文章目录
- 一、基础知识
-
- (1) Transformer架构核心组件解析
- (2) 参数高效微调方法原理与选择
- (3) 模型压缩技术实现步骤
- (4) 缓解大模型"幻觉"问题的方法
- (5) 专业领域语料构建与增强
- 二、逻辑思维
-
- (1) 数字序列推理
- (2) 绳子计时问题
- (3) 数字填空游戏
- 三、项目实例:个性化学习助手设计
-
- (1) 需求分析过程
- (2) 模型架构设计
- (3) 数据处理与隐私保护
- (4) 训练策略
- (5) 风险分析与应对
一、基础知识
(1) Transformer架构核心组件解析
核心组件:
-
Self-Attention(自注意力机制):通过计算序列中每个位置与其他位置的关联度,捕捉长距离依赖关系。公式为:Attention(Q,K,V)=softmax(QK^T/√d_k)V
-
FFN(前馈神经网络):每个位置独立经过两层全连接层(通常中间维度扩大4倍),提供非线性变换能力
-
LayerNorm(层归一化):对每个样本的特征维度进行归一化,稳定训练过程
训练与推理阶段差异:
- 训练阶段:使用完整的自注意力矩阵,采用Teacher Forcing方式,可以并行计算整个序列
- 推理阶段:通常使用自回归生成,每次只计算当前位置与之前位置的注意力,需要缓存之前的K、V以提升效率
(2) 参数高效微调方法原理与选择
原理:
- LoRA(Low-Rank Adaptation):在Transformer层的权重矩阵旁添加低秩分解的适配矩阵,仅训练适配参数
- Adapter:在FFN层后插入小型全连接层,仅训练Adapter参数
- Prompt Tuning:在输入层添加可学习的提示向量,通过提示引导模型输出
业务场景选择:
- 数据稀缺场景:优先选择Prompt Tuning或Adapter,参数更新量最小
- 需要较大能力调整:选择LoRA,平衡效果与参数效率
- 多任务学习:Adapter适合任务间的参数隔离
- 部署资源受限:Prompt Tuning最轻量,几乎不增加推理成本
(3) 模型压缩技术实现步骤
知识蒸馏步骤:
- 训练一个大型教师模型(Teacher Model)到收敛
- 准备相同训练数据,用教师模型生成软标签(soft labels)
- 训练小型学生模型(Student Model),损失函数包含:
· 硬标签交叉熵损失(真实标签)
· 软标签KL散度损失(教师输出)
· 有时加入中间层特征匹配损失 - 逐步微调学生模型
量化步骤:
- 训练后量化(Post-training Quantization):
· 在校准集上统计权重和激活值的范围
· 将FP32权重映射到INT8(线性或对称量化)
· 可选:进行量化感知训练微调 - 量化感知训练(Quantization-aware Training):
· 在前向传播中模拟量化效果(添加伪量化节点)
· 反向传播时使用直通估计器(Straight-through Estimator)
· 保持模型在量化后仍保持高精度
(4) 缓解大模型"幻觉"问题的方法
Prompt工程方法:
- Few-shot Prompting:提供领域相关的示例,引导模型遵循正确模式
- 思维链(Chain-of-Thought):要求模型展示推理步骤,便于检查和纠正
- 自我验证提示:让模型生成后自我检查一致性
- 检索增强生成(RAG):结合外部知识库,确保信息准确性
数据增强方法:
- 合成数据生成:使用可靠数据生成问答对,增强训练数据
- 对抗性训练:故意注入错误信息,训练模型识别并拒绝
- 强化学习从人类反馈(RLHF):通过人类偏好评分优化模型输出质量
(5) 专业领域语料构建与增强
高质量语料构建:
- 多源数据采集:学术论文、专业书籍、权威网站、行业报告
- 质量过滤:
· 基于规则的过滤(去除低质文本)
· 基于模型的过滤(使用质量分类器)
· 去重与去噪处理 - 格式标准化:统一文本编码、清理HTML/XML标记、规范化术语
数据稀缺问题的增强方法(以涉外法律文书为例):
- 跨语言知识迁移:利用多语言模型和翻译系统,从其他语言法律文档中获取知识
- 模板生成:基于现有文书创建模板,生成结构相似的新文档
- 领域自适应预训练:在通用预训练基础上,使用领域数据继续预训练
- 专家协同标注:设计半自动标注流程,结合专家知识和模型预标注
二、逻辑思维
(1) 数字序列推理
序列: 1, 3, 11, 41, 153, (?)
解析:
观察相邻数字关系:
· 3 = 1×4 - 1
· 11 = 3×4 - 1
· 41 = 11×4 - 3
· 153 = 41×4 - 11
发现规律:aₙ = 4×aₙ₋₁ - aₙ₋₂(从第三项开始)
验证:
· 11 = 4×3 - 1
· 41 = 4×11 - 3
· 153 = 4×41 - 11
因此下一个数:4×153 - 41 = 612 - 41 = 571
答案: 571
(2) 绳子计时问题
问题: 烧一根粗细不均匀的绳子需要1小时,如何用若干绳子实现计时45分钟?
解决方案:
- 准备两根相同的绳子A和B
- 同时点燃绳子A的两端和绳子B的一端
- 当绳子A完全烧完时(此时过去了30分钟),立即点燃绳子B的另一端
- 绳子B剩下的部分将在15分钟内烧完
- 总时间:30分钟 + 15分钟 = 45分钟
原理: 绳子从两端同时燃烧的时间是从一端燃烧时间的一半。
(3) 数字填空游戏
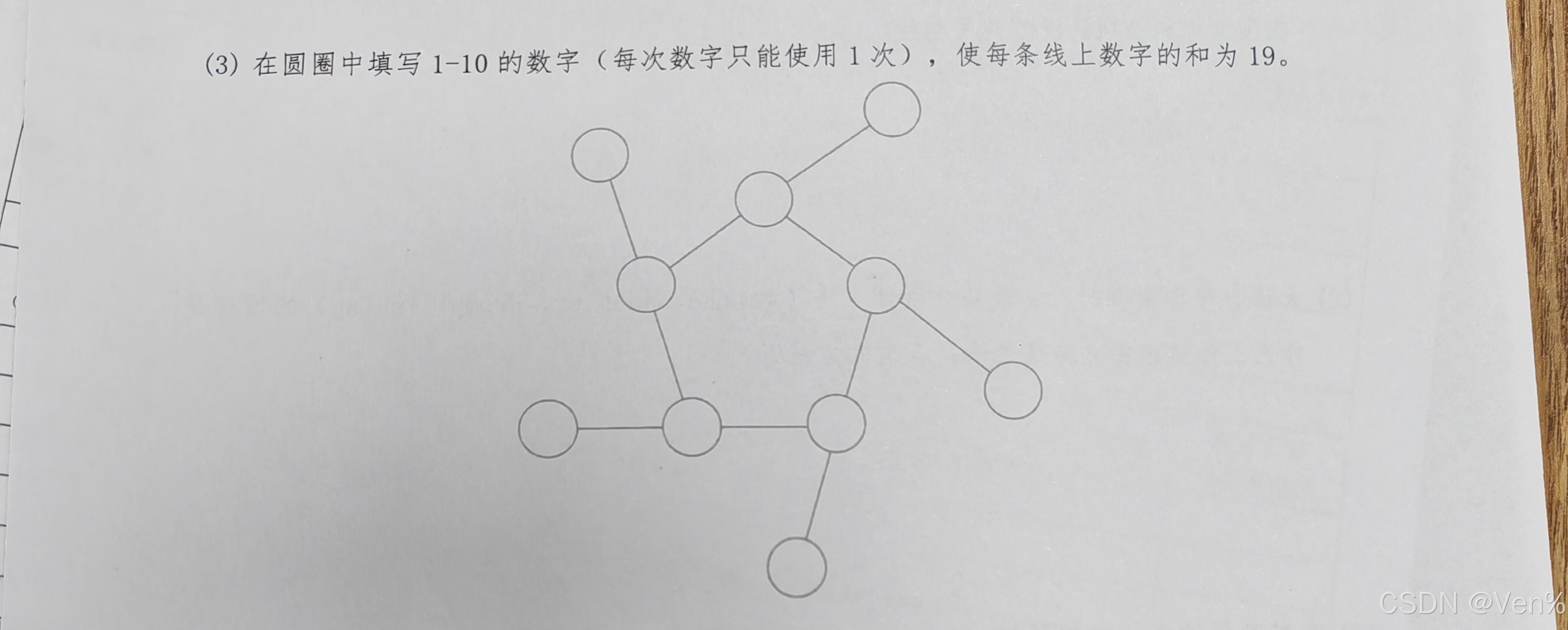
问题: 在圆圈中填写1-10的数字(每个数字使用一次),使每条线上数字的和为19。
由于题目没有给出具体的图形,我假设是常见的五芒星或类似结构。这里给出一个通用的解题思路:
解题策略:
- 计算所有数字总和:1+2+...+10 = 55
- 确定线条数量和每条线的和(19)
- 计算线条上的数字总次数(每个交点数字可能被多条线共享)
- 建立方程组求解
示例解(假设为五芒星结构):
一种可能的排列是:
· 顶点:1, 3, 5, 7, 9
· 交点:2, 4, 6, 8, 10
每条线(连接两个顶点和一个交点)和为19。
三、项目实例:个性化学习助手设计

(1) 需求分析过程
目标用户群体:
· 主要:K12学生、大学生、职业培训学员
· 次要:教师(用于辅助教学)、家长(了解学习进度)
核心功能点:
- 个性化推荐:基于学习历史、兴趣、能力水平推荐学习资源
- 智能问答:解答学科问题,提供解题思路
- 学习路径规划:动态调整学习计划
- 进度跟踪与反馈:可视化学习进展,识别薄弱环节
- 自适应测试:根据掌握程度调整题目难度
用户体验考虑:
· 界面简洁直观,适合各年龄段
· 响应迅速,减少等待时间
· 多模态交互(文本、语音、图像)
· 情感支持与鼓励机制
(2) 模型架构设计
基础模型选择:
· 选择: Llama 2/3或ChatGLM系列
· 理由:
- 开源可商用
- 中等规模(7B-13B)在效果与推理成本间平衡
- 已有教育领域微调案例参考
知识库构建:
- 结构化知识库:教材知识点图谱、习题库、教学视频元数据
- 非结构化知识库:学术论文、百科知识、教育文章
- 整合方式:采用RAG架构,将知识库作为外部检索源
- 更新机制:定期爬取最新教育资源,人工审核后入库
(3) 数据处理与隐私保护
数据收集计划:
- 用户数据:学习历史、测试成绩、互动记录(需用户授权)
- 内容数据:公开教育资源、合作机构提供的教材
- 交互数据:问答记录、反馈评分
处理流程:
- 匿名化:去除用户直接标识信息
- 差分隐私:在聚合统计中添加噪声
- 联邦学习:敏感数据本地处理,仅上传模型更新
- 加密存储:所有用户数据加密存储
标注计划:
- 自动预标注:使用基础模型生成初始标注
- 专家审核:教育专家修正关键标注
- 众包标注:非敏感数据可采用众包方式
- 持续迭代:基于用户反馈持续优化标注质量
(4) 训练策略
微调方法:
- 多任务微调:联合训练问答、推荐、解释生成任务
- 课程学习:从简单任务逐渐过渡到复杂任务
- 人类反馈强化学习:收集教师和学生的偏好数据,优化模型输出
分布式训练:
- 数据并行:适用于大规模用户数据
- 模型并行:若使用超大模型(70B+),拆分到多个GPU
- 混合并行:结合数据和模型并行,优化资源利用
模型压缩:
- 知识蒸馏:从大型教师模型蒸馏到小型部署模型
- 量化:INT8量化,平衡精度与推理速度
- 剪枝:移除注意力头或神经元中不重要的部分
(5) 风险分析与应对
主要风险及应对:
- 数据质量不足
· 预防:建立严格的数据质量评估体系
· 应对:采用半监督学习,利用少量高质量数据引导模型 - 模型性能不达标
· 预防:分阶段评估,设置明确的性能基准
· 应对:A/B测试不同模型版本,持续迭代优化 - 用户接受度低
· 预防:早期用户调研,设计符合用户习惯的交互
· 应对:收集用户反馈,快速迭代产品功能 - 隐私泄露风险
· 预防:实施严格的数据安全协议
· 应对:建立应急响应机制,定期安全审计 - 计算资源不足
· 预防:资源需求预估,采用混合云架构
· 应对:模型压缩和优化,降低推理成本
总结
AI大模型在教育领域的应用前景广阔,但需要深入理解教育场景的特殊性。成功的个性化学习助手需要平衡技术先进性、实用性和安全性,持续迭代优化,才能真正提升学习效果和用户体验。