
论文标题:Neural Conformal Control for Time Series Forecasting
论文链接:https://arxiv.org/abs/2412.18144
什么是共形预测?
01 概念与内涵
读本文之前,我也没有了解过"共形"预测的概念,所以特意查了资料。共形预测(Conformal Prediction, CP)是一种在任意预测模型之上构建的不确定性量化框架。通过计算样本的"非一致性分数"(衡量预测值与真实值的差异),并结合校准数据集的统计分布,在给定置信水平 (1−α) 下,生成一个预测区间或预测集合,从而保证真实结果落在其中的概率不低于 (1−α)。
02 传统预测的区别
听起来很复杂,对比一下普通预测结果就很容易理解了。普通预测通常只输出一个点预测(如预测气温 = 25℃),但是难以衡量结果的不确定性;而共形预测则输出一个区间或集合(如预测气温在 23℃, 28℃ 内,置信度 95%),既提供预测结果,也提供置信水平,从而让预测更稳健、更可信。
这种对区间和置信度的刻画在某些医学、金融等领域非常重要,因为我们不仅需要知道预测值的大小,还希望量化预测值可信度。
共形预测的难点
第一个难点在于时间序列数据的特殊性,传统 CP 假设数据可交换,时序数据可能存在分布漂移和时间依赖性,导致覆盖保证失效。
第二是在实际应用方面,小样本学习能力弱,预测区间一致性不足,还是分布一致性的问题。
本文模型NCC:Neural Conformal Control
一言以蔽之,NCC 构建了端到端的框架,下面从三个方面介绍。
模型
01 模型结构
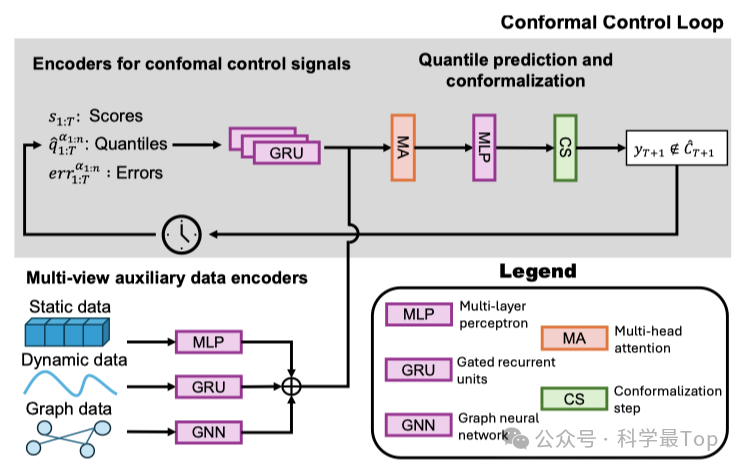
含保形控制循环与多视图数据编码器两大模块:
共形控制循环:处理历史共形信号(覆盖误差、分位数、非保形得分),通过 GRU 编码时序特征,经多头注意力融合为联合嵌入向量,再输入 MLP(含 ReLU 层)输出非负的中间分位数。
多视图数据编码器:针对不同模态数据设计专用编码器(GRU 处理时序数据、GCN 处理图数据、前馈网络处理静态数据),通过多头注意力融合多视图嵌入向量,提升对分布偏移的感知能力。
02 损失函数设计
设计三类损失函数协同优化模型,平衡覆盖保证、区间稳定性与效率:

03 关键优化:保证区间一致性与理论覆盖
分布一致性优化:训练时加单调性损失,强制 "误差率越小(置信度越高),分位数越大(区间越宽)";测试时通过 TTA 调整分位数,直至分布一致性得分(DCS)达标,解决区间交叉问题。
长期覆盖保证:通过 "保形化步骤",将中间分位数与动态调整项结合生成最终分位数。理论证明,当预测步数足够大时,NCC 的长期覆盖误差趋近于目标误差率,覆盖概率符合预期置信水平。
实验总结
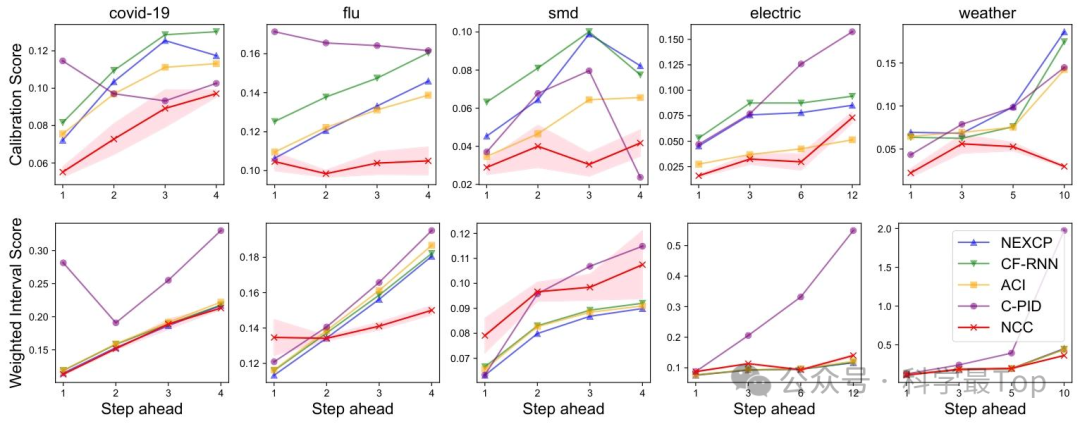
上图对比了 NCC 与 NEXCP、CF-RNN、ACI、C-PID 四种基准时间序列共形预测方法,在 covid-19、flu、weather、electric、smd 五个真实数据集及不同预测步长下的校准得分(CS)和加权区间得分(WIS);其中 NCC 用红色线条突出显示,周围粉色阴影代表误差边际,结果显示 NCC 在所有数据集上的 CS 均最优,且除 smd 数据集外,在其余四个数据集上的 WIS 均达到或接近最优,同时 NCC 的 CS 曲线在长预测步长下仍保持平缓,体现出优于基准方法的校准稳定性与区间实用性。
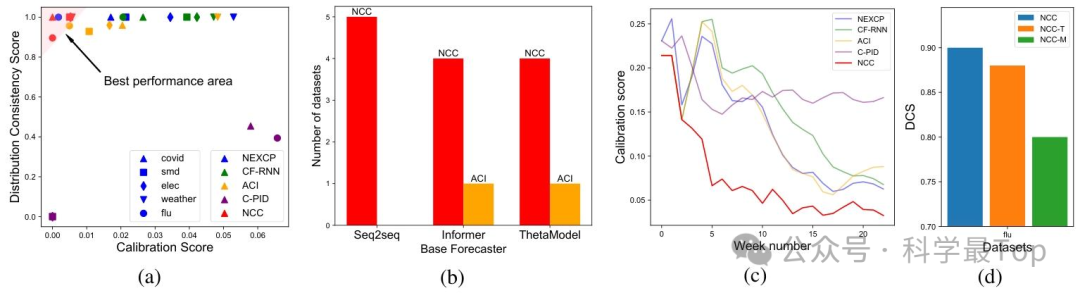
上图中,四个子图从不同维度验证了 NCC 的优势:子图 (a) 通过 DCS 与 CS 的散点对比,显示 NCC 在 "高分布一致性(DCS)" 与 "低校准偏差(CS)" 间实现平衡,避免了其他方法(如 C-PID)"适应性强则一致性差" 的矛盾;
子图 (b) 统计各方法 CS 最优的数据集数量,证明 NCC 无论搭配 seq2seq、Informer 还是 Theta 基预测器,均在至少 4 个数据集上表现最优;
子图 (c) 在 covid-19 少样本场景中,展现 NCC 的 CS 快速降至 0.1 以下,远超基准方法的少样本学习能力;
子图 (d) 通过 NCC、NCC-T(无 TTA)、NCC-M(无 TTA 与单调性损失)的 DCS 对比,验证了单调性损失与 TTA 对提升预测区间分布一致性的关键作用。
结论与未来方向
本文是首个端到端深度学习共形控制框架,用神经网络捕捉时间模式,结合多视图数据提升适应性,无需强分布假设。实用优化:通过单调性损失与 TTA 解决分位数交叉,满足 CDC 等机构的区间一致性要求;设计控制启发式损失,兼顾覆盖稳定性与区间效率。
- 局限性
区间宽度问题:在部分数据集上,NCC 的预测区间略宽于基准方法,因多目标损失(校准、一致性、效率)可能导致效率损失权重被低估。
超参数敏感性:模型性能对部分超参数(如损失函数中的K、学习率\(\eta\))敏感,需通过贝叶斯优化调参,增加使用复杂度。
- 未来方向
损失平衡优化:探索自适应权重策略,平衡校准、一致性与区间效率,提升对复杂分布偏移的适应能力。
**大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!**获取时序论文合集
