在分布式缓存的设计中,Redis 的"高可用"一直是核心话题。而实现高可用的基石,就是 主从复制(Replication)。
很多同学在学习 Redis 时,往往只记住了"全量同步"和"增量同步"这两个名词,但对于它们内部的触发机制、缓冲区覆盖问题以及架构优化,理解得不够透彻。
今天这篇文章,我们就抛开晦涩的源码,用通俗的逻辑把 Redis 主从同步的原理讲清楚,并聊聊在生产环境中该如何避坑。
一、前置知识:同步的"接头暗号"
在两台 Redis 节点建立连接时,Slave(从节点)怎么知道自己和 Master(主节点)的数据是不是一致的?Master 又凭什么决定是把所有数据打包发过去,还是只发几条刚才错过的命令?
这依赖于两个核心概念:Replication ID 和 Offset。
1. Replication ID (replid):数据集的"身份证"
你可以把它理解为一个**"微信群 ID"**。
-
每个 Master 都有一个唯一的
replid。 -
Slave 连接 Master 后,会继承这个 ID。
-
判断逻辑 :如果 Slave 拿出来的
replid和 Master 不一样,说明你们根本不是"一个群"的,之前的聊天记录完全对不上。这时候,Master 会无情地判定:你是新来的,必须进行全量同步。
2. Offset:数据的"计数器"
这里我要纠正一个常见的认知误区: 很多资料把 offset 称为"偏移量",让人误以为它是指文件里的某一行。其实,更准确的理解,它是一个全局的"字节计数器"。
-
它不依赖于物理文件,而是记录了 Redis 这辈子一共处理了多少字节的写命令。
-
Master 写了 100 字节,计数器 +100。
-
Slave 同步了 100 字节,计数器也 +100。
-
判断逻辑:Master 只要对比两者的数字差,就知道 Slave 到底落后了多少进度。
二、 同步的两种姿势:全量与增量
理解了凭证,我们再看具体的同步流程。这其实就是数据在网络间"搬运"的过程。
1. 全量同步 (Full Sync):新员工入职
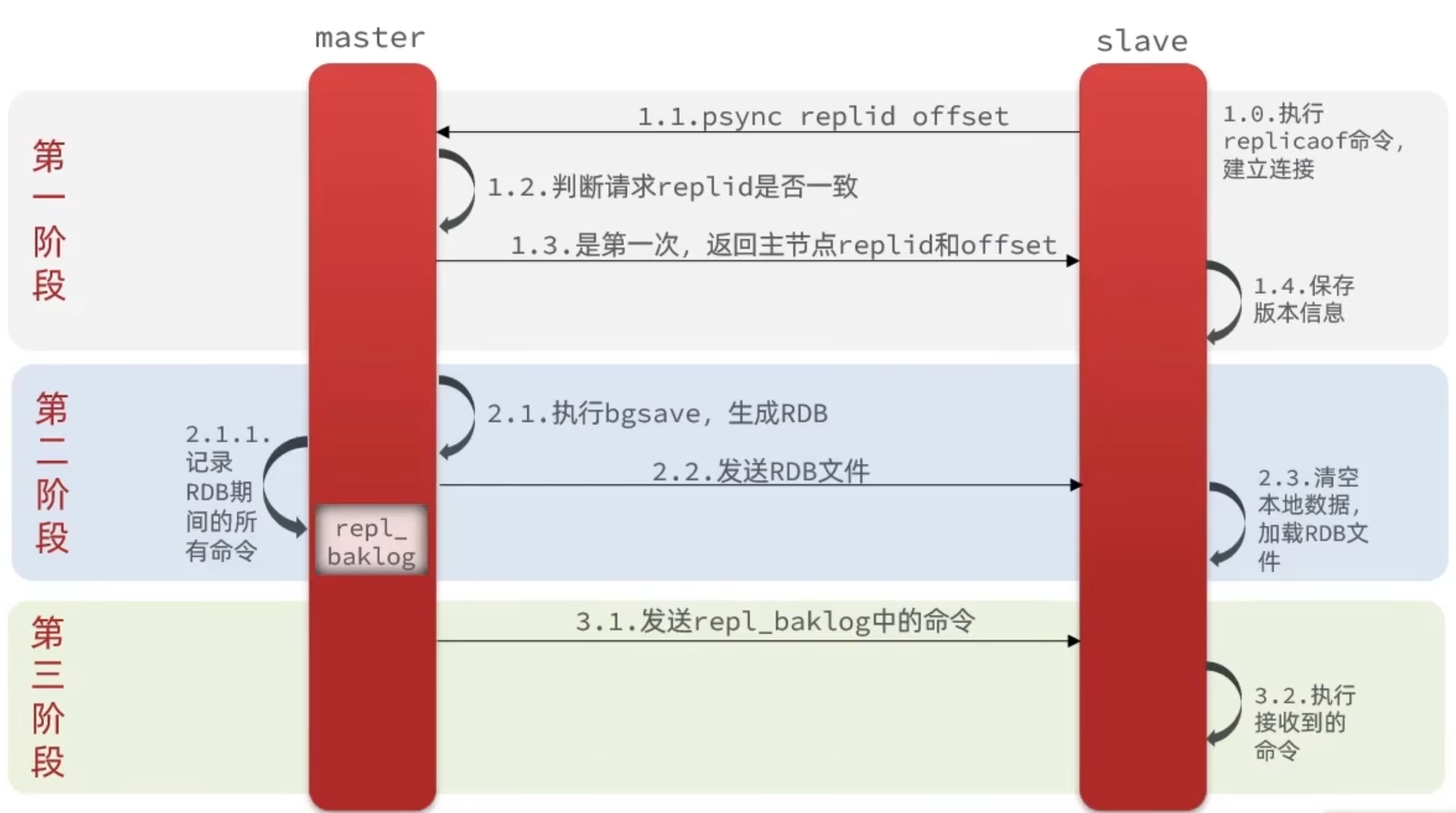
当 Slave 第一次连接 Master,或者 Slave 掉线太久导致数据完全对不上号(replid 变了)时,就会触发全量同步。
流程如下:
-
握手:Slave 发送请求,Master 发现是第一次来,决定执行全量同步。
-
快照生成 :Master 执行
bgsave,生成 RDB 文件。- 注意:此时 Master 的主进程依然在接收写请求,这些新数据会被暂存在内存缓冲区(repl_backlog)中。
-
搬运数据:Master 把 RDB 文件通过网络发送给 Slave。
-
加载数据:Slave 清空本地数据,加载 RDB。
-
追赶进度:Master 把刚才缓冲区里暂存的新命令发给 Slave。
思考:同步 vs 持久化,是一回事吗?
很多人看到这里涉及到了 RDB,就容易把"同步"和"持久化"搞混。其实它们虽然手段相似,但目的完全不同:
持久化 (Persistence) :是为了对抗时间。把数据存入磁盘(仓库),保证重启后数据还在。
同步 (Replication) :是为了对抗空间。把数据搬运到另一台机器,防止单点故障。
在全量同步中,Redis 只是借用了 RDB 这种"紧凑的打包格式"来进行网络传输。 实际上,在最新的 Redis 版本中,甚至可以配置"无盘复制",即 Master 生成 RDB 数据流后,不落磁盘,直接通过网卡发给 Slave。这再次印证了:RDB 在这里只是一个搬运箱,而不是仓库。
2. 增量同步 (Partial Sync):临时中断回来

如果 Slave 只是网络抖动断开了一小会儿,重连后 replid 是一致的,Master 就会尝试增量同步。
流程如下:
-
核对 :Slave 汇报自己的
offset(比如读到了 10000)。 -
续传:Master 检查自己的缓冲队列,发现自己写到了 10050。
-
同步 :Master 只需要把缓冲区里 10001 ~ 10050 这部分命令发给 Slave 即可。
三、 致命的"环形缓冲区" (repl_backlog)
增量同步虽然快,但有一个前提:你丢失的那部分数据,必须还在 Master 的缓冲区里。
Redis 的 repl_backlog 是一个环形数组(Ring Buffer),就像家里的循环录像带。
-
假设缓冲区大小是 1MB。
-
如果 Slave 断开期间,Master 写入了 2MB 的数据。
-
那么,最早的那 1MB 数据已经被新数据覆盖了。
后果: 当 Slave 回来要数据时,Master 发现数据找不到了,只能无奈地回复:"没办法,只能重新进行全量同步了。"
四、 生产环境优化实践
全量同步是非常消耗资源的(磁盘 IO、网络带宽、阻塞主线程),我们在生产环境中要尽量避免,或者降低其影响。以下是几个实用的优化思路:
1. 降低全量同步发生的概率(防患于未然)
既然"缓冲区被覆盖"是导致增量变全量的罪魁祸首,最直接的办法就是加大缓冲区。
-
配置 :
repl-backlog-size -
策略:根据你的业务流量估算。如果你允许 Slave 断连 1 分钟,而主库每秒写入 1MB,那么缓冲区至少要大于 60MB。建议设置得稍微大一些,比如 512MB 甚至 1GB,这就是给网络抖动买的"后悔药"。
2. 加快全量同步的速度(既然无法避免,那就提升速度)
-
Diskless Replication(无盘复制) : 如果你的服务器磁盘是机械硬盘,但网卡是万兆网卡,开启
repl-diskless-sync yes。这样 Master 就不写磁盘了,直接在内存中打包 RDB 并通过网络发送,减少磁盘 IO 压力。 -
控制单机内存大小: 不要让一个 Redis 实例内存过大(比如超过 20GB)。内存越大,生成 RDB 和传输的时间就越长,全量同步的代价就越惨重。
3. 给 Master 减负(主-从-从架构)
如果你的业务读请求非常大,挂了 10 个 Slave 节点。
-
问题:一旦发生全量同步,10 个 Slave 同时找 Master 要 RDB,Master 的网卡瞬间就被打满了,直接影响线上写请求。
-
优化 :采用 Master -> Slave -> Slave 的链式结构。 让一个性能好的 Slave 充当"分发者",其他的 Slave 找这个"分发者"同步数据。这样 Master 只需要服务这一个节点,压力瞬间释放。
五、 写在最后
总结一下,Redis 的数据同步机制其实就是一个精密的数据搬运系统。
-
全量同步是搬家,依赖 RDB 这个"打包箱";
-
增量同步是补作业,依赖 Offset 这个"计数器"和 Backlog 这个"缓冲区"。
-
而 Offset 的本质,就是连接主从两端数据一致性的逻辑标尺。
当然,主从复制虽然解决了数据备份和读写分离,但它依然无法解决**"容量上限"的问题。如果你的数据量大到单机存不下,那就需要引入分片(Sharding)**机制,也就是 Redis Cluster。