(十)自然语言处理笔记------基于Bert的文本分类的项目
- 实验数据集介绍:
- 实验1:基于Bert的文本分类项目
- [实验2:基于Bert + TextCNN 的文本分类项目](#实验2:基于Bert + TextCNN 的文本分类项目)
- [实验3:基于Bert + BiLSTM的文本分类项目](#实验3:基于Bert + BiLSTM的文本分类项目)
- [实验4:基于Bert + RCNN的文本分类项目](#实验4:基于Bert + RCNN的文本分类项目)
- [实验5:基于Bert + DPCNN的文本分类项目](#实验5:基于Bert + DPCNN的文本分类项目)
实验数据集介绍:
本博文采用的文本分类数据集主要包含七个类别,依次如下:
| 英文 | 中文 |
|---|---|
| finance | 财经 / 金融 |
| realty | 房地产 |
| stocks | 股票 |
| education | 教育 |
| science | 科学 |
| society | 社会 |
| politics | 政治 |
| sports | 体育 |
| game | 游戏 |
| entertainment | 娱乐 |
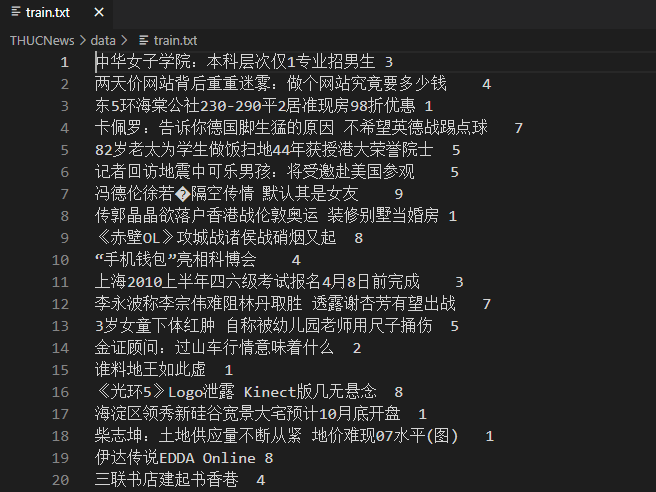
实验1:基于Bert的文本分类项目
模型结构:BERT + 全连接分类头

python
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""
配置参数
"""
def __init__(self, dataset):
self.model_name = 'BruceBert'
# 训练集
self.train_path = dataset + '/data/train.txt'
# 测试集
self.test_path = dataset + '/data/test.txt'
# 校验集
self.dev_path = dataset + '/data/dev.txt'
# dataset
self.datasetpkl = dataset + '/data/dataset.pkl'
# 类别
self.class_list = [ x.strip() for x in open(dataset + '/data/class.txt').readlines()]
#模型训练结果
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
# 设备配置
self.device = torch.device( 'cuda' if torch.cuda.is_available() else 'cpu')
# 若超过1000bacth效果还没有提升,提前结束训练
self.require_improvement = 1000
# 类别数
self.num_classes = len(self.class_list)
# epoch数
self.num_epochs = 200 # 训练轮次
# batch_size
self.batch_size = 512 # 批次数目
# 每句话处理的长度(短填,长切)
self.pad_size = 32
# 学习率
self.learning_rate = 1e-5
# bert预训练模型位置
self.bert_path = 'bert_pretrain'
# bert切词器
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
# bert隐层层个数
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True # 是否进行微调,微调:true;不微调:false
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
# x [ids, seq_len, mask]
context = x[0] #对应输入的句子 shape[128,32] [batch_size,序列长度]
mask = x[2] #对padding部分进行mask shape[128,32]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False) #shape [128,768]
out = self.fc(pooled) # shape [128,10]
return out
python
Input IDs (batch_size, seq_len)
│
├── Attention Mask (batch_size, seq_len)
│
▼
┌─────────────────────────────┐
│ BERT Encoder │
│ - Embedding + Transformer │
│ - 输出隐藏状态 & CLS池化 │
└─────────────────────────────┘
│
▼
pooled_output (CLS)
(batch_size, 768)
│
▼
┌─────────────────────────────┐
│ Linear 全连接层 │
│ Linear(768 → num_classes) │
└─────────────────────────────┘
│
▼
logits (batch_size, num_classes)测试结果:
python
Test Loss: 0.32, Test Acc:90.42%
Precision, Recall and F1-Score
precision recall f1-score support
finance 0.8613 0.9070 0.8836 1000
realty 0.9127 0.9310 0.9218 1000
stocks 0.8348 0.8390 0.8369 1000
education 0.9603 0.9180 0.9387 1000
science 0.8918 0.8080 0.8478 1000
society 0.8974 0.9010 0.8992 1000
politics 0.8900 0.8820 0.8860 1000
sports 0.9623 0.9710 0.9667 1000
game 0.9180 0.9520 0.9347 1000
entertainment 0.9156 0.9330 0.9242 1000
accuracy 0.9042 10000
macro avg 0.9044 0.9042 0.9040 10000
weighted avg 0.9044 0.9042 0.9040 10000
Confusion Maxtrix
[[907 15 49 3 5 4 10 2 0 5]
[ 16 931 16 1 3 11 5 6 3 8]
[ 73 28 839 0 26 2 21 4 5 2]
[ 6 3 1 918 8 26 17 2 5 14]
[ 16 10 52 3 808 20 18 1 52 20]
[ 7 15 6 13 8 901 25 3 10 12]
[ 19 7 28 10 14 23 882 3 3 11]
[ 1 2 3 1 2 3 5 971 1 11]
[ 0 3 9 3 23 2 3 2 952 3]
[ 8 6 2 4 9 12 5 15 6 933]]实验2:基于Bert + TextCNN 的文本分类项目
TextCNN 结构详解:
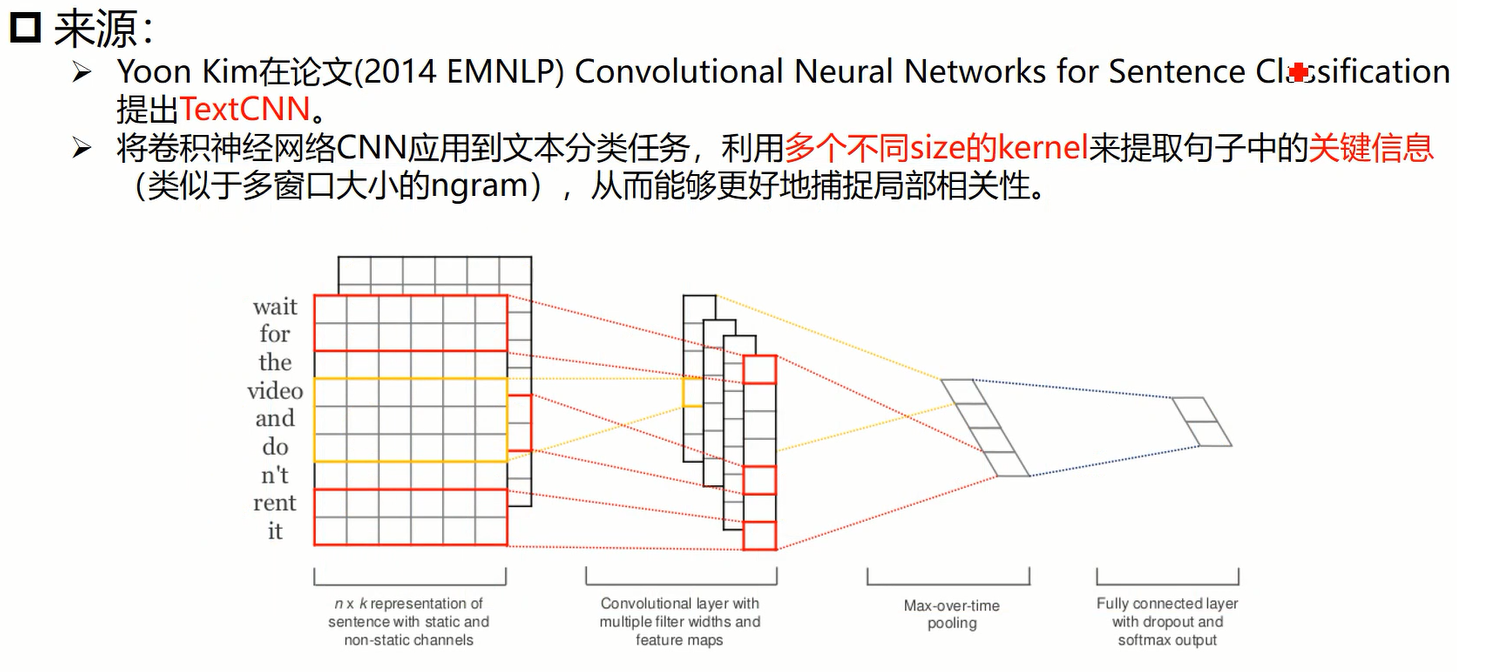

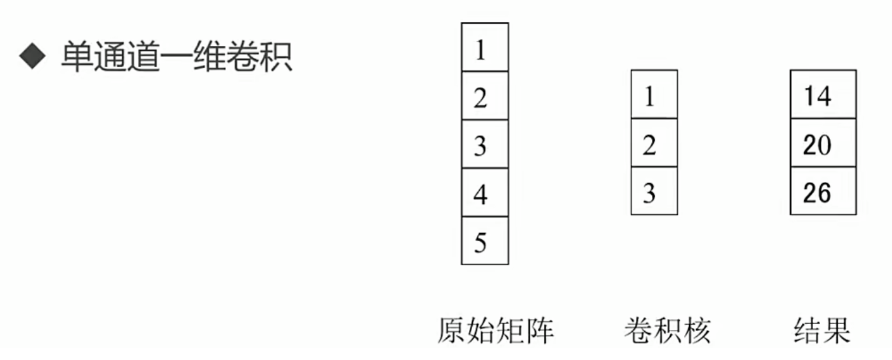
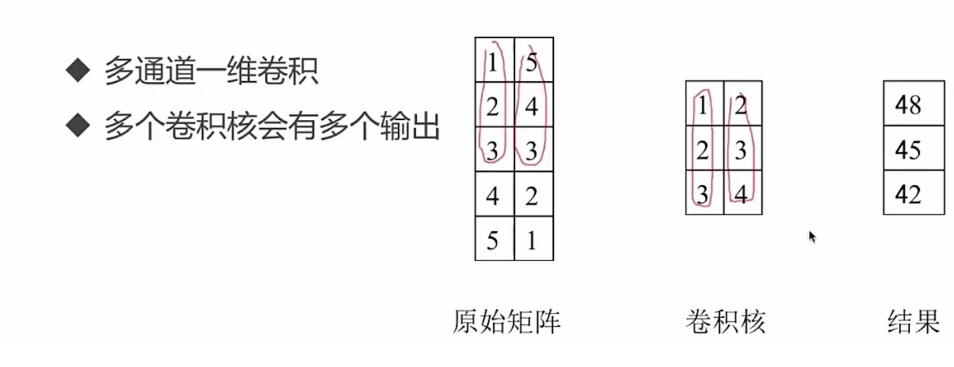

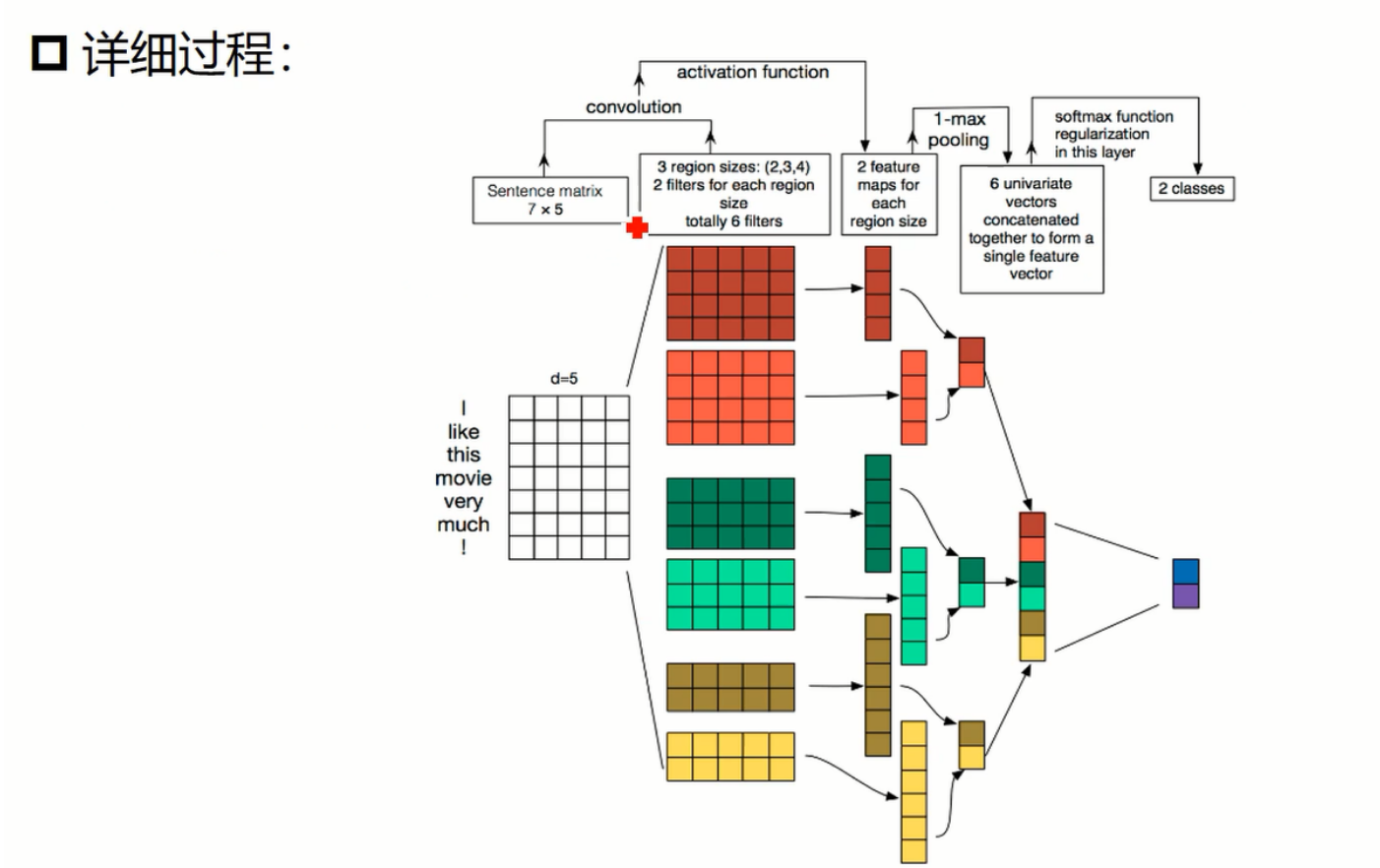
模型结构:

python
Input IDs (batch, seq_len)
Attention Mask
│
▼
┌─────────────────────────────┐
│ BERT │
│ 输出 token embeddings │
│ (batch, seq_len, 768) │
└─────────────────────────────┘
│
▼
unsqueeze(1)
(batch, 1, seq_len, 768)
│
▼
┌───────────────┬───────────────┬───────────────┐
│ Conv2d k=2 │ Conv2d k=3 │ Conv2d k=4 │
│ (1→256) │ (1→256) │ (1→256) │
└───────────────┴───────────────┴───────────────┘
│
▼
ReLU + MaxPool1d
│
▼
(每路输出: batch, 256)
│
▼
Concatenate
(batch, 256×3 = 768)
│
▼
Dropout
│
▼
Linear → 分类
(batch, num_classes)
python
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
# 模型名称
self.model_name="BruceBertCNN"
# 训练集
self.train_path = dataset + '/data/train.txt'
# 校验集
self.dev_path = dataset + '/data/dev.txt'
# 测试集
self.test_path = dataset + '/data/test.txt'
#dataset
self.datasetpkl = dataset + '/data/dataset.pkl'
# 类别名单
self.class_list = [ x.strip() for x in open(dataset + '/data/class.txt').readlines()]
#模型保存路径
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
# 运行设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 若超过1000bacth效果还没有提升,提前结束训练
self.require_improvement= 1000
# 类别数量
self.num_classes = len(self.class_list)
# epoch数
self.num_epochs = 200
# batch_size
self.batch_size = 512
# 序列长度
self.pad_size = 32
# 学习率
self.learning_rate = 1e-5
# 预训练位置
self.bert_path = './bert_pretrain'
# bert的 tokenizer
self.tokenizer = BertTokenizer.from_pretrained((self.bert_path))
# Bert的隐藏层数量
self.hidden_size = 768
# 卷积核尺寸
self.filter_sizes = (2,3,4)
# 卷积核数量
self.num_filters = 256
# droptout
self.dropout = 0.5
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True # 是否进行微调:微调:True,不微调:False
self.convs = nn.ModuleList(
[nn.Conv2d(in_channels=1, out_channels=config.num_filters, kernel_size=(k, config.hidden_size)) for k in config.filter_sizes]
)
self.droptout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes) # 其其之前经过一次 torch.cat 操作
def conv_and_pool(self, x, conv):
x = conv(x) # (批次数,1,32,768)---->(批次数,256,31,1)
x = F.relu(x)
x = x.squeeze(3) # (批次数,256,31,1) ---->(批次数,256,31)
size = x.size(2) # torch.Size([512, 256, 31]) size=31
x = F.max_pool1d(x, size) # torch.Size([512, 256, 31])------> torch.Size([512, 256, 1])
x = x.squeeze(2) # torch.Size([512, 256])
return x
def forward(self, x):
# x [ids, seq_len, mask]
context = x[0] #对应输入的句子 shape[128,32]
mask = x[2] #对padding部分进行mask shape[128,32]
encoder_out, pooled = self.bert(context, attention_mask = mask, output_all_encoded_layers = False) #shape [128,768]
out = encoder_out.unsqueeze(1) # 增加了一个通道的维度 shape由【批次数,序列长度,嵌入维度数】变为【批次数,通道数(1),序列长度,嵌入维度数】
out = torch.cat([self.conv_and_pool(out, conv)for conv in self.convs], 1) # 经过三次拼接后 shape变为torch.Size([512, 768])
out = self.droptout(out)
out = self.fc(out)
return out # 【批次数,类别数】
"""
nn.Conv2d(
in_channels=1,
out_channels=config.num_filters, # 例如 256
kernel_size=(k, config.hidden_size) # (k, 768)
)
假设:
config.hidden_size = 768(BERT-base)
k 是某个 filter size,比如 k = 2, 3, 4
stride = 1(默认)
padding = 0(默认)
dilation = 1(默认)
| k | 输出高度 |
| - | ---- |
| 2 | 31 |
| 3 | 30 |
| 4 | 29 |
你注释里的 31,说明这一层用的是:
k=2
归纳一下,就是二维卷积输出计算公式
nn.Conv2d(in_channels=1, out_channels=config.num_filters, kernel_size=(k, config.hidden_size))
"""
python
Test Loss: 0.3, Test Acc:90.34%
Precision, Recall and F1-Score
precision recall f1-score support
finance 0.9180 0.8620 0.8891 1000
realty 0.9083 0.9310 0.9195 1000
stocks 0.8429 0.8260 0.8343 1000
education 0.9464 0.9360 0.9412 1000
science 0.8457 0.8440 0.8448 1000
society 0.8701 0.9240 0.8962 1000
politics 0.8866 0.8760 0.8813 1000
sports 0.9836 0.9620 0.9727 1000
game 0.9222 0.9360 0.9290 1000
entertainment 0.9133 0.9370 0.9250 1000
accuracy 0.9034 10000
macro avg 0.9037 0.9034 0.9033 10000
weighted avg 0.9037 0.9034 0.9033 10000
Confusion Maxtrix
[[862 21 68 5 9 12 14 1 3 5]
[ 10 931 11 4 8 15 5 1 4 11]
[ 47 29 826 1 51 7 29 3 4 3]
[ 1 1 1 936 7 25 12 1 3 13]
[ 2 9 40 6 844 23 15 1 40 20]
[ 1 11 1 13 8 924 19 0 10 13]
[ 9 12 27 13 17 28 876 1 5 12]
[ 1 2 2 3 5 7 10 962 0 8]
[ 2 4 3 4 37 5 3 2 936 4]
[ 4 5 1 4 12 16 5 6 10 937]]
使用时间: 0:00:05
Test Loss: 0.3, Test Acc:90.34%实验3:基于Bert + BiLSTM的文本分类项目

python
Input IDs (batch, seq_len)
Attention Mask
│
▼
┌──────────────────────────────┐
│ BERT │
│ token embeddings │
│ (batch, seq_len, 768) │
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ BiLSTM (2 layers) │
│ hidden_size = 256 × 2 │
│ (batch, seq_len, 512) │
└──────────────────────────────┘
│
▼
Take last time step
(batch, 512)
│
▼
Dropout
│
▼
Linear → 分类
(batch, num_classes)
python
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
# 模型名称
self.model_name = "BruceBertRNN"
# 训练集
self.train_path = dataset + '/data/train.txt'
# 校验集
self.dev_path = dataset + '/data/dev.txt'
# 测试集
self.test_path = dataset + '/data/test.txt'
# dataset
self.datasetpkl = dataset + '/data/dataset.pkl'
# 类别名单
self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]
# 模型保存路径
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
# 运行设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 若超过1000bacth效果还没有提升,提前结束训练
self.require_improvement = 1000
# 类别数量
self.num_classes = len(self.class_list)
# epoch数
self.num_epochs = 200
# batch_size
self.batch_size = 128
# 序列长度
self.pad_size = 32
# 学习率
self.learning_rate = 1e-5
# 预训练位置
self.bert_path = './bert_pretrain'
# bert的 tokenizer
self.tokenizer = BertTokenizer.from_pretrained((self.bert_path))
# Bert的隐藏层数量
self.hidden_size = 768
# RNN隐层层数量
self.rnn_hidden = 256
# rnn数量
self.num_layers = 2
# droptout
self.dropout = 0.5
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm = nn.LSTM(config.hidden_size, config.rnn_hidden, config.num_layers, batch_first=True, dropout=config.dropout, bidirectional=True) # nn.LSTM(输入特征维度,输出特征维度,隐藏层数)
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.rnn_hidden * 2, config.num_classes) # config.rnn_hidden * 2:因为是双向的LSTM
def forward(self,x):
# x [ids, seq_len, mask]
context = x[0] # 对应输入的句子 shape[128,32]
mask = x[2] # 对padding部分进行mask shape[128,32]
encoder_out, text_cls = self.bert(context, attention_mask = mask, output_all_encoded_layers = False)
out, _ = self.lstm(encoder_out)
out = self.dropout(out)
out = out[:,-1,:] # 是提取每个样本序列最后一个时间步的输出 【批次,序列长度,数据维度】
out = self.fc(out)
return out实验4:基于Bert + RCNN的文本分类项目
BERT + BiLSTM + MaxPool(RCNN 思想) 的文本分类模型。它融合了 上下文建模(BERT)+ 序列建模(RNN)+ 全局池化(CNN/RCNN)

python
Input IDs + Attention Mask
│
▼
┌──────────────────────────────┐
│ BERT │
│ (batch, seq_len, 768) │
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ BiLSTM (2 layers) │
│ (batch, seq_len, 512) │
└──────────────────────────────┘
│
▼
ReLU
(batch, seq_len, 512)
│
▼
Permute → (batch, 512, seq_len)
│
▼
MaxPool1d (kernel = seq_len)
(batch, 512, 1)
│
▼
Squeeze
(batch, 512)
│
▼
Linear → 分类
(batch, num_classes)
python
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 微信公众号 AI壹号堂 欢迎关注
# Author 杨博
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
# 模型名称
self.model_name = "BruceBertRCNN"
# 训练集
self.train_path = dataset + '/data/train.txt'
# 校验集
self.dev_path = dataset + '/data/dev.txt'
# 测试集
self.test_path = dataset + '/data/test.txt'
# dataset
self.datasetpkl = dataset + '/data/dataset.pkl'
# 类别名单
self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]
# 模型保存路径
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
# 运行设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 若超过1000bacth效果还没有提升,提前结束训练
self.require_improvement = 1000
# 类别数量
self.num_classes = len(self.class_list)
# epoch数
self.num_epochs = 200
# batch_size
self.batch_size = 512
# 序列长度
self.pad_size = 32
# 学习率
self.learning_rate = 1e-5
# 预训练位置
self.bert_path = './bert_pretrain'
# bert的 tokenizer
self.tokenizer = BertTokenizer.from_pretrained((self.bert_path))
# Bert的隐藏层数量
self.hidden_size = 768
# RNN隐层层数量
self.rnn_hidden = 256
# rnn数量
self.num_layers = 2
# droptout
self.dropout = 0.5
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.lstm = nn.LSTM(config.hidden_size, config.rnn_hidden, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.rnn_hidden*2, config.num_classes)
def forward(self, x):
context = x[0]
mask = x[2]
encoder_out, text_cls = self.bert(context, attention_mask = mask, output_all_encoded_layers=False)
out, _ = self.lstm(encoder_out)
out = F.relu(out)
out = out.permute(0,2,1)
out = self.maxpool(out)
out = out.squeeze()
out = self.fc(out)
return out实验5:基于Bert + DPCNN的文本分类项目
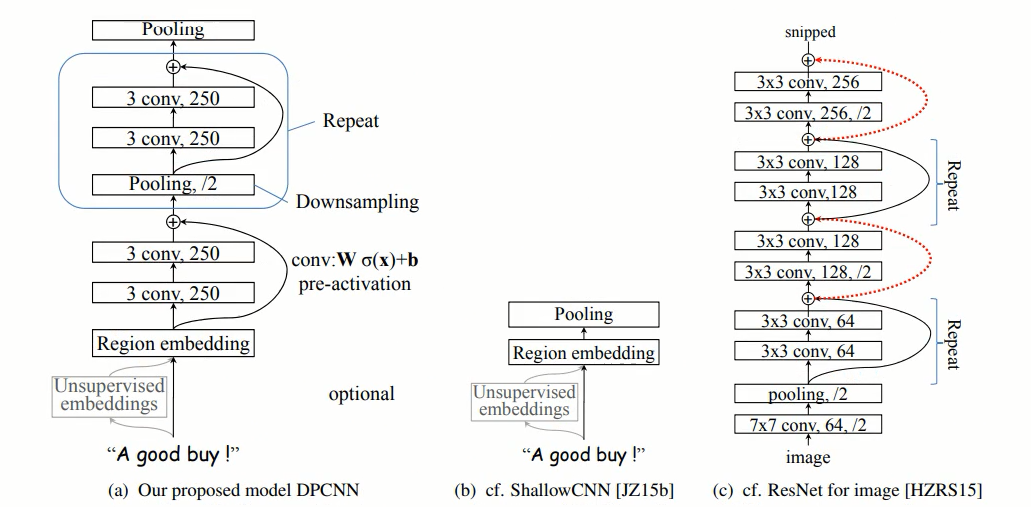
python
输入文本 token ids [batch, seq_len]
│
▼
BERT 编码层
encoder_out: [batch, seq_len, hidden_size=768]
│
▼
unsqueeze -> [batch, 1, seq_len, hidden_size]
│
▼
conv_region (3xhidden_size, out_channels=250)
输出: [batch, 250, seq_len-3+1, 1]
│
▼
padd1 + ReLU
│
▼
conv (3x1)
│
▼
padd1 + ReLU
│
▼
conv (3x1)
│
▼
while seq_len > 2:
_block:
┌───────────────┐
│ padding │
│ max_pool (3x1)│
│ conv → ReLU │
│ conv → ReLU │
│ + 残差连接(px) │
└───────────────┘
│
▼
squeeze -> [batch, num_filters=250]
│
▼
全连接层 fc
│
▼
输出 logits [batch, num_classes]
python
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 微信公众号 AI壹号堂 欢迎关注
# Author 杨博
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
# 模型名称
self.model_name = "BruceBertDPCNN"
# 训练集
self.train_path = dataset + '/data/train.txt'
# 校验集
self.dev_path = dataset + '/data/dev.txt'
# 测试集
self.test_path = dataset + '/data/test.txt'
# dataset
self.datasetpkl = dataset + '/data/dataset.pkl'
# 类别名单
self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]
# 模型保存路径
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
# 运行设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 若超过1000bacth效果还没有提升,提前结束训练
self.require_improvement = 1000
# 类别数量
self.num_classes = len(self.class_list)
# epoch数
self.num_epochs = 3
# batch_size
self.batch_size = 128
# 序列长度
self.pad_size = 32
# 学习率
self.learning_rate = 1e-5
# 预训练位置
self.bert_path = './bert_pretrain'
# bert的 tokenizer
self.tokenizer = BertTokenizer.from_pretrained((self.bert_path))
# Bert的隐藏层数量
self.hidden_size = 768
# RNN隐层层数量
self.rnn_hidden = 256
# 卷积核数量
self.num_filters = 250
# droptout
self.dropout = 0.5
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.hidden_size))
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1))
self.max_pool = nn.MaxPool2d(kernel_size=(3,1), stride=2)
self.padd1 = nn.ZeroPad2d((0,0,1,1))
self.padd2 = nn.ZeroPad2d((0,0,0,1))
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x):
context = x[0]
mask = x[2]
encoder_out, text_cls = self.bert(context, attention_mask = mask, output_all_encoded_layers = False)
out = encoder_out.unsqueeze(1) #[batch_size, 1, seq_len, embed]
out = self.conv_region(out) #[batch_size, 250, seq_len-3+1, 1]
out = self.padd1(out) #[batch_size, 250, seq_len,1]
out = self.relu(out)
out = self.conv(out) #[batch_size, 250, seq_len-3+1,1]
out = self.padd1(out) # [batch_size, 250, seq_len,1]
out = self.relu(out)
out = self.conv(out) # [batch_size, 250, seq_len-3+1,1]
while out.size()[2] > 2:
out = self._block(out)
out = out.squeeze()
out = self.fc(out)
return out
def _block(self, x):
x = self.padd2(x)
px = self.max_pool(x)
x = self.padd1(px)
x = self.relu(x)
x = self.conv(x)
x = self.padd1(x)
x = self.relu(x)
x = self.conv(x)
x = x + px
return x