
摘要
本文系统性地综述了AI智能体记忆系统的最新研究进展,提出了"形式-功能-动态"三维分类框架。研究指出记忆是基础模型驱动的智能体的核心能力,支撑长期推理、持续适应和复杂环境交互。文章深入探讨了记忆的三种主要形式、三类功能角色及其演化机制,为未来智能体研究提供了系统性的理论基础。
链接https://t.zsxq.com/u4Wqc获取原文pdf
一、引言:记忆为何成为AI智能体的核心能力
过去两年,我们见证了大语言模型(LLMs)向强大AI智能体的惊人演化。这些由基础模型驱动的智能体在深度研究、软件工程、科学发现等多个领域展现出卓越进展,不断推动人工通用智能(AGI)的发展轨迹。
在智能体的诸多能力中------推理、规划、感知、记忆和工具使用------记忆作为基石能力脱颖而出。它明确地将静态的、参数无法快速更新的LLMs转化为能够通过环境交互持续适应的智能体。从应用角度看,个性化聊天机器人、推荐系统、社会模拟和金融调查等众多领域都依赖于智能体处理、存储和管理历史信息的能力。从发展角度看,AGI研究的核心愿景之一就是赋予智能体通过环境交互持续进化的能力,而这一能力从根本上依赖于智能体记忆。
为什么需要新的分类体系?
尽管已有一些综述提供了宝贵的智能体记忆概述,但现有分类体系存在两大局限:
-
现有分类的局限性:早期分类体系在诸多方法论快速进展之前建立,无法完全反映当前研究的广度和复杂性。例如,2025年出现的新方向------从过往经验中提炼可复用工具的记忆框架,或记忆增强的测试时扩展方法------在早期分类方案中代表性不足。
-
概念碎片化:随着记忆相关研究的爆炸性增长,概念本身变得日益宽泛和碎片化。声称研究"智能体记忆"的论文在实现方式、目标和基本假设上常常截然不同。各种术语(声明性、情景性、语义性、参数化记忆等)的泛滥进一步模糊了概念清晰度。
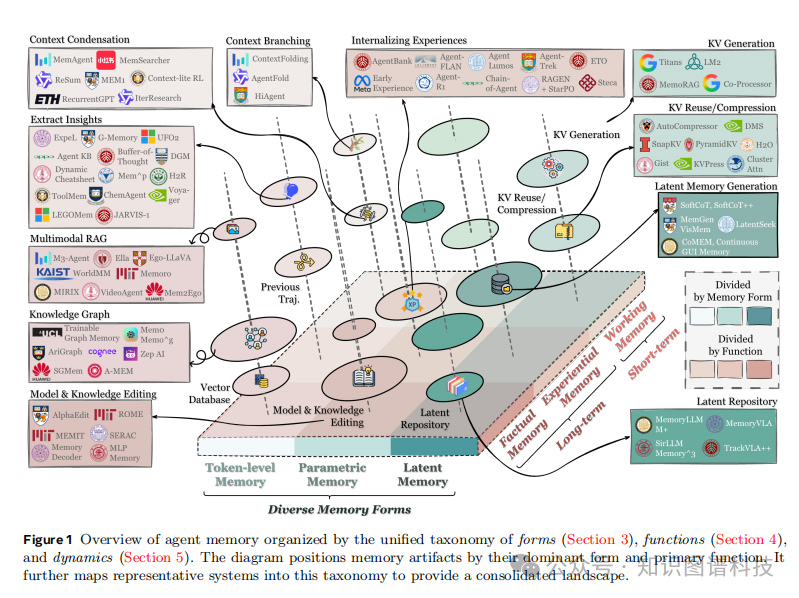
图1展示了按照"形式-功能-动态"统一分类体系组织的智能体记忆全景图,将记忆构件按其主要形式和功能定位,并映射代表性系统到此分类体系中。
二、核心概念:形式化智能体与记忆系统
2.1 基于LLM的智能体系统形式化定义
智能体与环境:设I = {1, ..., N}表示智能体的索引集,其中N=1对应单智能体情况,N>1代表多智能体设置。环境由状态空间S刻画,在每个时间步t,环境根据受控随机转移模型演化:
code
s_{t+1} ~ Ψ(s_{t+1} | s_t, a_t)每个智能体i接收观察值:
code
o_t^i = O^i(s_t, h_t^i, Q)其中h_t^i表示智能体i可见的交互历史部分,Q表示任务规范(如用户指令、目标描述)。
动作空间:LLM智能体的一个显著特征是其异构动作空间,包括:
-
自然语言生成(推理、解释、响应)
-
工具调用动作(API、搜索引擎、计算器)
-
规划动作(任务分解、执行计划)
-
环境控制动作(导航、编辑)
-
通信动作(智能体间协作)
2.2 智能体记忆系统的形式化
记忆系统表示为一个演化的记忆状态:
code
M_t ∈ M其中M表示可接受的记忆配置空间。M_t可以采取文本缓冲区、键值存储、向量数据库、图结构或任何混合表示的形式。
记忆生命周期的三大操作符:
-
记忆形成(Formation)
:
code
M_t+1^form = F(M_t, φ_t)选择性地将信息工件φ_t(工具输出、推理轨迹、部分计划等)转化为记忆候选。
-
记忆演化(Evolution)
:
code
M_{t+1} = E(M_t+1^form)将形成的记忆候选整合到现有记忆库中,可能包括合并冗余条目、解决冲突、丢弃低效用信息或重构记忆。
-
记忆检索(Retrieval)
:
code
m_t^i = R(M_t, o_t^i, Q)构建任务感知查询并返回相关记忆内容,检索到的信号m_t^i被格式化供LLM策略直接使用。
2.3 智能体记忆与相关概念的比较
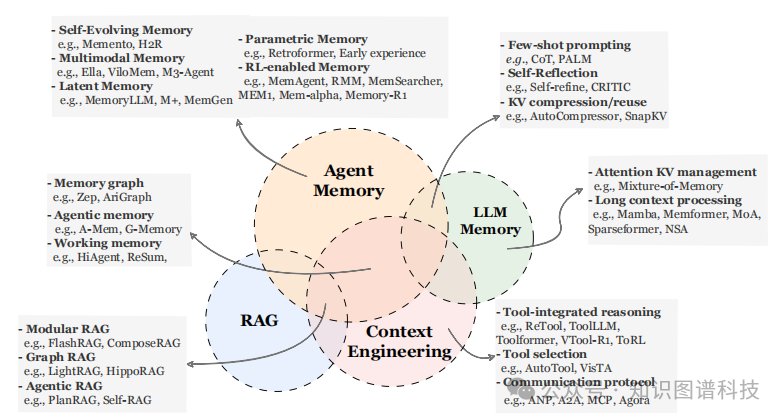
图2通过维恩图展示了智能体记忆与LLM记忆、RAG和上下文工程之间的共性与区别。
2.3.1 智能体记忆 vs. LLM记忆
从高层次看,智能体记忆几乎完全包含了传统意义上的LLM记忆。2023年以来,许多自称"LLM记忆机制"的工作在现代术语下更适合理解为早期的智能体记忆实例。这种重新诠释源于"LLM智能体"概念本身的历史模糊性。
重叠部分:
-
少样本提示可视为长期记忆形式
-
自我反思和迭代精炼对应短期任务内记忆
-
KV压缩和上下文窗口管理在单任务过程中保留显著信息时,发挥短期记忆机制作用
区别 :
直接干预模型内部状态的记忆机制------如更长有效上下文的架构修改、缓存重写策略、循环状态持久化------更适合归类为LLM记忆而非智能体记忆。它们的目标是扩展或重组底层模型的表示能力,而非为决策智能体提供可演化的外部记忆库。
2.3.2 智能体记忆 vs. RAG
在概念层面,智能体记忆和检索增强生成(RAG)表现出相当大的重叠:两者都构建、组织和利用辅助信息存储来扩展LLM/智能体的能力。然而,两个范式在历史上被应用的场景所区分。
传统区别:
-
RAG
:主要用静态知识源增强LLM,为单次推理任务服务
-
智能体记忆
:在智能体与环境的持续交互中实例化,不断将智能体自身动作和环境反馈产生的新信息纳入持久记忆库
边界模糊化 :
随着检索系统本身变得更动态,这一边界日益模糊。实际上,更现实的区分在于任务领域:
-
RAG主要应用于经典的多跳和知识密集型基准测试(HotpotQA、2WikiMQA、MuSiQue)
-
智能体记忆系统通常在需要持续多轮交互、时间依赖或环境驱动适应的场景中评估(LoCoMo、LongMemEval、GAIA、SWE-bench等)
三、记忆的形式:三种主流实现
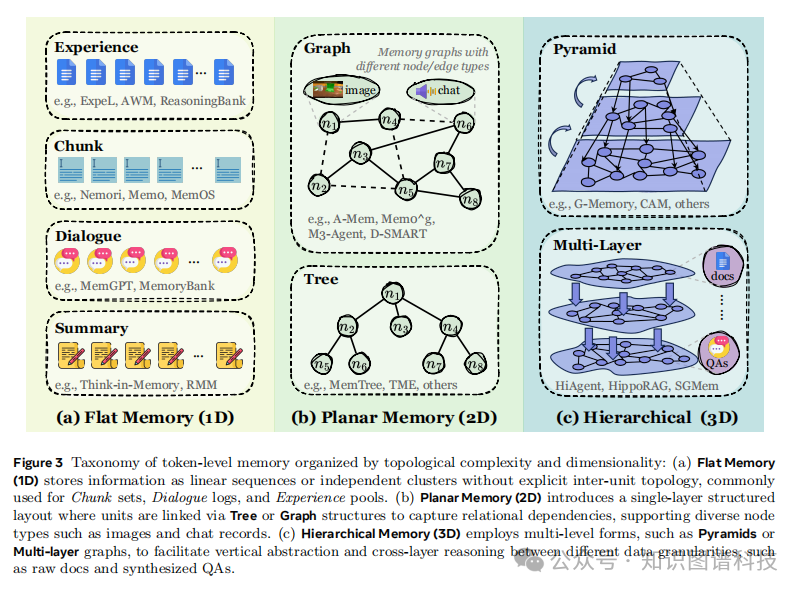
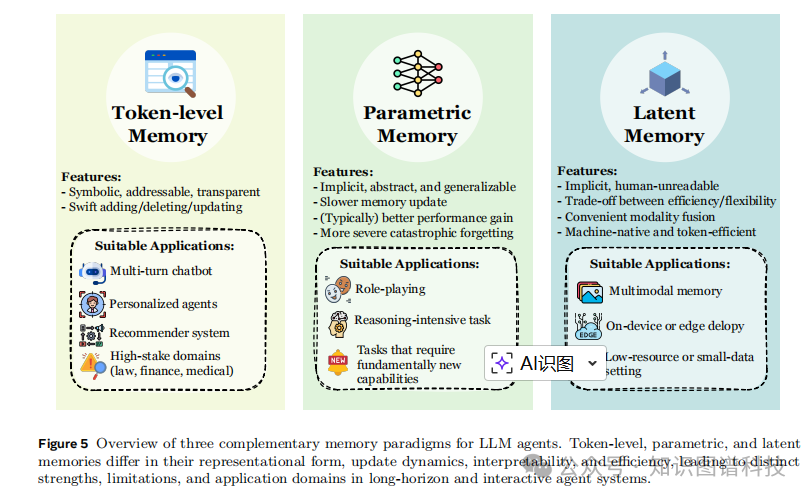
智能体记忆系统可以通过多种架构或表示形式实现。本节从形式 角度识别三种主流记忆实现:令牌级记忆 、参数化记忆 和潜在记忆。
3.1 令牌级记忆(Token-level Memory)
令牌级记忆是最直观和广泛采用的形式,它将记忆表示为可以直接注入LLM输入上下文的离散令牌序列。这种形式包括:
文本缓冲区 :最简单的实现,存储原始对话历史或交互日志
结构化文本表示 :将记忆组织为键值对、列表或层次结构
向量数据库 :使用语义嵌入进行高效检索
知识图谱:以图结构表示实体关系和事实知识
优势:
-
实现简单,易于理解和调试
-
与现有LLM架构无缝集成
-
支持灵活的检索和更新策略
局限:
-
受上下文窗口限制
-
大规模存储的计算成本高
-
难以捕获隐式知识模式
3.2 参数化记忆(Parametric Memory)
参数化记忆通过直接更新模型参数来存储信息,使记忆成为模型权重的一部分。这种方法包括:
持续学习 :通过在新数据上微调来更新模型知识
参数高效调优 :使用LoRA、Adapter等技术进行局部参数更新
记忆增强架构:专门设计用于动态参数更新的模型结构
优势:
-
不占用推理时的上下文窗口
-
可以编码复杂的隐式知识
-
推理效率高
局限:
-
更新成本高,需要重新训练
-
容易发生灾难性遗忘
-
难以追踪和解释特定记忆
3.3 潜在记忆(Latent Memory)
潜在记忆在令牌级和参数化记忆之间提供了一个中间方案,通过学习的潜在表示来编码记忆状态。这包括:
连续向量状态 :将记忆表示为可学习的向量
记忆增强注意力 :通过专门的注意力机制访问记忆
神经记忆网络:使用神经网络模块显式建模记忆操作
优势:
-
比参数化记忆更灵活
-
比令牌级记忆更紧凑
-
可以通过端到端训练优化
局限:
-
实现复杂度高
-
可解释性较差
-
需要专门的训练策略
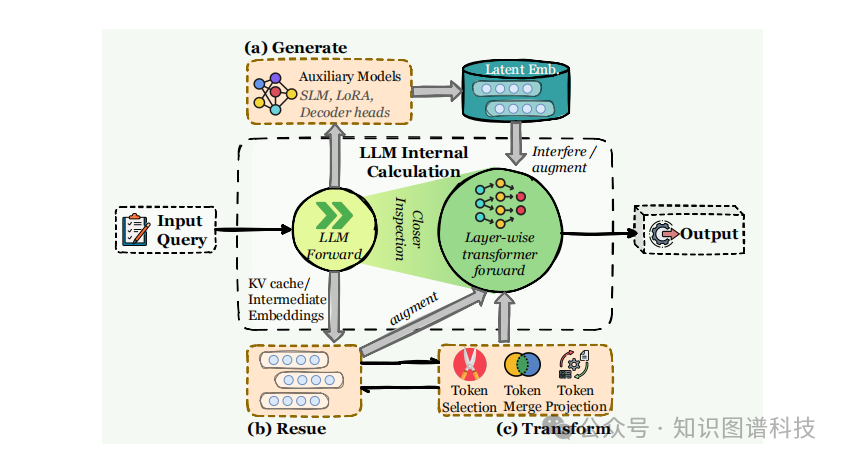
四、记忆的功能:超越时间维度的分类
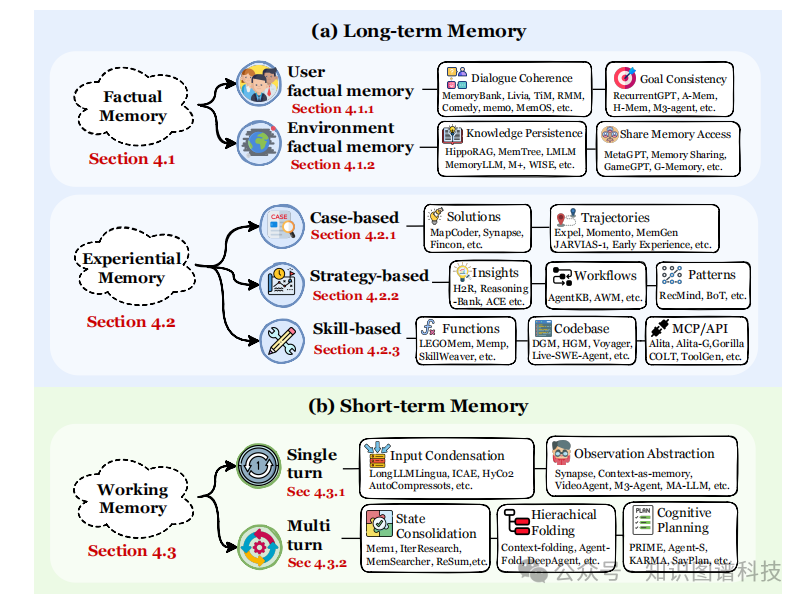
传统的长期/短期记忆分类已不足以捕捉当代智能体记忆系统的多样性。本节提出更细粒度的功能分类,区分事实记忆 、经验记忆 和工作记忆。
4.1 事实记忆(Factual Memory)
事实记忆记录智能体与用户和环境交互中的知识,包括:
用户偏好和画像 :个性化信息、兴趣、习惯
世界知识 :从交互中学习的事实、规则、约束
关系网络:实体间的关系和属性
应用场景:
-
个性化推荐系统
-
长期对话系统
-
知识图谱构建
关键挑战:
-
知识更新和一致性维护
-
隐私保护和数据安全
-
跨领域知识迁移
4.2 经验记忆(Experiential Memory)
经验记忆通过任务执行逐步增强智能体的问题解决能力,包括:
成功案例库 :存储有效的解决方案和策略
失败经验 :记录错误和避免策略
工具使用经验:积累工具调用模式和效果
应用场景:
-
软件开发智能体
-
复杂任务规划
-
持续学习系统
关键挑战:
-
经验泛化能力
-
过拟合特定任务
-
负面经验的有效利用
4.3 工作记忆(Working Memory)
工作记忆管理单个任务实例执行期间的工作空间信息,包括:
中间推理状态 :思维链、推理步骤
子目标跟踪 :任务分解和进度监控
临时变量:计算过程中的中间结果
应用场景:
-
多步推理任务
-
复杂问题分解
-
交互式任务执行
关键挑战:
-
工作空间容量限制
-
信息选择和遗忘策略
-
与长期记忆的协调
五、记忆的动态机制:形成、检索与演化
记忆不是静态的存储,而是动态演化的系统。本节分析记忆如何随时间形成、检索和演化。
5.1 记忆形成
记忆形成决定哪些信息值得保留,包括:
选择性编码 :过滤噪声,提取关键信息
抽象与总结 :将详细交互压缩为可复用知识
结构化组织:将记忆组织为便于检索的结构
技术方法:
-
基于重要性的采样
-
自动摘要和提炼
-
层次化记忆组织
5.2 记忆检索
高效的记忆检索对智能体性能至关重要,包括:
语义检索 :基于相似度的向量搜索
结构化查询 :在知识图谱上的遍历
上下文感知检索:根据当前任务动态选择相关记忆
优化策略:
-
多模态检索融合
-
重排序和精炼
-
检索结果的压缩
5.3 记忆演化
记忆系统需要持续演化以保持有效性,包括:
知识整合 :合并新旧记忆,解决冲突
遗忘机制 :删除过时或低价值信息
重组优化:重构记忆结构提高效率
关键技术:
-
增量更新算法
-
冲突检测与解决
-
自适应遗忘策略
六、资源与工具:基准测试与开源框架
6.1 代表性基准测试
长上下文对话评估:
-
LoCoMo:长期对话记忆评估
-
LongMemEval:长期记忆评估基准
复杂问题解决:
-
GAIA:通用AI助手基准
-
XBench:跨领域能力测试
-
BrowseComp:浏览和信息综合
代码智能体任务:
- SWE-bench Verified:软件工程基准
持续学习:
- StreamBench:流式学习基准
6.2 开源框架
目前多个开源框架支持智能体记忆系统的开发和部署,为研究者和开发者提供了便利的工具。这些框架通常提供:
-
记忆存储和管理接口
-
检索算法实现
-
向量数据库集成
-
多智能体协调机制
代表性框架:
LangChain/LangGraph :提供灵活的记忆模块和链式调用接口,支持多种记忆后端
MemGPT :专注于虚拟上下文管理,模拟操作系统级记忆层次
AutoGen :微软开发的多智能体框架,内置对话历史管理
ChatDev :面向软件开发的智能体框架,集成项目级记忆
Semantic Kernel:微软的企业级框架,支持插件化记忆系统
这些框架降低了实现复杂记忆机制的门槛,加速了从研究原型到实际应用的转化。
七、未来方向与挑战
7.1 技术挑战
可扩展性:随着交互时长增加,记忆规模呈指数增长,如何高效检索和压缩历史信息成为关键瓶颈。
一致性维护:跨会话、跨模态的记忆同步困难,容易产生矛盾信息。
隐私与安全:长期记忆存储涉及敏感数据,需要强化加密和访问控制机制。
遗忘机制:如何智能地淘汰过时或无关信息,避免记忆污染。
7.2 研究方向
神经符号融合:结合神经网络的泛化能力与符号系统的推理能力
终身学习:使智能体能够持续从交互中学习,动态更新知识库
情景记忆增强:模拟人类情景记忆机制,提升上下文理解深度
多模态记忆整合:统一处理文本、图像、音频等多源信息
个性化记忆建模:根据用户特征定制记忆策略,提升交互体验
分布式记忆架构:探索多智能体间的协同记忆共享机制
7.3 应用前景
个人助理进化:从被动响应到主动预测用户需求
教育领域变革:智能导师系统能追踪学习轨迹,提供个性化辅导
医疗健康管理:长期记录患者信息,辅助诊断和治疗决策
企业知识管理:构建组织级记忆系统,沉淀业务经验
八、结论
AI智能体的记忆系统正从简单的上下文缓存演进为复杂的认知架构。通过短期、长期、工作记忆的协同,智能体获得了类人的连续性和适应性。当前的技术突破虽然令人鼓舞,但距离真正的通用人工智能仍有距离。未来的研究需要在效率、可解释性和伦理规范间寻求平衡。
随着Transformer架构的持续优化、检索增强技术的成熟,以及神经符号方法的融合,记忆系统将成为智能体突破当前能力边界的关键突破口。我们有理由相信,具备完善记忆机制的AI智能体将在更多领域展现出接近甚至超越人类的认知能力,推动人机协作进入新纪元。
欢迎加入「知识图谱增强大模型产学研」知识星球,获取最新产学研相关"知识图谱+大模型"相关论文、政府企业落地案例、避坑指南、电子书、文章等,行业重点是医疗护理、医药大健康、工业能源制造领域,也会跟踪AI4S科学研究相关内容,以及Palantir、OpenAI、微软、Writer、Glean、OpenEvidence等相关公司进展。