目录
[4.1 MaskDecoder.predict_masks](#4.1 MaskDecoder.predict_masks)
[4.1.3 hs, src = self.transformer(src, pos_src, tokens)之后](#4.1.3 hs, src = self.transformer(src, pos_src, tokens)之后)
[4.1.3.1 转置卷积](#4.1.3.1 转置卷积)
[4.1.3.2 回到我们原来的问题](#4.1.3.2 回到我们原来的问题)
[4.1.3.3 怎么感觉跟ASPP空洞卷积有点像呢,](#4.1.3.3 怎么感觉跟ASPP空洞卷积有点像呢,)
[4.2 MaskDecoder的初始化](#4.2 MaskDecoder的初始化)
一、前言
这篇有点陷入转置矩阵出不来了,看晕了已经。就很难理解它是怎么实现的,输出尺寸公式为啥是那样。标记一下,以后看一下ConvTranspose2d实现的代码。有些东西暂时理解不了的,我觉得可以先放一放,以后知识储备上来了说不定就明白了,尤其是以后要看一下一些基础模块的代码实现的部分。
四、MaskDecoder
4.1 MaskDecoder.predict_masks
sam2/modeling/sam/mask_decoder.py
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
repeat_image: bool,
high_res_features: Optional[List[torch.Tensor]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# 输入:
# image_embeddings: torch.Size([1, 256, 64, 64])
# image_pe:torch.Size([1, 256, 64, 64])
# sparse_embeddings: torch.Size([1, 3, 256])
# dense_embeddings : torch.Size([1, 256, 64, 64])
# multimask_output:False
# repeat_image: False
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
# Concatenate output tokens
s = 0
# self.pred_obj_scores: True
if self.pred_obj_scores:
# self.obj_score_token.weight: torch.Size([1, 256])
# self.iou_token.weight: torch.Size([1, 256])
# self.mask_tokens.weight: torch.Size([4, 256])
output_tokens = torch.cat(
[
self.obj_score_token.weight, # >>> 0 号 token:objectness 打分
self.iou_token.weight, # >>> 1 号 token:iou 打分
self.mask_tokens.weight, # >>> 2~5 号 token:4 个 mask 原型
],
dim=0,
)
# output_tokens: torch.Size([6, 256])
s = 1 # >>> 后面拿 hs 时跳过 0 号 token
else:
output_tokens = torch.cat(
[self.iou_token.weight, self.mask_tokens.weight], dim=0
)
# sparse_embeddings: torch.Size([1, 3, 256])
output_tokens = output_tokens.unsqueeze(0).expand(
sparse_prompt_embeddings.size(0), -1, -1
)
# output_tokens: torch.Size([1, 6, 256])
# >>> 把"可学习 token"和"用户稀疏提示(点/框)"拼在一起
# sparse_prompt_embeddings: torch.Size([1, 3, 256])
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# tokens: torch.Size([1, 9, 256])
# >>> 如果 batch 里每张图要重复多次(跟踪里常见),就 repeat;否则直接拿
# repeat_image:False
if repeat_image:
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
else:
assert image_embeddings.shape[0] == tokens.shape[0]
src = image_embeddings
# src: torch.Size([1, 256, 64, 64])
# >>> 把"用户 dense 提示(低分辨率 mask)"也加到图像特征上
# dense_prompt_embeddings: torch.Size([1, 256, 64, 64])
src = src + dense_prompt_embeddings
# src: torch.Size([1, 256, 64, 64])
assert (
image_pe.size(0) == 1
), "image_pe should have size 1 in batch dim (from `get_dense_pe()`)"
# image_pe: torch.Size([1, 256, 64, 64])
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
# pos_src: torch.Size([1, 256, 64, 64])
b, c, h, w = src.shape
# b:1 c:256 h:64 w:64
# >>> 2-way transformer:token ↔ 图像特征 交叉注意力
# src: torch.Size([1, 256, 64, 64])
# pos_src: torch.Size([1, 256, 64, 64])
# tokens: torch.Size([1, 9, 256])
hs, src = self.transformer(src, pos_src, tokens)
# hs: torch.Size([1, 9, 256]) -> 精炼后的 token
# src: torch.Size([1, 4096, 256]) -> 精炼后的图像特征(flatten)
# >>> 拿 1 号 token 去做 IoU 回归
iou_token_out = hs[:, s, :]
# iou_token_out: torch.Size([1, 256])
# >>> 拿 2~5 号 token 去做 4 个 mask 原型
# s: 1 self.num_mask_tokens: 4
# mask_tokens_out=[:,2:6,:] 取第2,3,4,5索引对应的
mask_tokens_out = hs[:, s + 1 : (s + 1 + self.num_mask_tokens), :]
# mask_tokens_out: torch.Size([1, 4, 256])
# >>> 把 4096 个 token 再 reshape 回 64×64 空间特征图
# src:torch.Size([1, 4096, 256]) b:1 c:256 h:64 w:64
src = src.transpose(1, 2).view(b, c, h, w)
# src: torch.Size([1, 256, 64, 64])
# >>> 上采样到 256×256,同时融合高分辨率 skip 特征
# self.use_high_res_features:True
if not self.use_high_res_features:
upscaled_embedding = self.output_upscaling(src)
else:
dc1, ln1, act1, dc2, act2 = self.output_upscaling
# dc1: ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))
# ln1: LayerNorm2d()
# act1: GELU(approximate='none')
# dc2: ConvTranspose2d(64, 32, kernel_size=(2, 2), stride=(2, 2))
# act2: GELU(approximate='none')
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
feat_s0, feat_s1 = high_res_features
# feat_s0: torch.Size([1, 32, 256, 256])
# feat_s1: torch.Size([1, 64, 128, 128])
# >>> 第一层上采样 64→128,同时加 128 分辨率 skip
upscaled_embedding = act1(ln1(dc1(src) + feat_s1))
# upscaled_embedding: torch.Size([1, 64, 128, 128])
# >>> 第二层上采样 128→256,同时加 256 分辨率 skip
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)
# upscaled_embedding: torch.Size([1, 32, 256, 256])
# >>> 4 个 mask token 各自过一个小 MLP 得到 32 维"超向量"
hyper_in_list: List[torch.Tensor] = []
# self.num_mask_tokens: 4
for i in range(self.num_mask_tokens):
# 进入MLP.forward
# mask_tokens_out: torch.Size([1, 4, 256])
hyper_in_list.append(
self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])
)
# i=0 加入 torch.Size([1, 32])
# i=1 加入 torch.Size([1, 32])
# i=2 加入 torch.Size([1, 32])
# i=3 加入 torch.Size([1, 32])
hyper_in = torch.stack(hyper_in_list, dim=1)
# hyper_in: torch.Size([1, 4, 32])
# >>> 用"超向量"与上采样特征做 1×1 卷积等价运算:矩阵乘 + reshape
# upscaled_embedding: torch.Size([1, 32, 256, 256])
b, c, h, w = upscaled_embedding.shape
# b:1 c:32 h:256 w:256
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# masks: torch.Size([1, 4, 256, 256])
# >>> IoU 头:拿 1 号 token 回归 4 个 mask 的质量分数
iou_pred = self.iou_prediction_head(iou_token_out)
# iou_pred: torch.Size([1, 4])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# >>> objectness 头:拿 0 号 token 判断"图中到底有没有物体"
if self.pred_obj_scores:
assert s == 1
# 进入MLP.forward
# hs: torch.Size([1, 9, 256])
object_score_logits = self.pred_obj_score_head(hs[:, 0, :])
# object_score_logits: tensor([[20.2533]], device='cuda:0')
else:
# Obj scores logits - default to 10.0, i.e. assuming the object is present, sigmoid(10)=1
object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape[0], 1)
# mask: torch.Size([1, 4, 256, 256])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# mask_tokens_out: torch.Size([1, 4, 256])
# object_score_logits: torch.Size([1, 1]) 即 tensor([[20.2533]], device='cuda:0')
return masks, iou_pred, mask_tokens_out, object_score_logits代码整体流程一句话总结
把"可学习的 object/iou/mask token"和用户稀疏提示拼成 9 个 token。
与图像特征一起过 2-way transformer,得到精炼后的 token 和图像特征。
用 transformer 输出的 mask-token 过 MLP 得到 4 个 32 维"超向量",再与上采样到 256×256 的特征图做矩阵乘,一次性生成 4 张 mask。
同时用 iou-token 回归 4 个 mask 的质量分数,用 obj-token 给出"图中是否有物体"的 logits。
把 4 张 mask、4 个 IoU、4 个 token、1 个 objectness 分数一起返回,供上层 forward 再做筛选。
4.1.3 hs, src = self.transformer(src, pos_src, tokens)之后
>>> 2-way transformer:token ↔ 图像特征 交叉注意力
src: torch.Size(1, 256, 64, 64)
pos_src: torch.Size(1, 256, 64, 64)
tokens: torch.Size(1, 9, 256)
hs, src = self.transformer(src, pos_src, tokens)
hs: torch.Size(1, 9, 256) -> 精炼后的 token
src: torch.Size(1, 4096, 256) -> 精炼后的图像特征(flatten)
>>> 把 4096 个 token 再 reshape 回 64×64 空间特征图
src:torch.Size(1, 4096, 256) b:1 c:256 h:64 w:64
src = src.transpose(1, 2).view(b, c, h, w)
src: torch.Size(1, 256, 64, 64)
>>> 上采样到 256×256,同时融合高分辨率 skip 特征
self.use_high_res_features:True
if not self.use_high_res_features:
upscaled_embedding = self.output_upscaling(src)
else:
dc1, ln1, act1, dc2, act2 = self.output_upscaling
dc1: ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))
ln1: LayerNorm2d()
act1: GELU(approximate='none')
dc2: ConvTranspose2d(64, 32, kernel_size=(2, 2), stride=(2, 2))
act2: GELU(approximate='none')
high_res_features:[
torch.Size(1, 32, 256, 256),
torch.Size(1, 64, 128, 128)
]
feat_s0, feat_s1 = high_res_features
feat_s0: torch.Size(1, 32, 256, 256)
feat_s1: torch.Size(1, 64, 128, 128)
>>> 第一层上采样 64→128,同时加 128 分辨率 skip
upscaled_embedding = act1(ln1(dc1(src) + feat_s1))
upscaled_embedding: torch.Size(1, 64, 128, 128)
>>> 第二层上采样 128→256,同时加 256 分辨率 skip
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)
upscaled_embedding: torch.Size(1, 32, 256, 256)
什么意思
我们先看一下MaskDecoder初始化的时候self.output_upscaling的部分
定义输出上采样模块:将transformer输出的低分辨率特征图(如64x64)上采样到更高分辨率(如256x256)
结构:反卷积层 → 层归一化 → 激活函数 → 反卷积层 → 激活函数
self.output_upscaling = nn.Sequential(
第一次上采样:dim → dim/4,空间尺寸x2(如64x64 → 128x128)
nn.ConvTranspose2d(
256, 64
transformer_dim, transformer_dim // 4, kernel_size=2, stride=2
),
LayerNorm2d(transformer_dim // 4), # 2D层归一化
activation(), # 激活函数(默认GELU)
第二次上采样:dim/4 → dim/8,空间尺寸x2(如128x128 → 256x256)
nn.ConvTranspose2d(
64, 32
transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2
),
activation(), # 激活函数
)
然后我们回到上面问题
这段代码是 SAM模型MaskDecoder的上采样和特征融合部分,作用是将Transformer输出的低分辨率特征图逐步上采样到256×256的掩码预测分辨率,并融合高分辨率skip特征以增强细节。
分步解释:
1. Reshape操作
src = src.transpose(1, 2).view(b, c, h, w)
- 将Transformer输出的4096个token (64×64的空间展平)重新排列回2D空间特征图 形状
[B, 256, 64, 64]2. 上采样分支选择
if not self.use_high_res_features: upscaled_embedding = self.output_upscaling(src)
普通模式:直接使用预定义的上采样模块(两次反卷积)
高分辨率模式:手动拆解上采样步骤,融入skip连接(类似UNet)
3. 高分辨率特征融合(关键)
dc1, ln1, act1, dc2, act2 = self.output_upscaling feat_s0, feat_s1 = high_res_features # [256×256, 128×128]第一层上采样(64→128)
upscaled_embedding = act1(ln1(dc1(src) + feat_s1))
dc1(src):反卷积上采样到128×128分辨率,通道256→64
+ feat_s1:残差连接加上同分辨率的skip特征(FPN浅层特征,保留细节)
ln1 + act1:层归一化和激活函数第二层上采样(128→256)
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)
dc2(...):反卷积上采样到256×256分辨率,通道64→32
+ feat_s0:加上最高分辨率的skip特征(256×256)最终输出 :
[B, 32, 256, 256]特征图,用于后续掩码生成核心思想
多尺度融合:类似UNet的跳跃连接,将深层的语义特征与浅层的几何细节结合
动态加权:skip特征让模型在上采样过程中恢复精细的边缘和纹理
效率平衡:Transformer在低分辨率处理全局信息,上采样时补充局部细节
这段代码体现了SAM在精度与效率之间的巧妙设计,是生成高质量分割掩码的关键步骤。
解释一下反卷积层 → 层归一化 → 激活函数 → 反卷积层 → 激活函数各自的作用,还有解释一下上采样的维度变化 ,输入(1,256,64,64) 经过ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))变成了什么,为什么
模块作用解析
1. 反卷积层 (ConvTranspose2d)
核心作用:学习上采样,将低分辨率特征图放大到更高分辨率
相比插值上采样(如双线性插值),反卷积是可学习的参数化上采样,能自适应地恢复空间细节
每次上采样使空间尺寸放大2倍(stride=2),同时减少通道数
2. 层归一化 (LayerNorm2d)
作用:稳定训练过程,控制每层的输入分布
对2D特征图的每个样本单独做归一化,减少内部协变量偏移
让激活值分布更稳定,加速收敛,提高泛化能力
3. 激活函数 (GELU/ReLU)
作用:引入非线性,增强模型表达能力
避免多层网络退化为线性变换
GELU相比ReLU更平滑,有助于梯度流动
维度变化详解
输入张量形状
(1, 256, 64, 64) # (batch, channels, height, width)第一次反卷积后
nn.ConvTranspose2d(256, 64, kernel_size=2, stride=2)输出形状计算:
batch:保持不变 → 1
channels:输出通道数 → 64
height:(64 - 1) × 2 + 2 = 128
width:同上 → 128
结果:
--> (1, 64, 128, 128)原因:stride=2表示在输入元素之间插入1个零,kernel_size=2表示卷积核大小为2×2,综合效果是空间尺寸翻倍。
第一次上采样完整流程
(1, 256, 64, 64) ↓ ConvTranspose2d(256→64, kernel=2, stride=2) (1, 64, 128, 128) ↓ LayerNorm2d(64) (1, 64, 128, 128) # 归一化不改变形状 ↓ activation() (1, 64, 128, 128) # 激活函数不改变形状第二次反卷积后
nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)
channels:64 → 32
height:(128 - 1) × 2 + 2 = 256
width:同上 → 256
结果:
--> (1, 32, 256, 256)
流程总结
操作 输出形状 参数说明 输入 (1, 256, 64, 64) transformer输出 ConvTranspose2d #1 (1, 64, 128, 128) 256→64, stride=2 LayerNorm2d (1, 64, 128, 128) 通道维度归一化 GELU (1, 64, 128, 128) 非线性激活 ConvTranspose2d #2 (1, 32, 256, 256) 64→32, stride=2 GELU (1, 32, 256, 256) 非线性激活 最终输出 :
(batch, 32, 256, 256)这种设计通过逐层减少通道数+放大空间尺寸的方式,在恢复细节的同时控制计算量,是分割/生成任务中常见的上采样策略。
4.1.3.1 转置卷积
我觉得上面比较难理解的就是在于输入的 (1,256,64,64) 经过ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))变成了什么维度。ConvTranspose2d就是转置卷积。所以要先理解什么是转置卷积。
首先卷积的目的是进行多对一的操作,也就是我们常看到的高分辨率的图经过卷积之后变成低分辨率的图。转置卷积的目的正好反过来,它的目的是想把低分辨率的图变成高分辨率的图,也就是上采样。与插值进行上采样的方式不同的是,这种方式是可学习的。
先去看看这篇转置卷积的教程:
这里我来理解一下这篇文章。首先要先理解卷积的操作
下面就是3x3的卷积核,没有padding(矩形四周不填0)的情况下,stride=1的情况下,卷积的操作。最后4x4的卷积核会变成2x2。每9个元素会变成1个元素,不过stride=1就是说是每次卷积核移动都是有一列重合的地方。
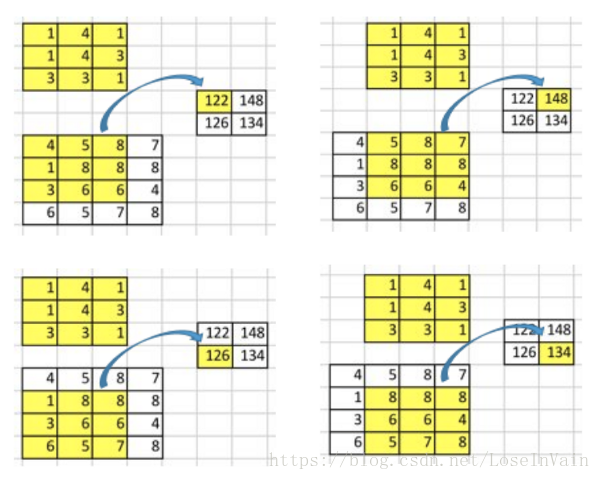
然后为了更好地理解后面的内容,我们先要将卷积操作用一个矩阵相乘来表示,就像下面这样。(4,16) 与 (16,1) 的矩阵相乘 -> (4,1),为什么上面那个卷积的操作相当于这个这两个矩阵相乘呢, 其实是因为每次卷积核跟输入的3x3元素进行卷积的时候,其实是3x3的卷积核矩阵与3x3的输入矩阵的加权求和的操作,其实这两个3x3矩阵分别变成一维的行和列,不就变成了矩阵乘法中的计算方式了吗:一行和一列元素对应相乘再相加。
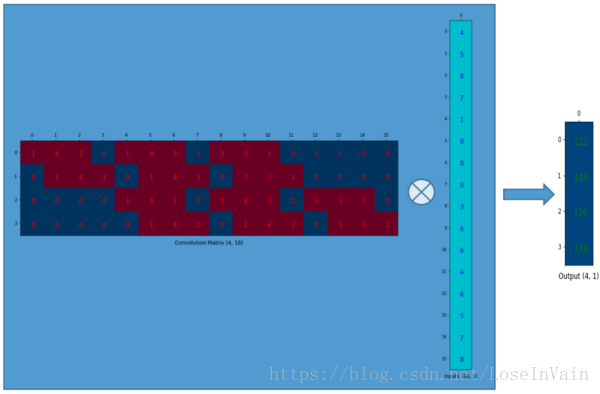
那个16x1的我们比较好理解,就是原先那个4x4的矩阵排列成16x1。但是那个4x16的矩阵是怎么来的,感觉好像是第一行排完之后,第二行从索引1开始排,第三行突然又从索引4开始排?
这个「第二行从索引 1 开始、第三行从索引 4 开始」的现象,正是 im2col(image-to-column) 把 4×4 输入展开成 16×1 向量后,再按「卷积核会在输入上滑动的先后次序」给卷积核权重重新编号 的结果。
下面我把「为什么这一行空 0 的个数、为什么起始索引跳成这样」一步步画给你看。
4×4 输入摊平成 16×1 的列向量
把输入按行优先拉直,给每个像素一个索引 0‒15:
输入摊平 X[col]:
[ 0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15 ] → [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]ᵀ
3×3 核在 4×4 输入上「valid 卷积、步长 1」会滑过 2×2=4 个空间位置
把这 4 个位置按「从左到右、从上到下」编号成输出行号 0‒3:
输出位置 (i_out, j_out) 对应的输入窗口左上角行列号:
输出 0: (0,0) 输出 1: (0,1)
输出 2: (1,0) 输出 3: (1,1)
把每个窗口里的 9 个输入像素再按「行优先」编号到 0‒15 的全局索引
就得到 每一行应该去取 Xcol 的哪 9 列:
输出 0 窗口 (0,0) 包含的输入索引:
[ 0 1 2
4 5 6
8 9 10 ] → [0,1,2,4,5,6,8,9,10]输出 1 窗口 (0,1):
[ 1 2 3
5 6 7
9 10 11 ] → [1,2,3,5,6,7,9,10,11]输出 2 窗口 (1,0):
[ 4 5 6
8 9 10
12 13 14 ] → [4,5,6,8,9,10,12,13,14]输出 3 窗口 (1,1):
[ 5 6 7
9 10 11
13 14 15 ] → [5,6,7,9,10,11,13,14,15]
现在把「每个窗口需要的 9 个输入索引」填到 16 列的稀疏矩阵里
行号 = 输出位置,列号 = 输入摊平索引,有关系的列填 1(或填权重 w),其余填 0:
4×16 卷积矩阵 C(每行 16 列,9 个 1 其余 0):
行 0 [1 1 1 0 1 1 1 0 1 1 1 0 0 0 0 0] ← 窗口 (0,0)
行 1 [0 1 1 1 0 1 1 1 0 1 1 1 0 0 0 0] ← 窗口 (0,1)
行 2 [0 0 0 0 1 1 1 0 1 1 1 0 1 1 1 0] ← 窗口 (1,0)
行 3 [0 0 0 0 0 1 1 1 0 1 1 1 0 1 1 1] ← 窗口 (1,1)观察列索引就能验证你问到的「跳跃」:
行 0 从列 0 开始
行 1 从列 1 开始(因为窗口右移 1 列)
行 2 突然从列 4 开始(因为窗口下移 1 行,一行 4 个像素,所以索引 +4)
行 3 从列 5 开始(再右移 1 列)
把 9 个 1 换成卷积核权重 w₀₀...w₂₂ 就得到文章里那张 4×16 的「卷积矩阵」
转置卷积只不过是把这张矩阵转置成 16×4,再把输入输出角色互换而已。
一句话总结:
「索引跳跃」并不是随意排的,而是完全由「卷积核在输入上滑动一步会跳过多少像素」决定------水平滑一步 +1,垂直滑一步 +input_width。 对 4×4 输入来说,垂直一步正好跳 4 格,所以你看到第三行从索引 4 开始。
既然卷积操作可以通过表示为卷积矩阵和输入矩阵的列向量形式的矩阵乘积形式进行表达,即卷积操作可以表达为:(4,16) 与 (16,1) 的矩阵相乘 -> (4,1),这就实现了16(4×4)到4(2×2)的下采样,因为这个卷积矩阵尺寸正是4×16的。所以,如果你有一个16×4的矩阵,你就可以从4(2×2)到16(4×4)了,这不就是一个上采样的操作吗? 16x4与4x1矩阵相乘 -> 16x1
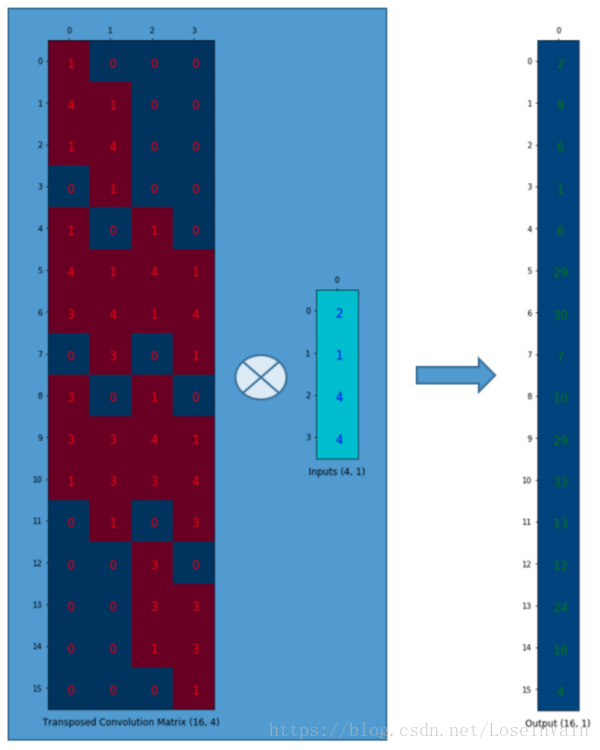
上面这个输出的16x1就可以塑形为(4×4)的矩阵。我们只是对小矩阵(2×2)进行上采样为一个更大尺寸的矩阵(4×4)。这个转置卷积矩阵维护了一个1个元素到9个元素的映射关系,因为这个关系正表现在了其转置卷积元素上。需要注意的是 :这里的转置卷积矩阵的参数,不一定从原始的卷积矩阵中简单转置得到的,转置这个操作只是提供了转置卷积矩阵的形状而已。
转置卷积操作构建了和普通的卷积操作一样的连接关系,只不过这个是从反向方向开始连接的。我们可以用它进行上采样。另外,这个转置卷积矩阵的参数是可以学习的,因此我们不需要一些人为预先定义的方法。即使它被称为转置卷积,它并不是意味着我们将一些现存的卷积矩阵简单转置并且使用其转置后的值。
从本质来说,转置卷积不是一个卷积,但是我们可以将其看成卷积,并且当成卷积这样去用。我们通过在输入矩阵中的元素之间插入0进行补充,从而实现尺寸上采样,然后通过普通的卷积操作就可以产生和转置卷积相同的效果了。你在一些文章中将会发现他们都是这样解释转置卷积的,但是这个因为在卷积操作之前需要通过添加0进行上采样,因此是比较低效率的。
4.1.3.2 回到我们原来的问题
为什么输入(1,256,64,64) 经过ConvTranspose2d(256, 64, kernel_size=(2, 2), stride=(2, 2))变成了(1,64,128,128)
PyTorch
ConvTranspose2d输出尺寸公式是:
H_out = (H_in - 1) * stride - 2 * padding + kernel_size + output_padding(
W_out的计算方式完全相同)
代入公式:
H_out = (H_in - 1) × stride + kernel_size - 2 × padding
= (64 - 1) × 2 + 2 - 0
= 63 × 2 + 2
= 128但这个公式为什么是这样呢?我们看一下卷积算输出尺寸的公式:
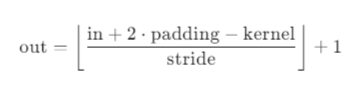
好像真就是反过来算而已。但是反过来算的时候怎么理解呢?
4.1.3.3 怎么感觉跟ASPP空洞卷积有点像呢,
你观察得非常敏锐!这确实是理解深度卷积的一个关键盲点。让我揭示它们的表面相似性 和本质区别。
一、表面相似:都在"插零"
操作 在哪里插零? 插零目的 转置卷积 输入特征图的元素之间 扩大空间尺寸(上采样) 空洞卷积 卷积核权重的元素之间 扩大感受野(不增加计算) 可视化对比:
转置卷积(stride=2):
输入特征图: [a, b] [c, d] 插零后: [a, 0, b] [0, 0, 0] [c, 0, d]→ 空间尺寸变大(2×2 → 3×3 → 卷积后4×4)
空洞卷积(dilation=2):
复制
普通卷积核: [w1, w2, w3] [w4, w5, w6] [w7, w8, w9] 空洞卷积核: [w1, 0, w2, 0, w3] [0, 0, 0, 0, 0] [w4, 0, w5, 0, w6] [0, 0, 0, 0, 0] [w7, 0, w8, 0, w9]→ 空间尺寸不变(感受野变大)
二、为什么感觉像?看卷积矩阵的视角
当你从卷积矩阵的稀疏性角度看:
转置卷积矩阵C^T(16×4,stride=2):
复制
行0: [w1, 0, w2, 0, w3, 0, ...] ← 权重被"空洞"隔开 行1: [0, w1, 0, w2, 0, w3, ...] ...这种稀疏模式看起来像空洞卷积的权重排列!
关键区别:
转置卷积的稀疏 :源于输入元素间的跳连接(stride>1导致)
空洞卷积的稀疏 :源于权重本身的跳连接(dilation>1导致)
三、本质区别:数学层面的不同
转置卷积:
是正向卷积的转置操作(矩阵视角)
输出尺寸公式:
H_out = (H_in-1)*stride + kernel改变空间分辨率
空洞卷积:
是权重重参数化(没有改变卷积本质)
输出尺寸公式:
H_out = (H_in + 2*padding - (kernel + (kernel-1)*(dilation-1))) / stride + 1保持空间分辨率,扩大感受野
四、实际应用中的协同
在深度学习网络中,它们经常配合使用:
典型场景:语义分割(如DeepLab)
Encoder:用空洞卷积提取密集特征(不损失分辨率)
Decoder:用转置卷积上采样恢复分辨率
特征提取:Conv(dilation=2) → 保持尺寸,感受野×2
Conv(dilation=4) → 保持尺寸,感受野×4上采样: ConvTranspose2d(stride=2) → 尺寸×2
一句话总结:
转置卷积是"空间的跳跃",空洞卷积是"权重的跳跃"。
你的直觉很准------它们都利用了稀疏连接的思想,但一个在输入空间,一个在权重空间!
4.2 MaskDecoder的初始化
为什么这里突然加了一个MaskDecoder的初始化,其实是先有初始化,再有predict_masks和forward的。但因为每个类的初始化都特别多东西,所以初始化一直都不怎么关注。但这里因为太阻碍理解predict_masks了,所以先大致看一下初始化。
class MaskDecoder(nn.Module):
def __init__(
self,
*,
transformer_dim: int,
transformer: nn.Module,
num_multimask_outputs: int = 3,
activation: Type[nn.Module] = nn.GELU,
iou_head_depth: int = 3,
iou_head_hidden_dim: int = 256,
use_high_res_features: bool = False,
iou_prediction_use_sigmoid=False,
dynamic_multimask_via_stability=False,
dynamic_multimask_stability_delta=0.05,
dynamic_multimask_stability_thresh=0.98,
pred_obj_scores: bool = False,
pred_obj_scores_mlp: bool = False,
use_multimask_token_for_obj_ptr: bool = False,
) -> None:
"""
使用transformer架构,根据图像和提示嵌入预测掩码的解码器。
这是SAM(Segment Anything Model)的核心组件之一。
参数说明:
transformer_dim (int): Transformer的通道维度(特征维度)
transformer (nn.Module): 用于预测掩码的transformer模型
num_multimask_outputs (int): 在掩码歧义消除时预测的掩码数量(如:一个点可能对应多个物体)
activation (nn.Module): 上采样掩码时使用的激活函数类型
iou_head_depth (int): 预测掩码质量的MLP深度(层数)
iou_head_hidden_dim (int): 预测掩码质量的MLP隐藏层维度
use_high_res_features (bool): 是否使用高分辨率特征(如FPN的浅层特征)
iou_prediction_use_sigmoid (bool): IoU预测是否使用sigmoid激活
dynamic_multimask_via_stability (bool): 是否通过稳定性动态选择多掩码输出
dynamic_multimask_stability_delta (float): 稳定性判断的delta阈值
dynamic_multimask_stability_thresh (float): 稳定性判断的阈值
pred_obj_scores (bool): 是否预测对象分数(用于区分前景/背景)
pred_obj_scores_mlp (bool): 对象分数预测是否使用MLP
use_multimask_token_for_obj_ptr (bool): 是否使用多掩码token作为对象指针
"""
super().__init__()
# 保存transformer的维度配置
self.transformer_dim = transformer_dim
self.transformer = transformer
# 掩码输出数量配置(num_multimask_outputs + 1个单一掩码输出)
self.num_multimask_outputs = num_multimask_outputs
# 定义特殊token的嵌入层
# IoU token: 用于预测掩码质量的特殊token
self.iou_token = nn.Embedding(1, transformer_dim)
# Mask tokens: 用于生成不同掩码的token(包括1个单一掩码和num_multimask_outputs个多掩码)
self.num_mask_tokens = num_multimask_outputs + 1
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
# 对象分数预测配置(用于视频分割等需要区分对象的场景)
self.pred_obj_scores = pred_obj_scores
if self.pred_obj_scores:
# Obj score token: 用于预测对象存在性的特殊token
self.obj_score_token = nn.Embedding(1, transformer_dim)
self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr
# 定义输出上采样模块:将transformer输出的低分辨率特征图(如64x64)上采样到更高分辨率(如256x256)
# 结构:反卷积层 → 层归一化 → 激活函数 → 反卷积层 → 激活函数
self.output_upscaling = nn.Sequential(
# 第一次上采样:dim → dim/4,空间尺寸x2(如64x64 → 128x128)
nn.ConvTranspose2d(
transformer_dim, transformer_dim // 4, kernel_size=2, stride=2
),
LayerNorm2d(transformer_dim // 4), # 2D层归一化
activation(), # 激活函数(默认GELU)
# 第二次上采样:dim/4 → dim/8,空间尺寸x2(如128x128 → 256x256)
nn.ConvTranspose2d(
transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2
),
activation(), # 激活函数
)
# 是否使用高分辨率特征(如FPN的浅层特征)来增强掩码细节
self.use_high_res_features = use_high_res_features
if use_high_res_features:
# 定义用于融合高分辨率特征的1x1卷积层
# conv_s0: 处理最浅层特征(分辨率最高)
self.conv_s0 = nn.Conv2d(
transformer_dim, transformer_dim // 8, kernel_size=1, stride=1
)
# conv_s1: 处理次浅层特征
self.conv_s1 = nn.Conv2d(
transformer_dim, transformer_dim // 4, kernel_size=1, stride=1
)
# 定义掩码超网络MLP列表:为每个mask token生成对应的掩码头参数
# 每个MLP将transformer输出映射到较小的权重空间
self.output_hypernetworks_mlps = nn.ModuleList(
[
# 输入维度: transformer_dim, 输出维度: transformer_dim // 8, 隐藏层维度: transformer_dim, 层数: 3
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
# 定义IoU预测头:预测每个掩码token生成的掩码质量(IoU分数)
self.iou_prediction_head = MLP(
transformer_dim, # 输入维度
iou_head_hidden_dim, # 隐藏层维度
self.num_mask_tokens, # 输出维度(对应每个mask token的IoU)
iou_head_depth, # MLP深度
sigmoid_output=iou_prediction_use_sigmoid, # 是否使用sigmoid输出
)
# 对象分数预测头(可选):预测对象是否存在或对象性分数
if self.pred_obj_scores:
# 简单的线性层或MLP
self.pred_obj_score_head = nn.Linear(transformer_dim, 1)
if pred_obj_scores_mlp:
# 使用3层MLP替代线性层
self.pred_obj_score_head = MLP(transformer_dim, transformer_dim, 1, 3)
# 动态多掩码机制配置:当单掩码输出不稳定时,动态切换到最佳多掩码输出
self.dynamic_multimask_via_stability = dynamic_multimask_via_stability
# 稳定性判断的delta值:用于计算掩码概率分布的稳定性
self.dynamic_multimask_stability_delta = dynamic_multimask_stability_delta
# 稳定性阈值:低于此阈值则触发多掩码切换
self.dynamic_multimask_stability_thresh = dynamic_multimask_stability_thresh代码核心原理解释
这段代码实现了 SAM (Segment Anything Model) 的掩码解码器,其核心思想如下:
- 双路径架构
Prompt路径 :处理点、框、文本等提示信息,通过
mask_tokens嵌入Image路径 :处理图像特征,通过
output_upscaling上采样2. Transformer核心
将图像嵌入与prompt tokens(mask tokens + iou token)拼接后送入transformer
利用自注意力机制让tokens与图像特征充分交互
3. 超网络机制 (Hypernetwork)
关键创新:不使用固定权重的掩码头,而是动态生成掩码头参数
output_hypernetworks_mlps为每个mask token学习一个小型MLP,该MLP输出卷积核权重实现"一个模型,多个动态头部",适应不同提示的歧义性
4. 多掩码输出策略
单一掩码 (tokens0):当提示明确时使用
多掩码 (tokens1:):当提示模糊时(如单个点可能对应多个物体),输出3个掩码选项
5. 动态稳定性Fallback
当
dynamic_multimask_via_stability=True时,会评估单一掩码的稳定性如果稳定性 < 阈值,自动切换到最佳多掩码输出,显著提升模糊提示下的性能
6. IoU预测头
同时预测每个掩码的质量分数,帮助用户选择最佳掩码
输出4个IoU分数(1个单一 + 3个多掩码)
7**. 高分辨率特征融合**
可选地融合FPN浅层特征(
use_high_res_features=True)通过
conv_s0和conv_s1融合多尺度信息,提升掩码边缘精度8. 应用场景扩展
对象分数预测 (
pred_obj_scores):支持视频分割中的对象追踪对象指针 (
use_multimask_token_for_obj_ptr):在视频帧间传递对象信息
MaskDecoder是SAM模型的掩码解码器,核心是通过超网络为每个掩码token动态生成专属的卷积参数,使Transformer能同时预测多个候选掩码及其IoU质量分数;当提示模糊时自动切换至多掩码输出并选择最稳定的预测,可选融合高分辨率特征优化边缘细节。
五、UNet
不用看这里,只是感觉UNet语义分割里面编码器出来以后用了空洞卷积,跟转置卷积应该没什么关系。与本文无关。
编码器18层,输入是(1,3,640,640)输出(1,2,640,640)
1.除了第1次块操作,特征图数量在不断上升
特征图数及出现次数:3*1=>32*1 => 16*1 => 24*2 => 32*3 => 64*4 => 96*3 => 160*3 => 320*1
2.特征图尺寸在不断下降
特征图尺寸及出现次数:640 => 320*2 => 160*2 => 80*3 => 40*7 => 20*4
尺寸减半的方法全都是倒残差结构中的分组卷积使用3*3卷积核,stride=2,padding=1实现的(输入尺寸是偶数)。
- 共18次块操作,前2次有点特殊,后面16次都是倒残差结构 倒残差结构大致就是1*1逐点卷积升维6倍+BatchNorm2d+RELU,然后3*3分组卷积1次+BatchNorm2d+RELU,然后3*3分组卷积1次+BatchNorm2d+RELU,然后再1*1卷积降维(降维到哪里见第1点)+BatchNorm2d
第1次块操作是3*3的卷积升维(3到32)+BatchNorm2d+RELU,尺寸减半。
第2次块操作块名也是倒残差,但是直接进入3*3分组卷积+BatchNorm2d+RELU,然后1*1卷积1次并降维(从32到16)+BatchNorm2d。
总之,升维是为了提取更多的信息,降维和降尺寸都是为了减少计算量。 倒残差是先升维再卷积再降维,但是在第2次块操作中放弃了1*1的升维,可能是因为第1次块操作已经做了升维,一开始原始特征没有丢失过多。
- 64维和96维的时候相同尺寸的重复次数特别多,可能是认为这个尺寸下是比较重要的特征。
解码器:空洞卷积、Dropout、上采样、拼接、特征融合、平滑卷积。
第17层的(1,320,20,20)经过1x1卷积、ASPP空洞卷积dilation取6、12、18四个操作变成四个(1,256,20,20)再连接成(1,1024,20,20)再dropout再1x1卷积成(1,256,20,20),再上采样成(1,256,40,40)再跟(1,96,40,40)连接再cat成(1,352,40,40),再平滑卷积smooth_conv: 3x3conv;1x1conv 变成(1,96,40,40),这就是第7个时的连接。只有3和4的连接最后是变成32维度,其他的都是变回编码器原来的维度原来的尺寸。比如第三个编码器是(1,16,320,320)连接后变成了(1,32,320,320)然后会经过pred和上采样变成(1,2,640,640)。
特征图数及出现次数:3*1=>32*1 => 16*1 => 24*2 => 32*3 => 64*4 => 96*3 => 160*3 => 320*1
把上面9次维度变化标记为1,2,3,4,5,6,7,8, 9,与解码器连接的层是3,4,5,7。