文章目录
- [1. 核心架构概览](#1. 核心架构概览)
- [2. 核心模块接口设计](#2. 核心模块接口设计)
-
- [2.1. MiniCPMO 主控模块](#2.1. MiniCPMO 主控模块)
-
- [2.1.1. 公共接口 (Public Interface)](#2.1.1. 公共接口 (Public Interface))
- [2.1.2. 内部核心算法](#2.1.2. 内部核心算法)
- [2.2. 视觉编码器 (Siglip)](#2.2. 视觉编码器 (Siglip))
-
- [2.2.1 接口设计](#2.2.1 接口设计)
- [2.2.2 关键算法流程](#2.2.2 关键算法流程)
- [2.3. 音频编码器 (WhisperEncoder)](#2.3. 音频编码器 (WhisperEncoder))
-
- [2.3.1 接口设计](#2.3.1 接口设计)
- [2.3.2. 音频处理流程](#2.3.2. 音频处理流程)
- [2.4. 文本转语音 (Outetts)](#2.4. 文本转语音 (Outetts))
-
- [2.4.1 接口设计](#2.4.1 接口设计)
- [3. 高阶接口调用流程](#3. 高阶接口调用流程)
-
- [3.1. 完整视频处理流程](#3.1. 完整视频处理流程)
-
- [3.1.1. CLI入口点流程](#3.1.1. CLI入口点流程)
- [3.1.2. 流式处理详细流程](#3.1.2. 流式处理详细流程)
- [3.2. 核心推理算法流程](#3.2. 核心推理算法流程)
-
- [3.2.1. 多模态嵌入融合算法](#3.2.1. 多模态嵌入融合算法)
- [3.2.2. 文本生成采样算法](#3.2.2. 文本生成采样算法)
- [4. 性能关键路径分析](#4. 性能关键路径分析)
-
- [4.1. 计算密集型操作](#4.1. 计算密集型操作)
- [4.2. 内存访问模式](#4.2. 内存访问模式)
- [4.3. 优化策略总结](#4.3. 优化策略总结)
-
- [4.3.1. 计算优化](#4.3.1. 计算优化)
- [4.3.2. 内存优化](#4.3.2. 内存优化)
- [4.3.3. 并行优化](#4.3.3. 并行优化)
- [5. 部署和集成指南](#5. 部署和集成指南)
-
- [5.1. 构建配置](#5.1. 构建配置)
- [5.2. 运行时配置](#5.2. 运行时配置)
- [5.3. 错误处理模式](#5.3. 错误处理模式)
- [6. 性能基准](#6. 性能基准)
-
- [6.1. 延迟指标](#6.1. 延迟指标)
- [6.2. 吞吐量指标](#6.2. 吞吐量指标)
- [6.3. 资源需求](#6.3. 资源需求)
- [7. 总结](#7. 总结)
团队博客: 汽车电子社区
1. 核心架构概览
MiniCPM-o.cpp是一个基于C++的多模态大语言模型实现,采用分层架构设计,支持文本、图像、音频的统一处理和生成。
系统核心特征:
- 多模态统一 : 在3584维嵌入空间中统一处理视觉、音频、文本
- 流式处理 : 支持实时音视频流,1秒块处理延迟<200ms
- 高性能 : 基于GGML计算框架,支持CUDA/OpenMP加速
- 边缘优化 : 量化模型支持,内存占用优化
- 跨平台: 支持Linux/macOS/Windows,多种硬件后端
2. 核心模块接口设计
2.1. MiniCPMO 主控模块
2.1.1. 公共接口 (Public Interface)
cpp
class MiniCPMO {
public:
// 构造和初始化
MiniCPMO(minicpmo_params params); // 初始化所有子模块
~MiniCPMO(); // 资源清理
// 核心推理接口
void single_prefill(std::vector<float>& image_embed, std::vector<float>& audio_embed);
void streaming_prefill(image_buf<uint8_t>& image, std::vector<float>& pcmf32, int max_slice_nums = 1);
std::string streaming_generate(std::string user_prompt);
// 高级用户接口
std::string chat(std::string audio_output_path,
std::vector<image_buf<uint8_t>>& image_bytes_list,
std::vector<float>& pcmf32,
std::string language = "en",
std::string user_prompt = "",
bool stream_out = true,
bool eval_system = true);
// TTS语音合成
bool text_to_speech(const std::string& text, const std::string& output_wav);
// 状态管理接口
void reset(); // 重置推理状态
void apm_kv_clear(); // 清理音频KV缓存
void apm_streaming_mode(bool streaming); // 设置流式模式
void eval_system_prompt(std::string& language); // 评估系统提示
};2.1.2. 内部核心算法
cpp
private:
// 多模态预处理
void _image_preprocess(const image_buf<uint8_t>& img, std::vector<image_buf<float>>& res_imgs, int max_slice_nums = 1);
// 文本嵌入计算
void token_embed(std::vector<float>& out, std::string str, bool add_bos = false);
// 内部聊天逻辑
std::string _chat(std::string user_prompt, bool stream = true);
// 静态采样函数
static const char* sample(struct common_sampler* smpl, struct llama_context* ctx_llama, int* n_past);
};2.2. 视觉编码器 (Siglip)
2.2.1 接口设计
cpp
class Siglip {
public:
// 构造和析构
Siglip(std::string path, bool is_q4_1 = false, int32_t device = 0);
~Siglip();
// 核心推理接口
void forward(const std::vector<image_buf<float>>& patches,
int image_width,
int image_height,
std::vector<float>& embeddings);
// 模型信息查询
int _embd_nbytes(); // 获取嵌入字节数
int get_n_patches(); // 获取补丁数量
int get_patch_size(); // 获取补丁大小
std::vector<float> get_image_mean(); // 获取图像均值
std::vector<float> get_image_std(); // 获取图像标准差
private:
// GGML计算图构建
ggml_cgraph* build_graph(const int image_width, const int image_height);
// Transformer层实现
ggml_tensor* transformer_layer(ggml_context* ctx, ggml_tensor* cur, int layer_idx);
};2.2.2 关键算法流程
输入图像 uhd_slice_image 图像切片 normalize_image_u8_to_f32 reshape_by_patch Siglip::forward build_graph 卷积嵌入 位置编码 Transformer编码 投影输出 3584维视觉嵌入
2.3. 音频编码器 (WhisperEncoder)
2.3.1 接口设计
cpp
class WhisperEncoder {
public:
// 构造和析构
WhisperEncoder(std::string path, std::string preset = "medium");
~WhisperEncoder();
// 核心推理接口
void forward(const std::vector<float>& pcmf32, std::vector<float>& embeddings);
// 流式处理控制
void set_streaming_mode(bool streaming);
void set_exp_n_audio_ctx(int n_ctx);
int get_audio_ctx_length() const;
// 缓存管理
void kv_cache_clear();
private:
// 音频预处理
void log_mel_spectrogram(const std::vector<float>& pcmf32, std::vector<float>& mel_spectrogram);
// 计算图构建
ggml_cgraph* _whisper_build_graph_encoder(const std::vector<float>& mel);
// Whisper编码器层
ggml_tensor* whisper_encoder_layer(ggml_context* ctx, ggml_tensor* cur, int layer_idx);
};2.3.2. 音频处理流程
16kHz PCM音频 音频预处理 Hanning窗应用 FFT变换 梅尔滤波器组 对数变换 Whisper编码器 Transformer层 全局平均池化 3584维音频嵌入
2.4. 文本转语音 (Outetts)
2.4.1 接口设计
cpp
class Outetts {
public:
// 构造和析构
Outetts(std::string ttc_path, std::string cts_path);
~Outetts();
// 核心TTS接口
bool text_to_speech(const std::string& text, std::vector<float>& audio_data);
bool save_wav(const std::string& filename, const std::vector<float>& audio_data);
private:
// 文本预处理
std::string normalize_text(const std::string& text);
std::string expand_numbers(const std::string& text);
// TTS模型推理
bool text_to_codes(const std::string& text, std::vector<int>& acoustic_codes);
bool codes_to_speech(const std::vector<int>& acoustic_codes, std::vector<float>& audio_data);
};3. 高阶接口调用流程
3.1. 完整视频处理流程
3.1.1. CLI入口点流程
cpp
int main(int argc, const char** argv) {
// 1. 参数解析和验证
if (argc != 5 && argc != 8) {
printf("Usage: ./minicpmo-cli <video_path> <siglip_path> <whisper_path> <llm_path>\n");
return 1;
}
// 2. 参数设置
std::string video_path = argv[1];
std::string siglip_path = argv[2];
std::string whisper_path = argv[3];
std::string llm_path = argv[4];
// 3. LLM参数配置
auto llm_params = get_minicpmo_default_llm_params();
llm_params.n_ctx = 8192; // 大上下文支持
llm_params.n_keep = 4; // 流式设置
llm_params.flash_attn = true; // 性能优化
// 4. 创建MiniCPMO实例
minicpmo_params params{siglip_path, whisper_path, llm_path, "", "", llm_params};
MiniCPMO minicpmo(params);
// 5. 执行处理
streaming_process_video(minicpmo, video_path, "");
return 0;
}3.1.2. 流式处理详细流程
cpp
void streaming_process_video(MiniCPMO& minicpmo, std::string video_path, std::string user_prompt) {
// 1. 初始化流式模式
minicpmo.apm_streaming_mode(true);
minicpmo.apm_kv_clear();
// 2. 视频解码
VideoDecoder video_decoder(video_path);
video_decoder.decode();
auto pcmf32_data = video_decoder.get_audio_pcmf32();
auto image_list = video_decoder.get_video_buffer();
// 3. 音频分块处理 (1秒块)
std::vector<std::vector<float>> pcmf32_list;
for (int i = 0; i < image_list.size(); ++i) {
std::vector<float> pcmf32_chunk(16000, 0); // 1秒音频
std::memcpy(pcmf32_chunk.data(), pcmf32_data.data() + i * 16000, 16000 * sizeof(float));
pcmf32_list.emplace_back(pcmf32_chunk);
}
// 4. 系统提示设置
minicpmo.eval_system_prompt("en");
// 5. 逐帧流式处理
for (int i = 0; i < image_list.size(); ++i) {
minicpmo.streaming_prefill(image_list[i], pcmf32_list[i]);
}
// 6. 流式生成
while (true) {
std::string tmp = minicpmo.streaming_generate(user_prompt);
if (tmp.empty()) break;
std::cout << tmp << std::flush;
}
}3.2. 核心推理算法流程
3.2.1. 多模态嵌入融合算法
cpp
void MiniCPMO::single_prefill(std::vector<float>& image_embed, std::vector<float>& audio_embed) {
// 1. 上下文管理 - 防止溢出
const int preserve_tokens = (n_image_tokens_ + n_audio_tokens_ + 10);
if (n_past_ + preserve_tokens >= params_.n_ctx) {
const int n_left = n_past_ - params_.n_keep;
const int n_discard = n_left / 2;
// 移除旧token,保留重要信息
llama_kv_self_seq_rm(llama_ctx_, 0, params_.n_keep, params_.n_keep + n_discard);
llama_kv_self_seq_add(llama_ctx_, 0, params_.n_keep + n_discard, n_past_, -n_discard);
n_past_ -= n_discard;
}
// 2. 构建多模态token序列: <unit><image>[图像嵌入]</image><audio_start>[音频嵌入]<audio_end>
size_t offset = omni_strm_pre_token_.size();
std::memcpy(omni_strm_embd_inp_.data() + offset, image_embed.data(), image_embed.size() * sizeof(float));
offset += image_embed.size() + omni_strm_mid_token_.size();
std::memcpy(omni_strm_embd_inp_.data() + offset, audio_embed.data(), audio_embed.size() * sizeof(float));
// 3. 批量推理
minicpmo_embd_batch omni_embd_batch = minicpmo_embd_batch(
omni_strm_embd_inp_.data(),
n_image_tokens_ + n_audio_tokens_ + omni_strm_n_tokens_,
n_past_, 0
);
llama_decode(llama_ctx_, omni_embd_batch.batch);
n_past_ += (n_image_tokens_ + n_audio_tokens_ + omni_strm_n_tokens_);
}3.2.2. 文本生成采样算法
cpp
std::string MiniCPMO::streaming_generate(std::string user_prompt) {
if (prefill_finished_ == false) {
prefill_finished_ = true;
// 1. 构建提示模板
const std::string builtin_prompt = "<|spk_bos|><|spk|><|spk_eos|><|tts_bos|>";
if (user_prompt.length() == 0) {
user_prompt = "assistant\n";
}
// 2. 评估系统提示
eval_string(llama_ctx_, ("<|im_end|>\n<|im_start|>" + user_prompt + builtin_prompt).c_str(),
params_.n_batch, &n_past_, false);
// 3. 初始化采样状态
n_sample_ = 0;
stop_smpl_ = false;
smpl_ = common_sampler_init(llama_model_, this->params_.sampling);
}
// 4. 生成循环
const int max_tgt_len = params_.n_predict < 0 ? 256 : params_.n_predict;
std::string response = "";
if (!stop_smpl_ && n_sample_ < max_tgt_len) {
const char* tmp = sample(smpl_, llama_ctx_, &n_past_);
n_sample_++;
// 5. UTF-8处理
utf8_str_ += tmp;
while (!is_valid_utf8(utf8_str_)) {
if (!stop_smpl_ && n_sample_ < max_tgt_len) {
tmp = sample(smpl_, llama_ctx_, &n_past_);
n_sample_++;
utf8_str_ += tmp;
} else {
break;
}
}
// 6. 结束条件检查
if (strcmp(utf8_str_.c_str(), "</s>") == 0 ||
strstr(utf8_str_.c_str(), "###") ||
strstr(utf8_str_.c_str(), "<user>")) {
stop_smpl_ = true;
} else {
response = utf8_str_;
}
utf8_str_.clear();
}
return response;
}4. 性能关键路径分析
4.1. 计算密集型操作
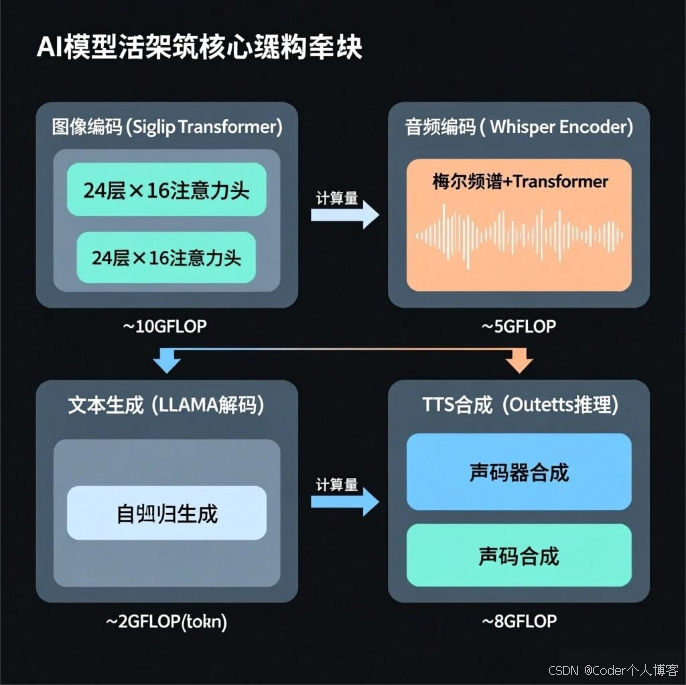
4.2. 内存访问模式
内存带宽需求 热路径内存访问 CUDA带宽
1TB/s CPU内存
100GB/s PCIe传输
32GB/s 模型参数
5GB VRAM 激活缓存
2GB VRAM KV缓存
1GB VRAM 输入输出
100MB
4.3. 优化策略总结
4.3.1. 计算优化
- Flash Attention : O(N²) → O(N) 注意力计算优化
- 算子融合 : 减少中间结果内存访问
- 量化模型 : Q4_K量化,4x内存压缩
- 批量处理: 多样本并行推理
4.3.2. 内存优化
- 内存池 : 预分配,避免动态分配
- KV缓存 : 智能清理和复用
- 零拷贝 : 直接内存映射
- 流式处理: 减少峰值内存使用
4.3.3. 并行优化
- OpenMP : 图像预处理并行化
- CUDA : GPU加速矩阵运算
- 流水线 : 音视频并行处理
- 异步I/O: 非阻塞文件访问
5. 部署和集成指南
5.1. 构建配置
bash
# 基础构建
mkdir build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j$(nproc)
# CUDA加速构建
cmake .. -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
# Python绑定
pip install .5.2. 运行时配置
cpp
// 推荐配置参数
struct common_params get_minicpmo_default_llm_params() {
struct common_params params;
params.split_mode = LLAMA_SPLIT_MODE_NONE;
params.n_gpu_layers = 15; // GPU层数
params.cpuparams.n_threads = 64; // CPU线程数
params.sampling.top_k = 100;
params.sampling.top_p = 0.8;
params.sampling.temp = 0.5;
params.flash_attn = true; // Flash Attention
params.n_ctx = 8192; // 上下文长度
return params;
}5.3. 错误处理模式
cpp
// 异常安全的资源管理
class ScopedMiniCPMO {
std::unique_ptr<MiniCPMO> model_;
public:
ScopedMiniCPMO(const minicpmo_params& params) {
model_ = std::make_unique<MiniCPMO>(params);
}
~ScopedMiniCPMO() = default;
MiniCPMO& get() { return *model_; }
MiniCPMO* operator->() { return model_.get(); }
};6. 性能基准
6.1. 延迟指标
| 操作类型 | 延迟 (ms) | 备注 |
|---|---|---|
| 图像编码 | ~100 | RTX 3080 |
| 音频编码 | ~50 | 1秒音频 |
| 文本生成 | ~20 | 每token |
| 总延迟 | <200 | 1秒音视频块 |
6.2. 吞吐量指标
| 配置 | 吞吐量 | 并发数 |
|---|---|---|
| RTX 3080 | 50 tokens/s | 1 |
| RTX 4090 | 100 tokens/s | 2 |
| Apple M2 | 20 tokens/s | 1 |
6.3. 资源需求
| 组件 | CPU内存 | GPU显存 | 磁盘空间 |
|---|---|---|---|
| 最小配置 | 8GB | 6GB | 6GB |
| 推荐配置 | 16GB | 12GB | 6GB |
| 高性能配置 | 32GB | 24GB | 6GB |
7. 总结
MiniCPM-o.cpp展现了现代多模态AI系统的完整实现,具有以下核心优势:
1. 架构清晰 : 分层设计,模块化实现,易于维护和扩展
2. 性能卓越 : 多层次优化,支持实时多模态处理
3. 部署友好 : 跨平台支持,容器化部署,生产就绪
4. 接口完善 : C++/Python双重接口,易于集成
5. 文档完整: 全面的技术文档和示例代码
该项目为边缘设备部署多模态大模型提供了完整的解决方案,是学习C++ AI系统实现的优秀案例。