1. 引言
本文档旨在详细阐述一个名为"抓取网站信息"的自动化工作流的技术实现、架构和组件功能。该工作流的核心目标是从指定的网站站点地图(sitemap)出发,系统性地抓取网站内容,利用大型语言模型(LLM)对内容进行深度结构化处理,并最终生成适用于检索增强生成(RAG)知识库的标准化Markdown文件。
2. 工作流架构概览
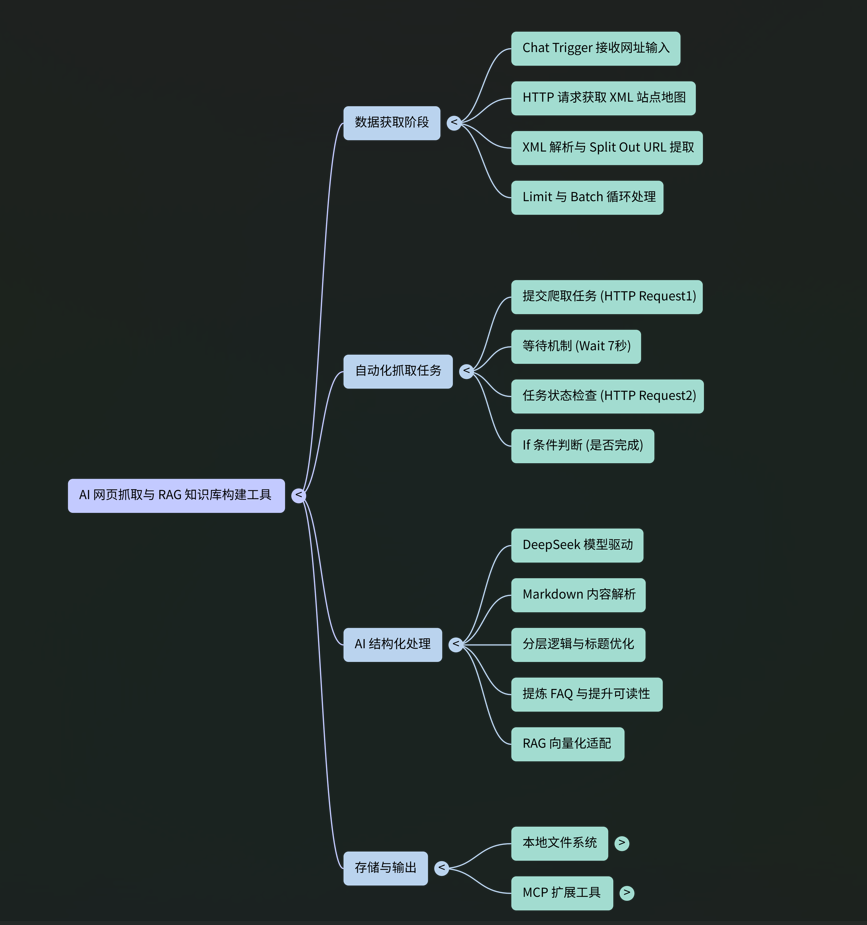
整个工作流遵循一个清晰的数据处理管道,可分为以下五个核心阶段:
- 数据输入与触发 工作流由用户在聊天界面中输入一个URL(通常是站点地图地址)来启动,该URL成为所有后续处理的起点。
- 站点地图解析 系统接收到初始URL后,会请求并解析该XML站点地图,从中提取出构成网站的所有独立页面URL列表。
- 异步内容抓取 所有提取出的URL被分批提交至一个外部的异步抓取服务。工作流通过一个轮询机制持续监控抓取任务的状态,直至任务完成。
- AI内容结构化 一旦内容抓取成功,工作流将调用大型语言模型(LLM),根据预设的指令对抓取到的原始Markdown内容进行格式化、清理和结构化处理。
- 文件持久化 最后,经过AI处理和优化的结构化内容被保存为本地Markdown文件,为后续的知识库入库和向量化做好准备。
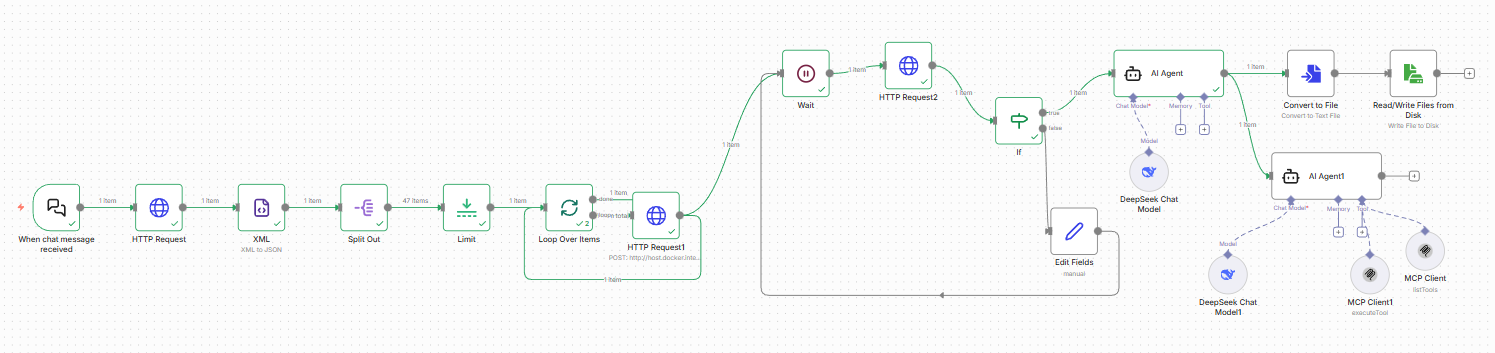
3. 核心组件详细规格
3.1 数据输入与初始化
工作流的入口点,负责接收初始指令。
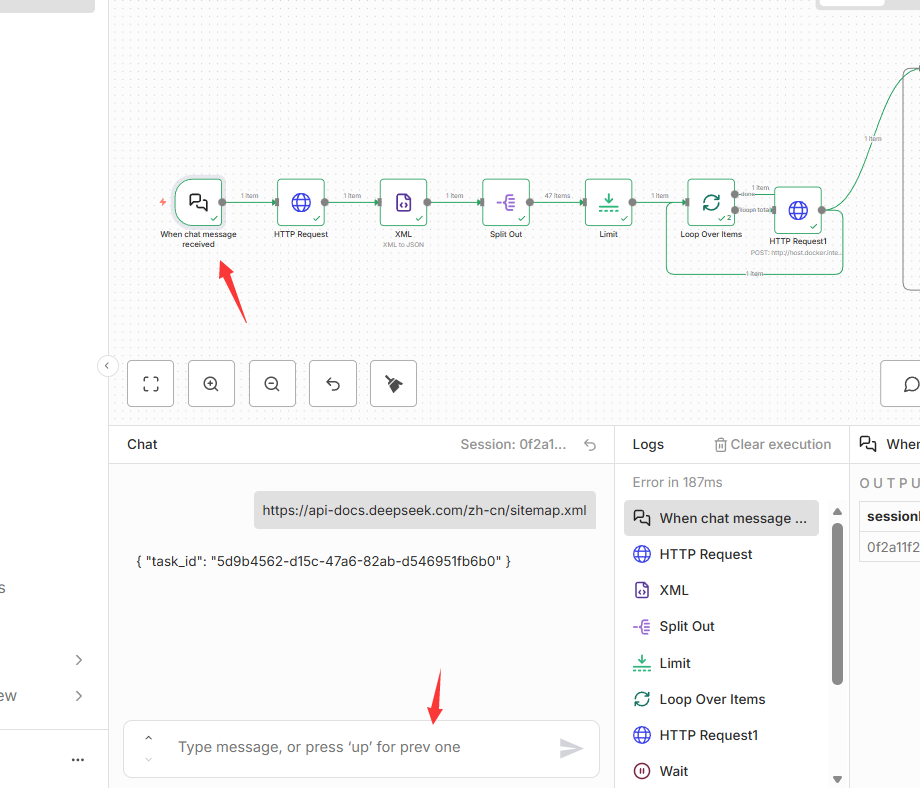
- 节点名称 :
When chat message received - 节点类型 :
@n8n/n8n-nodes-langchain.chatTrigger - 核心功能: 作为工作流的触发器,监听并接收用户通过聊天界面输入的初始消息。
- 关键参数 : 将接收到的聊天输入(
$json.chatInput)作为后续节点的URL来源。
3.2 站点地图解析与URL提取
此阶段负责从站点地图URL中解析出所有待抓取的页面链接。
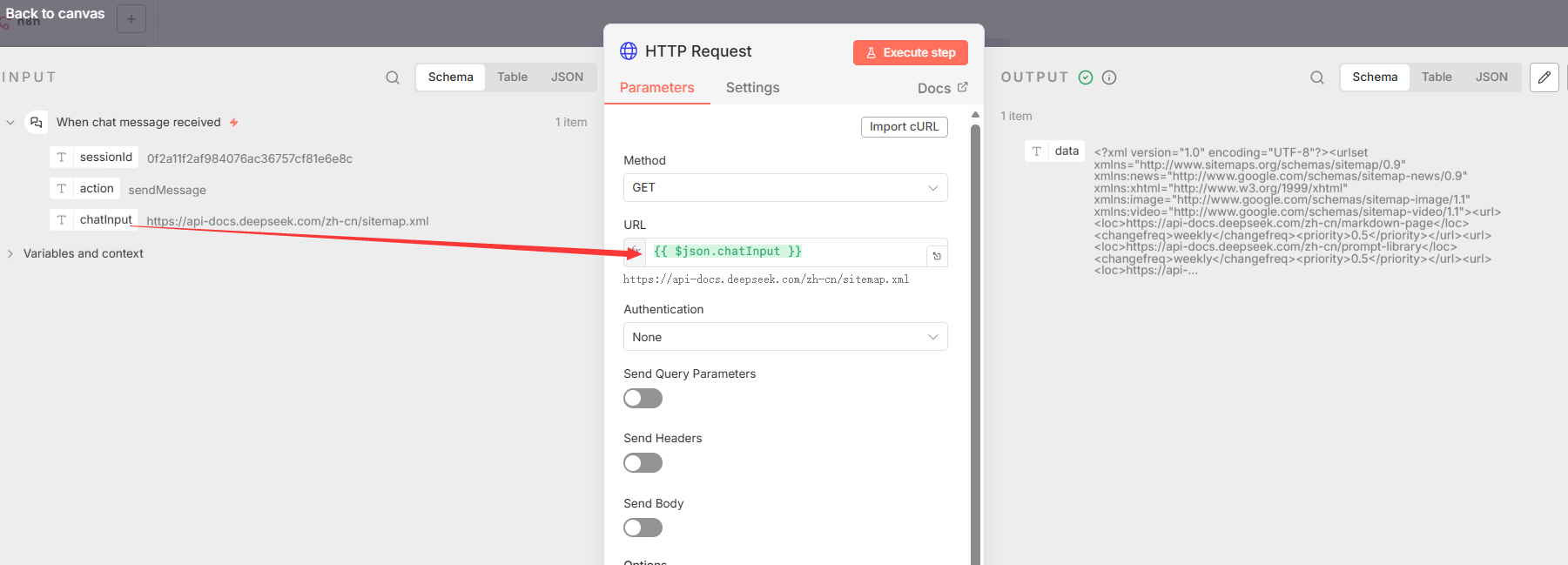
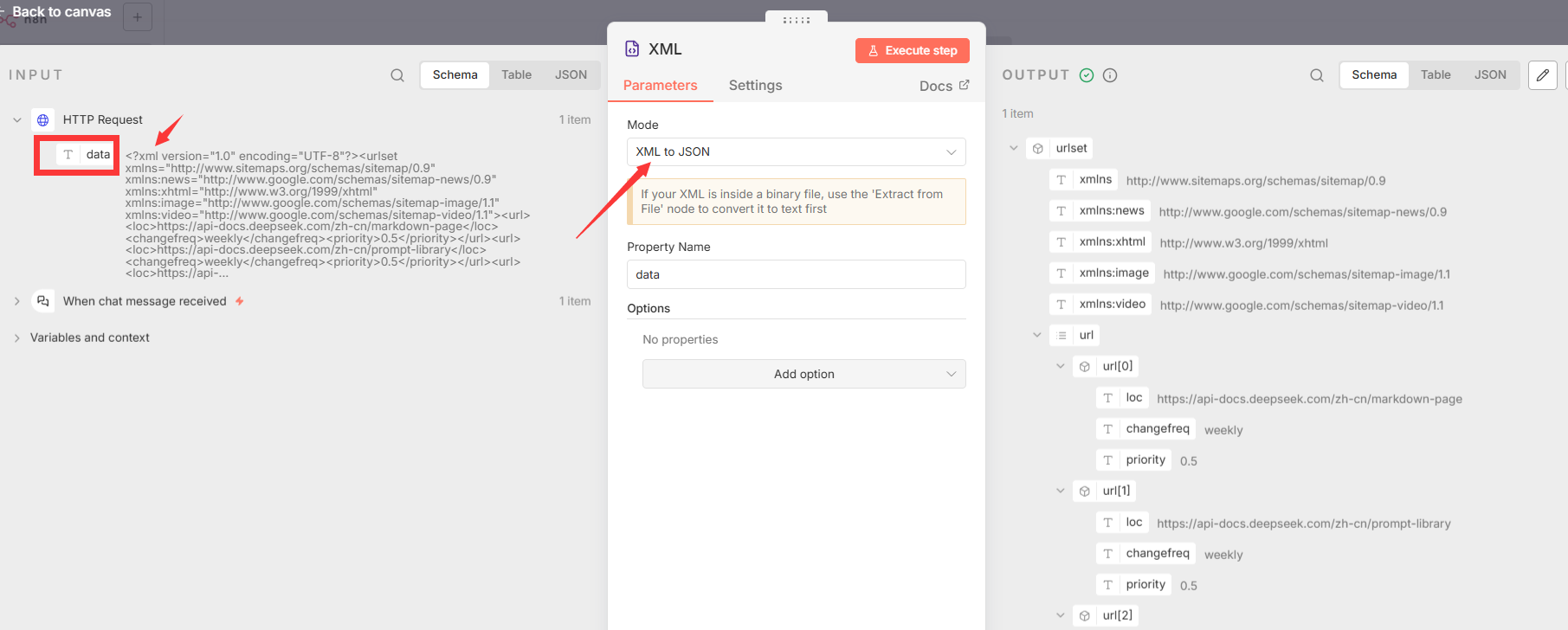
- 节点 1: HTTP Request
- 节点类型 :
n8n-nodes-base.httpRequest - 核心功能: 向触发器提供的URL(站点地图的地址)发起GET请求,获取XML站点地图的原始数据。
- 关键参数 :
url: "={``{ $json.chatInput }}"
- 节点类型 :
- 节点 2: XML转为json
- 节点类型 :
n8n-nodes-base.xml - 核心功能: 将上一步获取的原始数据解析为结构化的XML对象,以便提取信息。
- 节点类型 :
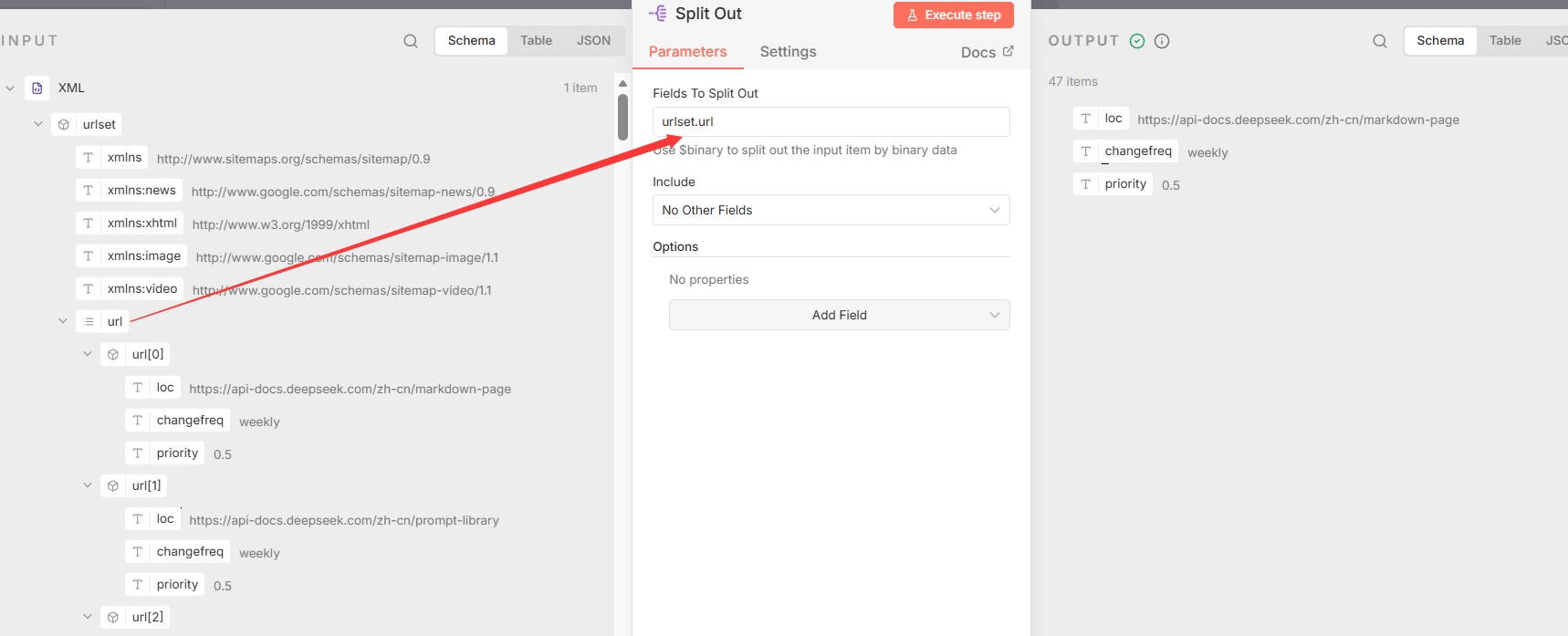
- 节点 3: Split Out
- 节点类型 :
n8n-nodes-base.splitOut - 核心功能 : 从解析后的XML数据中,将
urlset.url字段下的所有URL条目拆分成独立的数据项,为后续的逐一处理做准备。 - 关键参数 :
fieldToSplitOut: "urlset.url"
- 节点类型 :
3.3 数据批处理与循环
在对大量URL进行抓取前,进行必要的流程控制和准备。
- 节点 1: Limit
- 节点类型 :
n8n-nodes-base.limit - 核心功能: 限制进入后续流程的URL数量。此节点在当前配置中未设置具体限制值,主要作为流程控制的占位符,便于在需要时快速启用进行测试或分批处理。
- 节点类型 :
- 节点 2: Loop Over Items
- 节点类型 :
n8n-nodes-base.splitInBatches - 核心功能: 建立一个循环机制,用于迭代处理每一个从站点地图中提取出的URL。
- 节点类型 :
3.4 异步内容抓取与状态轮询
此部分实现了一个异步任务提交和状态检查的轮询(polling)循环。工作流首先向外部服务提交一个抓取任务,然后定期查询该任务的状态,直到任务完成后才进入下一阶段。
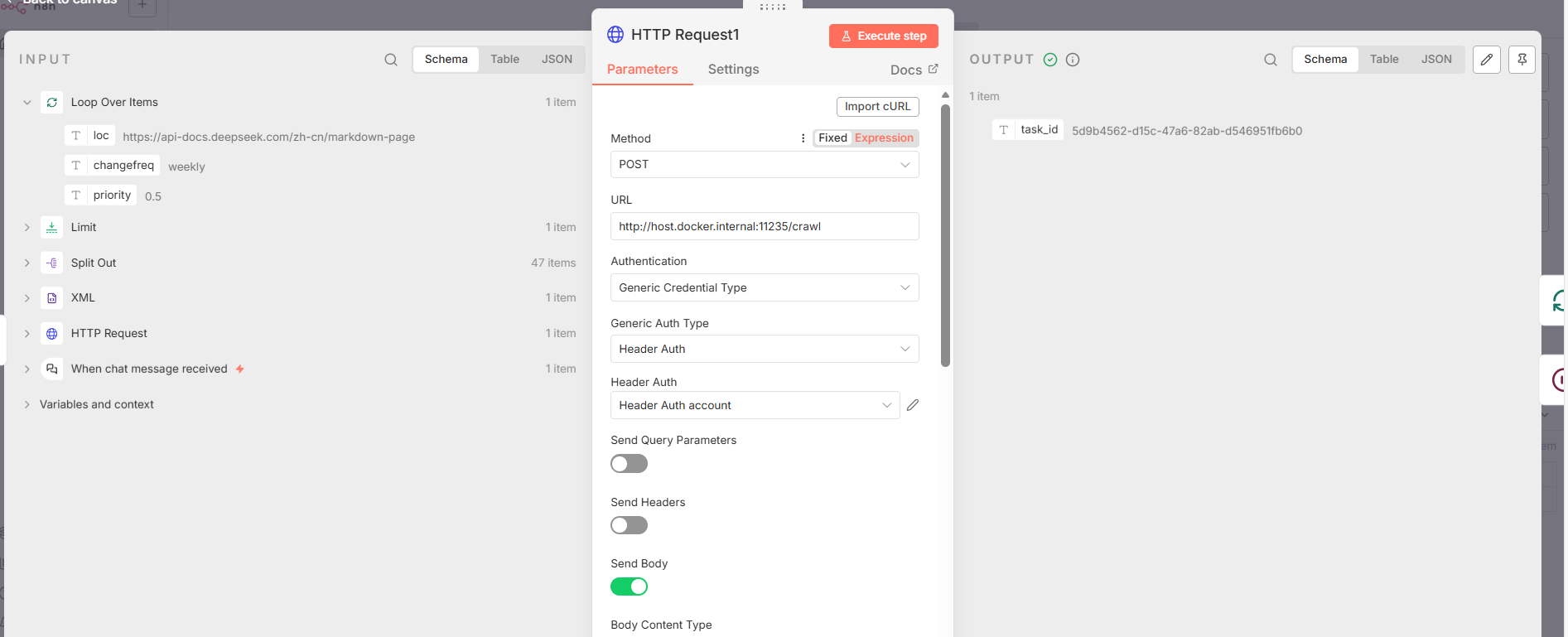
- 节点 1: HTTP Request1**(任务提交)**
- 节点类型 :
n8n-nodes-base.httpRequest - 核心功能 : 向本地的抓取服务 (
http://host.docker.internal:11235/crawl) 发起一个POST请求,提交一个抓取任务。 - 关键参数 :
method: "POST"url:http://host.docker.internal:11235/crawlbodyParameters: 发送包含urls和priority(值为10)的请求体。authentication: 使用httpHeaderAuth进行认证。
- 输出 : 该请求返回一个
task_id,用于后续的状态查询。
- 节点类型 :
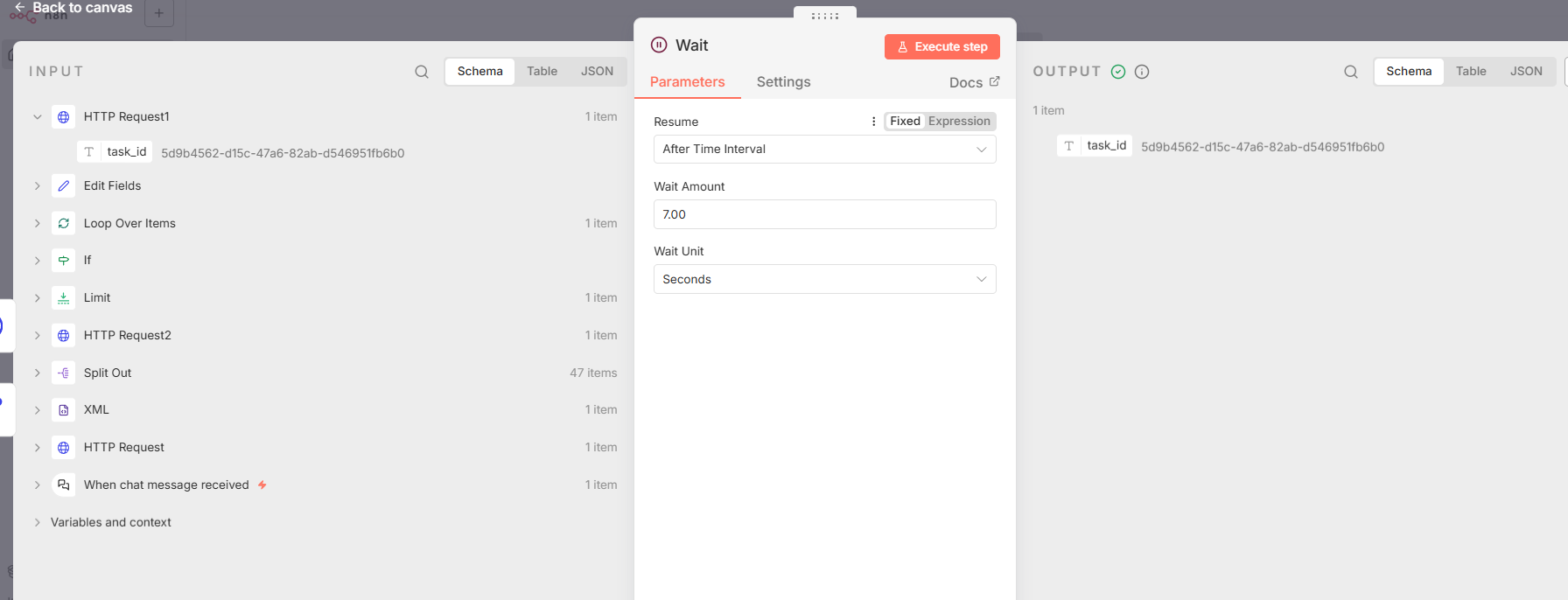
- 节点 2: Wait
- 节点类型 :
n8n-nodes-base.wait - 核心功能: 暂停工作流执行,以避免过于频繁地查询任务状态,减轻服务器压力。
- 关键参数 :
amount参数设置为7,在此节点上下文中代表7秒。
- 节点类型 :
- 节点 3: HTTP Request2**(状态查询)**
- 节点类型 :
n8n-nodes-base.httpRequest - 核心功能 : 使用上一步提交任务时获取的
task_id,向抓取服务的任务查询端点发起GET请求,获取任务的当前状态。 - 关键参数 :
url: "=http://host.docker.internal:11235/task/{``{ $json.task_id }}"
- 节点类型 :
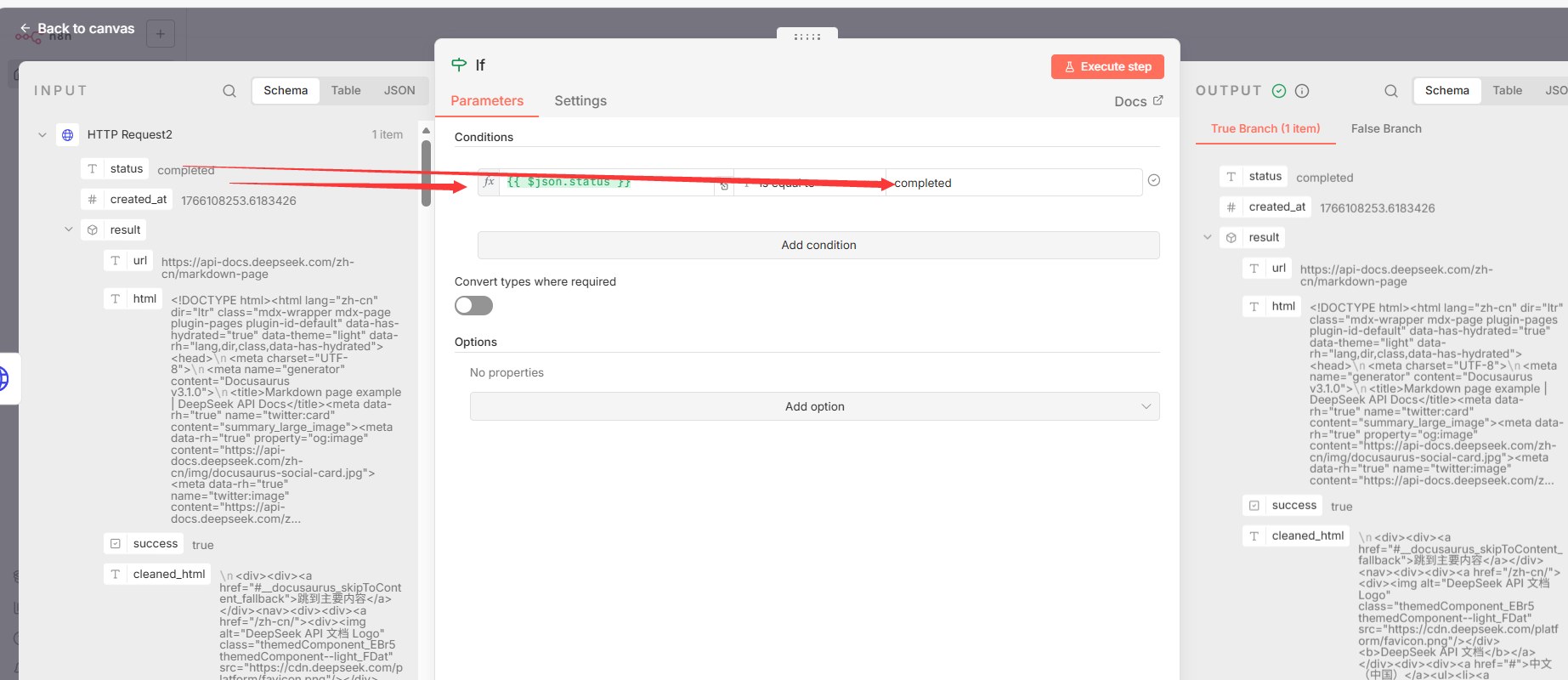
- 节点 4: If**(条件判断)**
- 节点类型 :
n8n-nodes-base.if - 核心功能 : 检查任务状态查询返回的
status字段。 - 关键参数 : 如果
$json.status的值等于"completed",则流程进入数据处理分支;否则,进入轮询等待分支。
- 节点类型 :
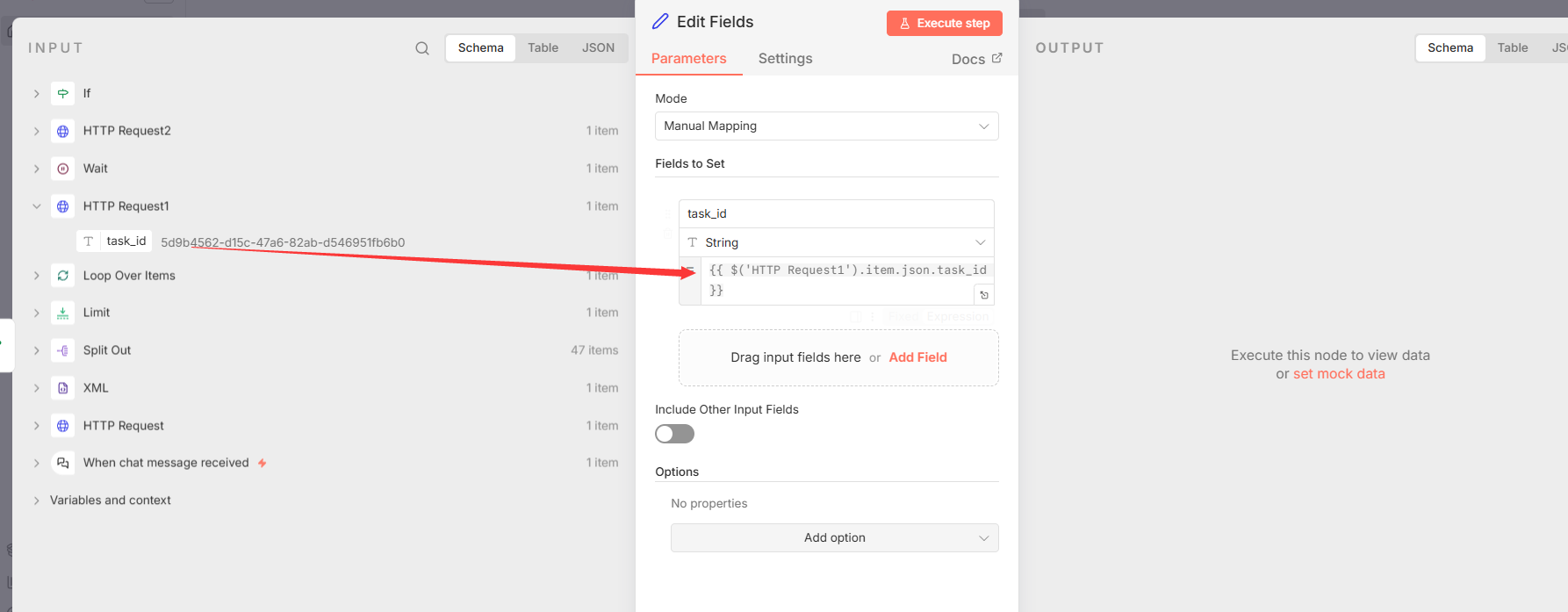
- 节点 5: Edit Fields**(循环变量设置)**
- 节点类型 :
n8n-nodes-base.set - 核心功能 : 此节点位于
If节点的"失败"(即任务未完成)分支,其核心作用是维持轮询循环的状态。它通过表达式{``{ $('HTTP Request1').item.json.task_id }}捕获并保留初始任务提交时返回的task_id,并将其传递回Wait节点。这确保了在每一次循环迭代中,状态查询节点都能正确地指向最初提交的同一个任务,避免了因循环导致的状态丢失。
- 节点类型 :
3.5 AI驱动的内容结构化
当抓取任务完成后,系统利用大型语言模型对抓取到的内容进行高级处理。
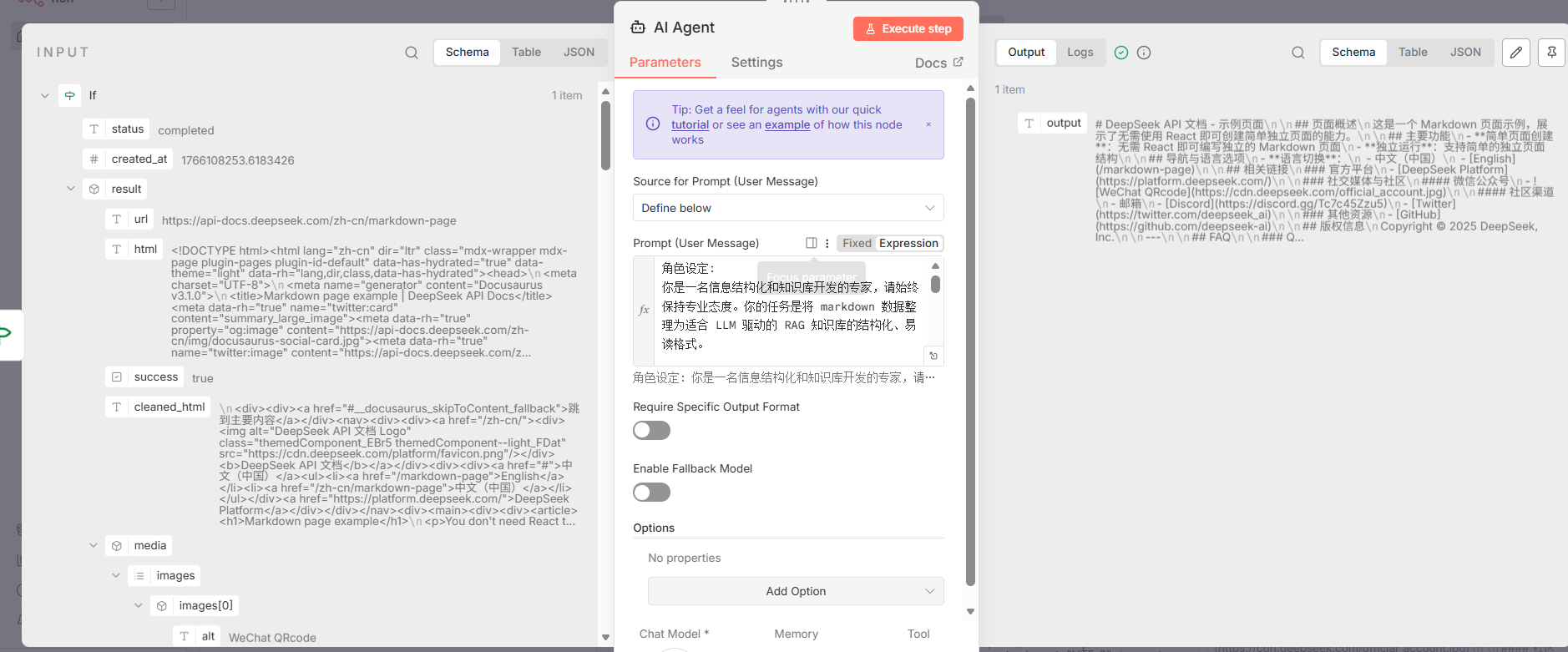
- 节点 1: AI Agent
- 节点类型 :
@n8n/n8n-nodes-langchain.agent - 核心功能 : 调用一个大型语言模型(LLM),根据预设的提示词(Prompt),对抓取到的Markdown内容 (
$json.result.markdown) 进行结构化、清理和格式优化。 - 关键参数: 使用以下提示词对LLM的行为进行精确控制,核心指令包括角色设定、任务要求(内容解析、结构化整理、创建FAQ、提升可读性)和响应规则。
- 节点类型 :
bash
角色设定:
你是一名信息结构化和知识库开发的专家,请始终保持专业态度。你的任务是将 markdown 数据整理为适合 LLM 驱动的 RAG 知识库的结构化、易读格式。
任务要求:
1. 内容解析
- 识别 markdown 数据中的关键内容和主要结构。
2. 结构化整理
- 以清晰的标题和分层逻辑组织信息,使其易于检索和理解。
- 保留所有可能对回答用户查询有价值的细节。
3. 创建 FAQ (如适用)
- 根据内容提炼出常见问题,并提供清晰、直接的解答。
4. 提升可读性
- 采用项目符号、编号列表、段落分隔等格式优化排版,使内容更直观。
5. 优化输出
- 严格去除 AI 生成的附加说明,仅保留清理后的核心数据。
响应规则:
1. 完整性:确保所有相关信息完整保留,避免丢失对搜索和理解有价值的内容。
2. 精准性:FAQ 需紧密围绕内容,确保清晰、简洁且符合用户需求。
3. 结构优化:确保最终输出便于分块存储、向量化处理,并支持高效检索。
数据输入:
<markdown>XXX</markdown>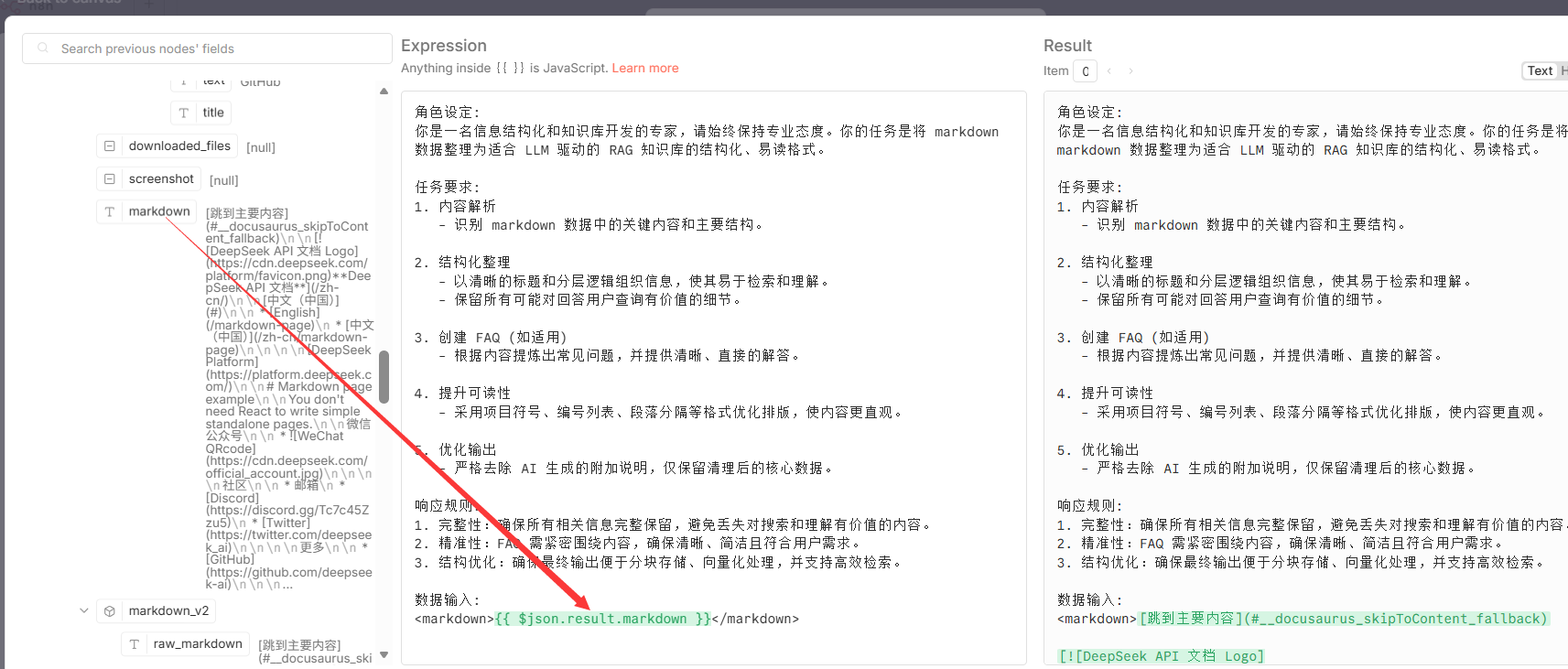
- 节点 2: DeepSeek Chat Model
- 节点类型 :
@n8n/n8n-nodes-langchain.lmChatDeepSeek - 核心功能 : 作为
AI Agent节点的后端语言模型,负责具体执行提示词中定义的复杂指令。
- 节点类型 :
3.6 数据持久化:文件输出
工作流将AI处理后的最终内容保存到磁盘,并提供了两种并行的实现方式。
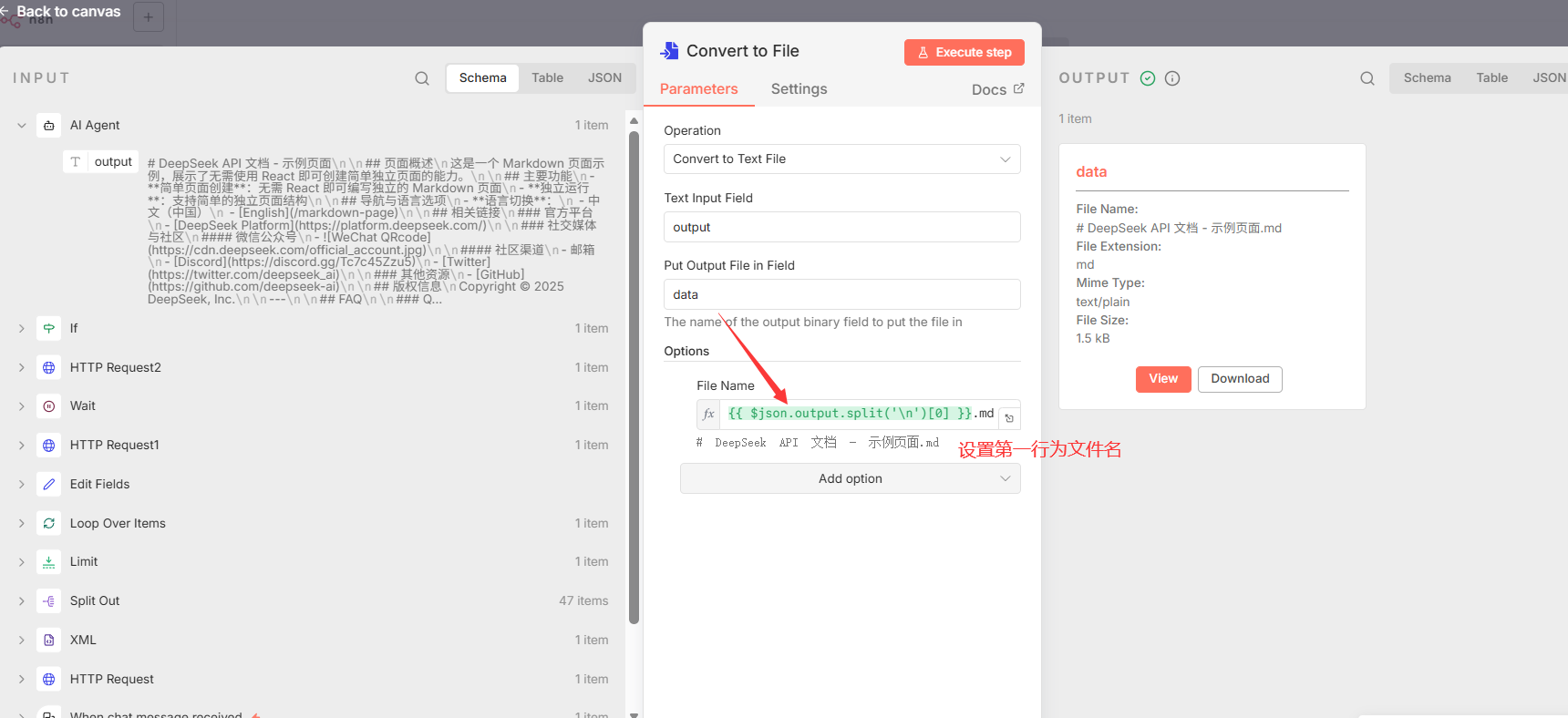
- 方式一:直接文件写入
- 节点 1: Convert to File: 将
AI Agent输出的文本内容转换为文件对象。文件名由输出内容的第一行决定 ({``{ $json.output.split('\\n')[0] }}.md),以生成一个简洁且相关的文件名。 - 节点 2: Read/Write Files from Disk: 将上一步生成的文件对象实际写入到服务器的磁盘。值得注意的是,此节点的
fileName参数配置为=/home/node/{``{ $('AI Agent').item.json.output }}.md,它会尝试使用AI Agent节点的全部文本输出作为文件名。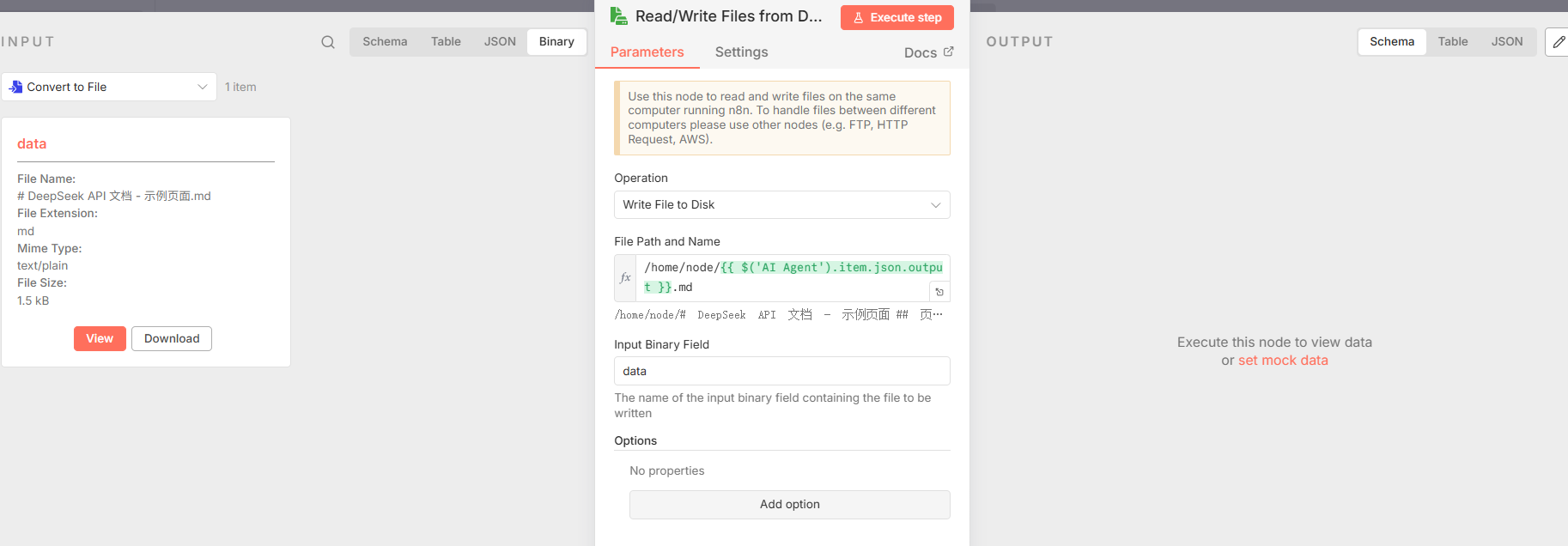
- 节点 1: Convert to File: 将
- 方式二:通过AI Agent工具写入
- 节点 1: AI Agent1: 这是第二个AI Agent,其任务非常专一:根据一个简单的自然语言指令 (
"把{``{$json.output}}写入/home/node/{``{new Date().toISOString()}}.md文件中") 来执行文件写入操作。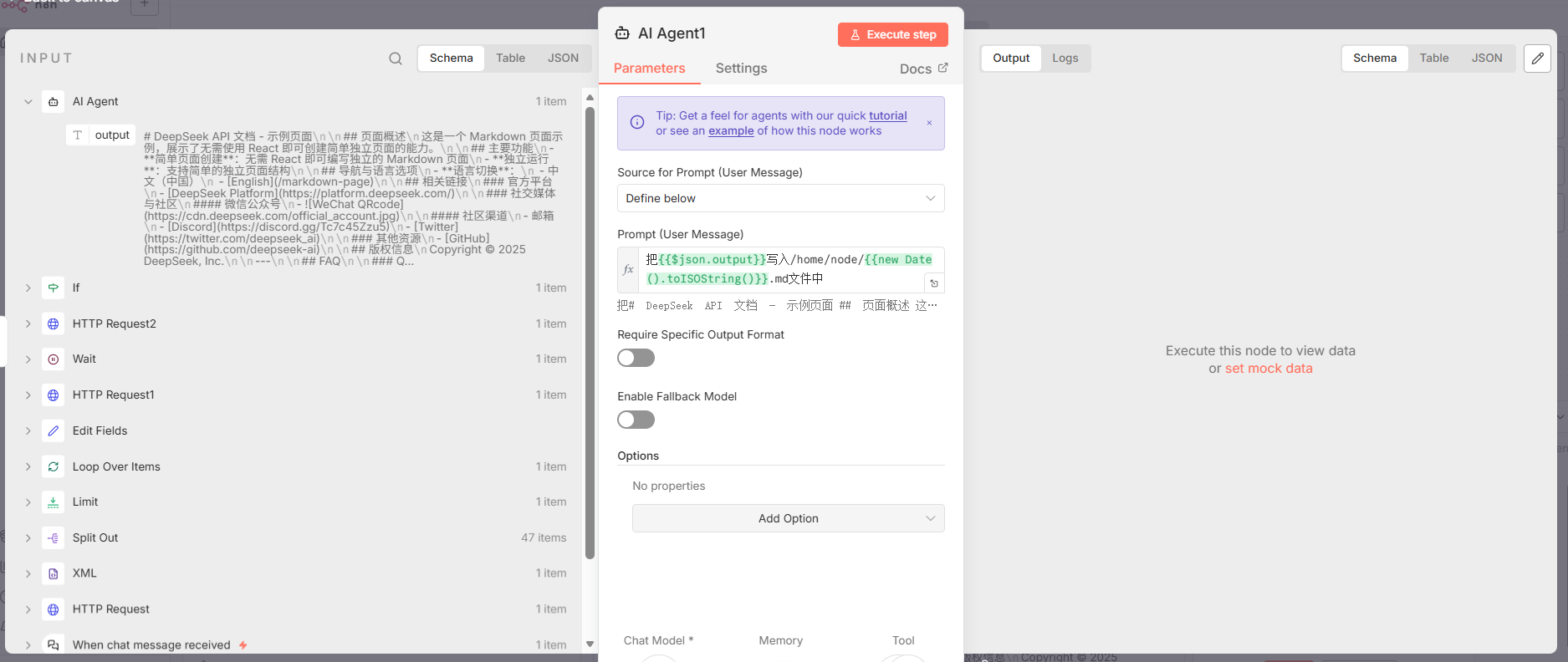
- 节点 2 & 3: MCP Client**&** MCP Client1: 为
AI Agent1提供外部工具。此Agent连接了两个mcpClientTool节点。其中,MCP Client1被明确配置为执行executeTool操作,提供了一个名为write_file的工具,使Agent具备了执行文件写入的实际能力。
- 说明: 这种方式展示了通过自然语言指令驱动AI调用外部工具来完成任务的能力,与传统的直接节点操作形成了对比,提供了更高的灵活性。
- 节点 1: AI Agent1: 这是第二个AI Agent,其任务非常专一:根据一个简单的自然语言指令 (
4. 总结
该工作流通过将自动化流程编排与先进的AI技术相结合,实现了一个高效、端到端的解决方案。它能够自动地将海量、非结构化的网站内容转化为高度结构化的、可直接用于高级检索应用(如RAG)的知识资产,极大地提升了知识库构建的效率和质量。