作者:飞桨开发者技术专家 刘力
| 适合人群:刚接触 PaddleOCR-VL + Docker部署的同学
| 学习目标:从一台刚装好的 Ubuntu 24.04 开始,完成 Docker 环境准备 → 拉起 PaddleOCR-VL 服务 → 本机用 HTTP 调用 /layout-parsing 接口跑通文档解析。
一, PaddleOCR-VL是什么、为什么用 Docker?
PaddleOCR-VL 是基于轻量级视觉语言模型(VLM)的文档解析解决方案,核心模型为 PaddleOCR-VL-0.9B,支持多语言文本、表格、公式、图表等元素级识别,并能以较低资源消耗达到 行业SOTA水平。本文推荐读者使用 Docker / Docker Compose 来部署PaddleOCR-VL------好处是依赖打包好、命令少、复现稳定,并且便于生产化扩展(端口、GPU 绑定、挂载配置等)。
- 环境要求与硬件兼容性(必须确认)
1.1 NVIDIA GPU(推荐):
-
若用 vLLM 或 FastDeploy 加速后端,官方要求NVIDIA 驱动支持 CUDA 12.6(并推荐显卡 CC ≥ 8.0,例如 RTX 30/40/50、A10/A100 等)
-
CUDA 12.6 通常对应 560+ 版驱动(NVIDIA 说明文档示例)
1.2 操作系统:Ubuntu 24.04(LTS)。
1.3 Docker 版本:≥ 19.03
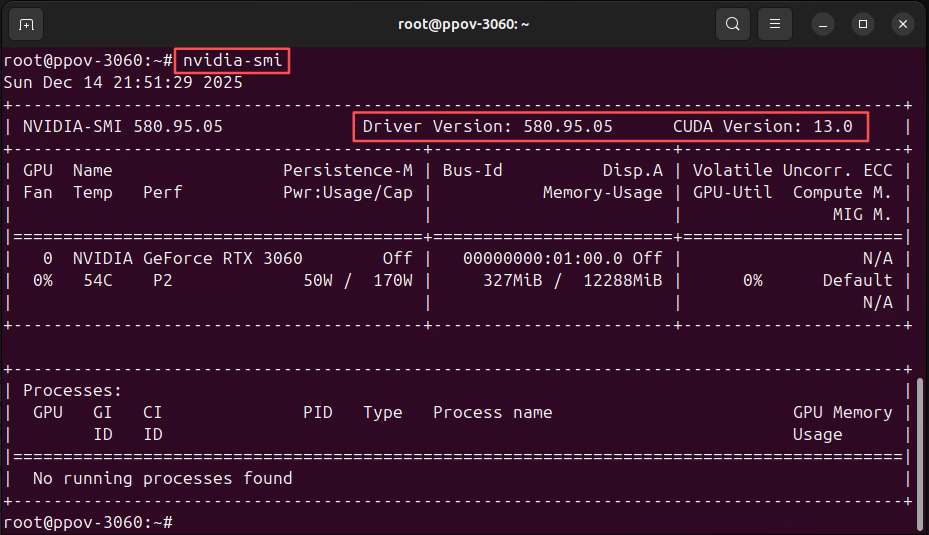
| 检查 GPU 驱动与 CUDA 运行 nvidia-smi ,请确认NVIDIA 驱动版本 > 560+(推荐: 580 )
- 安装 Docker 与 NVIDIA Container Toolkit
目的:让 Docker 能调用宿主机 GPU,并保证后续镜像/Compose 运行顺畅。
2.1 安装 Docker Engine
参考Docker官方文档 , 安装Docker Engine。
https://docs.docker.com/engine/install/ubuntu/2.2 安装 NVIDIA Container Toolkit(让容器获得 GPU)
参考NVIDIA官方安装指南:
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html安装NVIDIA Container Toolkit,让Docker容器能直接使用宿主机上的NVIDIA GPU。
- 用 Docker 拉取 PaddleOCR-VL官方镜像
3.1:直接拉取官方镜像
若机器能连外网,直接 docker pull 官方镜像(推荐):
# 要求:Docker ≥ 19.03,主机有 GPU,NVIDIA 驱动支持 CUDA 12.6+
docker run -it --gpus all --network host --user root \
ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddleocr-vl:latest \
/bin/bash
# 进入容器后,可用 PaddleOCR CLI 或 Python API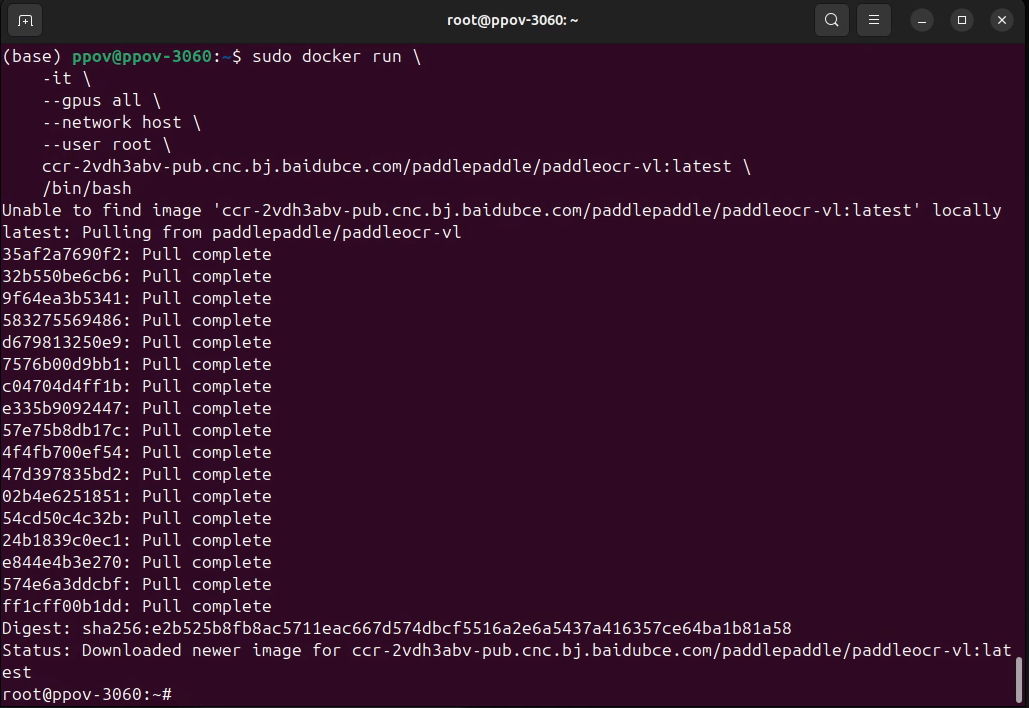
3.2 使用PaddleOCR CLI
镜像启动后,可以使用PaddleOCR CLI,一行命令即可快速体验 PaddleOCR-VL 效果:
paddleocr doc_parser -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png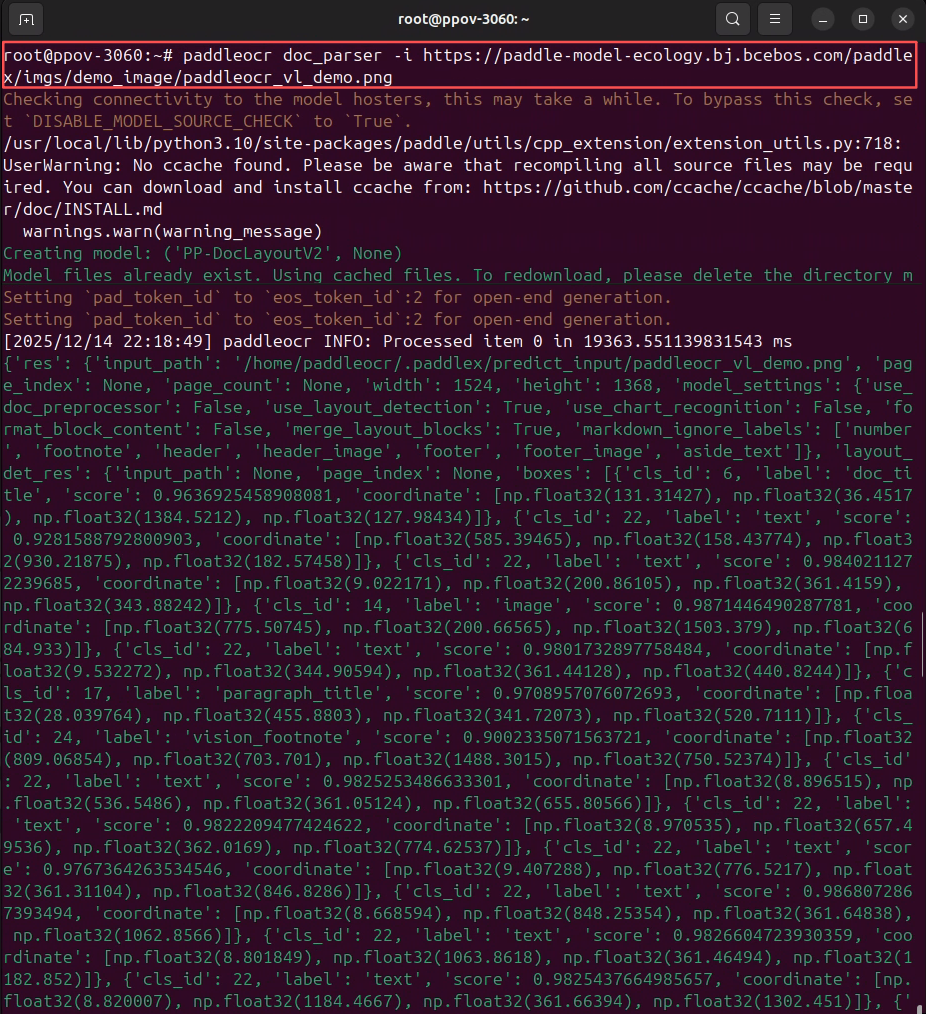
PaddleOCR CLI的详细参数, 请参考:
https://www.paddleocr.ai/latest/version3.x/pipeline_usage/PaddleOCR-VL.html#213.3 使用PaddleOCR Python API
命令行方式是为了快速体验查看效果,实际使用建议用Python API,将PaddleOCR-VL的能力集成到您的应用中。
首先,在容器中创建Python脚本:
cat > demo_vl.py << 'EOF'
from paddleocr import PaddleOCRVL
# 1. 初始化 PaddleOCR-VL 推理管线
pipeline = PaddleOCRVL()
# 你也可以启用/关闭不同模块,例如:
# pipeline = PaddleOCRVL(use_doc_orientation_classify=True) # 文档方向分类
# pipeline = PaddleOCRVL(use_doc_unwarping=True) # 文本图像矫正
# pipeline = PaddleOCRVL(use_layout_detection=False) # 关闭版面分析
# 2. 执行推理
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png")
# 3. 处理结果
for res in output:
# 打印结构化结果到终端
res.print()
# 保存为 JSON
res.save_to_json(save_path="output")
# 保存为 Markdown
res.save_to_markdown(save_path="output")
EOF然后,在容器中执行:
python demo_vl.py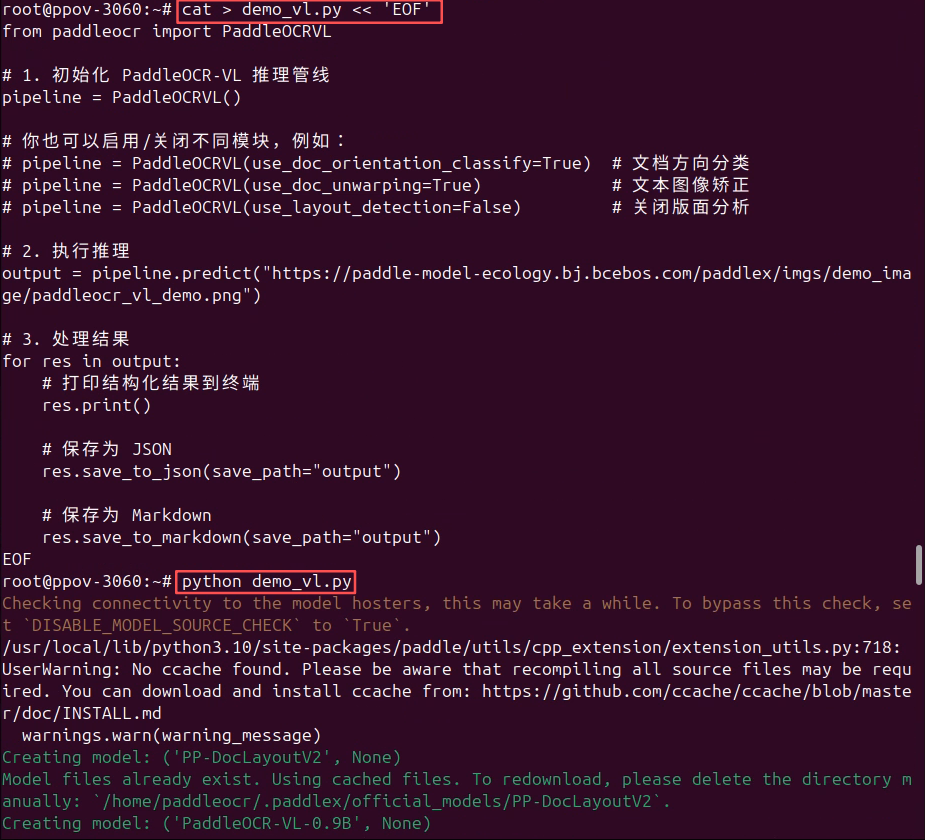
PaddleOCR-VL 提供了开箱即用的 Python 推理接口 PaddleOCRVL。在官方 Docker 镜像中,相关依赖与模型已预先安装,用户只需初始化推理管线并调用 predict() 方法即可完成文档理解任务。推理结果可直接导出为结构化 JSON 或 Markdown,方便下游系统集成。
二, 总结
至此,我们已经从 一台全新的 Ubuntu 24.04 环境 出发,完整走通了 PaddleOCR-VL 的 Docker 化部署与使用流程。你不需要手动安装 CUDA 或下载模型,只需准备好合适版本的 NVIDIA 显卡驱动、Docker 和 NVIDIA Container Toolkit,即可通过官方 Docker 镜像快速获得一个可直接用于生产验证的文档解析环境。
通过本文,你已经掌握了以下关键能力:
-
理解 PaddleOCR-VL 的定位与优势,以及为什么 Docker 是最省心、最稳定的部署方式
-
明确 硬件与驱动要求,避免因 CUDA / 驱动版本不匹配导致的隐性问题
-
完成 Docker 与 GPU 环境准备,并成功在容器中识别和使用 NVIDIA GPU
-
使用 PaddleOCR CLI 快速体验文档解析效果
-
使用 Python API(PaddleOCRVL) 将文档解析能力集成到自己的应用中,并导出 结构化 JSON / Markdown 结果
对于刚入门的用户来说,这已经是一个"最小可用闭环":
**|**从 0 到 1 跑通环境 → 看到效果 → 拿到结构化结果。
在此基础上,你可以继续深入探索更贴近实际业务的场景,例如:
-
使用 Docker Compose 将 PaddleOCR-VL 以服务形式部署,对外提供 HTTP API
-
批量解析 PDF、多页文档,或对接对象存储
-
将解析结果接入 RAG / 向量数据库 / 搜索系统,构建文档理解与问答应用
-
根据实际文档类型,灵活开启或关闭版面分析、方向校正、图像矫正等模块
希望这篇"保姆级教程"能帮你 少踩坑、快上手、跑得稳。当你第一次成功跑出结构化结果时,PaddleOCR-VL 的真正价值,也就自然展现在你眼前了。
祝你使用顺利,玩得开心 🚀
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com