一、介绍
蔬菜识别系统,基于TensorFlow搭建卷积神经网络算法,通过对8种常见的蔬菜图片数据集('土豆', '大白菜', '大葱', '莲藕', '菠菜', '西红柿', '韭菜', '黄瓜')进行训练,最后得到一个识别精度较高的模型,然后搭建Web可视化操作平台。
前端: Vue3、Element Plus
后端:Django
算法:TensorFlow、卷积神经网络算法
具体功能:
- 系统分为管理员和用户两个角色,登录后根据角色显示其可访问的页面模块。
- 登录系统后可发布、查看、编辑文章,创建文章功能中集成了markdown编辑器,可对文章进行编辑。
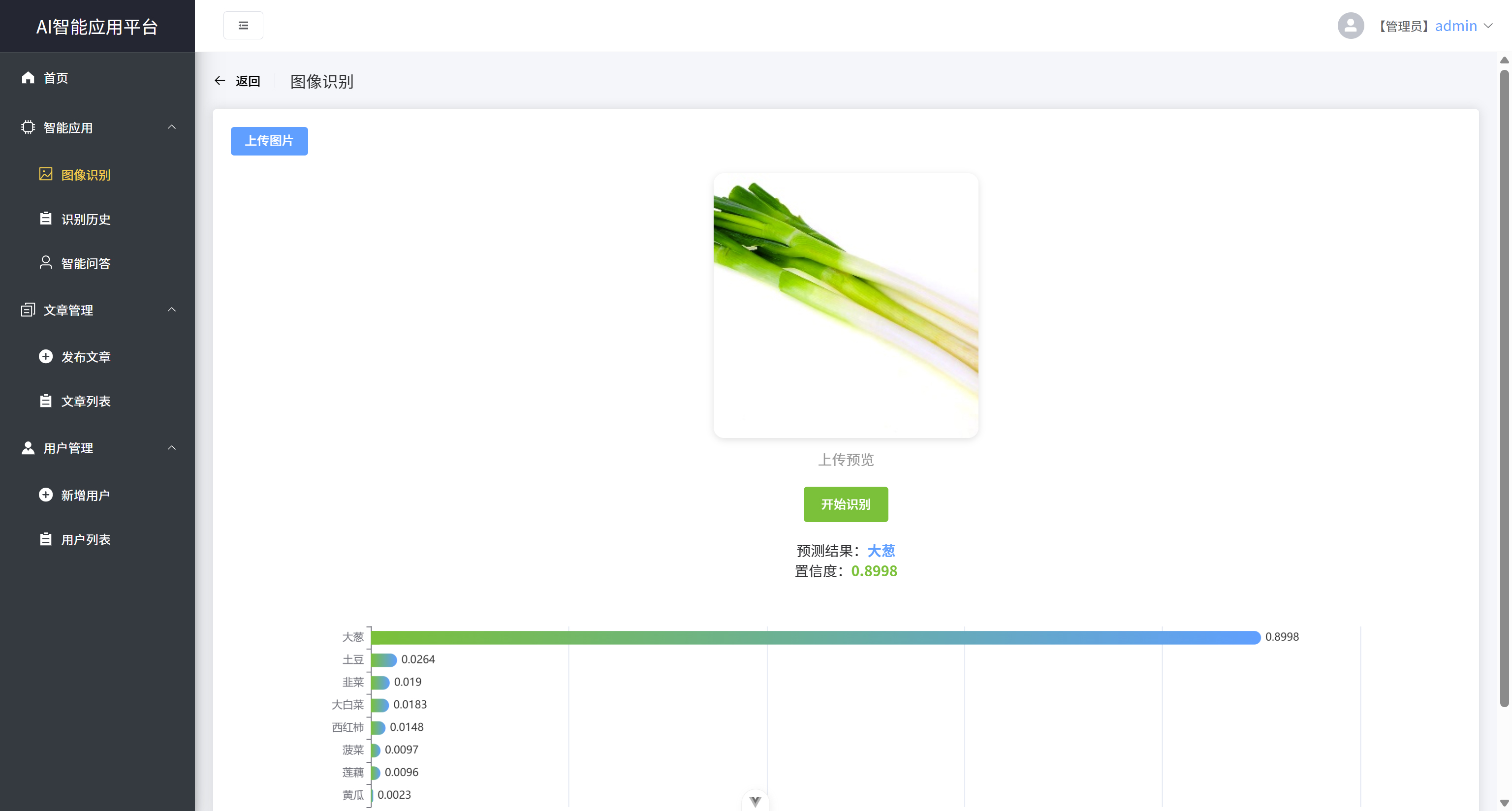
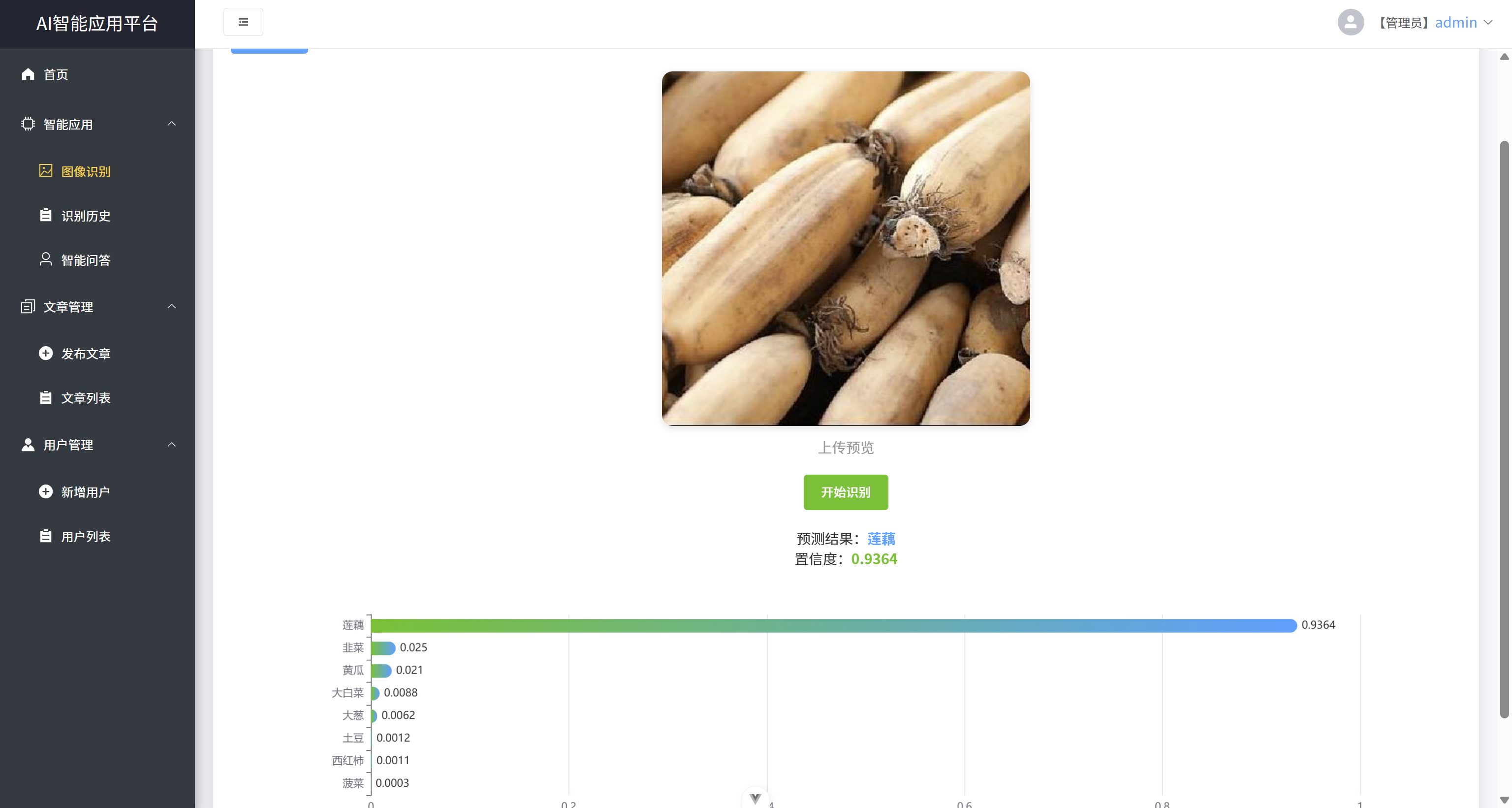
- 在图像识别功能中,用户上传图片后,点击识别,可输出其识别结果和置信度
- 基于Echart以柱状图形式输出所有种类对应的置信度分布图。
- 在智能问答功能模块中:用户输入问题,后台通过对接Deepseek接口实现智能问答功能。
- 管理员可在用户管理模块中,对用户账户进行管理和编辑。
选题背景与意义 :
随着智慧农业与新零售模式的快速发展,对蔬菜种类的自动化、精准化识别需求日益增长。然而,由于蔬菜品类繁多、外观形态相似及环境光照差异,传统的肉眼辨别或简单算法已难以满足现代高效管理的需求。
深度学习技术的成熟,尤其是**卷积神经网络(CNN)**在图像特征提取上的卓越表现,为解决复杂视觉分类任务提供了可能。本课题旨在结合计算机视觉与现代 Web 技术,构建一套高效的蔬菜识别系统。系统不仅通过 TensorFlow 提升识别精度,更结合了 Deepseek 大模型实现智能科普问答,并通过 Vue3 打造可视化平台,将复杂的 AI 算法转化为便捷的用户工具。该研究不仅能助力农产品管理的信息化,也为智慧生活场景下的人机交互提供了参考范式。
二、系统效果图片展示
三、演示视频 and 完整代码 and 安装
四、卷积神经网络算法介绍
卷积神经网络(CNN)是一种专门为处理具有网格结构数据(如图像)而设计的深度学习算法。其核心思想在于局部感受野 、权值共享 和空间下采样。与传统神经网络全连接的方式不同,CNN 通过"卷积层"利用卷积核(Filter)自动提取图像的边缘、纹理等底层特征,再由"池化层"压缩数据维度并保留关键信息,最后通过"全连接层"进行分类。这种结构极大地减少了模型参数量,并赋予了系统对平移、缩放等形变的鲁棒性。
以下是使用 TensorFlow/Keras 构建并调用简易 CNN 模型进行图像识别的代码片段:
python
import tensorflow as tf
from tensorflow.keras import layers, models
# 1. 构建卷积神经网络模型
model = models.Sequential([
# 卷积层:提取特征;池化层:降维
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 展开并连接全连接层进行分类
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(8, activation='softmax') # 假设识别8种蔬菜
])
# 2. 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 3. 示例调用:对单张图片进行预测
# image = load_and_preprocess_image("vegetable.jpg")
# prediction = model.predict(image)上述代码展示了 CNN 的标准工作流:首先通过两层 Conv2D 卷积层捕捉图像的空间特征,配合 MaxPooling2D 池化层减少计算量并防止过拟合。随后,通过 Flatten 将多维特征图打平,送入全连接层进行逻辑推理。最后,Softmax 激活函数将输出转化为对应 8 种蔬菜类别的概率分布。该流程具有极强的扩展性,只需增加网络深度或调整超参数,即可进一步提升在复杂场景下的识别精度。

- 输入层 (Input):接收原始蔬菜图像数据(如 64 * 64 像素的 RGB 图像)。
- 卷积层 (Convolution):通过滤波器(Filter)提取蔬菜的边缘、颜色和纹理特征。
- 池化层 (Pooling):进行下采样,在保留核心特征的同时大幅减少数据量,提高运算速度。
- 全连接分类层 (Output):将提取到的抽象特征映射到具体的类别(如"西红柿"或"黄瓜"),并输出置信度。