引言:什么是卷积神经网络?
想象一下,你在看一张照片,比如一张猫的图片。你的大脑如何瞬间认出这是只猫?它不是逐个像素地检查,而是捕捉到猫的特征:毛茸茸的毛、尖耳朵、胡须等。这些特征分布在图片的不同部分,大脑通过层层处理,最终得出结论。这就是卷积神经网络(Convolutional Neural Network,简称CNN)的灵感来源。
CNN是一种深度学习模型,专门设计用于处理图像、视频等网格状数据。它不像传统神经网络那样把所有信息一股脑儿扔进去,而是模仿人类视觉系统,通过"局部感知"和"参数共享"来高效提取特征。CNN在2012年ImageNet竞赛中大放异彩,自那以后,它成为计算机视觉领域的霸主,帮助我们实现了人脸识别、自动驾驶、医疗图像分析等神奇应用。
为什么CNN这么牛?传统方法处理图像时,需要手动设计特征提取规则,比如边缘检测。但CNN通过数据驱动的方式自动学习特征,从低级(如边缘、纹理)到高级(如物体形状)。这大大降低了人工干预,提高了准确率。本文将用通俗语言解释CNN,从基础到应用,配以图文,帮助你一步步理解。文章将超过2000字,确保详尽易懂。
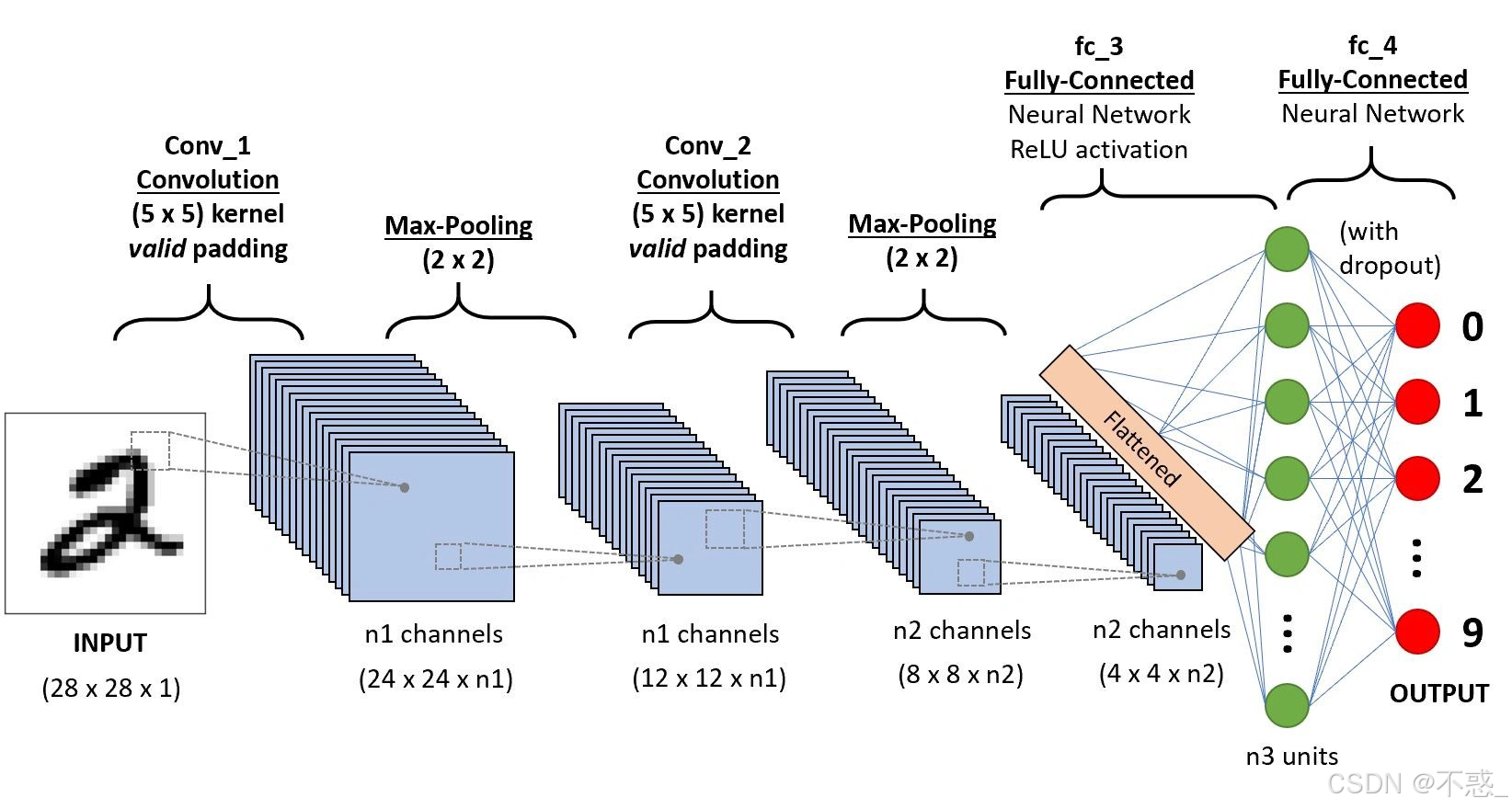
上图展示了一个典型的CNN架构:从输入图像开始,经过卷积层、池化层,到全连接层,最终输出分类结果。我们将逐一拆解这些部分。
神经网络基础:CNN的前身
要懂CNN,先得了解普通神经网络。神经网络模仿人脑神经元:每个神经元接收输入,计算加权和,加上偏置,然后通过激活函数输出。
一个简单的前馈神经网络有输入层、隐藏层和输出层。输入是数据(如像素值),隐藏层处理信息,输出是预测(如"是猫还是狗")。训练过程用反向传播算法:计算误差,调整权重,使预测更准。
但普通神经网络处理图像有问题。图像是高维数据,一张32x32的彩色图就有3072个像素。如果全连接,每个神经元连这么多输入,参数爆炸(上亿!),计算量巨大,还忽略了图像的空間结构------像素间有局部相关性,比如眼睛总在脸的上半部。
CNN解决了这些痛点。它引入卷积操作,只关注局部区域,并共享参数,极大减少计算量。简单说,CNN是神经网络的"图像特化版"。
CNN的核心组件一:卷积层
卷积层是CNN的灵魂。什么是卷积?别被数学吓到,通俗讲,它就像用一个"小窗户"(滤波器或内核)在图像上滑动,提取特征。
假设图像是灰度图(单通道),滤波器是个3x3矩阵。滑动时,对应像素相乘求和,得到新像素。这就像在检测边缘:特定滤波器能突出垂直线条。
对于彩色图像(RGB三通道),滤波器也是三维的。多个滤波器产生多个特征图(feature maps),每个捕捉不同特征,如颜色、纹理。
关键优势:
- 局部连接:每个神经元只连一小块区域,模拟视觉皮层。
- 参数共享:同一个滤波器在整张图上用,参数少。
- 平移不变性:物体移动位置,特征仍能检测。
数学上,卷积公式是:输出 = 输入 * 滤波器 + 偏置。其中*是卷积运算。
stride(步长)决定滑动间隔,padding(填充)处理边缘。stride=1全覆盖,stride=2降采样。
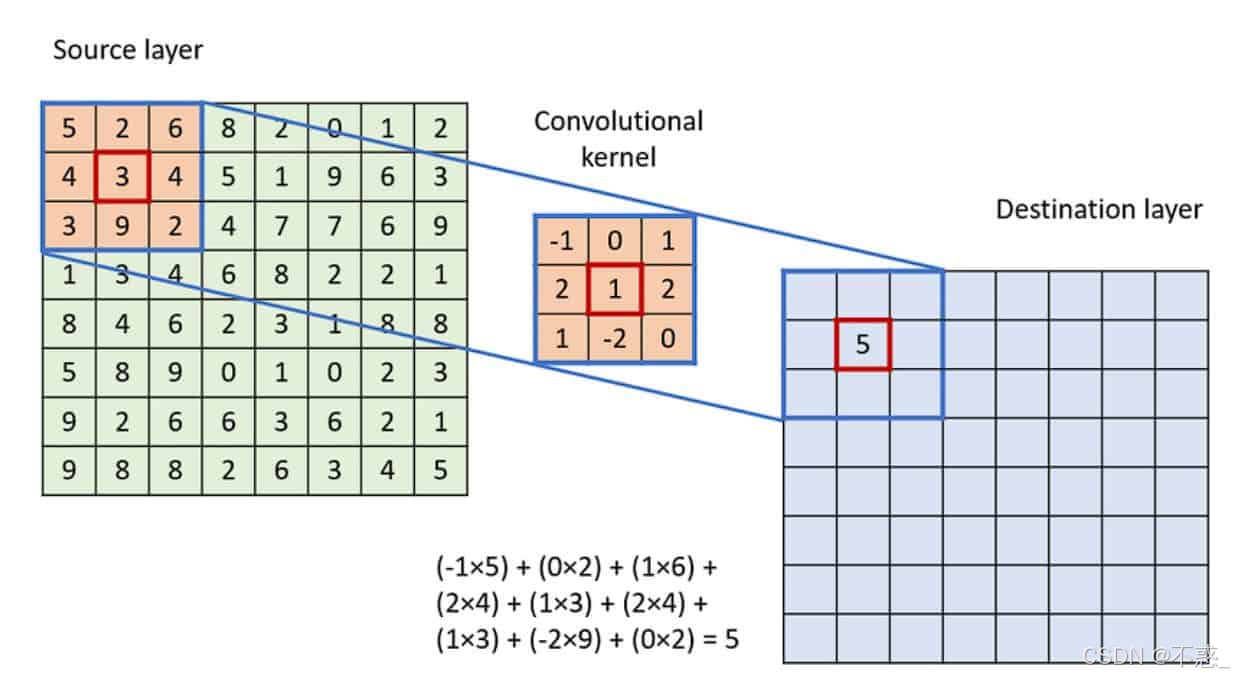
上图是一个卷积操作示例:滤波器在输入上滑动,生成输出特征图。注意如何捕捉局部模式。
多层卷积:浅层学低级特征(如边缘),深层学高级特征(如脸部)。
CNN的核心组件二:激活函数
卷积后,为什么需要激活?因为线性运算堆积仍是线性,无法处理复杂非线性问题。激活函数引入非线性,让网络拟合任意函数。
常见的是ReLU(Rectified Linear Unit):f(x) = max(0, x)。简单高效:负值变0,正值不变。避免梯度消失(sigmoid问题),计算快。
其他:Sigmoid(0-1间),用于二分类;Tanh(-1到1),中心0;Leaky ReLU,负值小斜率,避免"死亡ReLU"。
在CNN中,激活通常跟在卷积后,形成"卷积+激活"单元。
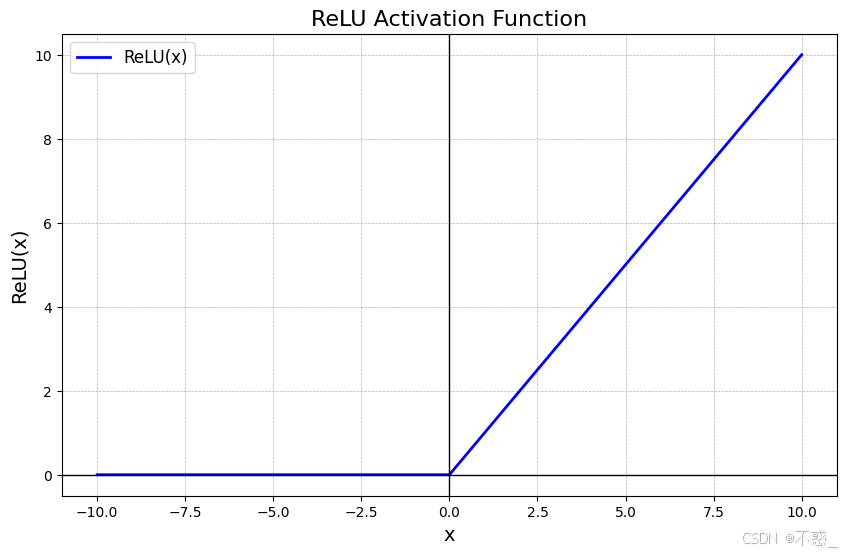
上图是ReLU函数图:x<0时0,否则x。简单却强大。
CNN的核心组件三:池化层
池化(Pooling)是降采样,减少维度,防止过拟合,保留重要信息。
最常见是Max Pooling:用2x2窗口,取最大值。Average Pooling取平均。
好处:
- 减少参数,加速计算。
- 引入平移不变性:小位移不影响最大值。
- 提取显著特征。
通常跟在卷积+激活后。stride=2,尺寸 halved。
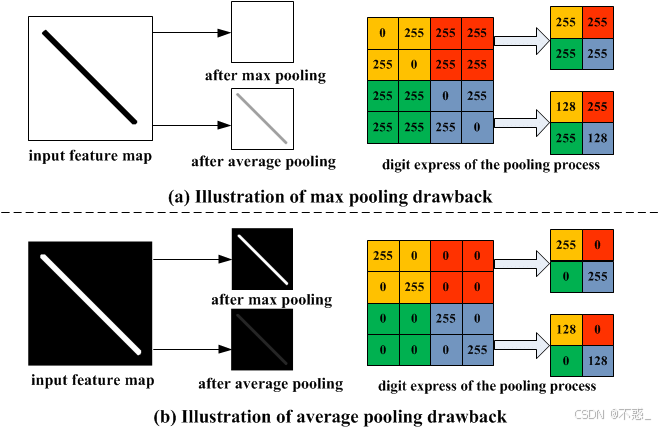
上图展示Max Pooling:从4x4区域取最大,输出2x2。
注意,池化无参数,只汇总。
CNN的核心组件四:全连接层
经过多层卷积和池化,特征图扁平化(flatten),送入全连接层(Fully Connected, FC)。
FC层像传统神经网络:每个神经元连上层所有。用于整合全局特征,做最终分类。
最后一层通常用Softmax:输出概率分布,如"猫90%,狗10%"。
但FC参数多,现代CNN如ResNet减少FC,用全局平均池化。
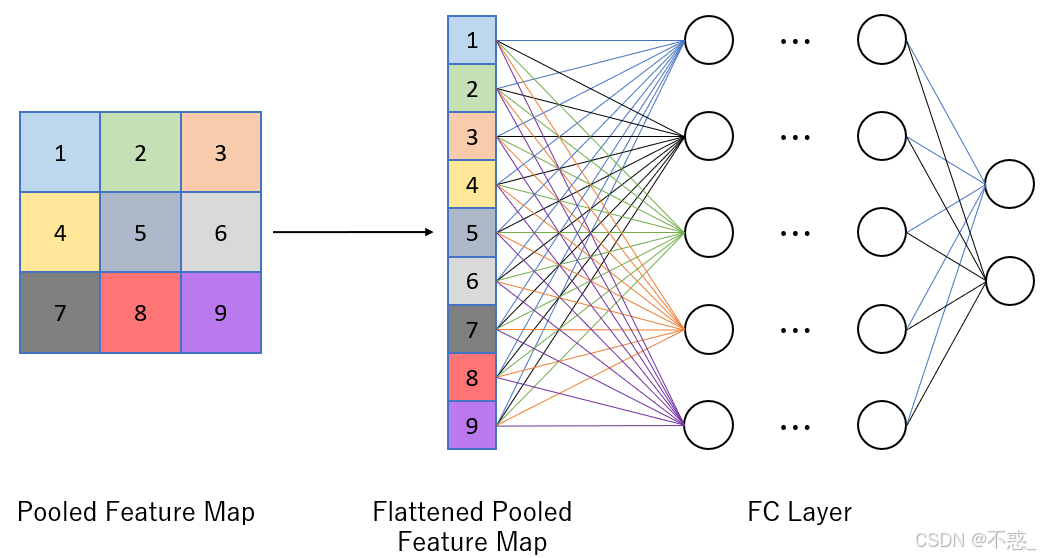
上图是一个全连接层示例:输入扁平化后,全连接到输出神经元。
CNN的工作原理:从输入到输出
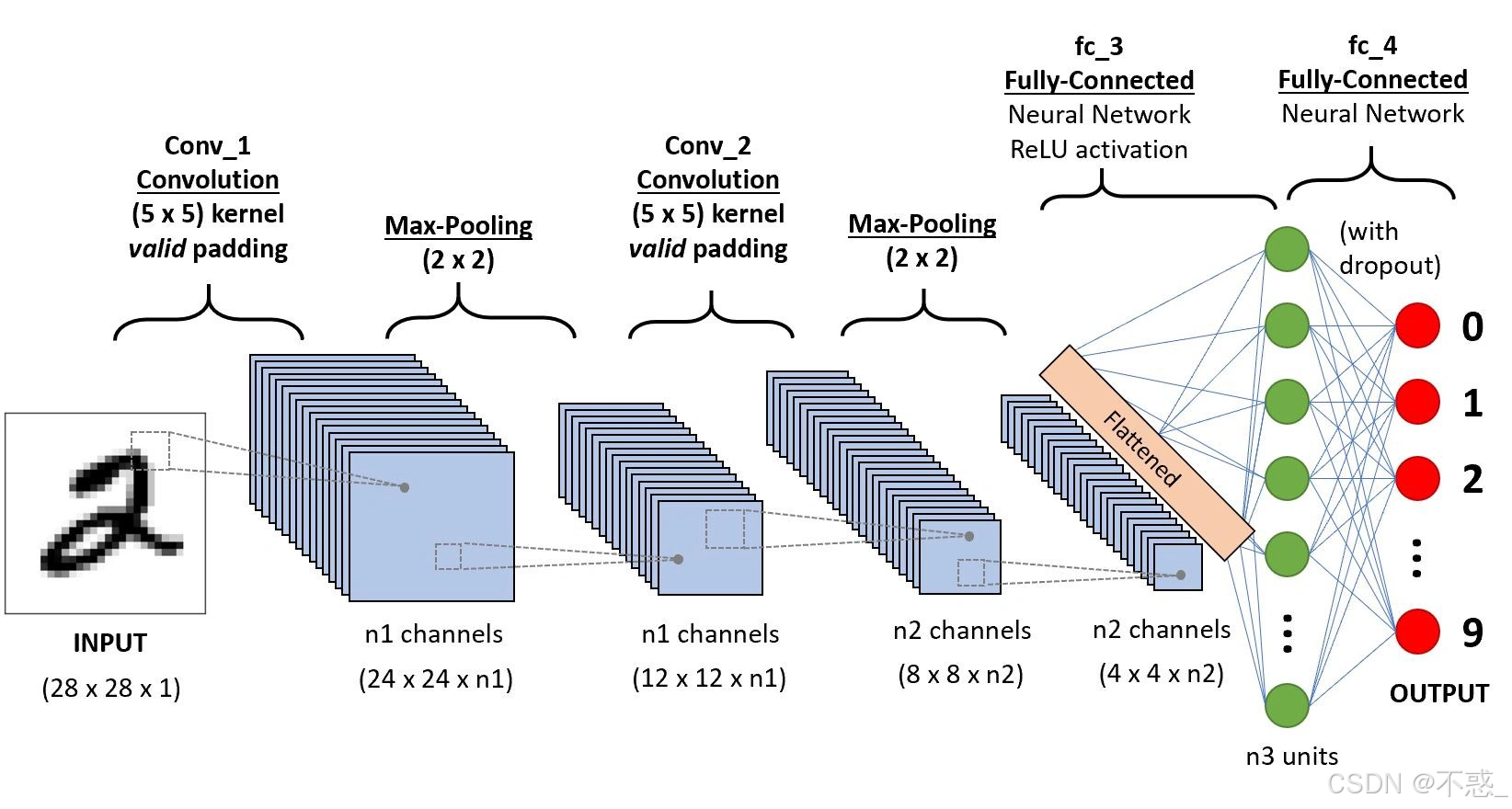
一个完整CNN流程:
- 输入:图像(如28x28手写数字)。
- 卷积层:多个滤波器提取特征,生成特征图。
- 激活:ReLU引入非线性。
- 池化:降维。
- 重复2-4,多层堆叠。
- 扁平化:变一维向量。
- 全连接:分类。
- 输出:概率。
训练:用大量标注数据,前向传播得预测,反向传播更新权重(梯度下降)。损失函数如交叉熵。
数据增强:翻转、旋转图像,增加多样性。
正则化:Dropout随机丢神经元,防过拟合;Batch Normalization归一化输入,加速训练。
经典CNN架构一:LeNet-5
LeNet-5是CNN鼻祖,1998年Yann LeCun设计,用于手写数字识别(MNIST数据集)。
架构:输入32x32灰度图。
- C1:6个5x5卷积,输出28x28x6。
- S2:2x2平均池化,14x14x6。
- C3:16个5x5卷积,10x10x16。
- S4:2x2池化,5x5x16。
- C5:120个5x5卷积,1x1x120。
- F6:全连接84。
- 输出:10类(0-9)。
总参数少,适合早期硬件。准确率99%+。
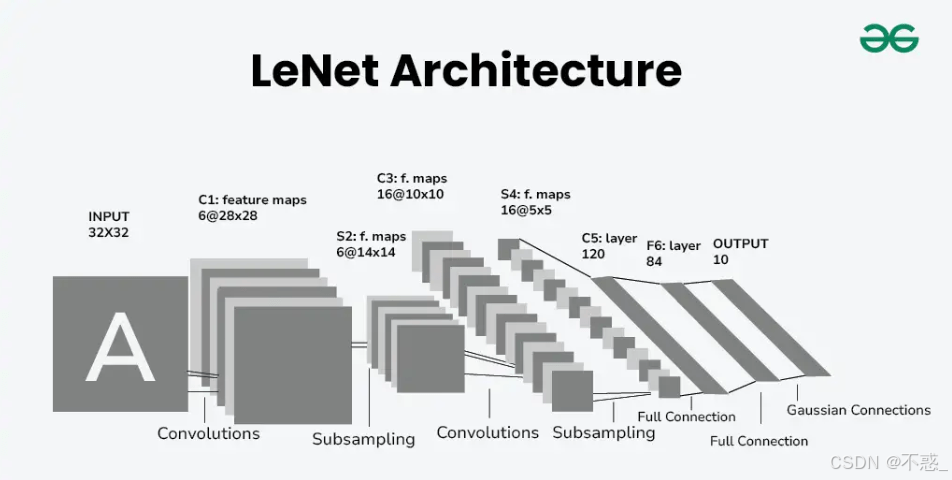
上图是LeNet-5架构图:简单却开创性。
经典CNN架构二:AlexNet
2012年Alex Krizhevsky的AlexNet赢得ImageNet,点燃深度学习热潮。
架构:输入224x224彩图。
- 5卷积层:第一层96个11x11滤波器,stride=4。
- Max池化。
- 3全连接层:4096、4096、1000(1000类)。
- ReLU、Dropout、数据增强。
创新:GPU并行、ReLU、Local Response Normalization。
参数6000万,准确率top-5 85%。
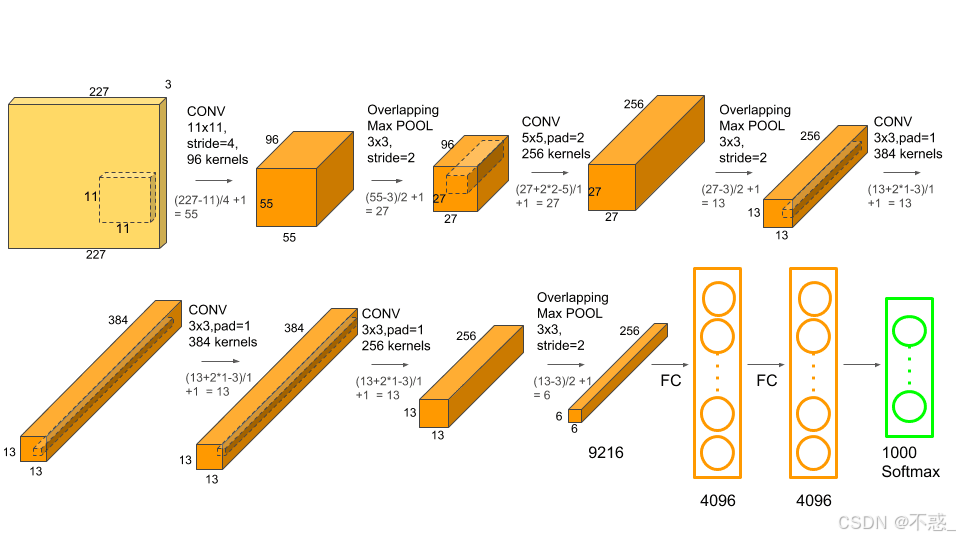
上图是AlexNet架构:更深更大。
其他经典:VGG(均匀层)、GoogLeNet(Inception模块,参数少)、ResNet(残差连接,超深层)。
CNN的应用
CNN不止图像分类。
- 物体检测:如YOLO、Faster R-CNN,实时框出物体。
- 图像分割:U-Net像素级分割,医疗肿瘤检测。
- 人脸识别:FaceNet嵌入式学习,解锁手机。
- 自动驾驶:检测行人、车道。
- 医疗:X光诊断肺炎。
- 自然语言:TextCNN处理句子。
- 视频分析:动作识别。
未来,结合Transformer的Vision Transformer挑战CNN。
上图展示CNN在图像识别的应用示例。
CNN的优势与局限性
优势:
- 自动特征提取。
- 参数高效。
- 泛化强。
- 并行计算友好。
局限:
- 需要大量数据和计算资源。
- 解释性差(黑箱)。
- 对旋转、缩放敏感(虽有增强)。
- 易受对抗样本攻击(小扰动误导)。
改进:迁移学习(预训练模型微调);注意力机制。
结论:CNN的未来
CNN从LeNet到现代变体,改变了世界。通俗理解,它像大脑视觉系统:层层提取特征,做出判断。掌握CNN,你能进入AI前沿。