https://github.com/knightcrawler25/GLSL-PathTracer
GLSL PathTracer 是一款基于 OpenGL 着色语言实现的高性能路径追踪渲染器,其设计深度融合了现代离线渲染的核心理论与 GPU 并行计算的工程实践。项目通过模块化架构、高效加速结构、物理基于的着色模型和灵活的渲染策略,实现了高质量图像生成与实时交互的平衡。本文将从架构设计、核心模块原理、关键技术细节三个维度,全面拆解项目的技术实现与设计思路。
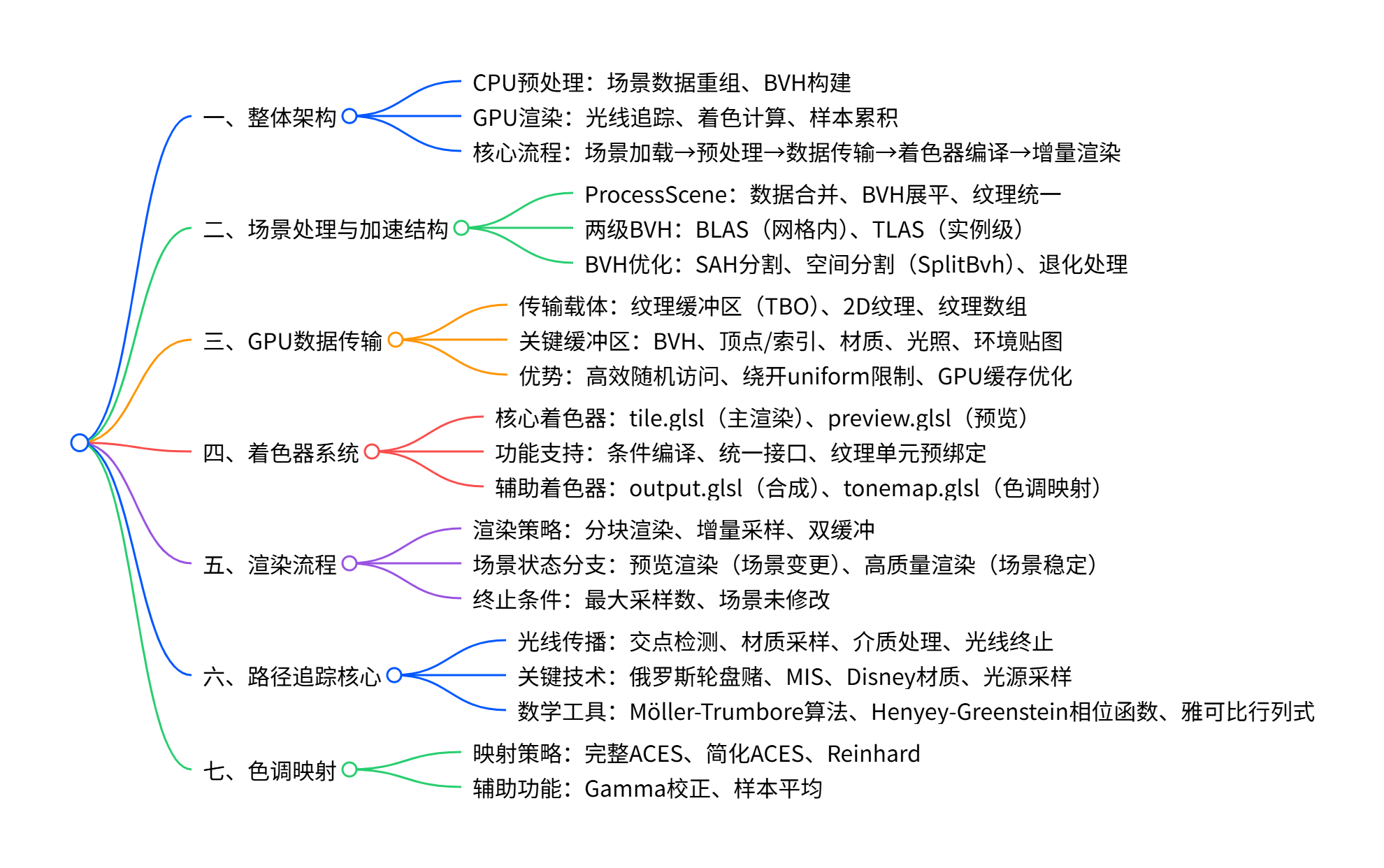
一、整体架构设计
GLSL PathTracer 采用 "CPU 预处理 + GPU 并行渲染" 的经典架构,核心流程可划分为五大环节,形成从场景加载到图像输出的完整流水线:
- 场景预处理环节 :通过ProcessScene函数将原始场景数据(网格、材质、光源、摄像机)转换为 GPU 可高效处理的紧凑格式,核心是构建两级 BVH 加速结构并完成数据重组。
- 加速结构构建环节 :通过createBLAS和createTLAS函数构建底层与顶层 BVH,结合 SAH(表面积启发式)优化和空间分割机制,为光线求交提供高效索引。
- GPU 数据传输环节 :通过InitGPUDataBuffers函数将 CPU 端的场景数据(BVH 节点、顶点、材质、光照等)以纹理形式上传至 GPU 显存,利用纹理缓冲区对象(TBO)实现高效访问。
- 着色器编译与初始化环节 :通过InitShaders函数加载、编译多类着色器,实现条件编译与统一接口设计,为渲染提供核心计算单元。
- 增量式渲染环节 :通过Render函数执行分块渲染流程,结合样本累积、双缓冲机制和色调映射,逐步生成高质量图像,同时保证交互响应性。
整个架构的核心设计理念是 "数据驱动 + 策略分离":将数据重组与加速结构构建放在 CPU 端预处理,将并行度高的光线追踪与着色计算放在 GPU 端,通过双着色器设计、分块渲染等策略,平衡渲染质量与交互体验。
二、核心模块原理深度解析
(一)场景处理与加速结构:路径追踪高效渲染的基石
场景处理与 BVH 加速结构是路径追踪性能的关键,项目通过精细化设计实现了复杂场景的快速光线求交。
1. 场景处理核心:ProcessScene 函数
ProcessScene作为连接场景加载与 GPU 渲染的桥梁,核心职责是数据重组与标准化:
- 加速结构构建 :先为每个网格构建 BLAS(底层加速结构),存储网格内部三角形的包围盒层次;再为所有网格实例构建 TLAS(顶层加速结构),根据实例变换矩阵调整包围盒,形成两级索引体系。
- BVH 展平 :通过BvhTranslator::Process将递归的 BVH 树转换为线性数组格式,消除指针依赖,适配 GPU 的连续内存访问模式。
- 数据合并与标准化 :将多个网格的顶点、法线数据合并为连续数组,顶点索引需添加偏移量避免冲突;统一处理纹理数据(整合为 2D 纹理数组、缩放至标准尺寸);自动设置默认摄像机参数(位置、视角),确保场景完整性。
- 并行优化 :利用 OpenMP 并行处理纹理缩放等耗时操作,提升预处理效率。
2. 两级 BVH 加速结构设计
项目采用的两级 BVH 结构是现代光线追踪引擎的标准方案,核心优势在于灵活性与复用性:
- BLAS(底层加速结构) :为单个网格独立构建,存储网格内部三角形的 BVH 层次,仅包含几何信息,不涉及实例变换。网格只需构建一次 BLAS,可在多个实例中复用,大幅减少内存占用。
- TLAS(顶层加速结构) :基于所有网格实例的变换后包围盒构建,存储实例级别的 BVH 层次。当仅移动、旋转实例时,无需重建 BLAS,仅需重新计算实例包围盒并重建 TLAS,显著提升更新效率。
- 包围盒变换 :TLAS 构建时,通过提取实例变换矩阵的右、上、前向向量和位移分量,对原始网格包围盒的最小 / 最大点进行变换,确保包围盒始终准确包裹变换后的实例。
3. BVH 构建核心:BuildNode 函数与 SAH 优化
BuildNode函数通过递归方式构建 BVH 节点,支持叶子节点与内部节点的自适应处理:
- 节点初始化 :更新树高、分配节点,设置边界框和索引等基础属性。
- 叶子节点判定 :当图元数量小于 2 时,直接存储图元索引及起始位置,终止递归。
- 内部节点分割 :
- 分割轴选择:以包围盒最长轴作为分割轴,确保分割有效性。
- 初始分割位置:以包围盒中心作为默认分割点。
- SAH 优化(可选):通过构建直方图(默认 64 个 bin)统计图元分布,计算每个可能分割面的预期成本(遍历成本 + 相交成本),选择总成本最小的分割位置。SAH 的核心思想是 "光线与包围盒相交概率与其表面积成正比",成本公式为cost = traversal_cost + (left_count * left_area + right_count * right_area) * inv_parent_area,其中traversal_cost通常设为 1,inv_parent_area是父节点表面积的倒数。
- 图元重排:采用双指针技术对图元进行原地重排,确保左子树图元在分割面左侧,右子树在右侧,避免额外内存分配。
- 退化处理:若所有图元集中在分割面一侧,强制从中间分割,避免无限递归。
- 并行安全 :通过原子操作保护共享数据结构,支持多线程并行构建。
4. SplitBvh 增强机制
SplitBvh 是 BVH 的增强版本,核心改进是引入空间分割(spatial splitting)机制,解决传统对象分割(object splitting)在大三角形场景下的包围盒重叠问题:
- 核心差异 :除了按图元重心分割,还支持按空间位置分割图元本身 ------ 若图元跨越分割平面,直接将其分割为两部分,分别归属左右子树,大幅减少包围盒重叠。
- 关键函数 :
- FindObjectSahSplit:传统对象分割 SAH 实现,额外计算包围盒重叠度,判断是否需要空间分割。
- SplitPrimRefs:执行图元分割操作,处理跨越分割平面的图元。
- 优势与代价 :优势是光线追踪时减少节点访问数量,提升渲染性能;代价是图元可能被多个节点引用,增加内存开销,且空间分割提高了 BVH 构建复杂度。
(二)GPU 数据传输:基于纹理的高效数据交互
InitGPUDataBuffers函数负责将 CPU 端场景数据上传至 GPU,核心设计是 "以纹理为载体",适配 GPU 的存储与访问特性,解决着色器无法直接访问主机内存的问题。
1. 数据传输核心设计:为什么选择纹理?
OpenGL 着色器对主机内存访问受限,数据需上传至 GPU 显存,项目选择纹理作为传输载体的原因的是:
- 纹理适合存储大量结构化数据,支持高效随机访问。
- GPU 对纹理访问有专门的缓存和预取机制,性能优于其他数据结构。
- 可绕开 uniform 变量的大小限制,支持 GB 级别的数据传输。
- 支持多种格式(RGB32F、RGBA32I 等),适配不同类型数据(浮点型、整型)。
2. 关键数据缓冲区详解
项目为不同类型数据设计了针对性的纹理存储方案,确保数据访问高效且格式匹配:
- BVH 数据缓冲区 :数据来自展平后的 BVH 节点数组,以 RGB32F 格式存储为纹理缓冲区,供着色器遍历 BVH 时快速访问节点信息。
- 顶点索引缓冲区 :存储顶点索引数组,格式为 RGB32I(3 个 32 位整数为一组,对应一个三角形的三个顶点索引),通过纹理缓冲区对象(TBO)存储,支持一维索引访问。
- 顶点 / 法线缓冲区 :顶点数据(位置 + U 纹理坐标)存储为 RGBA32F 格式,法线数据(法线向量 + V 纹理坐标)同样采用 RGBA32F 格式,确保高精度传输。
- 材质数据纹理 :将所有材质数据存储为 2D 纹理,宽度计算为(sizeof(Material)/sizeof(Vec4)) * 材质数量,高度为 1,采用最近邻采样保持数据精确性,避免插值导致的材质属性失真。
- 变换矩阵纹理 :每个 4x4 变换矩阵占用 16 个浮点数(4 个 Vec4 分量),纹理宽度为(sizeof(Mat4)/sizeof(Vec4)) * 矩阵数量,同样为 2D 纹理(高度 1),适配实例变换的批量访问。
- 光照数据纹理 :仅在存在光源时创建,格式为 RGB32F,宽度为(sizeof(Light)/sizeof(Vec3)) * 光源数量,存储光源位置、强度等信息。
- 纹理贴图数组 :将所有纹理整合为 2D 纹理数组(GL_TEXTURE_2D_ARRAY),格式为 RGBA8,采用线性过滤实现平滑纹理效果,减少纹理切换开销。
- 环境贴图纹理 :分为环境贴图本身(RGB32F 格式,线性过滤)和累积分布函数(CDF,R32F 格式,最近邻过滤),CDF 用于环境光的重要性采样。
3. 纹理缓冲区对象(TBO)特性
项目中大量使用纹理缓冲区对象(TBO)存储结构化数据,其核心特性是:
- 无传统纹理的宽高限制,大小仅受显存约束,支持 GB 级数据存储。
- 本质是一维线性存储,通过索引访问而非 UV 坐标,适配结构化数据的随机访问需求。
- 不支持纹理过滤,仅通过精确索引获取数据,确保数据准确性。
- 例如顶点索引纹理:1000 个三角形对应 3000 个索引,以 RGB32I 格式存储为 1000 个纹素的一维纹理,着色器通过texelFetch(vertexIndicesTex, i).xyz获取第 i 个三角形的索引。
(三)着色器系统:灵活可配置的渲染计算单元
着色器系统是项目的渲染核心,通过InitShaders函数完成加载、编译、链接与配置,支持条件编译、统一接口和多策略渲染,适配不同场景需求。
1. 着色器加载与编译流程
- 源码加载 :加载五类核心着色器:通用顶点着色器(vertex.glsl)、主路径追踪着色器(tile.glsl)、低分辨率预览着色器(preview.glsl)、输出合成着色器(output.glsl)、色调映射着色器(tonemap.glsl)。
- 动态预处理器宏 :根据渲染选项(如是否启用景深、介质渲染、各向异性材质)动态添加预处理器定义,实现条件编译,避免不必要的计算。
- 编译与链接 :通过LoadShaders辅助函数编译顶点着色器与片段着色器,链接为完整着色器程序,确保语法正确与接口兼容。
- uniform 变量设置 :统一配置纹理单元绑定、渲染参数(如最大采样数、最大光线深度)等,确保着色器访问数据的一致性。
2. 核心着色器功能解析
(1)主路径追踪着色器(tile.glsl)
核心职责是执行完整路径追踪算法,采用分块渲染策略,是高质量图像生成的核心:
- 核心功能 :光线与场景求交、材质着色、直接 / 间接光照计算、样本累积降噪。
- 设计特点 :分块渲染(默认 256×256 瓦片),每次仅处理图像的一个局部区域,降低 GPU 内存压力;支持多帧样本累积,通过累积纹理减少图像噪声;结合双缓冲机制,避免渲染撕裂。
(2)预览着色器(preview.glsl)
用于场景变更时(如摄像机移动、实例变换)的快速预览,核心目标是 "实时反馈":
- 核心差异(与 tile.glsl 对比) :
- 分辨率:采用低分辨率渲染(pixelRatio=0.25),仅为完整分辨率的 1/4。
- 渲染策略:全屏渲染而非分块,单次采样而非多帧累积,减少计算量。
- 最大深度:强制设置为 2,简化光线弹跳计算,快速输出结果。
- 随机化:使用固定随机种子,保证预览结果一致性。
- 设计目的 :在用户交互时提供即时视觉反馈,平衡交互性与渲染质量。
(3)输出与色调映射着色器
- 输出着色器(output.glsl) :负责瓦片数据的合成与累积,将当前瓦片的新采样结果与历史累积纹理混合,逐步提升图像质量。
- 色调映射着色器(tonemap.glsl) :将 HDR(高动态范围)渲染结果压缩至 LDR(低动态范围)显示范围,支持三种映射方式:
- 完整 ACES 映射:遵循电影行业标准 ACES 色彩管理系统,通过色彩空间转换(sRGB→ACES→显示空间)实现高精度色调映射,色彩准确且细节丰富。
- 简化 ACES 映射:通过有理函数逼近完整 ACES 曲线,计算量更小,视觉效果接近专业级。
- 传统 Reinhard 映射:采用color = color / (1 + luminance/color_limit)公式,渐进式压缩高光,计算简单高效。
- Gamma 校正 :补偿人眼与显示设备的非线性响应(感知亮度∝物理亮度 ^γ,γ≈2.2),确保图像在不同设备上的一致性。
3. 着色器系统设计亮点
- 条件编译 :通过预处理器宏动态启用 / 禁用功能(如景深、介质),适配不同硬件性能与场景需求。
- 纹理单元映射 :预先绑定所有纹理到固定纹理单元,避免运行时重复绑定,提升渲染效率。
- 统一接口 :所有着色器采用一致的 uniform 命名与数据绑定方式,降低维护成本,便于扩展。
(四)核心渲染流程:增量式分块渲染策略
Render函数实现了项目的核心渲染逻辑,采用 "增量式 + 分块 + 双缓冲" 的混合策略,在保证图像质量的同时,兼顾交互响应性与内存效率。
1. 渲染核心策略:分块增量渲染
分块增量渲染是项目的核心设计,其原理是:
- 不一次性渲染完整图像,而是将图像划分为多个瓦片(默认 256×256),逐瓦片迭代渲染。
- 每帧仅更新部分瓦片的采样数据,累积到全局累积纹理中,逐步降低图像噪声。
- 优势:降低 GPU 内存压力(无需存储完整分辨率的中间数据);支持渐进式渲染(每帧都能看到图像质量提升);保持界面响应性(即使在高分辨率场景下,也能快速反馈)。
2. 完整渲染流程
(1)渲染终止条件
当场景未修改、设置了最大采样数(maxSpp≠-1)且当前采样数达到最大值时,停止渲染,避免无效计算。
(2)场景状态分支处理
- 场景变更时(scene->dirty=true) :执行快速预览渲染:
- 绑定低分辨率帧缓冲对象(pathTraceFBOLowRes)。
- 设置视口为低分辨率(windowSize×0.25)。
- 使用预览着色器(preview.glsl)绘制四边形,输出低质量但实时的预览图像。
- 重置场景状态标志,等待用户停止交互。
- 场景稳定时 :执行完整高质量渲染,分为三步:
- 瓦片路径追踪:绑定路径追踪帧缓冲(pathTraceFBO),设置视口为瓦片大小,使用主路径追踪着色器(tile.glsl)计算当前瓦片的新采样数据。
- 累积纹理更新:绑定累积帧缓冲(accumFBO),将新瓦片数据混合到累积纹理中,通过多帧采样累积降低噪声。
- 色调映射与输出:绑定输出帧缓冲(outputFBO),使用色调映射着色器将累积纹理的 HDR 数据转换为 LDR 图像,输出至显示设备。
(3)双缓冲机制
采用双缓冲机制避免渲染撕裂:
- 两个纹理交替使用:一个用于当前帧的瓦片渲染(写入新采样数据),另一个用于显示前一帧的完整累积结果。
- 渲染过程中,显示缓冲区始终呈现完整图像,避免部分瓦片未渲染导致的画面残缺。
(4)状态维护
分块渲染的状态由三个核心变量维护:
- tile.x/tile.y:当前处理的瓦片坐标,按顺序遍历所有瓦片。
- currentBuffer:双缓冲索引,标识当前使用的渲染缓冲区。
- sampleCounter:当前全局采样次数,用于控制累积纹理的混合权重。
(五)路径追踪核心算法:物理基于的光线传播模拟
PathTrace 函数是路径追踪的核心,模拟光线在场景中的传播、反射、折射与散射过程,融合了多项现代离线渲染的关键技术,确保渲染结果的物理准确性。
1. 光线传播完整流程
PathTrace 函数通过无限循环模拟光线弹跳,直至满足终止条件,流程如下:
- 初始化 :创建光线对象,记录光线起点、方向、介质状态等信息;初始化随机数生成器(PCG)。
- 光线弹跳循环 :
- 最近交点检测:调用ClosestHit函数遍历 TLAS 与 BLAS,找到光线与场景几何体的最近交点,返回交点坐标、法线、材质 ID 等信息;若无交点(光线射向无穷远),则添加环境贴图或均匀光源贡献,结束路径。
- 自发光处理:若交点为自发光物体,直接累加其辐射亮度,结合多重重要性采样(MIS)优化光源采样效率。
- 最大深度检查:若光线弹跳次数达到最大深度(用户配置),终止循环。
- 介质处理:若交点所在区域存在参与介质,计算光线能量衰减(吸收介质)、添加发射光(发光介质)或采样散射事件(散射介质),更新光线方向与能量。
- 表面散射处理:
- Alpha 测试:处理透明纹理,若纹理 Alpha 值低于阈值,跳过当前交点,继续追踪光线。
- 直接光照计算:使用下次事件估计(Next Event Estimation)采样光源,计算直接光照贡献。
- BSDF 采样:基于 Disney 材质模型采样新的光线方向,考虑漫反射、镜面反射、折射等效应。
- 介质状态更新:记录光线当前所处介质,为后续介质处理提供依据。
- 俄罗斯轮盘赌:当光线弹跳次数超过阈值(通常 3-5),根据光线能量(throughput)动态调整终止概率,避免追踪贡献微弱的光线,优化性能。
2. 关键技术解析
(1)俄罗斯轮盘赌:智能光线终止策略
核心思想是 "根据光线能量动态决定是否继续追踪",在保证渲染无偏性的前提下,减少无效计算:
- 数学原理 :设光线当前贡献为 W,以概率 q 终止路径(贡献为 0),以概率 1-q 继续追踪(贡献为 W/(1-q)),确保期望值不变(E 贡献 = q×0 + (1-q)×(W/(1-q)) = W)。
- 实现细节 :
- 触发条件:光线弹跳次数超过OPT_RR_DEPTH(默认 3-5)。
- 终止概率计算:q = 1 - min(max(throughput.x, max(throughput.y, throughput.z)) + 0.001, 0.95),其中throughput是光线当前能量,取 RGB 通道最大值避免单一通道过暗导致过早终止;+0.001 确保终止概率不为 0,保证数值稳定性;min (...,0.95) 限制最大终止概率为 95%,避免光线过早截断。
- 决策逻辑:生成 0,1 随机数,若大于 q 则终止路径,否则将throughput除以 (1-q) 进行能量补偿。
- 优势 :自适应光线能量,强光线路径追踪更深,弱光线路径及时终止,平衡性能与质量。
(2)多重重要性采样(MIS):降低渲染方差
核心问题:单一采样策略(BSDF 采样或光源采样)在特定场景下效果不佳(如小光源 + 镜面材质,BSDF 采样难以命中光源;大光源 + 漫反射材质,光源采样效率低)。MIS 通过平衡多种采样策略的贡献,降低渲染方差。
- 数学原理 :对于两种采样策略(概率密度 p₁和 p₂),混合估计公式为I ≈ Σw₁(x₁)/p₁(x₁)×f(x₁) + Σw₂(x₂)/p₂(x₂)×f(x₂),其中 w₁(x)+w₂(x)=1,权重通过幂启发式函数计算:w₁ = p₁²/(p₁²+p₂²),w₂ = p₂²/(p₁²+p₂²)。
- 项目应用 :
- 平衡 BSDF 采样与光源采样:在直接光照计算中,同时采用 BSDF 采样(根据材质特性采样光线方向)和光源采样(直接采样光源表面点),通过 MIS 权重分配贡献。
- 光源类型适配:点光源(面积 = 0)无法直接采样,MIS 权重设为 1.0(仅使用 BSDF 采样);面光源(面积 > 0)支持两种采样策略,通过幂启发式计算权重。
(3)Disney 材质模型:物理基于的通用材质
项目实现了完整的 Disney BRDF(双向反射分布函数),支持从塑料、金属到布料、玻璃的多种材质模拟,核心是多分量叠加与物理参数控制:
- 核心函数 :
- TintColors:计算色调向量,混合基础颜色与菲涅尔反射率,生成镜面反射和绒毛效应的颜色基础。
- EvalDisneyDiffuse:改进版 Lambert 漫反射模型,融合菲涅尔权重、后向散射、伪次表面散射和绒毛效应,模拟复杂漫反射行为。
- EvalMicrofacetReflection:微表面镜面反射模型,采用 GTR2 各向异性法线分布函数(GTR2Aniso)和 Smith 各向异性遮蔽函数(SmithGAniso),支持拉丝金属等各向异性材质。
- EvalMicrofacetRefraction:微表面折射模型,考虑折射率变化、能量守恒和雅可比变换,模拟玻璃、水等透明材质。
- EvalClearcoat:清漆涂层模型,采用 GTR1 法线分布函数,模拟汽车油漆、塑料表面的额外高光层。
- 关键参数 :金属度(metallic)、粗糙度(roughness)、各向异性(anisotropic)、清漆强度(clearcoat)、绒毛强度(sheen)等,通过参数组合实现多样化材质效果。
(4)光源采样:针对不同光源类型的优化
项目支持球体光源、矩形光源、远距离光源三种类型,每种光源都实现了针对性的重要性采样策略:
- 球体光源采样 :在球心方向的半球上均匀采样,通过 ONB(正交基)变换到世界空间,PDF 公式为distance²/(light.area×0.5×|dot(normal, direction)|),0.5 因子源于仅考虑外表面发光。
- 矩形光源采样 :通过两个随机数在矩形区域内均匀采样表面点,法线由矩形的两个边向量叉积计算,PDF 公式为distance²/(light.area×|dot(normal, direction)|)。
- 远距离光源采样 :方向固定(从原点指向光源位置),距离设为无穷大(无衰减),PDF 设为 1.0,模拟太阳等远距离光源。
(5)介质渲染:Henyey-Greenstein 相位函数
项目支持参与介质(如烟雾、云、牛奶)的渲染,核心是 Henyey-Greenstein 相位函数,描述光线在介质中的散射角度分布:
- 相位函数公式 :p(θ) = (1-g²)/(4π(1+g²-2g×cos(θ))^1.5),其中 θ 是入射与出射方向的夹角,g 是各向异性参数(g=0 为各向同性散射,g>0 为前向散射,g<0 为后向散射)。
- 采样方法 :通过逆变换采样(Inverse Transform Sampling)生成符合分布的散射方向,先计算 CDF(累积分布函数),再求解反函数得到散射角度,结合球坐标转换得到三维方向。
(6)光线三角形求交:Möller-Trumbore 算法
ClosestHit函数中采用 Möller-Trumbore 算法实现高效光线三角形求交,该算法计算速度快、数值稳定,是工业标准:
- 核心原理 :将光线参数方程与三角形重心坐标方程联立,通过叉积和点积简化计算,避免复杂矩阵运算。
- 优势 :仅需一次叉积和多次点积运算,计算量固定;对浮点精度误差鲁棒;支持批量交点检查,适配 GPU 并行计算。
(7)AnyHit 函数:高效阴影检测
与ClosestHit(寻找最近交点)不同,AnyHit函数的核心职责是 "检测是否存在任何交点",主要用于阴影检测:
- 工作流程 :创建从着色点到光源的阴影光线,设置最大距离为着色点到光源的距离(减去微小偏移避免自相交),若在该距离内检测到任何遮挡物,则判定为阴影区域。
- 额外功能 :支持透明材质处理,对于硬边缘透明(ALPHA_MODE_MASK),低于阈值则视为透明;对于软边缘透明(ALPHA_MODE_BLEND),根据 alpha 值和随机数决定是否遮挡。
- 性能优势 :找到第一个交点即可返回,无需遍历所有可能交点,比ClosestHit更高效。
(六)关键数学工具:雅可比矩阵与行列式
雅可比矩阵及其行列式是项目中连接几何变换与物理计算的核心数学工具,确保渲染过程中的数值稳定性与物理正确性。
1. 雅可比矩阵的核心意义
雅可比矩阵是多元向量函数的一阶偏导数矩阵,核心在于 "输出对输入的微分关系",决定了其物理意义:
- 行代表输出分量,列代表输入变量,描述输入的微小变化如何影响输出。
- 在渲染中,主要用于坐标变换、概率密度调整、力 / 速度映射等场景。
2. 雅可比行列式的几何意义与应用
雅可比行列式是雅可比矩阵的行列式,绝对值表示坐标变换前后的体积 / 面积缩放比例,符号表示变换是否保持定向:
- 几何意义 :二维场景中表示面积缩放因子,三维场景中表示体积缩放因子;正号保持定向,负号翻转定向。
- 核心应用 :
- 坐标变换校正:如球面坐标到笛卡尔坐标变换中,雅可比行列式为r²sinθ,用于补偿积分计算中的体积扭曲。
- 概率密度调整:在采样空间变换时,通过行列式调整概率密度,确保概率守恒(如微表面反射中,从半矢量空间到方向空间的变换雅可比为1/(4×VDotH))。
- 物理合理性判断:在网格变形、体映射生成中,通过行列式符号判断是否存在体积反转(行列式 > 0 为合理)。
- 数值稳定性:在折射、散射等计算中,处理掠射角等极端情况,避免数值发散。
3. 项目中的典型应用场景
- 球面采样 :从世界空间到球坐标变换时,雅可比行列式r²sinθ用于调整采样密度,避免两极区域过度采样。
- 微表面折射 :光线从一种介质进入另一种介质时,雅可比行列式用于校正立体角变换,确保能量守恒,公式为(η²×|h·ωₜ|)/(|h·ωᵢ|×(h·(ωᵢ+ηωₜ))²)。
- 环境贴图采样 :结合球面坐标变换的雅可比行列式,调整环境光采样的概率密度,实现重要性采样。
(七)色调映射:HDR 到 LDR 的高质量转换
色调映射是连接高动态范围渲染结果与显示设备的关键环节,项目通过tonemap.glsl实现多种映射策略,在压缩动态范围的同时保留细节与对比度。
1. 核心挑战与解决方案
- 挑战 :HDR 图像亮度范围可达 0, ∞),而显示设备仅支持 \[0,1 范围,直接裁剪会丢失高光与阴影细节。
- 解决方案 :采用非线性压缩函数,平衡全局对比度与局部细节,确保视觉感知一致性。
2. 三种映射策略详解
- 完整 ACES 映射 :遵循电影行业 ACES 色彩管理系统,流程为 "sRGB→ACES 工作空间→RRT/ODT 变换→显示空间",色彩准确、动态范围支持广,特别优化肤色表现,适合专业级渲染。
- 简化 ACES 映射 :通过有理函数逼近完整 ACES 曲线,计算量更小,视觉效果接近专业级,兼顾性能与质量。
- 传统 Reinhard 映射 :采用color = color/(1 + luminance/color_limit)公式,渐进式压缩高光,计算简单高效,适合实时预览或性能受限场景。
3. Gamma 校正与样本平均
- Gamma 校正 :补偿人眼与显示设备的非线性响应(感知亮度∝物理亮度 ^γ,γ≈2.2),确保图像在不同设备上的一致性。
- 样本平均 :基于蒙特卡洛积分原理,将多帧采样结果累加后取平均(最终颜色 = 累积总和 × 1/采样数),降低图像噪声。
三、项目架构设计亮点总结
GLSL PathTracer 的成功源于其模块化、物理基于、高效灵活的设计,核心亮点可概括为:
- 两级 BVH+SAH + 空间分割 :构建高效加速结构,兼顾构建速度与渲染效率,支持复杂场景的快速光线求交。
- 纹理驱动的 GPU 数据传输 :利用纹理缓冲区对象(TBO)解决大量数据传输问题,适配 GPU 访问特性,提升数据交互效率。
- 双着色器渲染策略 :预览着色器保证交互实时性,主着色器保证渲染质量,平衡用户体验与图像效果。
- 分块增量渲染 :降低内存压力,支持渐进式降噪,即使高分辨率场景也能保持界面响应性。
- 完整的物理基于渲染链路 :从 Disney 材质模型、多重重要性采样到介质渲染、俄罗斯轮盘赌,每一步都遵循物理原理,确保渲染结果的真实性。
- 灵活的条件编译与接口设计 :支持功能动态启用 / 禁用,适配不同硬件性能与场景需求,便于扩展与维护。
整个项目以 "高效、准确、灵活" 为核心目标,将路径追踪的理论知识与 GPU 编程的工程实践深度融合,为 GLSL 路径追踪的学习与应用提供了高质量的参考实现。