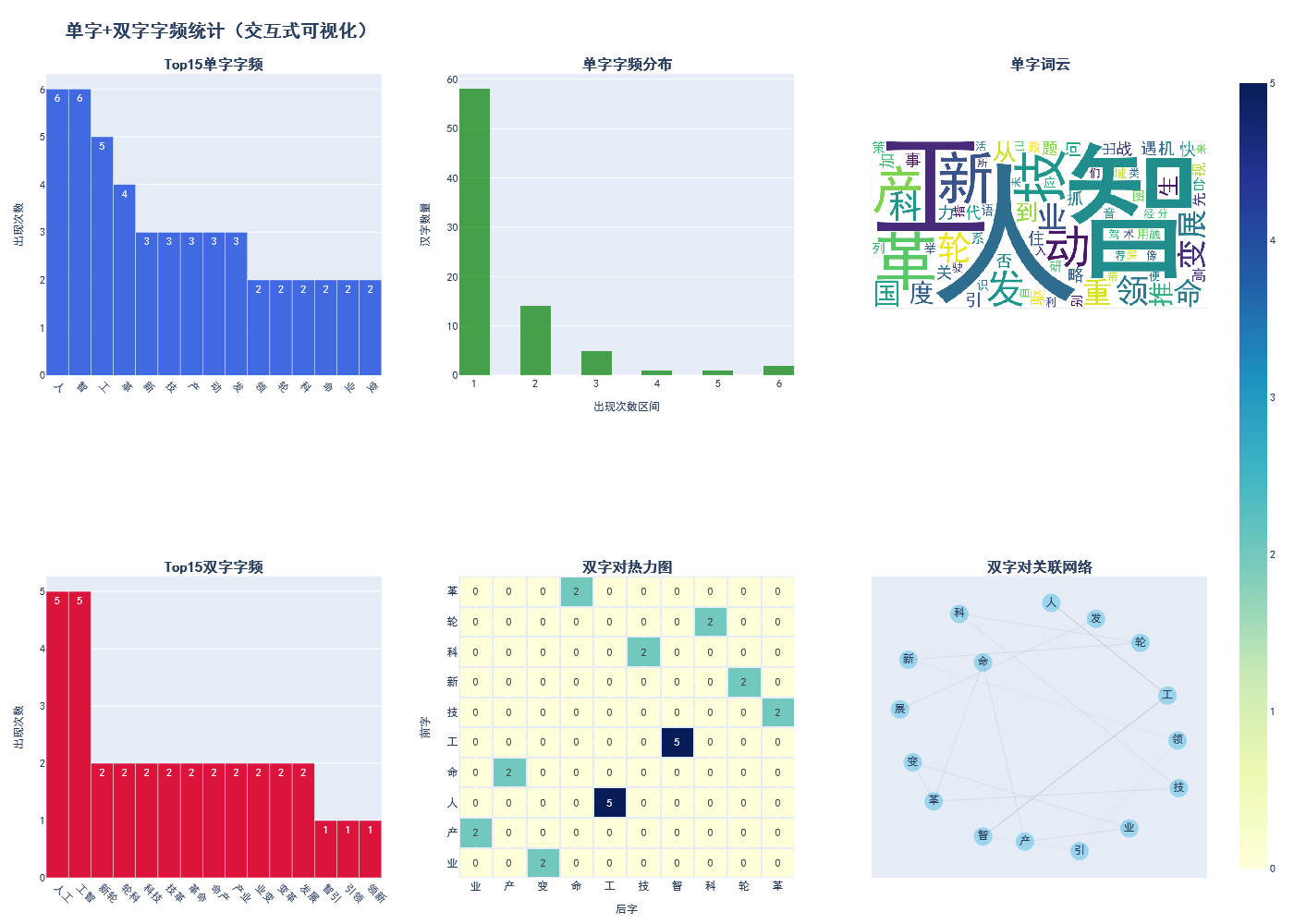

===== 示例2:多文本对比 =====
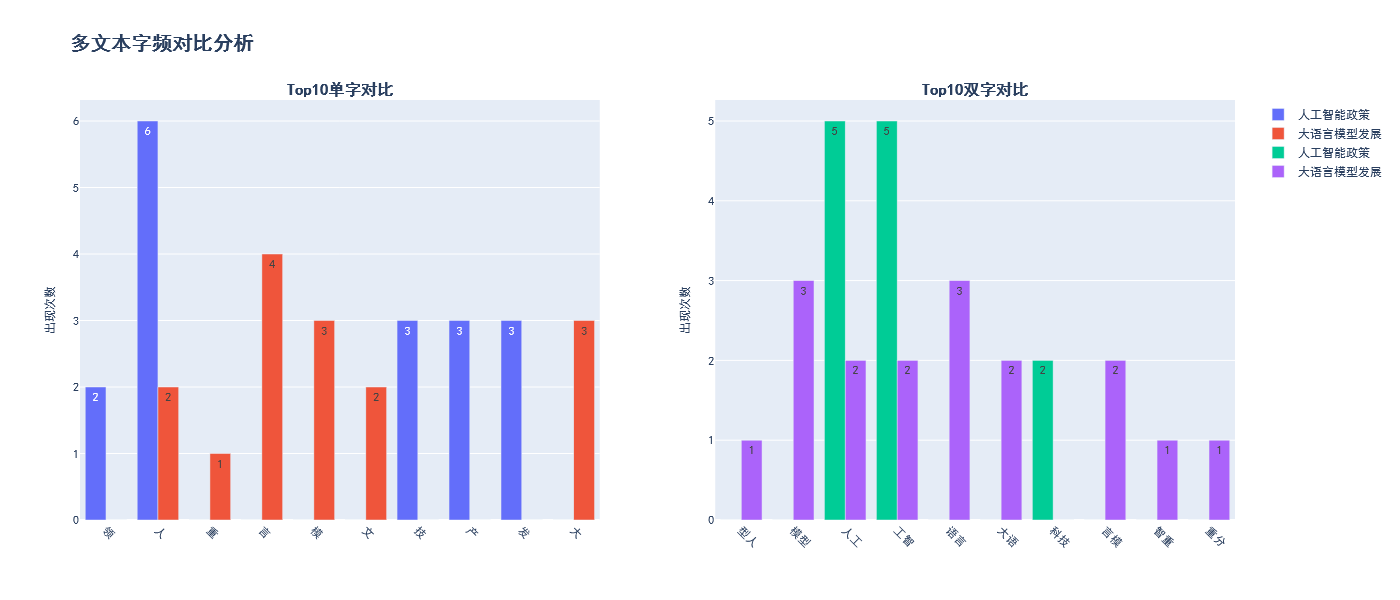

===== 示例3:大规模文件处理 =====
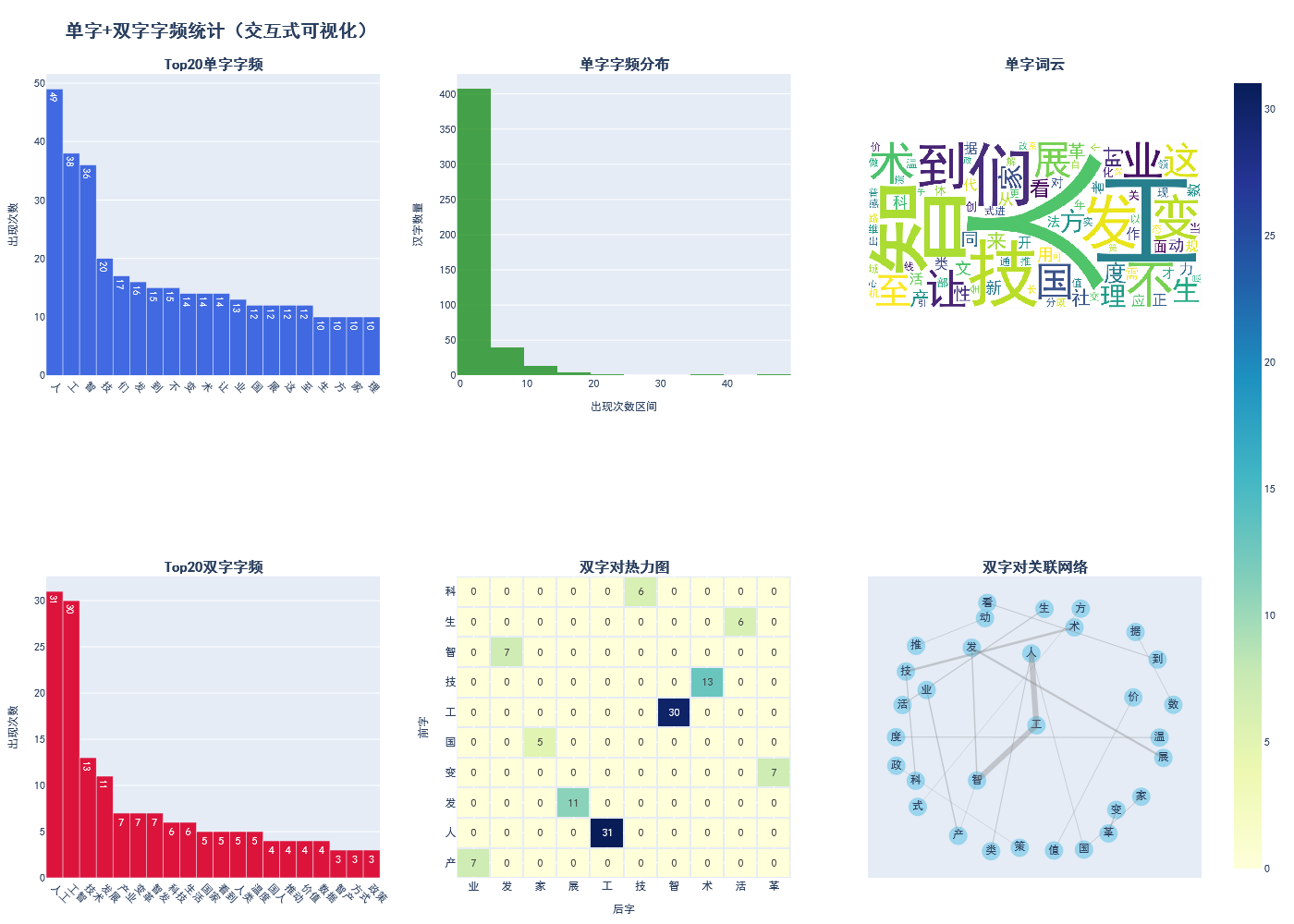

十二、总结
本文介绍了一个中文文本字频统计与交互式可视化工具的完整开发流程。该工具支持GB级大文本处理,通过分块读取和多线程技术实现高效统计,能够分析单字频率、双字组合频率,并提供多文本对比功能。系统采用模块化设计,包含文本预处理、频率统计、可视化等核心模块,解决了中文显示、跨平台兼容等关键技术问题。可视化部分使用Plotly生成交互式图表,包括词云、热力图、关联网络等多种形式。工具具有易用性强、性能优异的特点,适用于中文文本分析、数据挖掘等应用场景。