文本大模型
核心概念
- LLaMA:Meta开源的大语言模型
- LoRA:给你模型也得有训练的动力才行
- Self-Instruct:下游任务得规矩些,输入和输出都得有个标准格式
- PEFT(Parameter-Efficient Fine-Tuning):Hugging Face整合版本
LoRA微调模型的原理
使用LoRA时,可以将其原理理解为在原有知识基础上有选择性地对特定领域参数进行微调。就像原本掌握数学、语文等知识,现在想学习天文,不必从零开始学习所有知识,而是专注新增领域的学习和调整。
现在开发者可以轻松地聚焦于自己的特定任务或多个小任务上,不再受限于以往参数量大导致模型训练困难的问题。借助于预训练的大模型基础,开发者可以方便地微调模型以满足各自的下游任务需求,无论是文本生成、视觉相关任务还是其他领域,都可以利用大模型进行个性化定制和高效训练。
通过训练一个小模型专注天文相关的内容,并将这个小模型的参数与大模型的部分或全部参数相加以合并,这样既能利用大模型的通用性和学习能力,又能使大模型更聚焦特定领域,从而实现解决更多下游任务的目标。
当大模型的研究变得相对轻松,许多复杂的算法和原理已被简化,很多任务都能通过大模型轻松实现,这体现了大道至简的原则,许多工作都变得简单高效。
实际操作中,首先保持大模型的参数不变,它作为基础且有较强通用能力的模型;然后针对每个下游任务,单独构建一个小模型来学习和适应特定任务。通过冻结大模型参数,并用各个下游任务的小模型进行针对性训练,可以实现不同下游任务的有效解决。每个小模型都聚焦在一个或多个任务上,利用大模型作为根基,通过加法操作,组合能解决各种下游任务的解决方案。
数据的好坏对于模型性能至关重要,因此需要针对具体应用场景收集并使用相关联的高质量数据集,以确保模型在该场景下的表现和效果。同时,在选择和准备数据时,要考虑数据是否适合所聚焦的具体任务,避免无效的信息影响。
在微调过程中,所需的训练参数比例可以大幅度减少。
在微调大模型时,可以将大模型参数固定,然后训练一个小模型,通过构建矩阵A和B的关系简化原本庞大的权重矩阵,从而实现减少需要训练的参数量,实现近似的表示。
Transformer与LoRA的关系
文本大模型主要使用Transformer结构来构建。在Transformer中最核心的三个元素Q、K和V组成,训练好这三个权重参数矩阵对于模型性能提升至关重要。
在LoRA算法中,新导入的QKV组的维度可以调整,可以设置与原有的QKV相同维度,也可以根据具体需求设置不同维度。
LoRA算法的优势在于能够通过在原始模型基础上添加较小的额外模块,针对不同的下游任务进行微调。这样既能保持大模型的结构不变,又能灵活适应不同的应用场景,显著减少了对不同任务所需训练的模型数量和参数量,使得模型保持和加载更为便捷高效。
LoRA模型强调一个加法原理的并行模型,在这个模型中,即使引入一个小模型,其目的是为了并行执行并保持整体推理效率,不会显著增加推理负担。
在Transformer中,Q、K、V的重要性可能存在差异。Q矩阵的信息量可能比K、V矩阵的信息更为重要。
大模型在解决具体下游任务时可能存在准确性问题,有时候会给出看上去合理但实际上错误的答案。可以将下游任务拆分为多个下游任务,让每个模型专注自己的领域,类似学术有专攻,确保在特定任务上的精确度。
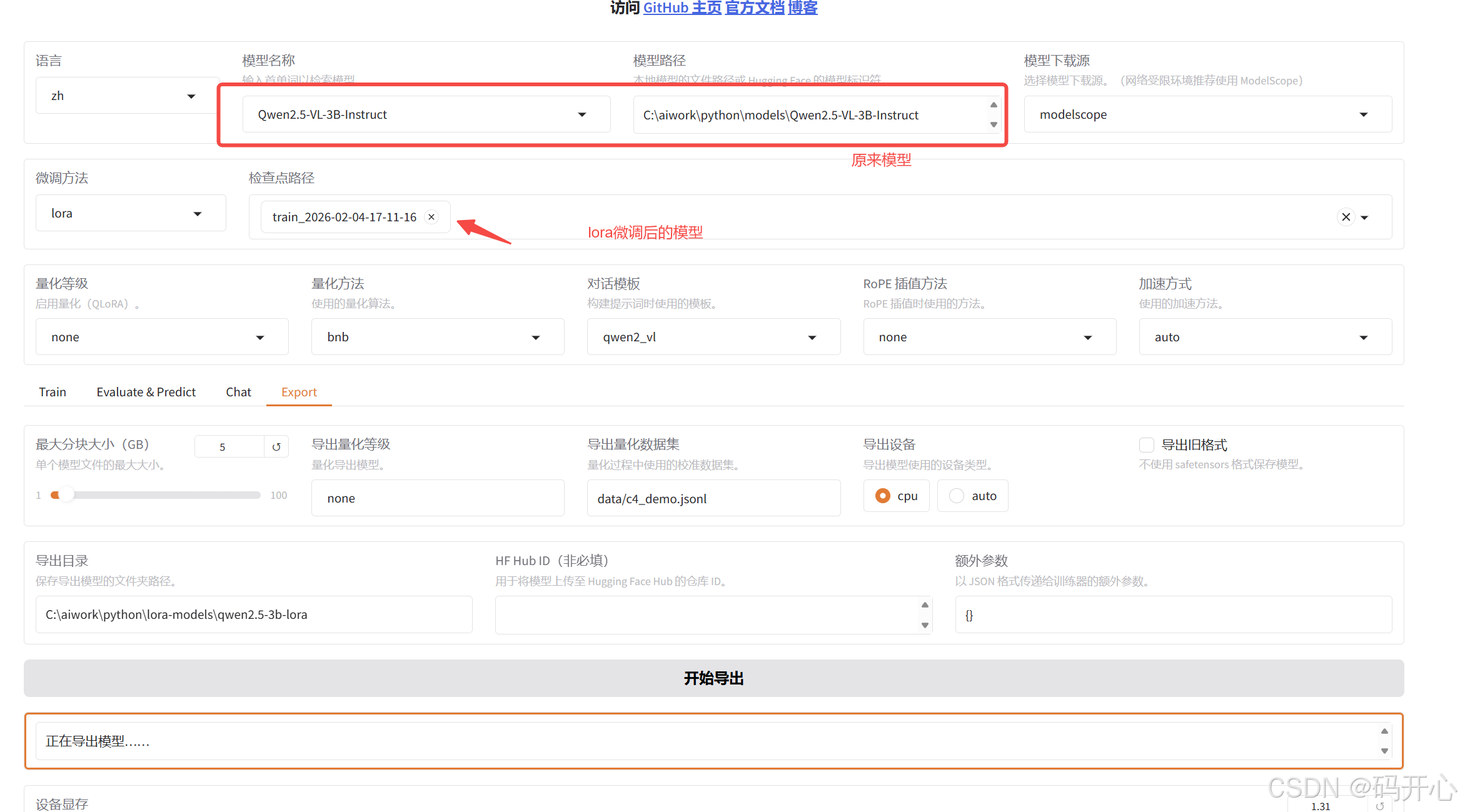
LLaMA-Factory微调框架
环境搭建
1. 创建环境
创建conda环境
bash
conda create -n llama-factory python==3.10激活环境
bash
conda activate llama-factory设置pip源
python
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple2.编译llama-factory
python
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements/metrics.txt重新安装torch,阿里云源,清华源没有gpu版本
python
pip uninstall torch
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu1293.启动 llama-factory
python
llamafactory-cli webui4.下载模型
python
modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir Qwen2.5-VL-3B-Instruct5.设置模型进行测试
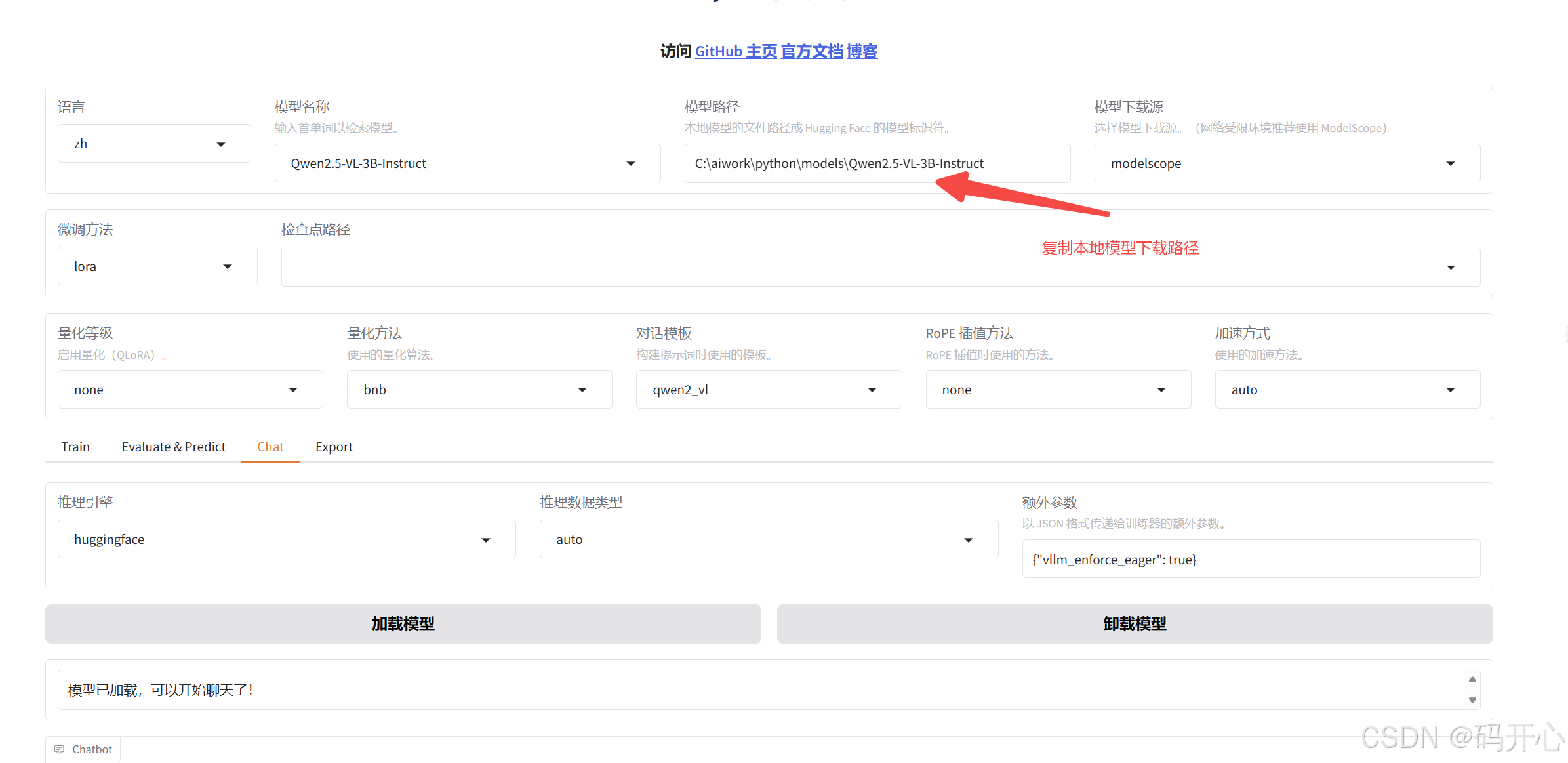
选择图片,输入问题即可。
6.设置训练集
修改dataset_info.json文件复制
json
"mllm_demo": {
"file_name": "mllm_demo.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}复制mllm_demo.json 为自己的qwenvl.json
修改qwenvl.json文件
json
[
{
"messages": [
{
"content": "<image>图中有几个作业人员在现场,安全员是否在场,是否正在进行施工?",
"role": "user"
},
{
"content": "4个作业人员,且2名安全员在现场,正在进行施工",
"role": "assistant"
}
],
"images": [
"qwenvl/图片1.png"
]
}
]以上内容可以通过deepseek去生成。
7.训练设置
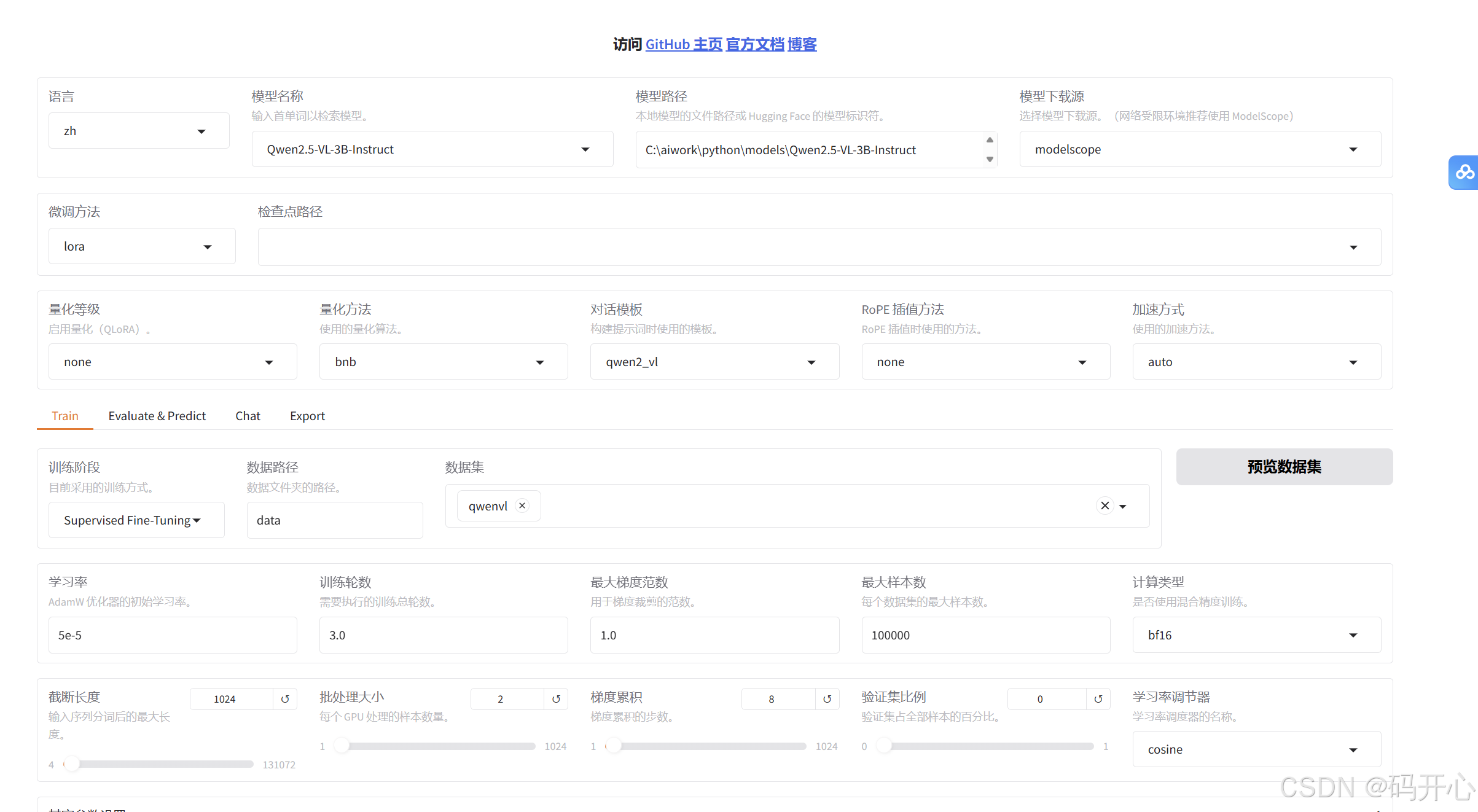
| 配置项 | 建议值 | 说明 |
|---|---|---|
| 模型路径 | ./models/Qwen2.5-VL-3B-Instruct |
本地绝对路径或HuggingFace Hub ID |
| 模板 | qwen2_vl | 必须匹配模型官方的对话模板 |
| 量化 | 可选4-bit/8-bit | 显存<16GB建议开启4-bit量化 |
| 参数 | 推荐设置 | 原理说明 |
|---|---|---|
| LoRA秩® | 8-64 | 简单任务8-16,复杂领域知识64 |
| LoRA缩放系数(α) | 16-32 | 通常设为r的2倍 |
| 目标模块 | q_proj,v_proj | Q/V矩阵对语义理解最关键 |
| 学习率 | 1e-4 ~ 5e-4 | 比全量微调高10倍(参数少不怕过拟合) |
| 批次大小 | 4-8 | 配合梯度累积达到 effective batch size=64 |
| 训练轮数 | 3-5 epochs | 小数据集3轮,大数据集5轮+早停 |
选择data对应的数据集qwenvl
可以预览数据,正常预览就说明数据集然正常
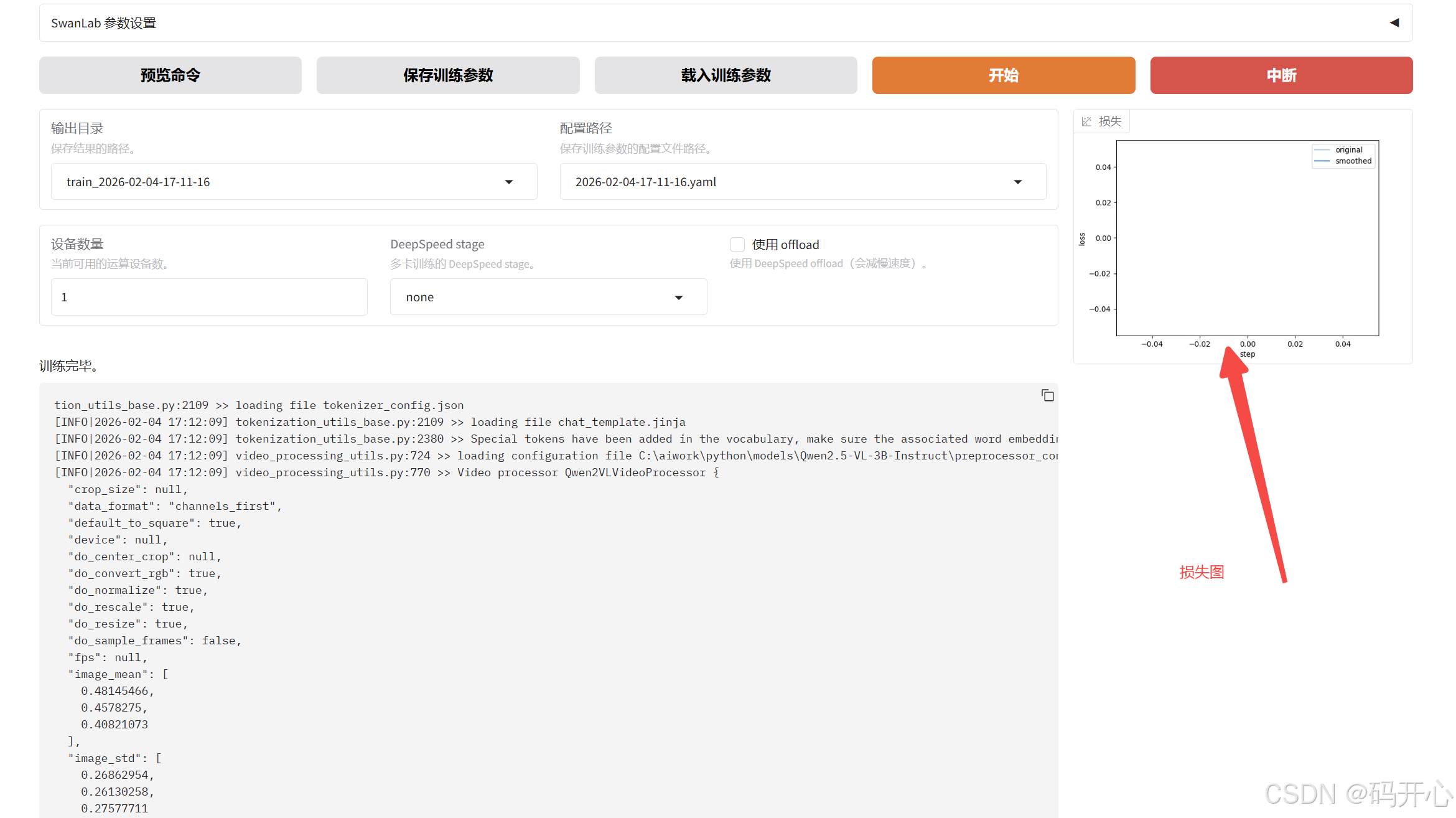
8.训练结果
9.合并模型