目录
[1-1 什么是软件包](#1-1 什么是软件包)
[1-2 Linux 软件生态和依赖](#1-2 Linux 软件生态和依赖)
[1-3 yum / apt 的基本操作](#1-3 yum / apt 的基本操作)
[1-3-1 查看软件包](#1-3-1 查看软件包)
[1-3-2 安装软件](#1-3-2 安装软件)
[1-3-3 卸载软件](#1-3-3 卸载软件)
[编辑1-3-4 注意事项](#编辑1-3-4 注意事项)
[1-4 安装源配置](#1-4 安装源配置)
[二、编辑器 Vim](#二、编辑器 Vim)
[2-1 Linux 编辑器-vim使用](#2-1 Linux 编辑器-vim使用)
[2-2 vim 的三大模式](#2-2 vim 的三大模式)
[2-3 vim 的基本操作流程](#2-3 vim 的基本操作流程)
[2-4 vim 命令模式常用快捷键](#2-4 vim 命令模式常用快捷键)
[复制 & 粘贴](#复制 & 粘贴)
[替换 / 撤销 / 修改](#替换 / 撤销 / 修改)
[行号 & 跳转](#行号 & 跳转)
[2-5 末行模式常用命令](#2-5 末行模式常用命令)
[三、编译器 gcc/g++](#三、编译器 gcc/g++)
[3-1 背景](#3-1 背景)
[3-2 gcc 常见编译选项](#3-2 gcc 常见编译选项)
[3-2-1 预处理](#3-2-1 预处理)
[3-2-2 编译(生成汇编)](#3-2-2 编译(生成汇编))
[3-2-3 汇编(生成目标文件)](#3-2-3 汇编(生成目标文件))
[3-2-4 链接(生成可执行程序)](#3-2-4 链接(生成可执行程序))
[3-3 静态链接 vs 动态链接](#3-3 静态链接 vs 动态链接)
[3-4 静态库和动态库](#3-4 静态库和动态库)
[3-5 其他常用选项](#3-5 其他常用选项)
[4-1 背景](#4-1 背景)
[4-2 依赖关系的理解](#4-2 依赖关系的理解)
[4-3 最小可用 Makefile 示例](#4-3 最小可用 Makefile 示例)
[4-4 推导过程](#4-4 推导过程)
[4-5 扩展语法](#4-5 扩展语法)
[5-1 回车与换行](#5-1 回车与换行)
[5-2 行缓冲区现象](#5-2 行缓冲区现象)
[5-3 倒计时程序](#5-3 倒计时程序)
[5-4 进度条程序](#5-4 进度条程序)
[六、版本控制器 Git](#六、版本控制器 Git)
[6-1 版本控制](#6-1 版本控制)
[6-2 git 简史](#6-2 git 简史)
[6-3 安装 git](#6-3 安装 git)
[6-4 在 GitHub 创建项目的大致流程](#6-4 在 GitHub 创建项目的大致流程)
[6-5 Git 三板斧:add / commit / push](#6-5 Git 三板斧:add / commit / push)
[七、调试器:gdb / cgdb 使用](#七、调试器:gdb / cgdb 使用)
[7-1 样例代码:从 1 加到 100](#7-1 样例代码:从 1 加到 100)
[7-2 预备:](#7-2 预备:)
[7-3 gdb 常用指令](#7-3 gdb 常用指令)
一、软件包管理器
1-1 什么是软件包
在 Linux 下,装软件有两种基本方法:
-
自己下载源码 → 手动编译 → 安装
-
直接用别人编译好的「软件包」+ 软件包管理器
软件包就可以理解成 Linux 世界里的「安装包(App 安装程序)」,而 yum / apt 就是「应用商店」。
-
Fedora / CentOS / RedHat 系列:常用 yum(现在很多版本是 dnf,本质类似)
-
Ubuntu / Debian 系列:常用 apt
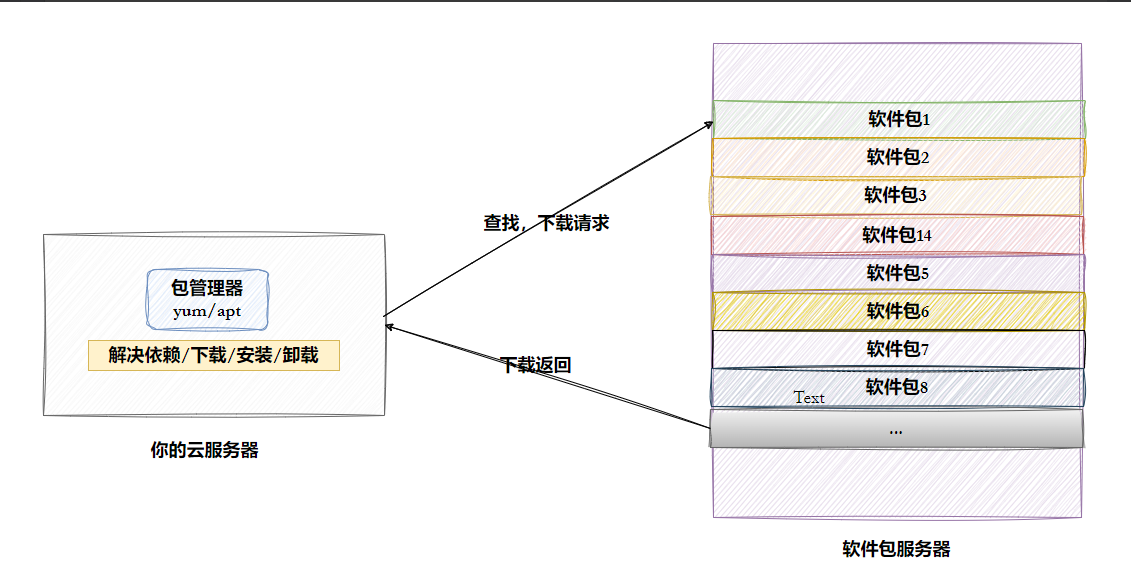
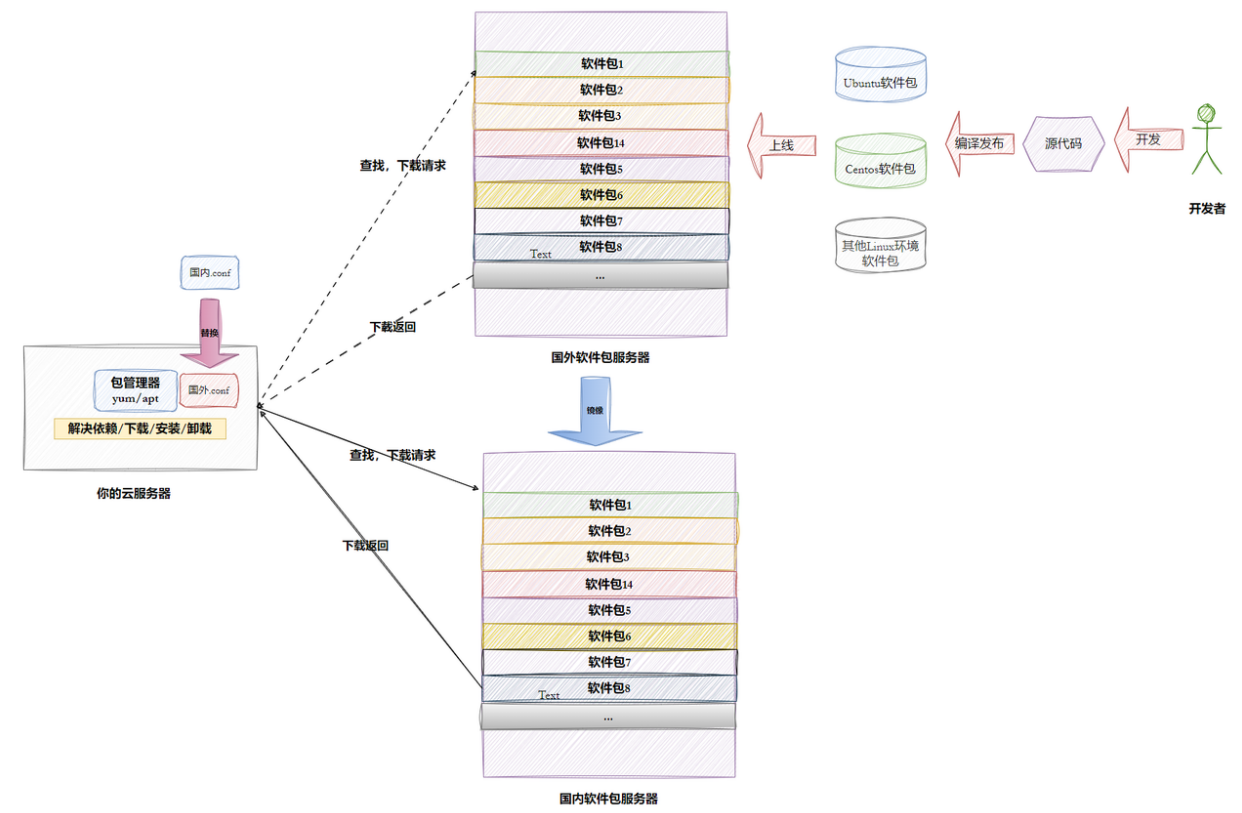
1-2 Linux 软件生态和依赖
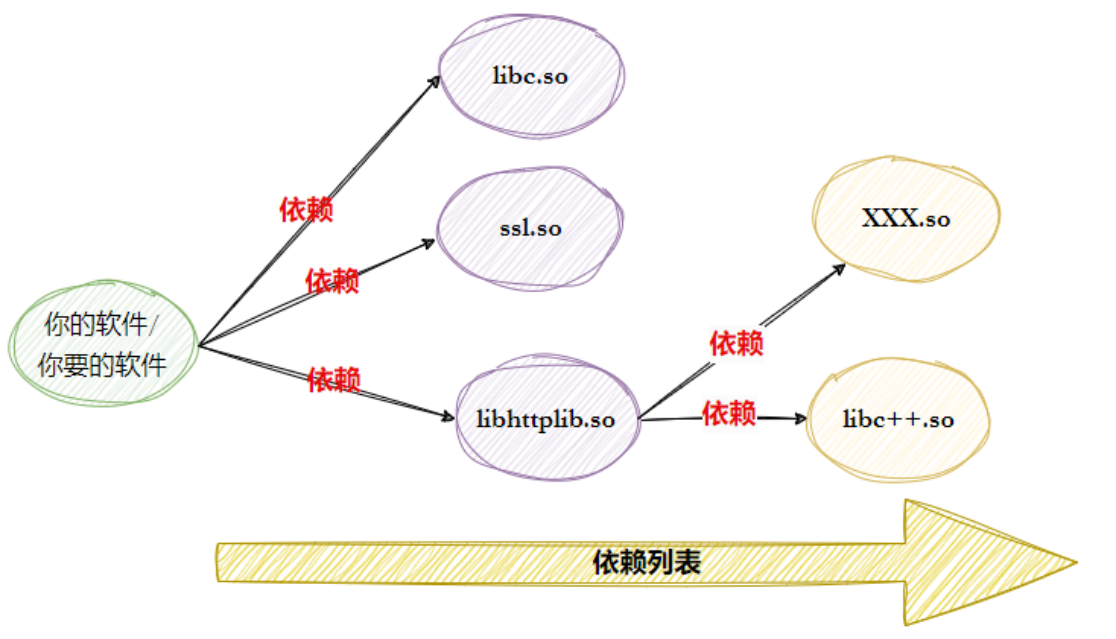
一个软件往往依赖一堆库,比如你写的程序依赖 libhttp.so,它又依赖 ssl.so,再往上还有 libc.so... 这就是「依赖地狱」。软件包管理器的核心价值之一,就是自动帮你解决依赖关系。
同时,Linux 的「好不好用」,很大程度上取决于它的生态:
-
有没有足够多的软件包?
-
有没有好的社区、文档、教程?
-
有没有各大高校/公司提供的 镜像源(加速下载)?
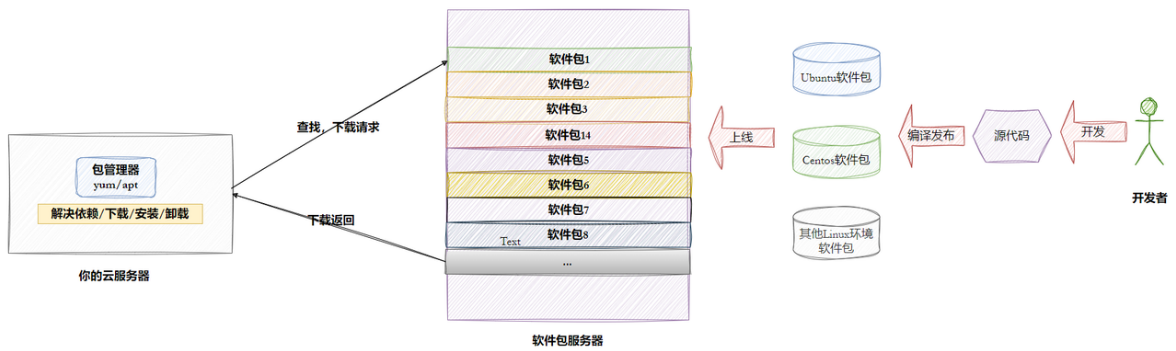
以下是一些国内Linux软件安装源的官方链接**(由gemini生成)**
🏛️ 高校开源镜像站(社区维护,最推荐)
高校镜像站通常由学生社团(如 LUG)维护,不仅包含 Linux 发行版,还包含各种编程语言包(如 Python PyPI, Node.js npm 等),同步速度快,文档详细。
1. 清华大学开源软件镜像站 (TUNA)
-
官方链接:
https://mirrors.tuna.tsinghua.edu.cn/ -
国内最负盛名、最全面的镜像站之一。支持的发行版和软件仓库极多(包括 Ubuntu, Arch, Fedora, CentOS, Homebrew 等),带宽充足,文档非常友好(每种源都有"使用帮助")。
2. 中国科学技术大学镜像站 (USTC)
-
官方链接:
https://mirrors.ustc.edu.cn/ -
历史悠久,是许多其他镜像站的上游来源。在华东及中部地区速度极快,稳定性极高,是 Arch Linux 等发行版的官方推荐源之一。
3. 上海交通大学镜像站 (SJTU)
-
官方链接:
https://mirrors.sjtug.sjtu.edu.cn/ -
由 SJTUG 维护,近年来发展迅猛。除了常规源,它也是 Docker Hub 国内加速的首选之一(需特定配置),且对 Arch Linux 用户有特定优化。
4. 浙江大学开源镜像站 (ZJU)
-
官方链接:
https://mirrors.zju.edu.cn/ -
界面简洁,同步及时。对于在浙江及周边地区的用户,连接速度通常具有优势。
🏢 知名企业镜像站
由互联网巨头维护,通常依托于其云服务基础设施,带宽极其充裕,极其稳定,适合服务器生产环境使用。
1. 阿里云官方镜像站 (Aliyun)
-
官方链接:
https://developer.aliyun.com/mirror/ -
国内最大的云服务商提供,覆盖了几乎所有主流 Linux 发行版(CentOS, Ubuntu, Debian, Alpine)。极其稳定,如果你使用的是阿里云服务器,使用内网源速度更是飞快。
2. 腾讯云软件源 (Tencent)
-
官方链接:
https://mirrors.cloud.tencent.com/ -
依托腾讯云基础设施,不仅提供操作系统源,还提供各种开发工具和容器镜像加速,文档清晰易用。
3. 华为云镜像站
-
官方链接:
https://mirrors.huaweicloud.com/ -
华为云提供的开源组件镜像,不仅有 Linux 系统源,还涵盖了 Java (Maven), Python (PyPI), Go 等语言的依赖包镜像。
4. 网易开源镜像站 (163)
-
官方链接:
http://mirrors.163.com/ -
国内最早期的镜像站之一,非常经典。虽然近年来更新的软件种类不如高校源多,但在 Debian/Ubuntu/CentOS 等基础系统源上依然非常可靠。
1-3 yum / apt 的基本操作
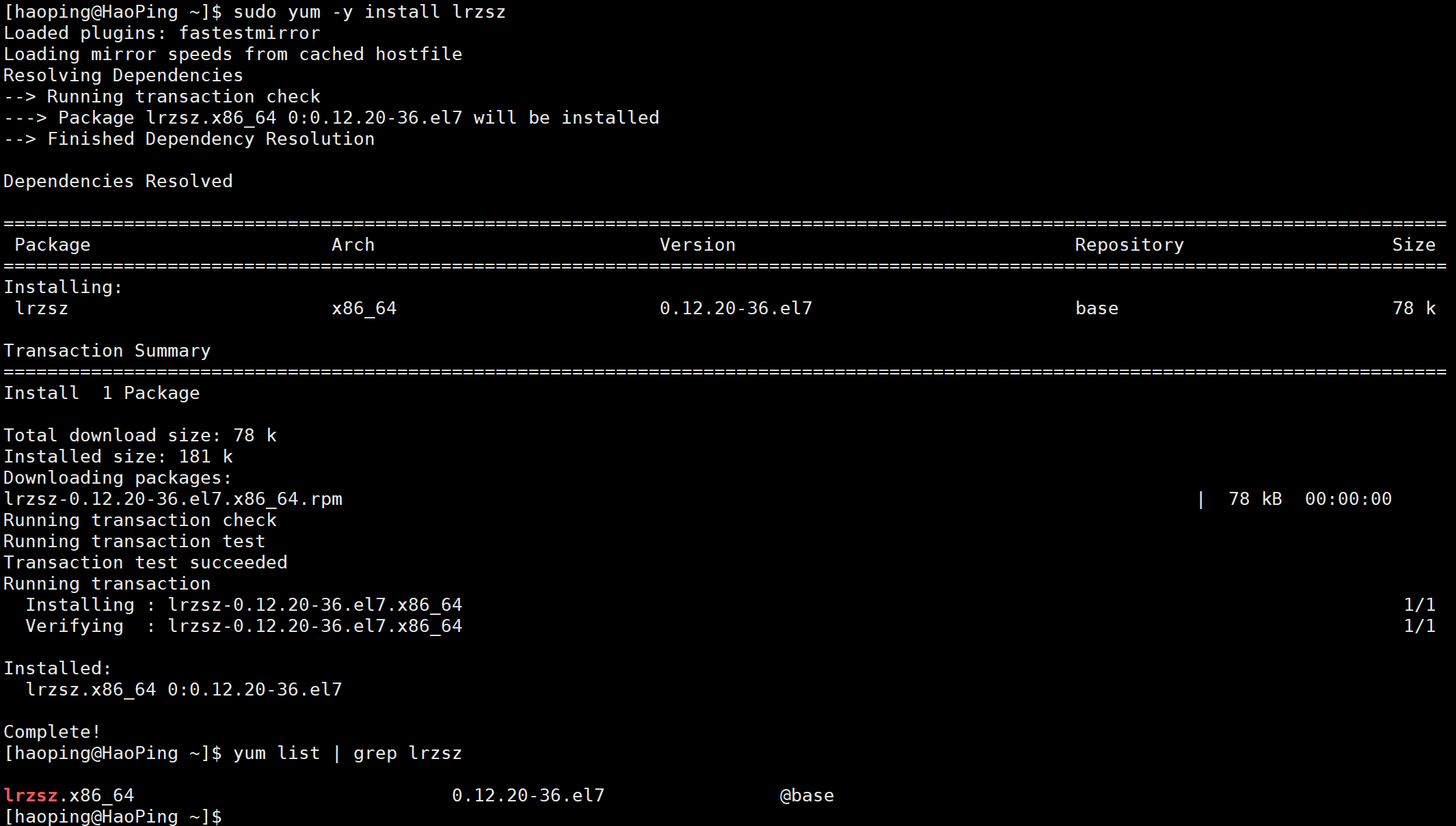
1-3-1 查看软件包
- CentOS:
bash
# 列出所有软件包,再用 grep 过滤
yum list | grep lrzsz- Ubuntu:
bash
apt search lrzsz # 搜索包
apt show lrzsz # 查看详细信息注意软件包名里的关键信息:
-
x86_64:64 位系统包 -
i686:32 位系统包 -
el7:适配 CentOS7/RedHat7 -
最后一列通常是软件源名字,比如
@base就类似「商店名称」。
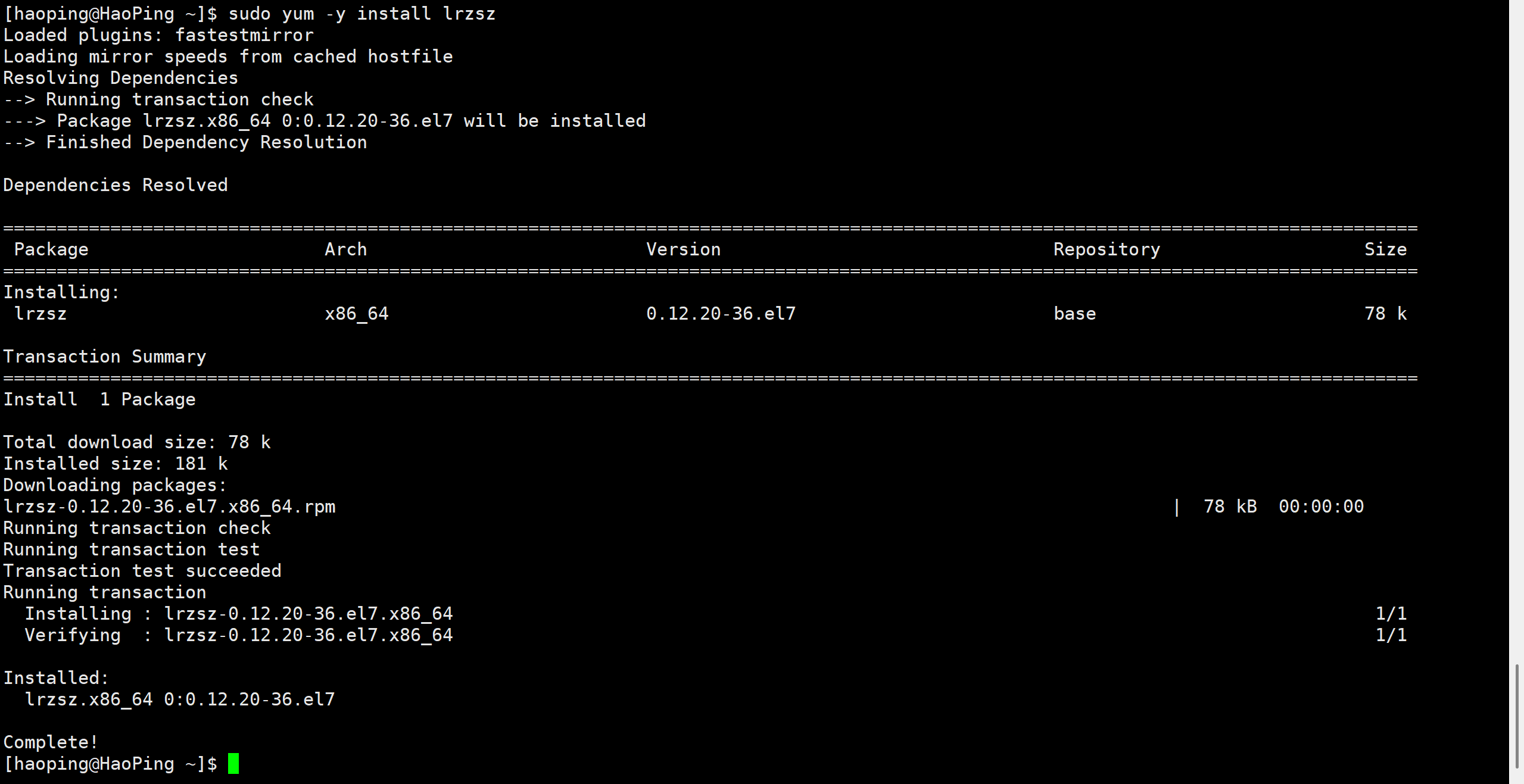
1-3-2 安装软件
-
CentOS:
sudo yum install -y lrzsz
-
Ubuntu:
sudo apt install -y lrzsz
特点:
-
会自动解析依赖,提示需要下载哪些包
-
过程中可能会问
[y/N],-y就是自动选 yes -
最后看到
Complete!或没有报错,说明安装成功
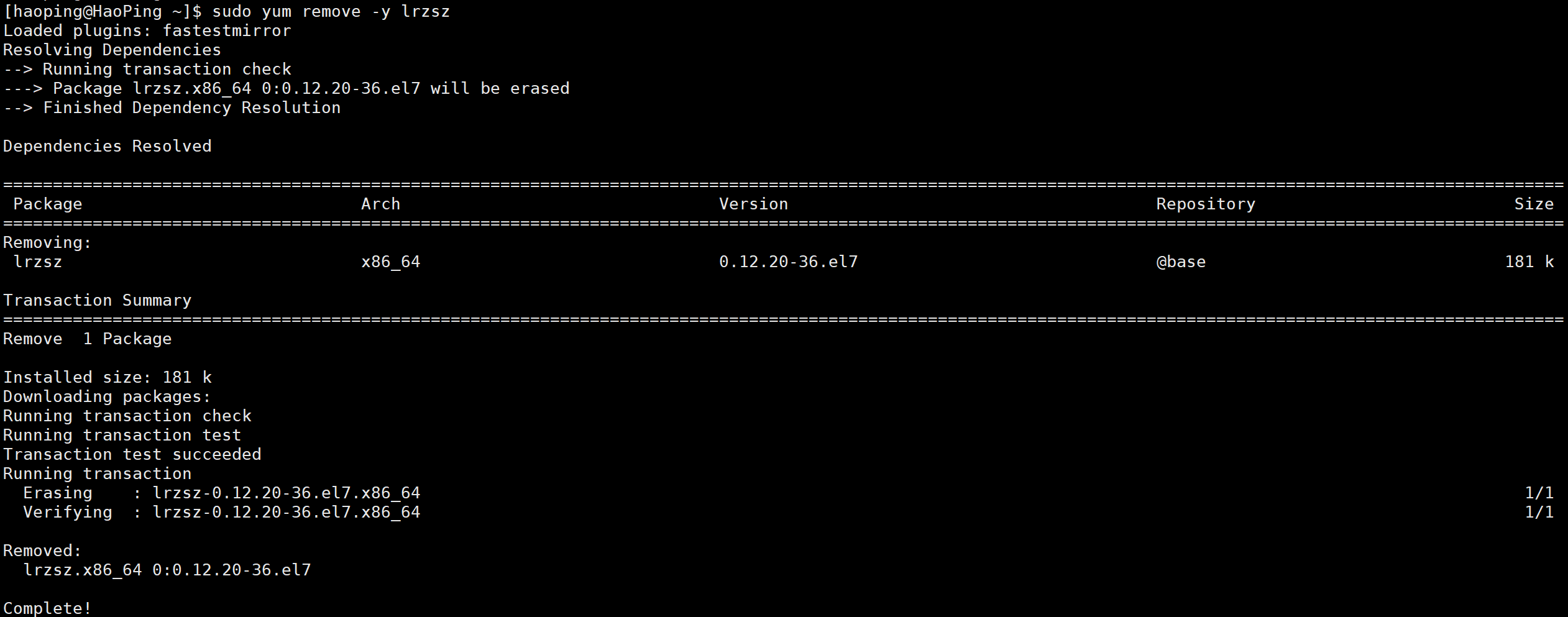
1-3-3 卸载软件
- CentOS:
bash
sudo yum remove -y lrzsz-
Ubuntu:
sudo apt remove -y lrzsz
 1-3-4 注意事项
1-3-4 注意事项
-
必须联网(虚拟机也一样),可以用:
ping www.baidu.com
-
安装/卸载涉及系统目录,一般要
sudo或 root 权限 -
同一时刻只能有一个 yum/apt 在工作,如果另一个没结束就再开一次,会提示锁文件冲突
1-4 安装源配置
软件源配置文件位置:
- CentOS:
bash
ls -l /etc/yum.repos.d/
# CentOS-Base.repo 标准源
# epel.repo 扩展源(需要时用 yum install -y epel-release 安装)- Ubuntu:
bash
cat /etc/apt/sources.list # 标准源
ls -l /etc/apt/sources.list.d/ # 扩展源二、编辑器 Vim
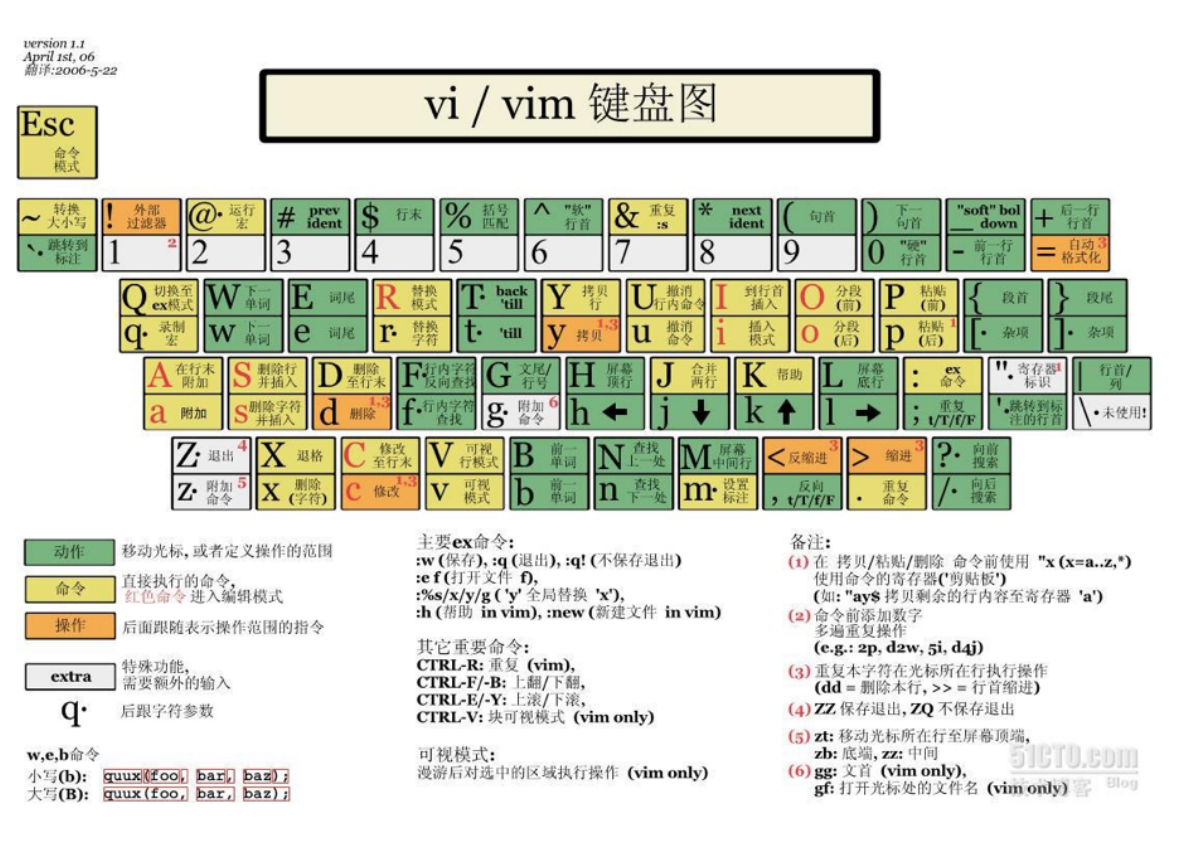
2-1 Linux 编辑器-vim使用
-
vi:传统老编辑器
-
vim:vi 的增强版,支持语法高亮、插件、在终端、X Window、macOS、Windows 都能跑
大多情况下统一使用 vim。
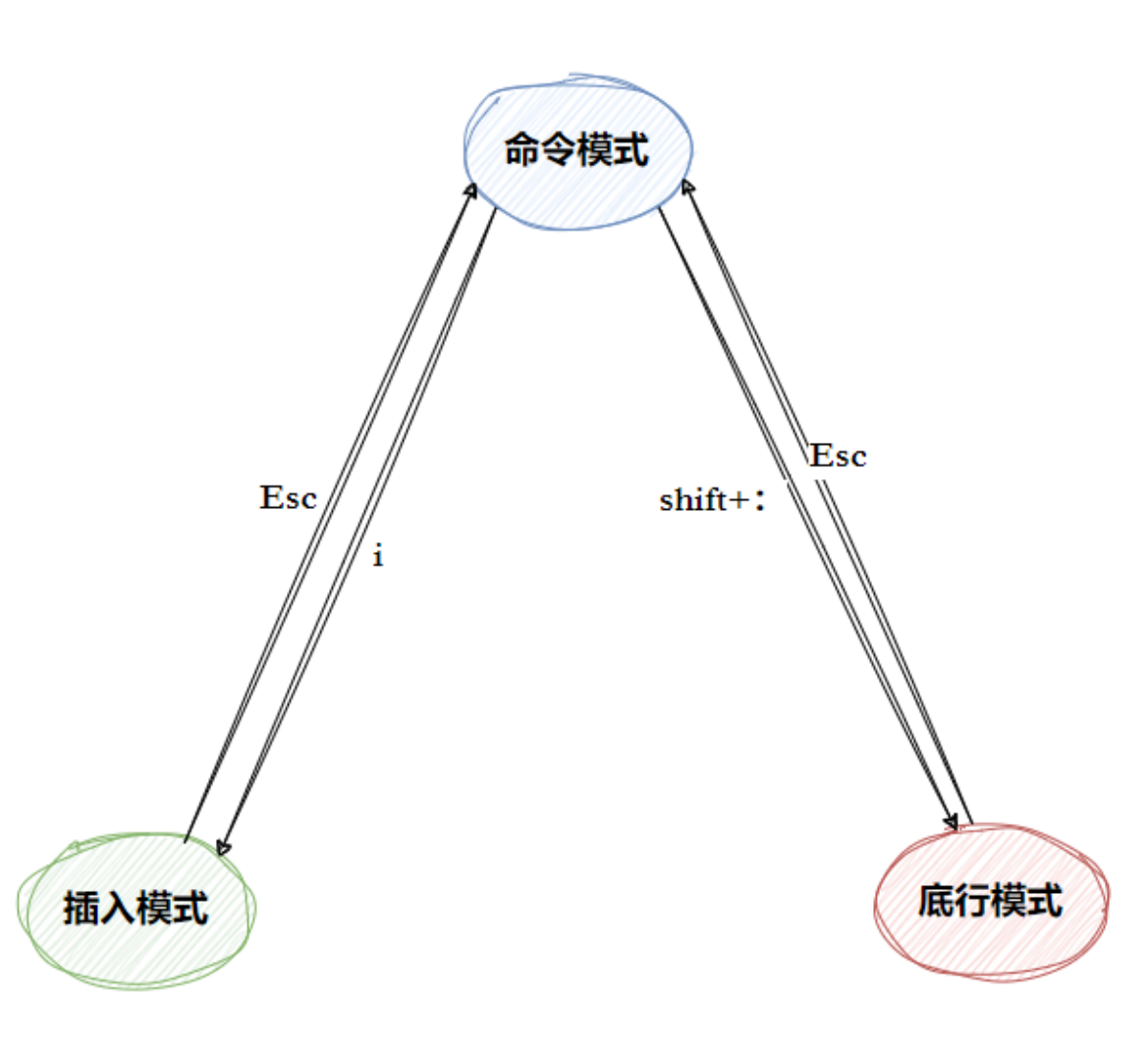
2-2 vim 的三大模式
vim 模式很多,但核心记住三种:
-
命令模式(Normal)
-
打开文件后默认在这里
-
移动光标、删除/复制、跳转、进入其他模式
-
-
插入模式(Insert)
-
真正写入数据
-
通过
i / a / o进入,Esc返回命令模式
-
-
末行模式(Last line / command-line)
-
用来保存、退出、查找、替换、设置行号等
-
在命令模式按
:进入
-
额外:可以在 vim 里输入 :help vim-modes 看所有 12 种模式。
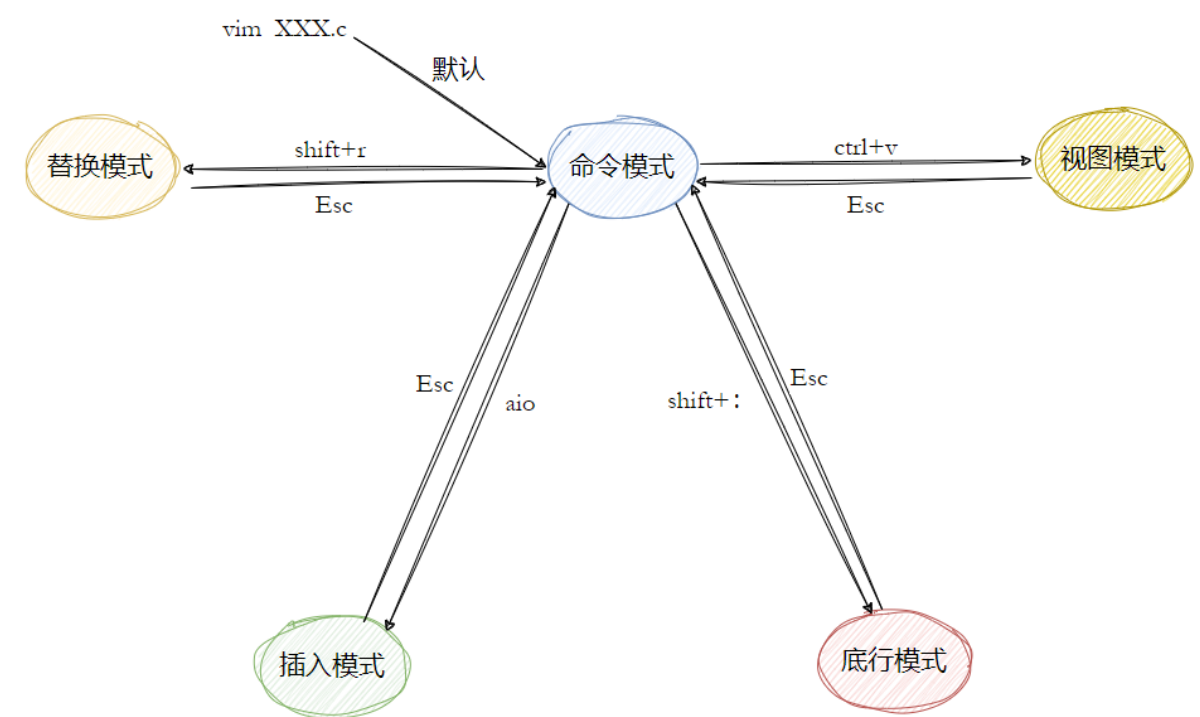
2-3 vim 的基本操作流程
- 进入 vim:
bash
vim test.c- 命令模式 → 插入模式:
-
i:从当前光标位置开始插入 -
a:从光标后一个字符开始插入 -
o:在下一行新开一行,从行首插入
- 插入模式 → 命令模式:
- 按
Esc
- 命令模式 → 末行模式:
:(就是 Shift +;)
-
保存与退出(末行模式):
:w " 保存
:wq " 保存并退出
:q! " 不保存强制退出
2-4 vim 命令模式常用快捷键
插入相关
-
i/a/o:不同方式进入插入模式。-
i : 在当前光标处进入插入模式
-
a : 在当前光标后进入插入模式
-
o : 在当前光标的下方新起一行进入插入模式
-
光标移动
除了方向键,更推荐用 hjkl:
-
h / j / k / l:左 / 下 / 上 / 右 -
G:跳到文件末尾 -
gg:跳到文件开头 -
$:本行行尾 -
^:本行行首 -
w / e / b:以「单词」为单位跳转 -
Ctrl + f / b:整屏上下翻 -
Ctrl + d / u:半屏翻 -
#l:光标移动到当前行第 # 个字符
删除
-
x:删光标所在字符 -
#x:删除接下来 # 个字符 -
X / #X:向前删除 -
dd / #dd:删除当前行 / 向下 N 行
复制 & 粘贴
-
yw / #yw:复制从光标到单词末尾 / N 个单词 -
yy / #yy:复制当前行 / 向下 N 行 -
p:在光标后粘贴(所有y开头命令配合p使用)
替换 / 撤销 / 修改
-
r:替换当前一个字符 -
R:进入覆盖模式,直到Esc -
u:撤销上一步,多次u多级撤销 -
Ctrl + r:反撤销(恢复撤销) -
cw / c#w:修改从光标到单词结束 / N 个单词
行号 & 跳转
-
末行模式
:set nu:显示行号 -
Ctrl + g:显示当前行号 -
#G:跳到第 # 行
2-5 末行模式常用命令
在命令模式先按 : 进入末行模式:
-
行号:
:set nu
:10 " 跳到第 10 行 -
查找:
/关键字 " 向下搜索,n 继续,N 反向
?关键字 " 向上搜索 -
保存与退出:
:w
:q
:q!
:wq
三、编译器 gcc/g++
3-1 背景
一个 C/C++ 源文件,要变成可以运行的二进制,一般要经历四步:
-
预处理(Preprocess):宏展开、删除注释、条件编译、展开头文件等
-
编译(Compile):从 C 代码翻译成汇编
-
汇编(Assemble) :汇编变成机器码(目标文件
.o) -
链接(Link):把多文件+库拼起来生成可执行程序或库文件
3-2 gcc 常见编译选项
通用格式:
bash
gcc [选项] 源文件 [选项] -o 目标文件3-2-1 预处理
bash
gcc -E hello.c -o hello.i-
-E:只做预处理,不继续往下编译 -
输出的
hello.i就是「去注释 + 展开头文件 + 宏替换后」的 C 源码
3-2-2 编译(生成汇编)
bash
gcc -S hello.i -o hello.s-S:只编译到汇编,不做汇编和链接
3-2-3 汇编(生成目标文件)
bash
gcc -c hello.s -o hello.o-c:只汇编,不做链接
3-2-4 链接(生成可执行程序)
bash
gcc hello.o -o hello这一步会把当前目标文件 + 依赖的库文件链接在一起,生成最终程序。
3-3 静态链接 vs 动态链接
静态链接:
-
所需的库代码直接「拷贝一份」进可执行文件
-
文件更大,但运行时不依赖外部库文件
-
更新库函数需要重新编译所有相关程序
动态链接:
-
程序里只记录「用到哪个库」,运行时由系统加载共享库
.so -
节省内存与磁盘空间,多程序共享同一份库
-
更新库文件可以让多个程序一起受益(也有兼容性风险)
用 ldd 查看程序依赖的动态库:
ldd hello你会看到类似 libc.so.6 等动态库。
3-4 静态库和动态库
在 Linux 下约定俗成:
-
静态库 :
libxxx.a -
动态库 :
libxxx.so
gcc 默认优先使用动态库,要用静态链接可以加 -static(前提是系统安装了对应的 .a 静态库):
bash
# CentOS 安装常见 C/C++ 静态库
sudo yum install -y glibc-static libstdc++-static3-5 其他常用选项
几个常见的:
-
-E / -S / -c:四阶段中前 3 步 -
-o:指定输出文件名 -
-g:生成调试信息(给 gdb 用) -
-static / -shared:静态/动态链接 -
-O0/1/2/3:优化级别(O3 优化最多) -
-w / -Wall:关闭 / 开启所有警告(开发建议开-Wall)
四、自动化构建-make/Makefile
4-1 背景
为什么需要 Makefile?
当项目只有一个 hello.c 时,gcc hello.c -o hello 还能接受;
当项目有十几个 .c、几十个 .h,每次都手敲一长串 gcc 命令就非常痛苦了。
Make + Makefile 的作用:
-
只要写好一次规则,以后只需一个
make,整个工程自动重编译 -
根据文件的「修改时间」智能判断哪些需要重新编译
4-2 依赖关系的理解
可以类比 PPT 里的「月底要钱」的例子:老板要看的是最终报表,但报表依赖你填的明细表,明细表又依赖每天的原始数据,少一环都不行。
在 Makefile 中:
-
目标(target) 依赖 一堆源文件(prerequisites)
-
make会从第一个目标开始,层层追踪依赖,直到找到所有必需的中间文件
4-3 最小可用 Makefile 示例
myproc.c:
bash
#include <stdio.h>
int main() {
printf("hello Makefile!\n");
return 0;
}Makefile:
bash
myproc: myproc.c
gcc -o myproc myproc.c
.PHONY: clean
clean:
rm -f myproc使用方式:
bash
make # 生成 myproc
./myproc
make clean # 删除编译结果说明:
-
myproc依赖myproc.c -
gcc -o myproc myproc.c是生成规则 -
clean是「伪目标」,不会被自动执行,但可以make clean -
.PHONY: clean:声明为伪目标,让 make 不去管它和同名文件的时间戳问题
4-4 推导过程
可以把预处理、编译、汇编、链接全部展开写成多个目标:
bash
myproc: myproc.o
gcc myproc.o -o myproc
myproc.o: myproc.s
gcc -c myproc.s -o myproc.o
myproc.s: myproc.i
gcc -S myproc.i -o myproc.s
myproc.i: myproc.c
gcc -E myproc.c -o myproc.i
.PHONY: clean
clean:
rm -f *.i *.s *.o myproc执行 make 时,make 会按依赖顺序自动调用每一步。
核心工作流程:
-
找到 Makefile 的第一个目标(这里是
myproc) -
判断目标是否存在、是否「比依赖旧」
-
如果需要,就继续递归处理依赖(
myproc.o→myproc.s→myproc.i→myproc.c) -
找不到依赖文件就报错退出
4-5 扩展语法
更通用的写法:
bash
BIN = proc.exe
CC = gcc
#SRC = $(shell ls *.c)
SRC = $(wildcard *.c) #当前目录所有 .c
OBJ = $(SRC:.c=.o) #将SRC的所有同名.c 替换 成为.o 形成⽬标⽂件列表
LFLAGS = -o #链接选项
CFLAGS = -c #链接选项
RM = rm -f
$(BIN): $(OBJ)
@$(CC) $(LFLAGS) $@ $^ #$@:代表⽬标⽂件名。 $^: 代表依赖⽂件列表
@echo "linking ... $^ -> $@"
%.o: %.c #%.c 展开当前⽬录下所有的.c。 %.o: 同时展开同名.o
@$(CC) $(CFLAGS) $< #%<: 对展开的依赖.c⽂件,⼀个⼀个的交给gcc
@echo "compiling ... $< -> $@" #@:不回显命令
.PHONY: clean test
clean:
$(RM) $(OBJ) $(BIN) #$(RM): 替换,⽤变量内容替换它
test:
@echo $(SRC)
@echo $(OBJ)这里用到了:
-
变量:
$(BIN) / $(SRC)等 -
通配规则:
%.o: %.c -
自动变量:
-
$@:当前目标 -
$^:所有依赖 -
$<:第一个依赖
-
-
@:不在终端回显命令本身,只显示输出
五、练手系统程序-进度条
5-1 回车与换行
在终端输出里,\n 是换行(向下移动一行),\r 是回车(回到本行行首)。
做进度条这种「在同一行不断刷新」的效果,就离不开 \r。
建议配图:老式打字机键盘,演示「回车」和「换行」的区别。
5-2 行缓冲区现象
示例 1:带 \n 的输出,立刻显示:
bash
printf("hello bite!\n");
sleep(3);示例 2:不带 \n,终端可能要等程序结束才会一次性输出,这是因为 stdout 默认是行缓冲。
解决方法:
bash
printf("hello bite!");
fflush(stdout); // 手动刷新缓冲区
sleep(3);5-3 倒计时程序
bash
#include <stdio.h>
#include <unistd.h>
int main() {
int i = 10;
while (i >= 0) {
printf("%-2d\r", i); // 用 \r 回到行首
fflush(stdout);
i--;
sleep(1);
}
printf("\n");
return 0;
}5-4 进度条程序
核心思路:
-
准备一个字符串数组
buffer[NUM],初始全是空 -
每次把前面一部分填成
=,表示进度 -
用
\r回车 +fflush(stdout)刷新显示 -
配合一个
|/-\的小动画当「转圈圈」指示
process.c(版本一):
cpp
#define NUM 101
#define STYLE '='
void process_v1() {
char buffer[NUM];
memset(buffer, 0, sizeof(buffer));
const char *lable = "|/-\\";
int len = strlen(lable);
int cnt = 0;
while (cnt <= 100) {
printf("[%-100s][%d%%][%c]\r",
buffer, cnt, lable[cnt % len]);
fflush(stdout);
buffer[cnt] = STYLE;
cnt++;
usleep(50000);
}
printf("\n");
}process.c(完整版本二):
cpp
void FlushProcess(double total, double current)
{
char buffer[NUM]; //进度条
memset(buffer, 0, sizeof(buffer));
const char* lable = "|/-\\"; //加载图标
int len = strlen(lable);
int num = (int)(current * 100 / total); //进度条的进度(需要填充多少STYLE)
for(int i = 0; i < num; ++i)
{
buffer[i] = STYLE;
}
static int cnf = 0; //每次调用FlushProcess函数时cnf不变,目的是保持加载图标正常旋转
cnf %= len;
double rate = current / total; //加载进度
printf("[%-100s][%.1lf%%][%c]\r", buffer, rate * 100, lable[cnf++]);
fflush(stdout);
}main.c:
cpp
#include"process.h"
double total = 1024.0;
double speed = 1.0;
void DownLoad()
{
double current = 0;
while(current <= total)
{
FlushProcess(total, current);
//下载代码
usleep(3000); //充当下载数据
current += speed;
}
printf("\ndownload %.2lfMB Done\n", current);
}
int main()
{
//process_v1();
DownLoad();
return 0;
} 六、版本控制器 Git
6-1 版本控制
没有版本控制时,你可能会看到这样的文件命名:
-
报告-v1
-
报告-v2
-
报告-确定版
-
报告-最终版
-
报告-究极进化版......
代码项目也一样:需要能回溯历史、对比版本、多人协作,这就是 版本控制器(VCS) 的作用。
Git 可以管理任意类型文件,对我们来说最重要的是:管理源代码。
6-2 git 简史
-
Linux 内核最早用手动打补丁管理
-
后来用了商业的 BitKeeper
-
2005 年合作破裂,Linus 自己撸了一个新的版本控制系统:Git
-
目标:速度快、设计简单、支持大量分支、完全分布式、能管理超大项目
6-3 安装 git
bash
sudo yum install -y git
git --version6-4 在 GitHub 创建项目的大致流程
1.注册 GitHub 账号(邮箱验证)
2.登录后在主页点击 New repository
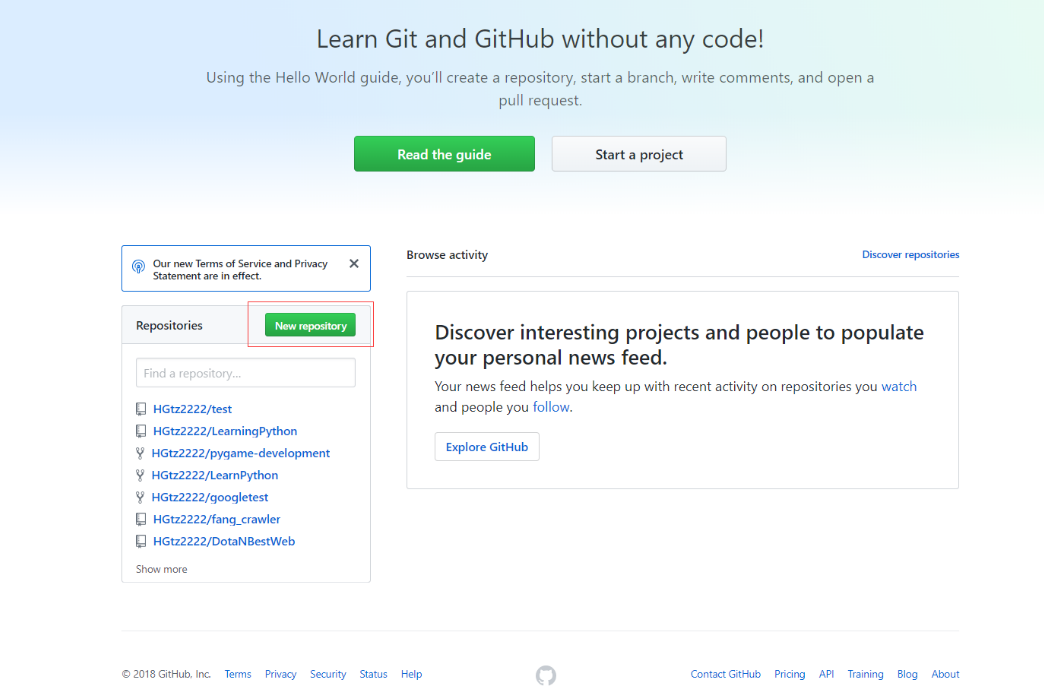
3.填好仓库名,Create repository
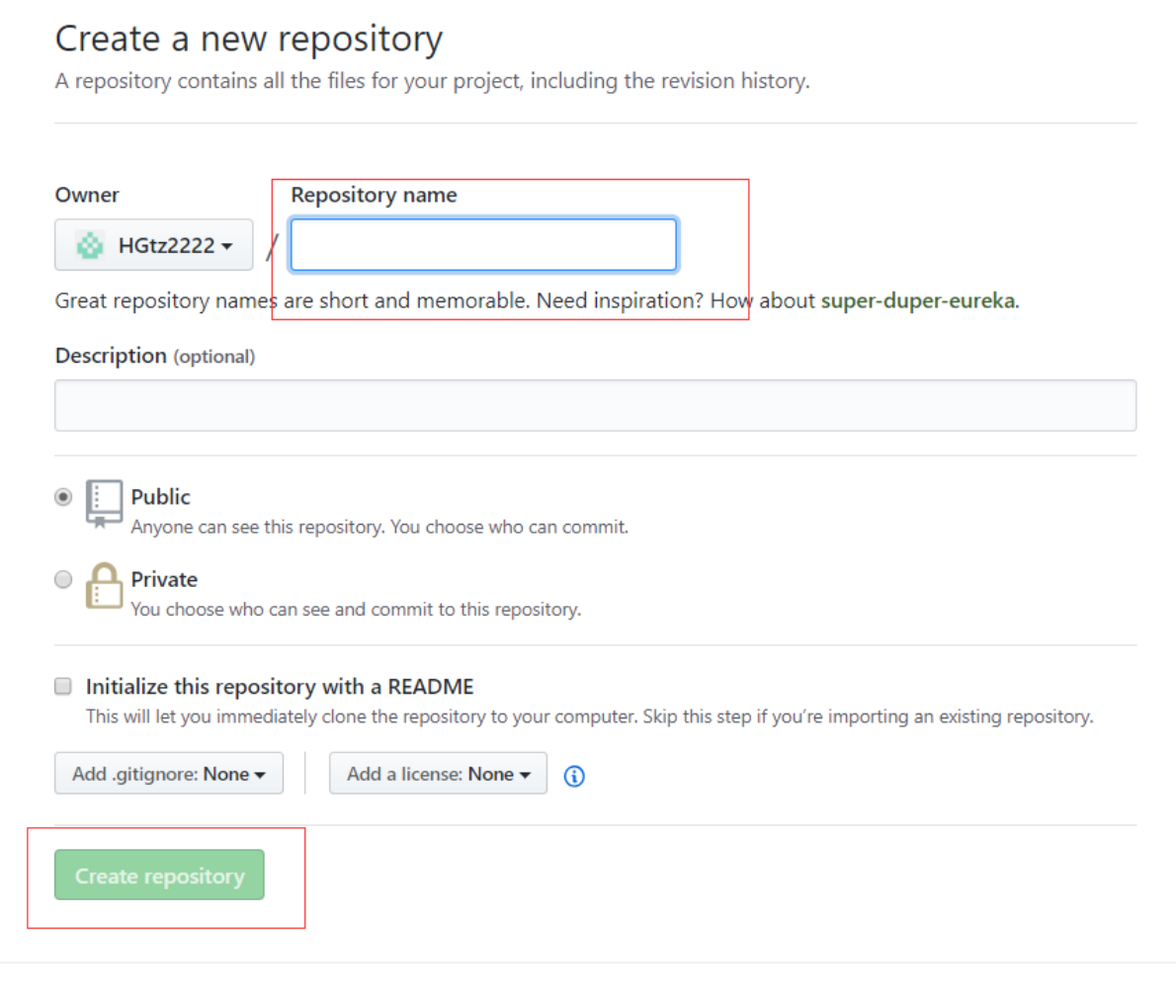
4.在仓库页面复制仓库的 HTTPS/SSH 链接

在本地某个目录克隆:
bash
git clone <仓库地址>6-5 Git 三板斧:add / commit / push
-
把你的代码文件扔进刚才 clone 下来的目录
-
常规三步:
bash
git add <文件名> # 告诉 git:这个文件要纳入版本控制
git commit -m "描述这次改动" # 提交到本地仓库
git push # 推送到远端(GitHub)首推会要求输入用户名/密码或使用 Token,配置好之后建议再配一下 SSH key 或凭据缓存实现「免密码提交」。
常用辅助命令:
-
git status:看当前改动情况 -
git log:看提交历史 -
.gitignore:忽略不想被提交的文件(比如编译结果、临时文件)
七、调试器:gdb / cgdb 使用
7-1 样例代码:从 1 加到 100
mycmd.c:
cpp
int Sum(int s, int e) {
int result = 0;
for (int i = s; i <= e; i++) {
result += i;
}
return result;
}
int main() {
int start = 1;
int end = 100;
printf("I will begin\n");
int n = Sum(start, end);
printf("running done, result is: [%d-%d]=%d\n",
start, end, n);
return 0;
}7-2 预备:
注意:编译时一定要加 -g
gdb 只能调试带调试信息的二进制:
bash
gcc mycmd.c -o mycmd -g # 建议平时都这么写7-3 gdb 常用指令
进入 & 退出:
bash
gdb mycmd # 进入
Ctrl + D / quit # 退出核心命令举例:
-
查看代码:
-
list/l -
list 10显示第 10 行附近 -
list main显示函数 main -
list mycmd.c:1从文件第 1 行开始
-
-
运行:
-
run/r从头运行 -
continue/c继续运行
-
-
单步:
-
next/n单步执行,不进入函数 -
step/s单步执行,进入函数内部
-
-
断点:
-
break 10/b 10 -
break main -
info break查看断点 -
delete breakpoints/disable/enable
-
-
打印与修改变量:
-
print x/p 表达式 -
set var i=10 -
display x/undisplay 1
-
-
调用栈:
-
backtrace/bt -
info locals查看局部变量
-