前言
在现实生活当中,有一些数据是和时间序列相关的 ,例如自然语言,我们说一句话,前面的字对我们后面的影响是很大的 ,再比如说天气,前面的天气对后面的天气影响是很大的,还有典型的数据,我们电力的使用数据,一个人用电是有一定的习惯的,所以它前面的用电对 后面的用电是有一定影响的,这些数据都和时间序列是有一定关系的。
像这样的一些数据,我们全连接神经网络和卷积神经网络是很难提取到其中有用的信息的,而循环神经网络可以提取时间信息
循环神经网络,一般我们来说有三大类:
- 最基础的入门神经网络,就是 RNN神经网络
- 用的最多的就是 LSTM
- 还有LSTM的变种 GRU
我们现在一般提到循环神经网络,就是指 LSTM
但是 LSTM 作为 RNN 改进过来的,如果想学习 LSTM ,必须先学习了解 RNN
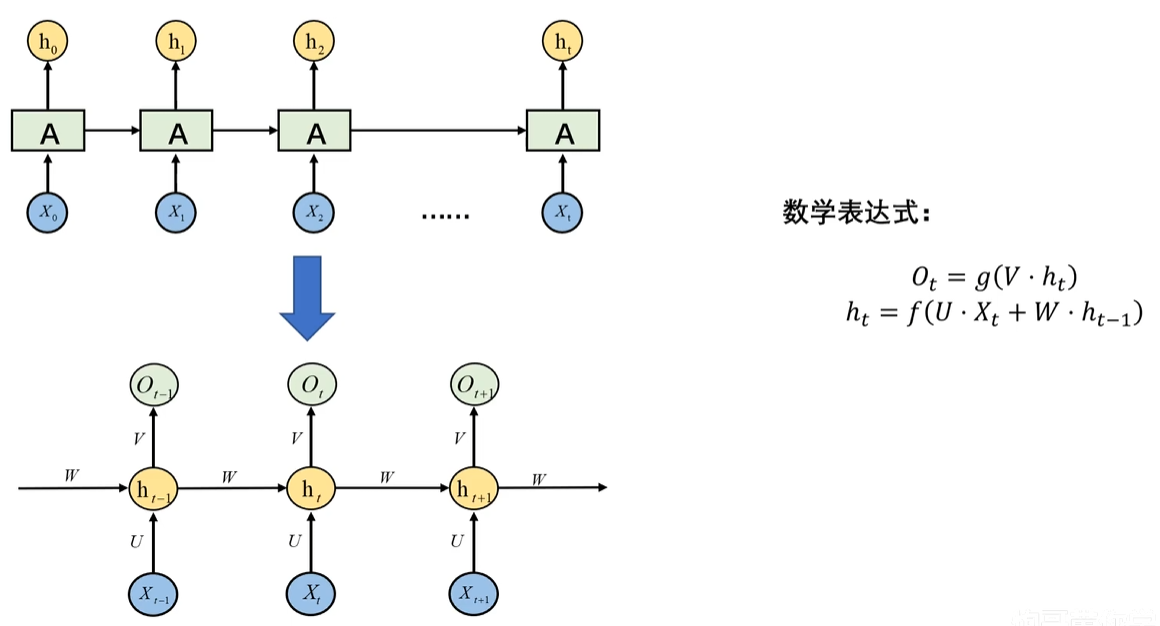
1. RNN神经网络的基本结构
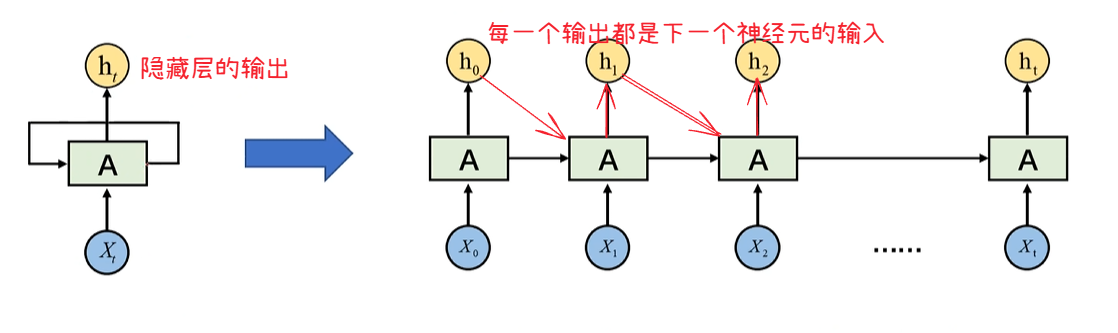
这是RNN的基本结构 ,相比于其他,它为什么可以提取到时间的信息呢?我们全连接神经网络,里面的X特征值是全部一起输入的,而这里的Xt,或者说X1,X2,X3,它是有时间顺序的,X1先输入,X2再输入,并且X1得到的h1,会作为参数传入X2的神经元中。因此,虽然是按顺序来的,但是后面的神经元依旧包含前面神经元的时间信息。
比如说,我们输入:我是中国人,我生活在中国,我会说中文,我们输入的语言是有时间顺序的,"是中国人","生活在中国",对于" 会说中文" 影响很大

可以理解为,v 是ht-1 的权重,w 是Xt 的权重,每个ht的计算过程都是这样,一层层往下
其实就是,充分考虑前一个特征对后一个特征的影响,然后再往后一直推理,这就是循环神经网络的精髓所在
2. RNN和全连接神经网络的区别
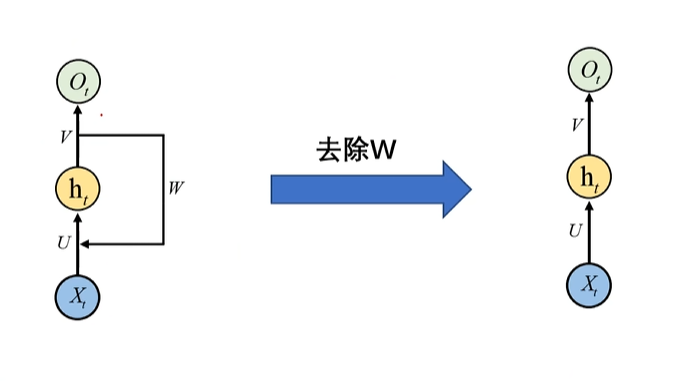
其实循环神经网络去掉W,不再以输出作为输入,就是全连接神经网络了,为什么呢?
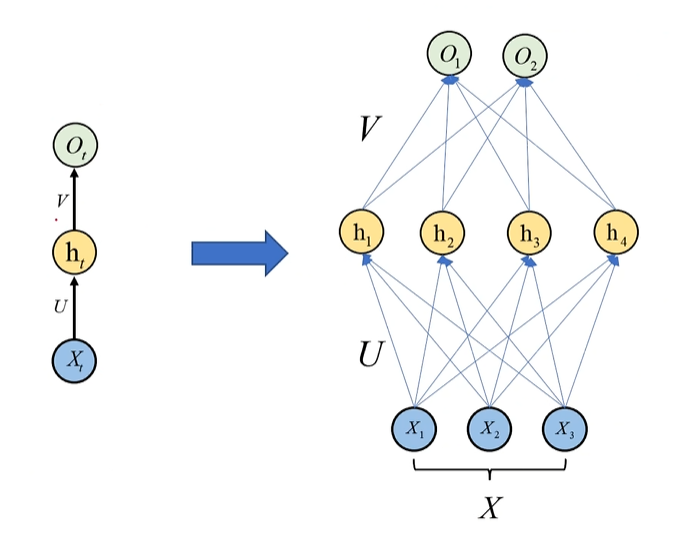
将右边这个的隐藏层展开(隐藏层会有多个神经元,不能老把它看做只有一个神经元),那其实不就是全连接神经网络了吗,U就是W1,V就是W2
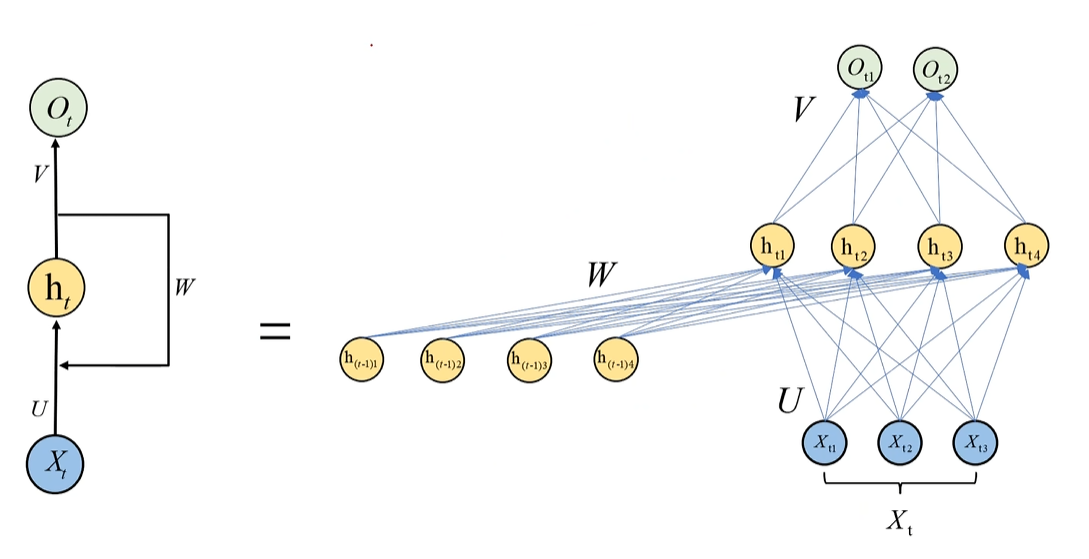
将左边这个循环神经网络的隐藏层打开,过程就是 ht = 激活函数( U*Xt + ht-1*W ),Ot = 激活函数(ht * V)(其实有没有感觉有点像递归)
3. 权重共享
如图,其实我们会发现不管是t时刻,还是t+1、t-1时刻,它的权重w都是一样的,这里又要提到权重共享的概念。我们在卷积核中提到过权重共享。
在循环神经网络,每一层隐藏层都有很多神经元,如果每一个神经元都配一个专门的W权重,不是太好。
权重过多的缺点:权重过多容易过拟合,并且容易计算量过大。
因此一层隐藏层配一个W权重就够了
4. RNN神经网络前向传播

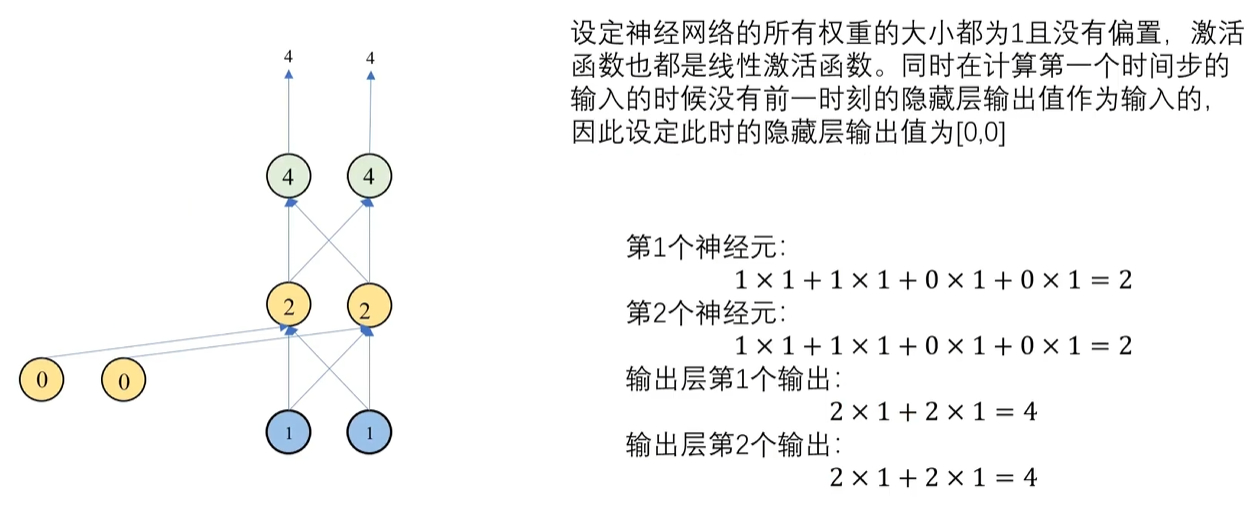
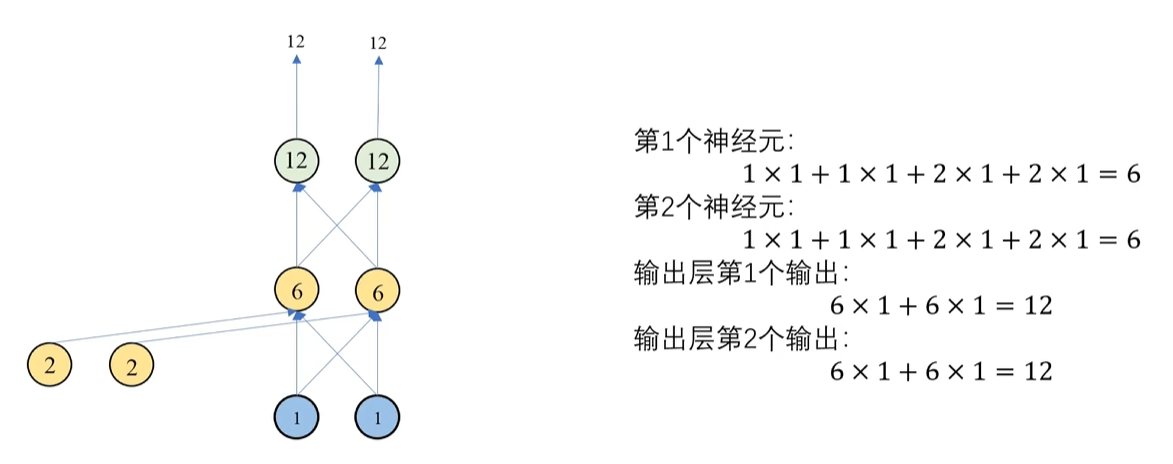
前向传播反正就是正常的计算过程 ,不过RNN有它的问题,前向传播的过程中会出现梯度消失(梯度趋于0) 和**梯度爆炸(梯度趋于无穷)**的问题,这也就是为什么需要LSTM来改进RNN
5. RNN神经网络的反向传播(BPTT)
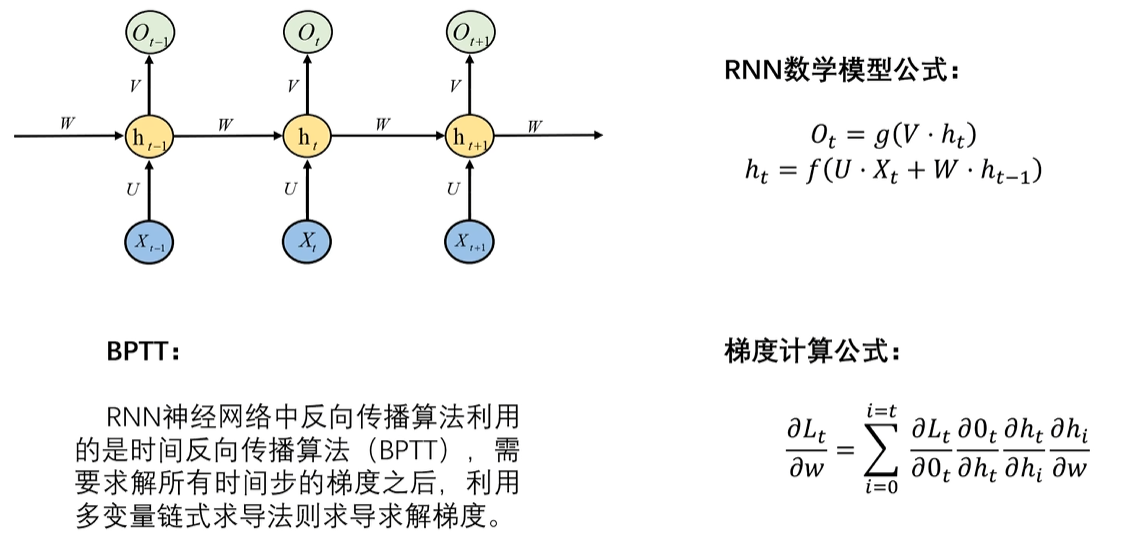
为什么会出现梯度消失 和梯度爆炸 问题呢?在我们反向传播的过程中,我们需要使用梯度下降法来对w进行求导来进行梯度更新,但是因为权重共享 ,所以会导致,比如说,你对ht时刻进行W梯度更新,导致你ht-1、ht-2.....的W全部都更新了,这样肯定是不对的。
因此我们可以看出,RNN的反向传播算法和正常的神经网络算法是不一样的。使用的算法叫做:BPTT
如图右下角,因为ht时刻的信息,实际上是包含前面ht-1、ht-2....前面所有时刻的信息的,因此,对当前ht时刻求导的时候,应该是要对ht前面所有时刻进行求偏导,然后再累加起来,才是真正W梯度更新的导数
6. RNN神经网络产生梯度消失和梯度爆炸的原因

其他项都好说,但是
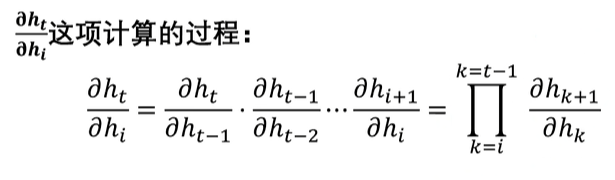
这一项,根据链式法则 ,就是这样的一个连乘形式
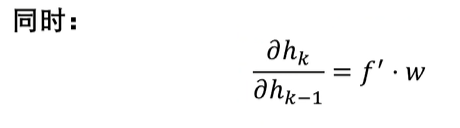
同时单拎一个出来,就是=f` * w ,f` 是什么?我们知道ht = f(V*Xt + W*ht-1),这个 f 就是激活函数, f` 就是激活函数的导数。

因此
假如说,W初始化为0.9,因为是连乘,你连乘个1000次就趋于0了,这就是梯度消失的原因
假如说,W初始化为1.1,因为是连乘,你连乘个1000次就趋于无穷了,这就是梯度爆炸的原因
更别说,w初始化可能是0.25,可能是2,这样轮次一多,很容易出现这些问题
并且,我们这里的是求和符号 ,其实也就是说,当 t 比较小的时候,梯度还是存在的,可以学习到东西的,只有到了某一时刻,才会出现问题。
也就是说,距离ht越近的,学习到的东西会越多,比如说有100层,等你反向传播到第1层了,几乎就学不到东西了。
实际上LSTM也只是缓解这个问题,也并没有解决。LSTM相比RNN可以学习更长时间步的信息
7. LSTM模型基本运算
LSTM 的核心思想:
- 引入"记忆单元"(cell state)来保存长期信息。
- 使用门控机制 (gates)来控制信息的流动:决定保留什么、丢弃什么、添加什么。
- 这使得 LSTM 能够选择性地记住或遗忘信息,从而有效捕捉长期依赖。
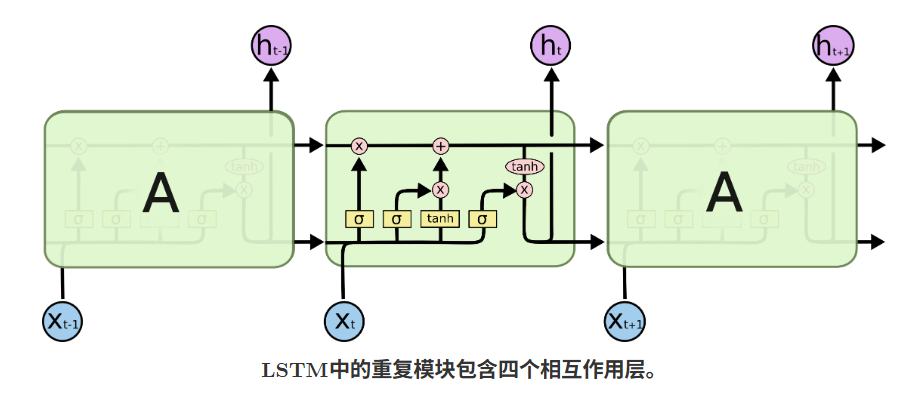
下面会逐步讲解LSTM的示意图。现在,我们先试着熟悉我们将用的符号。

在上图中,每条线承载一个完整的向量,从一个节点的输出到其他节点的输入。粉色圆圈代表点数运算,如向量加法,黄色方框则是学习后的神经网络层。合并行表示串接,而行分叉表示内容被复制,且复制到不同位置。
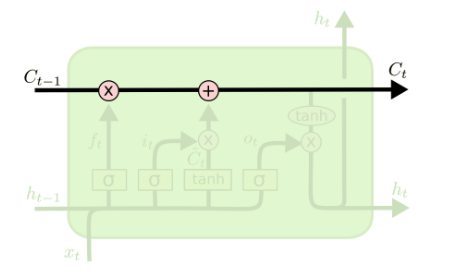
在LSTM神经网络上面有一条独特的向量计算的一条流水线,是LSTM中极其重要的一部分。
在之前RNN中,,输出只有ht,而这里多了一个Ct 。而Ct的目的就是为了保存前面时刻中的有用信息 ,就是说,前面有用的信息就保存下来,没用的信息就剔除掉,当然Ct-1也包含着Ct-2、Ct-3....等前面所有有用的信息,它不会像RNN,将前面的所有信息ht一股脑全部作为输入 。通过一些向量计算,加减乘除啥的,帮助我们只保留有用的信息。
8. LSTM的遗忘门
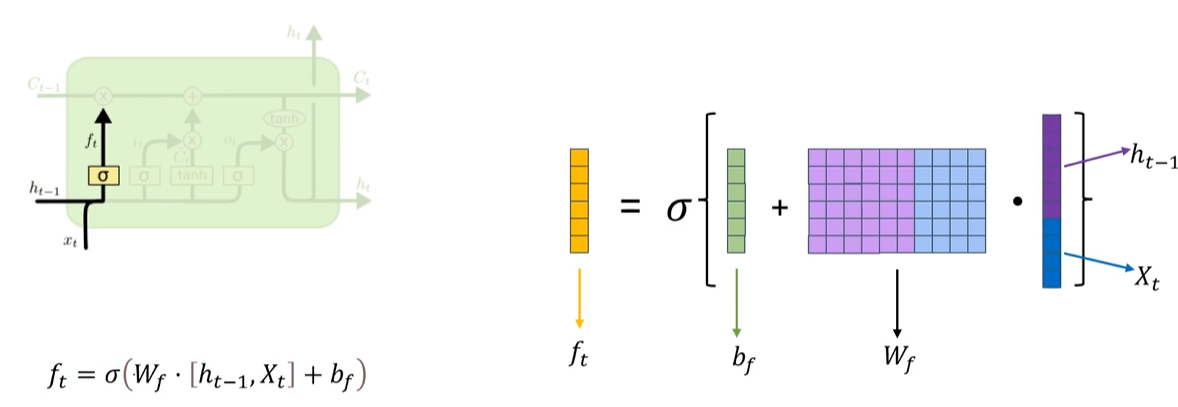
遗忘门就是帮助我们来遗忘信息的
ft 的函数就不在赘述了,其实和前面都差不多,值得一提的是,这里的激活函数是Sigmoid,我们之前讲过Sigmoid会导致梯度消失问题,但这里的作用不一样:
这里是为了将结果映射到 0,1之间,作为一个遗忘的比例,比如说:你的信息是5,然后它认为这些信息都不重要,那就映射成0,那就是5 * 0 = 5。如果它因为你的信息全都很重要,那就映射成1,那就是5 * 1 = 5,全部保留下来。
到底要保留多少,根据公式,是由W权重b偏置,和ht-1输入和当前Xt输入的特征值共同决定的
9. LSTM的输入门
1. 基本结构
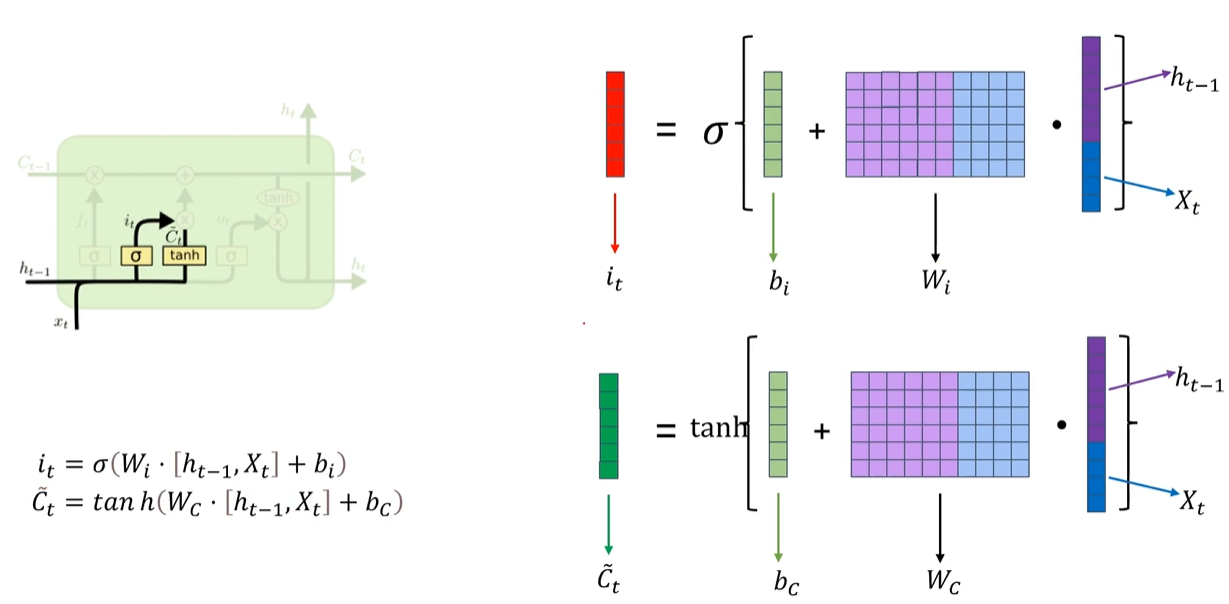
it 就是上面的 ft 一样的
Ct也差不多,就是激活函数换成了tanh双曲正切,因此结果区域为 -1,1
2. LSTM的细胞状态更新
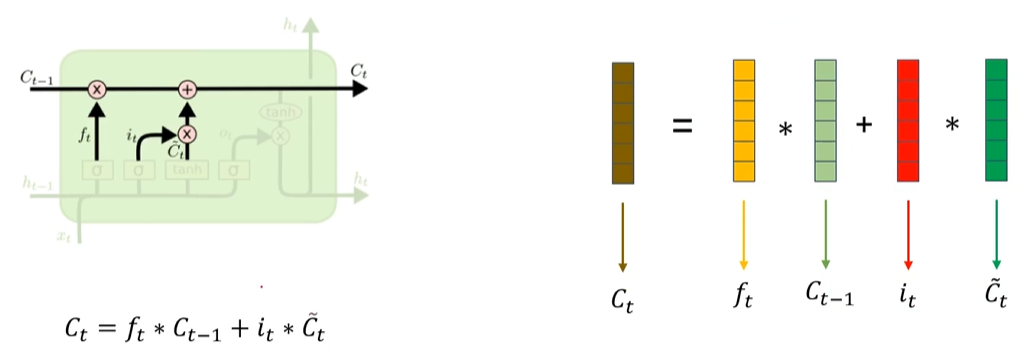
可以看到Ct细胞更新公式,实际上Ct就是 Ct-1的有用信息 + 输入层的有用信息。那么为什么输入层的激活函数要用tanh函数呢?
因为tanh范围是-1到1,不容易梯度爆炸,然后他又负数,可以代表信息中的一些负相关值,sigmoid0到1会梯度爆炸,也不能表达负信息。
10. LSTM的输出门
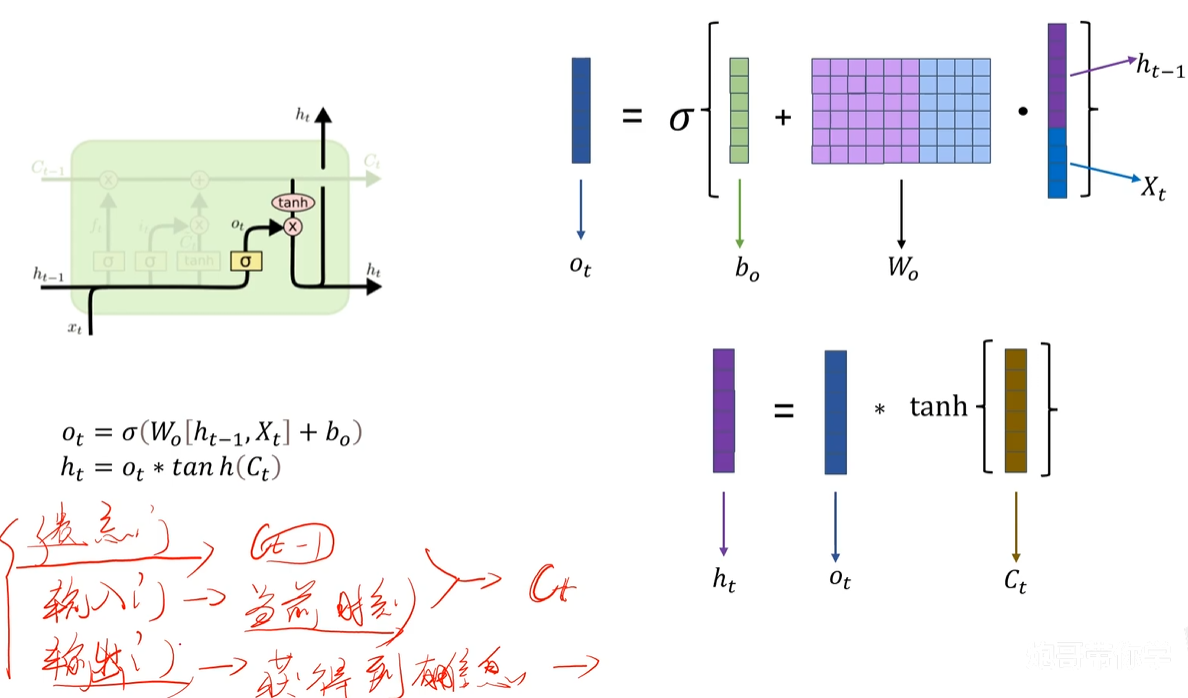
Ot依然再做保留有用信息的比例,而ht就是要输出这一层的结果了,Ct里面保留的是前面所有有用的信息,然后激活函数之后,×上信息的保留比例,最后输出ht
总结: 就是三个门,遗忘门、输入门、输出门。
遗忘门 + 输出门 得到 Ct 保留下来的有用数据------>最后经过输出门,得到输出结果ht
11. LSTM如何缓解梯度消失
要讲它是如何缓解的,依然要从反向传播,更新梯度的角度来看。

明显,LSTM其他公式都挺正常的,唯独更新的时候,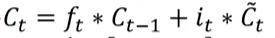 出现了递归,因此我们对Ct求导看看
出现了递归,因此我们对Ct求导看看

我们直接看到求导结果,ft是什么?不就是我们的遗忘门的公式吗。假如说,前面三项相加 = 0.2 这时候只要控制 ft ≈ 0.8,这样四项相加就近似为1了,这样即使连乘,也不会出现梯度趋于0或者趋于无穷了
那么为什么遗忘门可以是 0.8 ?ft 是→w、b、x等参数共同控制的,你可以理解为人为控制,或者说深度学习之后,算法自行的控制,让它最后的结果近似于1。
当时,当你轮次多了之后,还是会有梯度消失和梯度爆炸问题的,毕竟是近似于1,而不是真的等于1,只是说相对于RNN来说,是有缓解的
ChristopherOlah的博文这篇文章写的很好,网上流传也相当之广,可以品读一番,不过需要前面一定的学习基础。