TL;DR
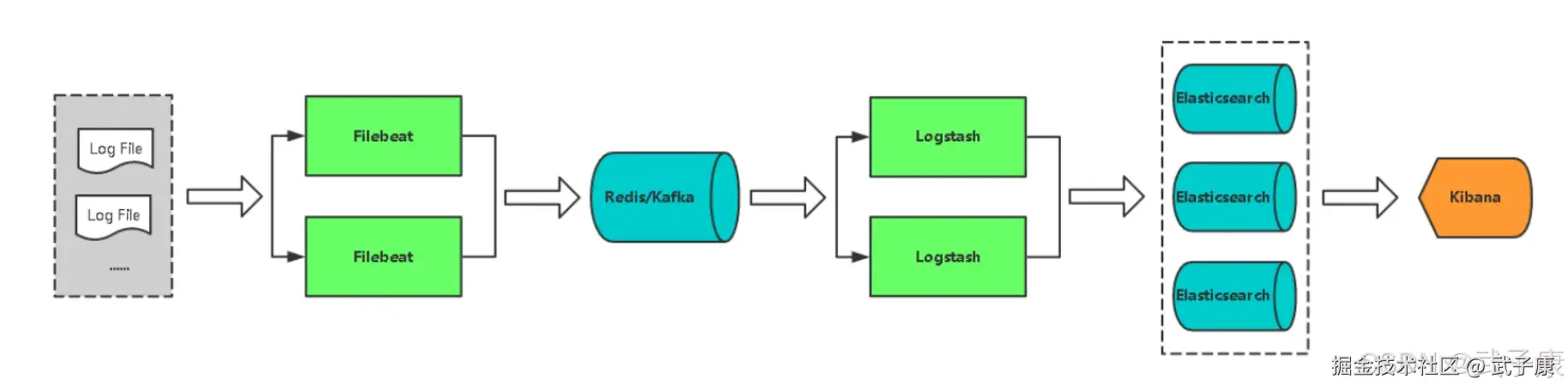
- 场景:用 Nginx 产生日志,走 Zookeeper+Kafka 汇聚,写入 Elasticsearch,Kibana 可视化
- 结论:先把 Nginx access_log 规范为 JSON,后续采集解析成本最低、吞吐最稳
- 产出:可复现的最小链路(Nginx→Kafka→ES→Kibana)与常见故障速查表
版本矩阵
| 组件 | 版本 | 已验证 | 说明 |
|---|---|---|---|
| Nginx | apt 安装版(随发行版变化) | 部分 | 关键在 log_format json 与 access_log ... json; 生效;版本不影响该用法主路径 |
| Zookeeper | 未注明 | 部分 | 需三节点分别 zkServer.sh start;注意服务用户、JAVA_HOME、数据目录一致性 |
| Kafka | 2.12-2.7.2 | 是 | 以 kafka-server-start.sh -daemon .../server.properties 启动;依赖可用的 ZK/或配置到位 |
| Elasticsearch | 7.3.0 | 是 | .../elasticsearch -d;注意 vm.max_map_count、权限、bootstrap check |
| Kibana | 7.3.0 | 是 | 必须与 ES 主版本一致;bin/kibana 前台运行,建议配进程守护 |
| 日志格式 | Nginx JSON(自定义字段) | 是 | 以 JSON 直出降低后续解析成本;字段命名建议稳定(见速查卡) |
整体架构
Nginx
Nginx 是一个高性能的 HTTP 和反向代理服务器,同时也能作为 IMAP/POP3 邮件代理服务器使用。它最初由 Igor Sysoev 于 2004 年开发,目的是解决高并发情况下的 C10K 问题,即同时处理 1 万个客户端连接的问题。Nginx 采用了事件驱动架构,能够使用较少的资源处理大量并发请求,因此在静态资源服务、反向代理、负载均衡等场景中表现得尤为出色。
Nginx 的主要功能包括:
- 静态资源服务:Nginx 可以非常高效地处理静态文件的请求,如 HTML、CSS、JavaScript、图片等,适合作为前端服务器。
- 反向代理:Nginx 可以作为反向代理,将客户端请求转发到后端服务器处理,再将响应返回给客户端。它支持 HTTP 和 HTTPS 协议,能够帮助隐藏后端服务器,增强安全性。
- 负载均衡:Nginx 支持多种负载均衡算法,如轮询、加权轮询、IP 哈希等。它可以将流量分发到多个后端服务器,提高系统的可靠性和可扩展性。
- 缓存:Nginx 可以缓存后端服务器的响应,减少对后端服务器的请求压力,提升性能。
- 高并发支持:由于采用异步非阻塞的事件驱动模型,Nginx 可以处理非常高的并发连接,适合大规模网站的流量处理需求。
- 模块化设计:Nginx 支持多种模块,如 gzip 压缩、SSL/TLS 加密、访问控制、连接限制等,方便定制和扩展。
配置Nginx
我这里直接用工具安装了,你也可以采用源码编译的方式等。
shell
apt install nginx安装完毕后,我们要修改一下Nginx的配置内容:
shell
# 可能不一样
vim /etc/nginx/nginx.conf原来的内容如下图所示,我们要修改内容: 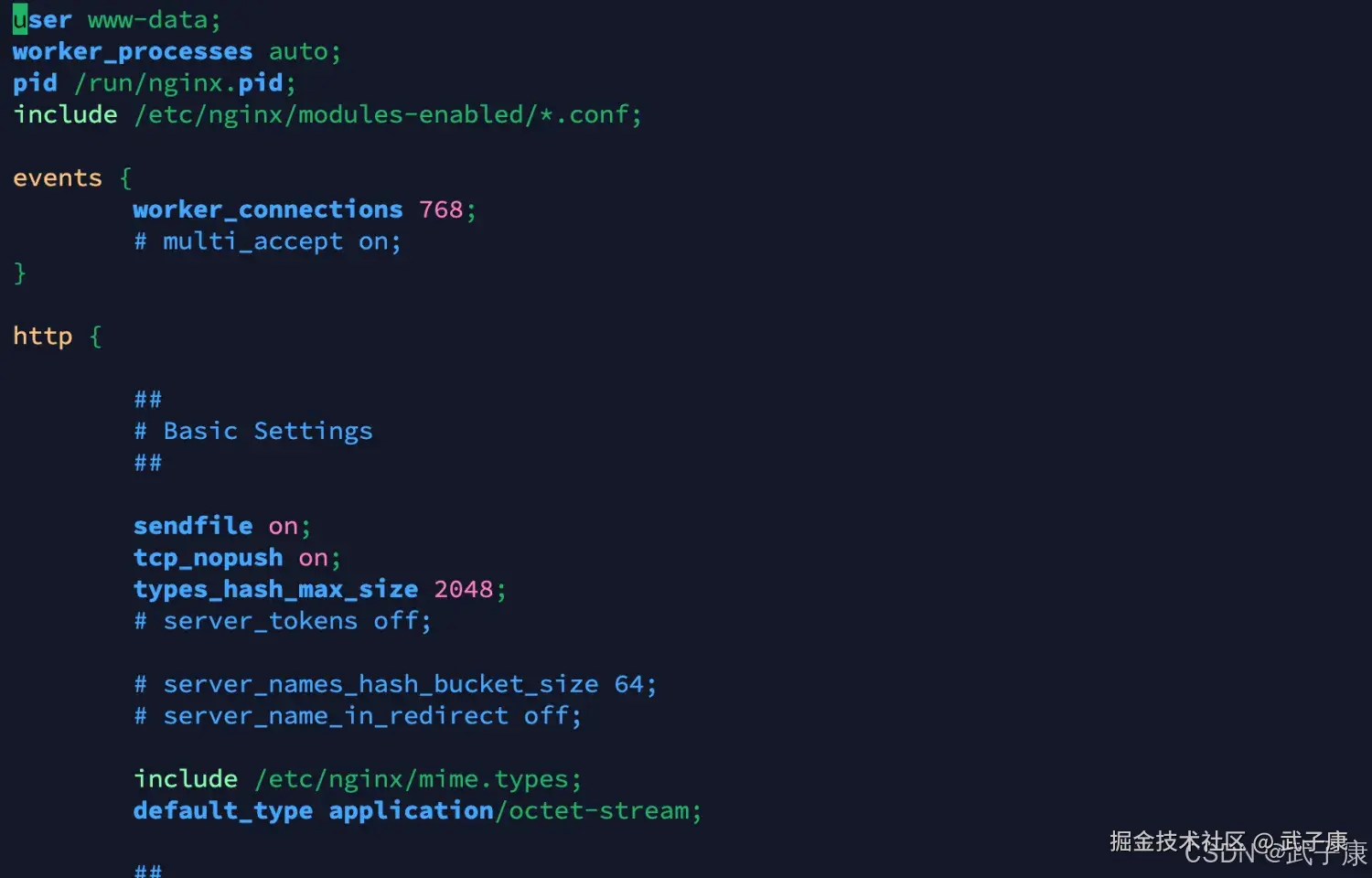 修改日志的格式(方便后续的Logstash进行解析,虽然Logstash可以通过正则的方式来实现字段的提取,但是效率并不高)。
修改日志的格式(方便后续的Logstash进行解析,虽然Logstash可以通过正则的方式来实现字段的提取,但是效率并不高)。
shell
log_format json '{ "@timestamp": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"request_uri": "$request_uri", '
'"request_method": "$request_method", '
'"http_referrer": "$http_referer", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent"}';
access_log logs/access.log json;修改的对应的截图如下所示: 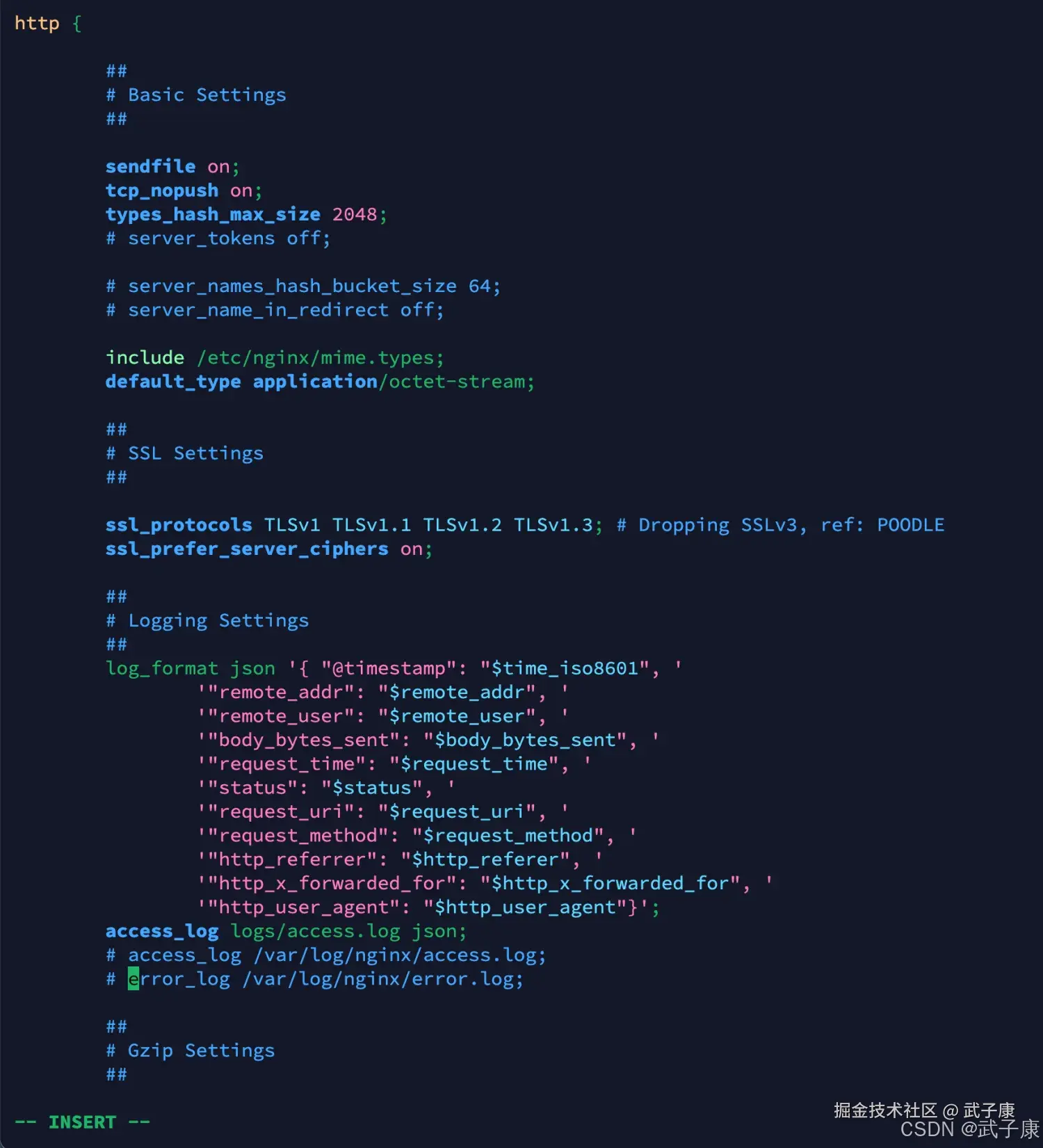 同时我们监听一个别的端口,必须8888
同时我们监听一个别的端口,必须8888
shell
server {
listen 8888;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
}这部分的截图为: 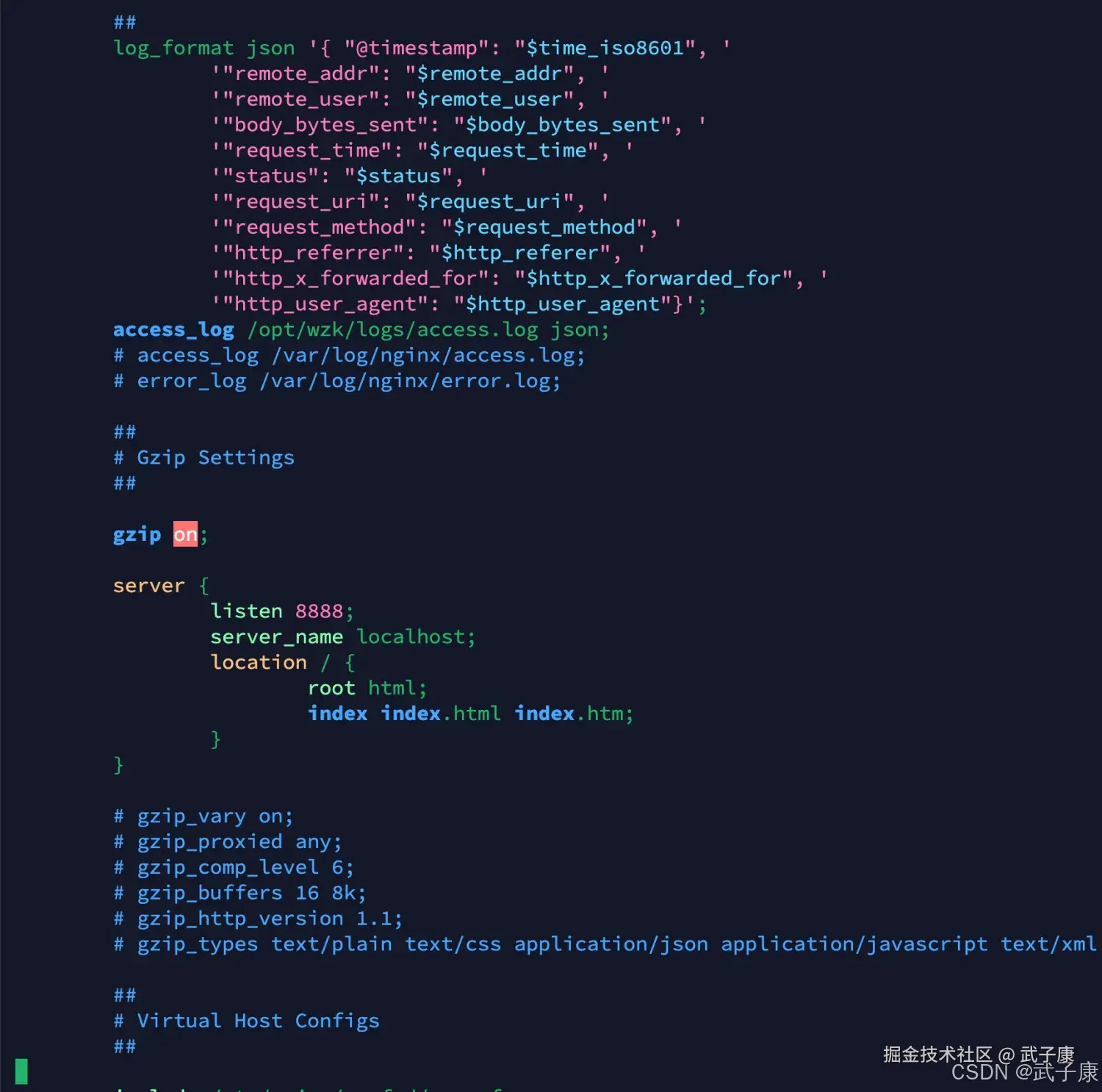
重启Nginx
shell
nginx -s reload访问页面
shell
http://h121.wzk.icu:8888/我们多访问几次,可以看到后台的日志的内容:
shell
root@h121:/opt/wzk/logs# tail -f access.log
{ "@timestamp": "2024-08-19T14:24:39+08:00", "remote_addr": "223.80.101.21", "remote_user": "-", "body_bytes_sent": "0", "request_time": "0.000", "status": "304", "request_uri": "/", "request_method": "GET", "http_referrer": "-", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}
{ "@timestamp": "2024-08-19T14:24:39+08:00", "remote_addr": "223.80.101.21", "remote_user": "-", "body_bytes_sent": "0", "request_time": "0.000", "status": "304", "request_uri": "/", "request_method": "GET", "http_referrer": "-", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}
{ "@timestamp": "2024-08-19T14:24:43+08:00", "remote_addr": "223.80.101.21", "remote_user": "-", "body_bytes_sent": "396", "request_time": "0.000", "status": "200", "request_uri": "/", "request_method": "GET", "http_referrer": "-", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}
{ "@timestamp": "2024-08-19T14:24:43+08:00", "remote_addr": "223.80.101.21", "remote_user": "-", "body_bytes_sent": "197", "request_time": "0.000", "status": "404", "request_uri": "/favicon.ico", "request_method": "GET", "http_referrer": "http://h121.wzk.icu:8888/", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}
{ "@timestamp": "2024-08-19T14:24:44+08:00", "remote_addr": "223.80.101.21", "remote_user": "-", "body_bytes_sent": "0", "request_time": "0.000", "status": "304", "request_uri": "/", "request_method": "GET", "http_referrer": "-", "http_x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"}对应的截图如下所示: 
Zookeeper
Zookeeper 是一个分布式协调服务,用于分布式应用程序中的配置管理、命名服务、分布式同步和集群管理等功能。它提供了一种简单但可靠的机制,能够协调多个服务器之间的状态,使得分布式系统可以像单个系统一样进行管理。Zookeeper 的核心理念是通过一个树状的目录结构来存储配置信息,类似于文件系统,每个节点称为 znode。
Zookeeper 的主要功能包括:
- 命名服务:Zookeeper 能够存储和提供分布式系统中的资源名称信息,例如分布式集群中的服务器名称和地址。
- 配置管理:Zookeeper 可以实时跟踪和分发配置数据,确保分布式系统中的各个节点拥有一致的配置状态。
- 分布式同步:Zookeeper 提供了一种原语,帮助分布式系统中的节点在操作时保持同步,避免数据冲突和竞争条件。
- 集群管理:Zookeeper 能够监控集群中节点的存活状态,提供节点的动态加入、移除以及失败恢复的功能。
我们需要去启动 ZooKeeper 的集群服务,需要在:
- h121
- h122
- h123 上述节点分别启动 ZK 服务:
shell
zkServer.sh startKafka
Kafka 是由 LinkedIn 开发的一个分布式流处理平台,现由 Apache 基金会维护。Kafka 最初是为了处理 LinkedIn 内部的大规模数据流而设计的,现在已成为各类企业用于处理实时数据流的重要工具。
Kafka 的优势包括:
- 高吞吐量:Kafka 能够处理大量的数据流,支持低延迟的实时消息处理。
- 持久化存储:消息存储在磁盘上,可以设置保留策略来控制消息的生命周期。
- 可扩展性:Kafka 通过增加分区和 Broker 来水平扩展,无需中断服务。
- 容错性:通过副本机制,Kafka 可以在部分 Broker 失效的情况下仍然继续运行。
我们需要去启动Kafka的集群服务,需要在:
- h121
- h122
- h123 上述节点分别启动 Kafka 服务:
shell
kafka-server-start.sh -daemon /opt/servers/kafka_2.12-2.7.2/config/server.propertiesElasticsearch
Elasticsearch 是一个分布式、RESTful 搜索和分析引擎,基于 Apache Lucene 开发。它能够快速存储、搜索和分析大量数据,广泛应用于日志处理、全文搜索、数据分析等场景。
Elasticsearch 通常和其他工具如 Logstash 和 Kibana 一起使用,组成 ELK(Elasticsearch、Logstash、Kibana)堆栈,来实现从日志采集、处理到可视化展示的一体化解决方案。
我们需要去启动Elasticsearch的集群服务,需要在:
- h121
- h122
- h123 上述节点分别启动 Elasticsearch 服务:
shell
su es_server
/opt/servers/elasticsearch-7.3.0/bin/elasticsearch -dKibana
Kibana 是一个开源的数据可视化和探索工具,专门为 Elasticsearch 设计,用来帮助用户对存储在 Elasticsearch 中的数据进行实时分析、可视化和管理。它提供了一个图形用户界面,用户可以轻松地创建不同类型的图表、仪表盘、以及数据监控工具,快速获取关键信息。
核心功能和特点:
- 数据可视化:Kibana 支持创建多种图表,包括条形图、折线图、饼图、地理图等。用户可以通过拖拽界面元素,将复杂的数据转换为可读性强的可视化图表。
- 仪表盘:Kibana 允许用户将多个图表、地图、搜索结果组合成一个统一的仪表盘,以便实时监控系统运行状态或者追踪特定指标。仪表盘可以进行动态更新,显示最新的数据。
- 数据探索:用户可以使用 Kibana 的 Discover 功能,快速搜索、过滤和浏览 Elasticsearch 中的文档。通过 Kibana 提供的查询语言(例如 Lucene 查询语法或 Elasticsearch Query DSL),用户可以灵活地筛选所需的数据。
- 时间序列分析:Kibana 提供了强大的时间序列数据分析工具(如 Timelion 和 TSVB),可以帮助用户分析和展示按时间顺序排列的数据,适用于日志分析和监控系统性能。
- 安全与用户管理:在集成了 Elasticsearch 的 X-Pack 安全模块后,Kibana 可以实现细粒度的权限控制和用户管理。用户可以对不同的团队或用户分配不同的访问权限,确保数据安全。
- 报警与通知:Kibana 的 Alerting 功能允许用户设置告警规则,当监控的数据达到特定阈值时,自动触发通知(例如通过电子邮件或 webhook 发送告警信息)。
- 交互式地图:Kibana 提供了地理空间可视化功能,用户可以将地理数据绘制在交互式地图上,适合进行地理信息系统(GIS)相关的分析和展示。
我们需要启动Kibana服务,这里我是启动了 h122 节点。
shell
su es_server
cd /opt/servers/kibana-7.3.0-linux-x86_64
bin/kibana错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| nginx -s reload 报错或不生效 | 配置语法错误/文件路径不对 | nginx -t 看具体行号;先 nginx -t 通过再 reload;确认编辑的是实际生效的 nginx.conf/包含文件 |
| access.log 不是 JSON 或字段缺失 | log_format 未被引用/access_log 仍指向默认格式 | 查 access_log 指向与格式名;看生成内容;access_log json; 与 log_format json '...' 名称一致;避免引号/逗号拼接错误 |
| access_log logs/access.log 找不到或无写入 | 相对路径不在预期目录/权限不足 | nginx -V 看 prefix;检查目录权限;改为绝对路径(如 /var/log/nginx/access_json.log);确保目录可写 |
| 8888 端口访问失败 | server 块未被 include/被防火墙拦/监听冲突 | `ss -lntp |
| 日志里大量 304/0 bytes | 浏览器缓存命中 | 对比 status=304、body_bytes_sent=0属正常;压测或 curl 时加禁缓存参数以验证写入 |
| /favicon.ico 404 | 静态站点未提供图标 | 日志 request_uri=/favicon.ico属正常;需要可补 favicon 文件或单独 location 处理 |
| zkServer.sh start 失败 | JAVA_HOME/权限/数据目录问题 | 查 zookeeper.out/日志;设置 JAVA_HOME;确保 dataDir 可写;统一 myid 与配置 |
| Kafka 启动失败或反复重启 | ZK 未就绪/zookeeper.connect 错/端口不通 | Kafka 日志、telnet ZK 端口;先确保 ZK 集群健康;核对 connect 字符串与网络连通 |
| ES 启动报 bootstrap checks | 内核参数/内存锁/文件句柄不足 | ES 日志提示项常见:设置 vm.max_map_count、提升 ulimit、配置 heap 与权限 |
| Kibana 连接不上 ES | 版本不匹配/elasticsearch.hosts 配置错/ES 未起来 | Kibana 控制台日志、访问 ES 端口;保证 Kibana 7.3.0 对 ES 7.3.0;修正 hosts;先验证 curl ES |
| 后续解析成本高、字段漂移 | JSON 字段命名随意/类型不稳定(数字变字符串) | 对比多条日志同字段类型;固定字段集合与命名;数值字段尽量保持数值语义(如 request_time/body_bytes_sent) |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解