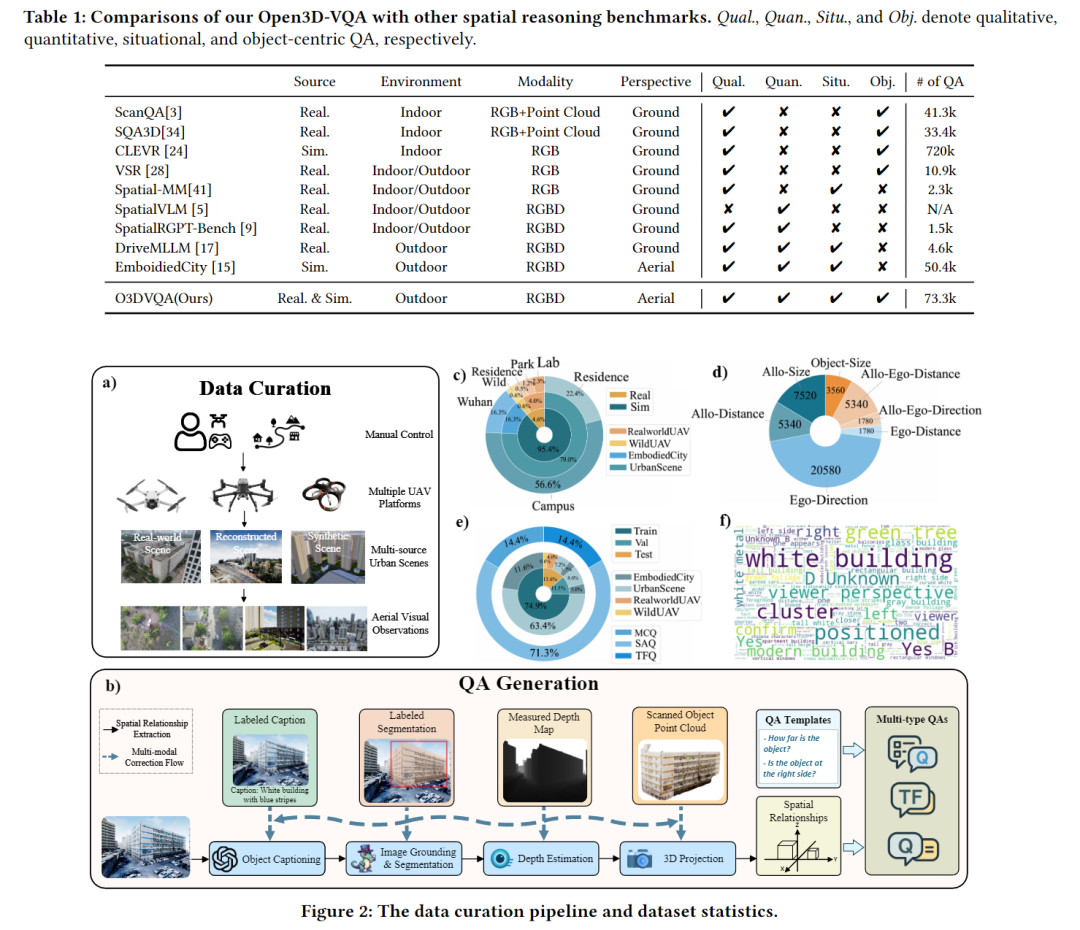
文章:Open3D-VQA: A Benchmark for Comprehensive Spatial Reasoning with Multimodal Large Language Model in Open Space
代码:https://github.com/EmbodiedCity/Open3D-VQA.code
单位:清华大学
。
一、问题背景:现有AI空间推理能力存在明显短板
随着AI在自动驾驶、机器人操作等领域的应用落地,对三维空间推理的需求日益迫切。但当前主流的评估基准存在三大局限:
-
场景受限:多聚焦室内或地面视角,缺乏城市级开放空间的考量;
-
任务单一:要么只关注物体间相对关系,要么忽略距离等精准测量需求;
-
数据不足:空中视角数据采集风险高、成本大,难以形成规模化评测。
这些问题导致AI在处理无人机航拍分析、城市三维建模等实际任务时,常常出现"看不懂距离""辨不清方向"的尴尬情况,严重制约了相关技术的落地应用。

二、方法创新:构建全方位空中空间推理评测体系
为解决上述痛点,团队打造了Open3D-VQA基准,核心创新体现在三方面:
-
多维任务设计:涵盖4种空间视角(如上帝视角、第一人称视角)和7类推理任务,包括物体大小对比、绝对距离测算、视角转换推理等,全面覆盖城市空间推理需求;
-
双源数据支撑:整合真实无人机航拍数据(来自深圳、罗马尼亚等地)和高保真模拟场景数据,共7.3万条问答对,既保证真实性又提升数据多样性;
-
智能生成 pipeline:通过GPT-4o生成物体描述,结合SegCLIP、SAM等工具提取三维空间关系,再经多模态校正流程减少误差,实现问答对自动生成与质量控制。
三、实验结果:揭示AI空间推理三大关键发现
团队对13款主流多模态大模型(包括GPT-4o、Gemini、LLaVA等)进行了全面评测,得出重要结论: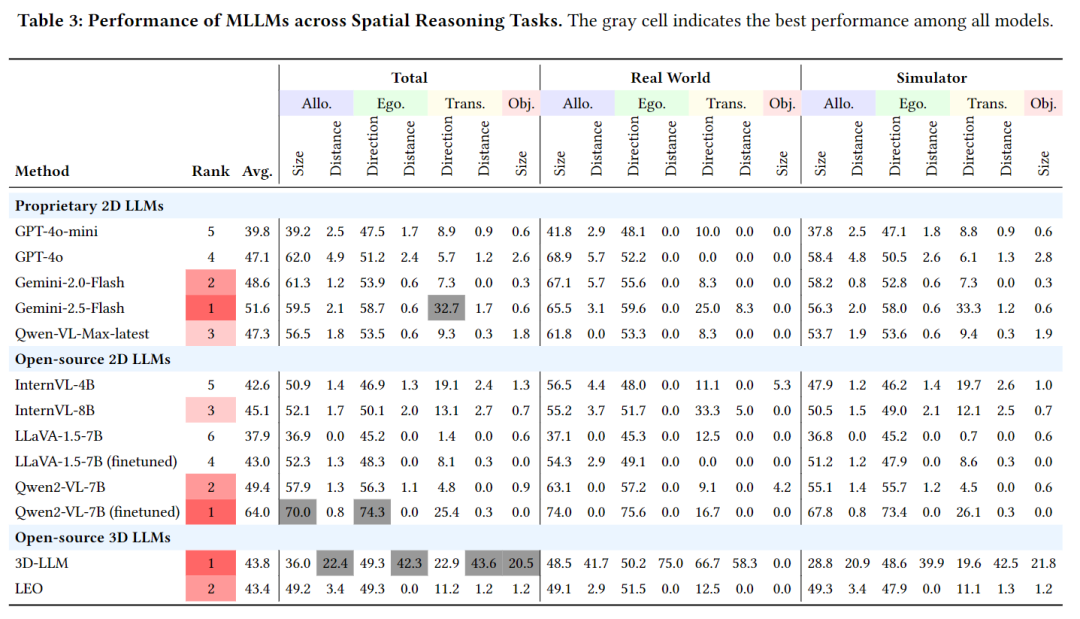
-
相对关系推理优于绝对测量:所有模型在判断"谁更高""谁在左边"等相对关系时表现较好,但在测算具体距离时准确率仅4.1%;
-
3D模型未显绝对优势:传统2D多模态模型经微调后,在多数任务上与3D模型性能相当,仅在距离推理上3D模型因点云数据略有优势;
-
模拟数据微调效果显著:仅用模拟场景数据微调后,LLaVA和Qwen2-VL在真实场景中的推理准确率分别提升6.5%和22.3%,验证了数据的泛化价值。
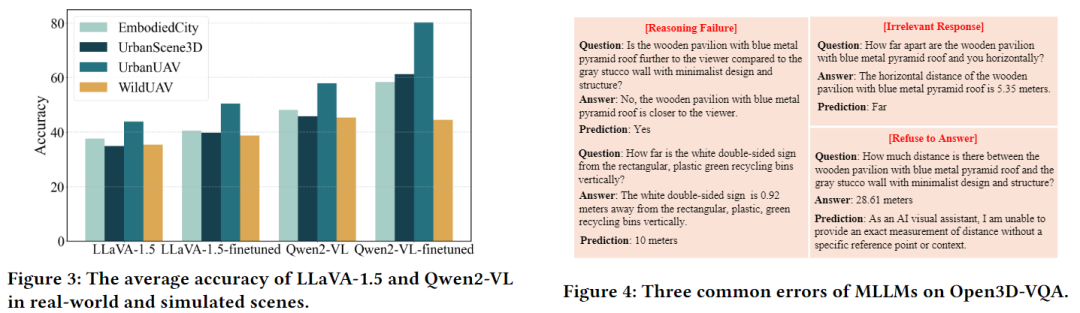
四、优势与局限:客观看待基准的价值与不足
核心优势
-
场景全面:首次聚焦空中视角的城市开放空间,填补了现有基准的空白;
-
数据优质:结合真实与模拟数据,兼顾规模(7.3万问答)与多样性(4类真实场景+3类模拟场景);
-
工具开放:开源完整的数据集、生成 pipeline 和评测工具,支持后续研究复用。
现存局限
-
模型转化推理能力薄弱:所有模型在"上帝视角转第一人称视角"类任务上准确率普遍低于10%,是当前技术的主要瓶颈;
-
距离测算精度不足:即使是最优模型,在绝对距离估算任务上的表现仍有较大提升空间;
-
依赖多模态辅助数据:纯2D模型在定量推理任务中表现不佳,需依赖深度图、点云等额外信息。
五、一句话总结
Open3D-VQA基准首次构建了空中视角下的三维空间推理评测体系,既揭示了当前AI在距离测算、视角转换等任务中的短板,也为无人机导航、城市智能分析等领域的技术优化提供了关键支撑。