文章目录
- 一、优先级队列基础认知
- 二、堆的操作实现
-
- [2.1 堆的向下调整(shiftDown)](#2.1 堆的向下调整(shiftDown))
- [2.2 堆的创建(createHeap)](#2.2 堆的创建(createHeap))
- [2.3 堆的插入(shiftUp)](#2.3 堆的插入(shiftUp))
- [2.4 堆的删除](#2.4 堆的删除)
- 三、用堆模拟优先级队列
- 四、Java中的PriorityQueue详解
-
- [4.1 PriorityQueue的核心特性](#4.1 PriorityQueue的核心特性)
- [4.2 PriorityQueue的常用构造器](#4.2 PriorityQueue的常用构造器)
- [4.3 自定义比较器实现大堆](#4.3 自定义比较器实现大堆)
- [4.4 PriorityQueue的常用方法](#4.4 PriorityQueue的常用方法)
- 五、堆的经典应用
-
- [5.1 堆排序](#5.1 堆排序)
- [5.2 Top-K问题](#5.2 Top-K问题)
- 六、练习
一、优先级队列基础认知
1.1 什么是优先级队列
优先级队列是一种特殊的队列,它不再遵循"先进先出"的规则,而是按照元素的优先级来决定出队顺序:优先级高的元素先出队,优先级低的元素后出队。它最核心的两个操作是:
- 返回最高优先级的元素
- 添加新的元素
1.2 优先级队列的底层:堆
JDK1.8中,PriorityQueue的底层采用堆这种数据结构实现。堆并非全新的数据结构,而是在完全二叉树基础上增加了规则约束的特殊结构。
堆的定义与分类
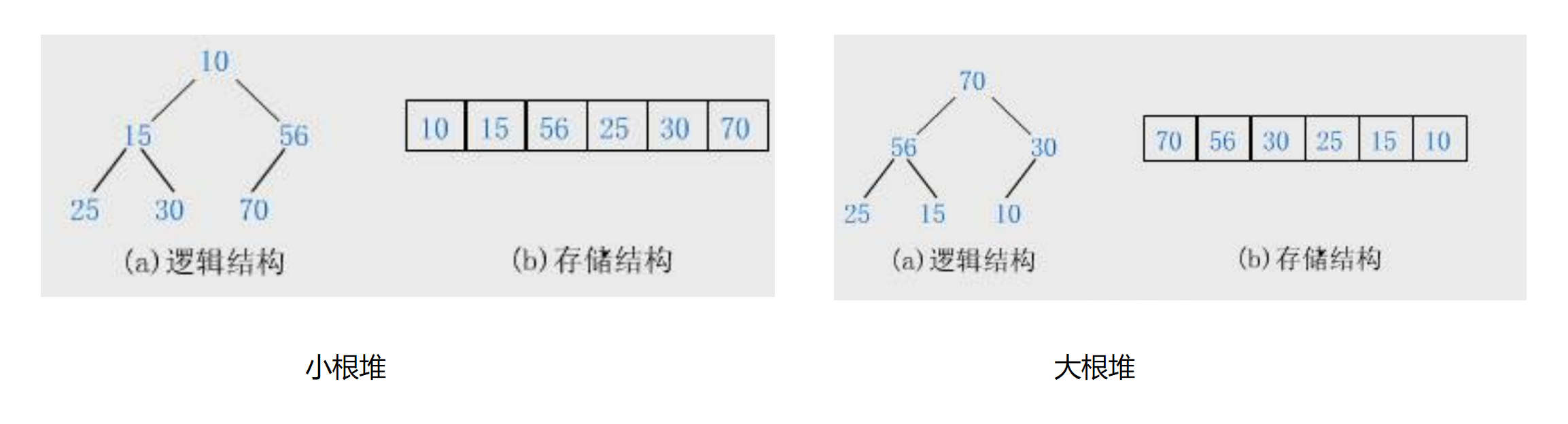
假设有一个关键码集合K={k0, k1, k2, ..., kn-1,将其按完全二叉树的顺序存储在一维数组中,若满足以下条件,则称为堆:
- 小堆(小根堆) :每个节点的值都不大于其左右孩子的值,即Ki < K2i+1且Ki < K2i+2,根节点是整个堆中最小的元素。
- 大堆(大根堆) :每个节点的值都不小于其左右孩子的值,即Ki > K2i+1且Ki > K2i+2,根节点是整个堆中最大的元素。
堆的性质
- 堆中任意节点的值,总是满足"不大于(小堆)"或"不小于(大堆)"其父节点的值。
- 堆一定是一棵完全二叉树,这也是堆能高效用数组存储的关键。
堆的存储方式
由于堆是完全二叉树,我们可以通过数组按层序顺序存储堆,无需存储空节点,空间利用率极高。假设数组下标为 i ,则节点间的关系满足:
- 若i=0,则该节点是根节点;否则,其父节点下标为(i-1)/2。
- 若2i+1 <节点总数,左孩子下标为2i+1;否则无左孩子。
- 若2i+2 <节点总数,右孩子下标为2i+2;否则无右孩子。
二、堆的操作实现
要实现堆,关键要掌握向下调整 、向上调整两个算法,在此基础上可完成堆的创建、插入和删除。
2.1 堆的向下调整(shiftDown)
向下调整的前提是:待调整节点的左、右子树已满足堆的性质。以小堆为例:
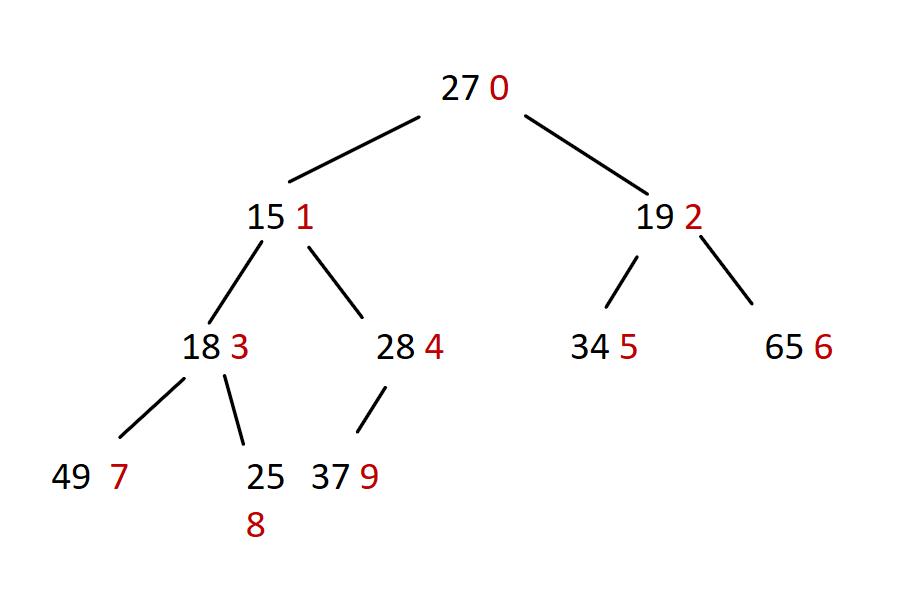
- 先找到最后一棵子树的根节点,
parent = (len - 1 - 1 ) / 2 - 使用for循环:初始parent的位置是
(len - 1 - 1 ) / 2;每次只需要让parent--,来调整前一棵树;最终parent<0结束循环。 - 向下调整:
- 若右孩子存在,比较左右孩子大小,让
child标记更小的孩子。 - 比较
parent和child的值:- 若
parent值更小,满足小堆性质,调整结束。 - 否则,交换
parent和child的值;之后parent指向child,child指向新parent的左孩子,继续调整。
- 若
child的边界是数组的size
- 若右孩子存在,比较左右孩子大小,让
代码实现(小堆):
java
public void shiftDown(int[] array, int parent) {
// child先标记parent的左孩子
int child = 2 * parent + 1;
int size = array.length;
while (child < size) {
// 找到左右孩子中较小的那个
if (child + 1 < size && array[child + 1] < array[child]) {
child += 1;
}
// 若parent满足堆性质,直接退出
if (array[parent] <= array[child]) {
break;
} else {
// 交换parent和child
int temp = array[parent];
array[parent] = array[child];
array[child] = temp;
// 继续向下调整
parent = child;
child = 2 * parent + 1;
}
}
}时间复杂度 :最坏情况需从根节点调整到叶子节点,比较次数为堆的高度(完全二叉树高度为log2n),因此时间复杂度为O(log2n)。
2.2 堆的创建(createHeap)
对于任意无序数组,我们从倒数第一个非叶子节点 开始,依次向前对每个节点执行向下调整,最终可将数组调整为堆。倒数第一个非叶子节点的下标为(array.length - 2) / 2(或(array.length - 1 - 1) >> 1,位运算更高效)。
代码实现:
java
public static void createHeap(int[] array) {
// 从倒数第一个非叶子节点开始,向前逐个调整
int root = (array.length - 2) >> 1;
for (; root >= 0; root--) {
shiftDown(array, root);
}
}时间复杂度:通过数学推导(错位相减),建堆的总操作步数约为(n),因此时间复杂度为(O(n))(而非(O(n\log n)),这是堆排序高效的关键)。
2.3 堆的插入(shiftUp)
堆的插入需保证插入后仍满足堆性质,步骤如下:
- 将新元素放入数组末尾(底层空间,若空间不足需扩容)。
- 用
child标记新插入节点,向上调整:- 计算
parent((child - 1) / 2)。 - 比较
parent和child的值:- 若
parent满足堆性质(小堆中parent更小),调整结束。 - 否则,交换
parent和child,child指向parent,继续向上调整。
- 若
- 计算
代码实现(小堆):
java
public void shiftUp(int[] array, int child) {
int parent = (child - 1) / 2;
while (child > 0) {
// 若parent满足堆性质,退出
if (array[parent] <= array[child]) {
break;
} else {
// 交换parent和child
int temp = array[parent];
array[parent] = array[child];
array[child] = temp;
// 继续向上调整
child = parent;
parent = (child - 1) / 2;
}
}
}2.4 堆的删除
堆的删除有一个严格规则:只能删除堆顶元素(优先级最高的元素),步骤如下:
- 将堆顶元素(数组下标0)与数组最后一个元素交换。
- 有效元素个数减1(相当于删除了原堆顶元素)。
- 对新的堆顶元素(原最后一个元素)执行向下调整,恢复堆性质。
三、用堆模拟优先级队列
基于上述堆的操作,我们可以手动实现一个简单的优先级队列,核心功能包括offer(插入)、poll(删除堆顶)、peek(获取堆顶)。
代码实现(小堆):
java
public class MyPriorityQueue {
// 存储堆元素的数组(简化版,未处理扩容)
private int[] array = new int[100];
// 有效元素个数
private int size = 0;
// 插入元素
public void offer(int e) {
array[size++] = e;
// 从最后一个元素向上调整
shiftUp(array, size - 1);
}
// 删除并返回堆顶元素
public int poll() {
if (size == 0) {
throw new NoSuchElementException("PriorityQueue is empty");
}
int oldTop = array[0];
// 堆顶与最后一个元素交换
array[0] = array[--size];
// 向下调整新堆顶
shiftDown(array, 0);
return oldTop;
}
// 获取堆顶元素(不删除)
public int peek() {
if (size == 0) {
throw new NoSuchElementException("PriorityQueue is empty");
}
return array[0];
}
// 向下调整(同2.1)、向上调整(同2.3)方法省略...
}四、Java中的PriorityQueue详解
Java集合框架提供了PriorityQueue(线程不安全)和PriorityBlockingQueue(线程安全),日常开发中PriorityQueue使用更广泛。
4.1 PriorityQueue的核心特性
- 包导入 :使用前需导入
java.util.PriorityQueue。 - 元素可比性 :队列中元素必须能比较大小,否则插入时抛出
ClassCastException;不能插入null,否则抛出NullPointerException。 - 容量与扩容 :无固定容量,可自动扩容,扩容规则如下:
- 容量<64时,按"原容量+2"扩容(近似2倍)。
- 容量≥64时,按"原容量的1.5倍"扩容(
oldCapacity >> 1)。 - 若容量超过
Integer.MAX_VALUE - 8,则按Integer.MAX_VALUE扩容。
- 时间复杂度 :插入(
offer)和删除(poll)操作均为(O(\log_2 n))。 - 默认堆类型 :默认是小堆,若需大堆,需自定义比较器(实现
Comparator接口)。
4.2 PriorityQueue的常用构造器
| 构造器 | 功能说明 |
|---|---|
PriorityQueue() |
创建空队列,默认容量11 |
PriorityQueue(int initialCapacity) |
创建指定初始容量的空队列(容量≥1,否则抛异常) |
PriorityQueue(Collection<? extends E> c) |
用集合c的元素创建队列 |
示例代码:
java
import java.util.ArrayList;
import java.util.PriorityQueue;
public class PriorityQueueDemo {
public static void main(String[] args) {
// 1. 默认构造器(小堆,容量11)
PriorityQueue<Integer> q1 = new PriorityQueue<>();
// 2. 指定初始容量(容量100)
PriorityQueue<Integer> q2 = new PriorityQueue<>(100);
// 3. 用集合创建
ArrayList<Integer> list = new ArrayList<>();
list.add(4);
list.add(3);
list.add(2);
list.add(1);
PriorityQueue<Integer> q3 = new PriorityQueue<>(list);
System.out.println("q3大小:" + q3.size()); // 输出4
System.out.println("q3堆顶:" + q3.peek()); // 输出1(小堆)
}
}4.3 自定义比较器实现大堆
PriorityQueue默认是小堆,若需大堆,需在构造时传入自定义Comparator,重写compare方法:
- 小堆:
compare(o1, o2) return o1 - o2(o1小则返回负数,o1优先级高)。 - 大堆:
compare(o1, o2) return o2 - o1(o2大则返回正数,o2优先级高)。
示例代码(大堆):
java
import java.util.Comparator;
import java.util.PriorityQueue;
// 自定义大堆比较器
class BigHeapComparator implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
// o2 - o1:o2大则返回正数,o2优先级高
return o2 - o1;
}
}
public class BigHeapDemo {
public static void main(String[] args) {
PriorityQueue<Integer> bigHeap = new PriorityQueue<>(new BigHeapComparator());
bigHeap.offer(4);
bigHeap.offer(3);
bigHeap.offer(5);
bigHeap.offer(1);
System.out.println("大堆堆顶:" + bigHeap.peek()); // 输出5
}
}4.4 PriorityQueue的常用方法
| 方法名 | 功能说明 |
|---|---|
boolean offer(E e) |
插入元素e,成功返回true,失败抛异常 |
E peek() |
获取堆顶元素,空队列返回null |
E poll() |
删除并返回堆顶元素,空队列返回null |
int size() |
返回有效元素个数 |
void clear() |
清空队列 |
boolean isEmpty() |
判断队列是否为空,空返回true |
示例代码:
java
import java.util.PriorityQueue;
public class PriorityQueueMethodDemo {
public static void main(String[] args) {
int[] arr = {4, 1, 9, 2, 8, 0, 7};
PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);
// 插入所有元素
for (int e : arr) {
q.offer(e);
}
System.out.println("队列大小:" + q.size()); // 输出7
System.out.println("堆顶元素:" + q.peek()); // 输出0(小堆)
// 删除2个元素
q.poll();
q.poll();
System.out.println("删除后堆顶:" + q.peek()); // 输出2
// 插入0
q.offer(0);
System.out.println("插入后堆顶:" + q.peek()); // 输出0
// 清空队列
q.clear();
System.out.println("是否为空:" + q.isEmpty()); // 输出true
}
}五、堆的经典应用
堆的应用非常广泛,除了实现优先级队列,还有堆排序、Top-K问题等经典场景。
5.1 堆排序
堆排序利用堆的性质实现排序,核心分为两步:
- 建堆 :
- 若要升序排序:建大堆(每次将最大元素放到末尾)。
- 若要降序排序:建小堆(每次将最小元素放到末尾)。
- 利用堆删除思想排序 :
- 将堆顶元素(最大/最小)与数组末尾元素交换,有效长度减1。
- 对新堆顶执行向下调整,恢复堆性质。
- 重复上述步骤,直到有效长度为1。
示例(升序排序,建大堆) :
原数组:5, 11, 7, 2, 3, 17
- 建大堆:17, 11, 7, 2, 3, 5。
- 堆顶17与末尾5交换:5, 11, 7, 2, 3, 17,有效长度5;调整堆为11, 5, 7, 2, 3, 17。
- 堆顶11与末尾3交换:3, 5, 7, 2, 11, 17,有效长度4;调整堆为7, 5, 3, 2, 11, 17。
- 重复操作,最终得到升序数组:2, 3, 5, 7, 11, 17。
5.2 Top-K问题
Top-K问题是指从海量数据中找出前K个最大或最小的元素(数据量可能大到无法全部加载到内存),用堆解决是最优方案。
解决思路
-
找前K个最大元素:
- 用前K个元素建小堆(堆顶是当前K个元素中最小的,若后续元素比堆顶大,则替换堆顶)。
- 遍历剩余N-K个元素,若元素>堆顶,替换堆顶并向下调整。
- 最终堆中元素即为前K个最大元素。
-
找前K个最小元素:
- 用前K个元素建大堆(堆顶是当前K个元素中最大的,若后续元素比堆顶小,则替换堆顶)。
- 遍历剩余N-K个元素,若元素<堆顶,替换堆顶并向下调整。
- 最终堆中元素即为前K个最小元素。
示例代码(找前K个最小元素)
java
import java.util.PriorityQueue;
public class TopK {
public int[] smallestK(int[] arr, int k) {
// 参数校验
if (arr == null || k <= 0) {
return new int[0];
}
// 建大堆(自定义比较器)
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((o1, o2) -> o2 - o1);
// 前K个元素入堆
for (int i = 0; i < k; i++) {
maxHeap.offer(arr[i]);
}
// 遍历剩余元素,比堆顶小则替换
for (int i = k; i < arr.length; i++) {
if (arr[i] < maxHeap.peek()) {
maxHeap.poll();
maxHeap.offer(arr[i]);
}
}
// 提取堆中元素
int[] result = new int[k];
for (int i = 0; i < k; i++) {
result[i] = maxHeap.poll();
}
return result;
}
public static void main(String[] args) {
TopK topK = new TopK();
int[] arr = {3, 1, 4, 1, 5, 9, 2, 6};
int[] smallestK = topK.smallestK(arr, 3);
// 输出前3个最小元素:1,1,2
for (int num : smallestK) {
System.out.print(num + " ");
}
}
}六、练习
-
下列关键字序列为堆的是()
A: 100,60,70,50,32,65 B: 60,70,65,50,32,100
C: 65,100,70,32,50,60 D: 70,65,100,32,50,60
答案:A(100是大堆根,60≤100,70≤100;50≤60,32≤60;65≤70,满足大堆性质) -
已知小根堆为8,15,10,21,34,16,12,删除关键字8之后需重建堆,比较次数是()
A: 1 B: 2 C: 3 D: 4
答案:C(删除8后,最后一个元素12移到堆顶,向下调整:12与10比较(1次),交换后12与16比较(2次),12与12比较(3次),最终堆为10,15,12,21,34,16,12) -
最小堆0,3,2,5,7,4,6,8,删除堆顶元素0之后,结果是()
A: 3,2,5,7,4,6,8 B: 2,3,5,7,4,6,8
C: 2,3,4,5,7,8,6 D: 2,3,4,5,6,7,8
答案:C(删除0后,8移到堆顶,向下调整:8与3、2比较(选2,1次),交换后8与5、4比较(选4,2次),交换后8与6比较(3次),最终堆为2,3,4,5,7,8,6)