关于侧输出流
Flink 侧输出流详解
侧输出流是 Apache Flink 中一个重要的功能,允许从主流中拆分出多个额外的数据流。
什么是侧输出流?
侧输出流允许在一个处理函数中,除了产生主流结果外,还可以产生一个或多个额外的输出流。这些侧输出流与主流具有相同的并行度和处理保证。
主要应用场景
1.数据分流:将数据按照不同条件拆分到不同流中
2.异常处理:将处理失败的数据单独输出
3.延迟数据:在窗口处理中处理迟到数据
4.监控指标:输出监控和诊断信息
核心概念
OutputTag
用于标识侧输出流的标签,包含类型信息。
java
// 定义侧输出标签
OutputTag<String> errorTag = new OutputTag<String>("errors") {};
OutputTag<Integer> lateDataTag = new OutputTag<Integer>("late-data") {};使用方法
java
// 定义侧输出标签
public static final OutputTag<RawCollectionLogs> FAILED_PROCESS_DATA_TAG = new OutputTag<>("failed-process-data") {};
@Override
public void processElement(RawCollectionLogs value, Context context, Collector<TaggedMessage> collector) throws Exception {
log.info("processElement,value={}", JSON.toJSONString(value));
try {
if (value.getMsg().startsWith("cm_project")){
ProjectMessage message = convertToProjectMessage(value); collector.collect(new TaggedMessage(message, "project"));
} else if (value.getMsg().startsWith("cm_url")){
PageMessage pageMsg = saveDataWithPage(value); collector.collect(new TaggedMessage(pageMsg, "page"));
} else {
UserBehaviorMessage behaviorMessage = saveDataWithBehavior(value); collector.collect(new TaggedMessage(behaviorMessage, "behavior"));
}
}catch (Exception e){
log.info("processElement,error,msg={},rawId={}",e.getMessage(),value.getId());
// 输出处理过程中异常的数据
context.output(FAILED_PROCESS_DATA_TAG, value);
}
}主函数中使用
java
public class FlinkSimlinkJob {
public static void main(String[] args) throws Exception {
// 设置执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 纯内存状态
env.setStateBackend(new HashMapStateBackend());
// 从 MySQL 表 A 读取数据
DataStream<RawCollectionLogs> sourceData = env
.addSource(new RawDataReadFunction())
.assignTimestampsAndWatermarks(WatermarkStrategy.noWatermarks());
// 4. 解析变更数据
SingleOutputStreamOperator<TaggedMessage> processedStream = sourceData
.process(new RawDataProcessFunction())
.name("flinkSimlinkJob-process");
// 使用简化版事务性
Sink processedStream.addSink(new FlinkSimlinkSink())
.name("flinkSimlinkJob-sink")
.uid("flinkSimlinkJob-sink");
// 侧输出流
sideOutputSink(processedStream);
env.executeAsync("FlinkSimlinkJob");
}
/**
* 侧输出流
*/
private static void sideOutputSink(SingleOutputStreamOperator<TaggedMessage> processedStream) {
SideOutputDataStream<RawCollectionLogs> sideOutput = processedStream.getSideOutput(RawDataProcessFunction.FAILED_PROCESS_DATA_TAG);
sideOutput.addSink(UpdateRawDataSink.create());
}
}处理逻辑是: 错误的数据也需要记录下来,由于与成功的处理逻辑保存的表或者结构不同,通过侧输出流将数据单独输出。
关于重复校验
使用processedState 和 ttlConfig 实现内存级去重
processedState
processedState 是一个 Flink 状态变量,具体类型为 ValueState:
- ValueState:Flink 提供的状态类型,用于存储单个值
- Boolean:存储的数据类型,表示用户是否已经处理过
- Keyed State:键控状态,与特定键(这里是用户的 UID)绑定
主要功能:
java
// 检查是否已经处理过(状态去重)
Boolean isProcessed = processedState.value();
if (isProcessed != null && isProcessed) {
log.info("Order already processed");
return; // 直接返回,不再处理
}具体作用:
java
1. 精确一次处理保障
确保同一用户的订单只被处理一次
防止因网络重传、作业重启等导致的重复处理
2. 内存级去重
在 Flink 进程内存中快速判断是否已处理
避免每次都查询外部数据库
3. 性能优化
状态存储在 Flink 的托管内存中,访问速度快
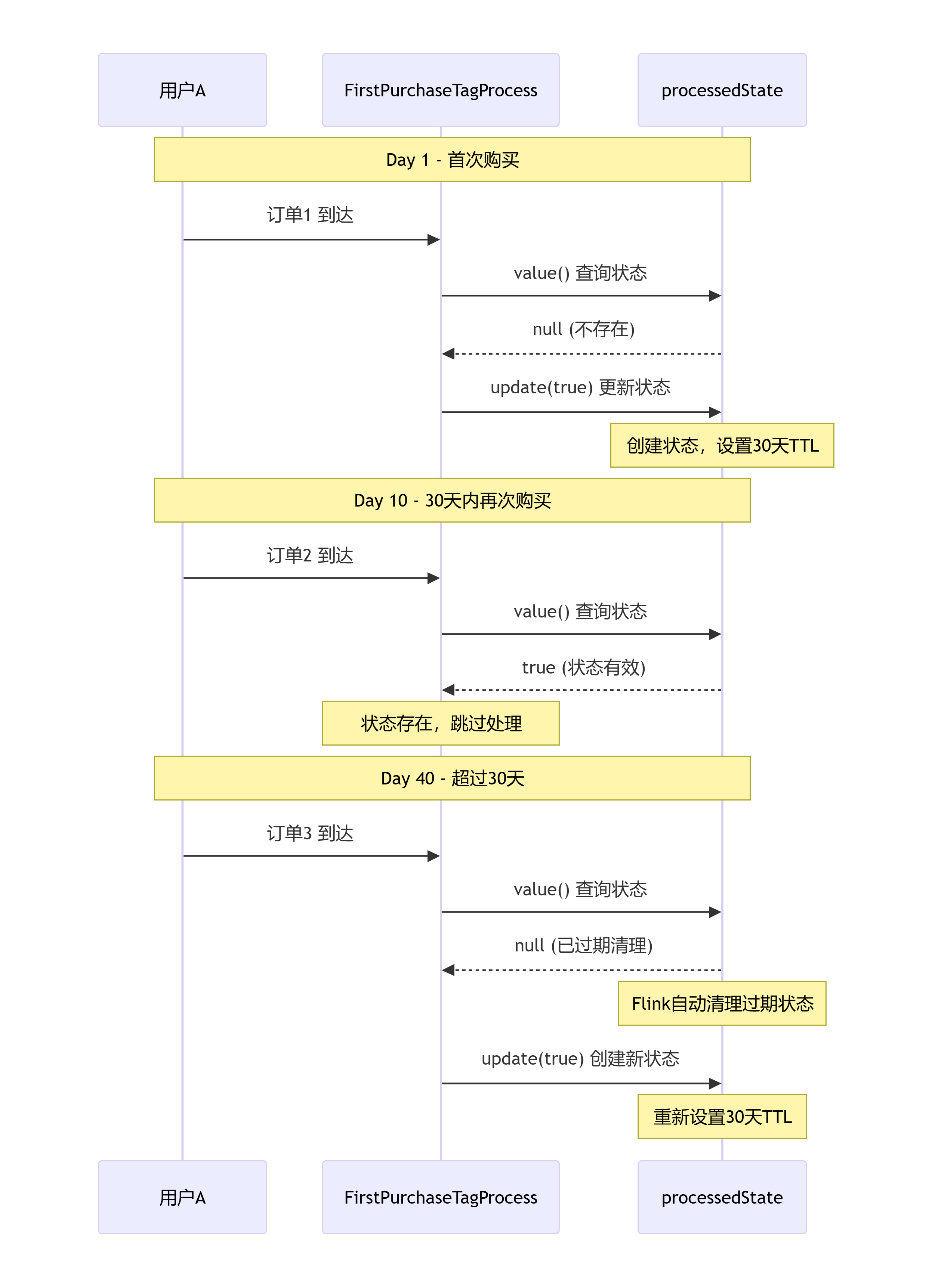
减少对外部存储(如 MySQL)的查询压力工作原理
java
用户A → 订单1 → 首次处理 → processedState.update(true)
用户A → 订单2 → 检查状态 → 已处理 → 跳过状态的生命周期
- 创建:用户首次出现时创建
- 更新:处理成功后更新为 true
- 持久化:Flink 会自动保存到状态后端
- 清理:由 TTL 配置控制何时清理
TTLConfig
用于定义状态在内存/存储中的存活时间,过期后,Flink 会自动清理过期的状态。
为什么需要 TTL
- 如果不设置 TTL,状态会永久保留
- 用户量增长会导致状态无限膨胀
- 内存/存储资源会被耗尽
TTL 解决的核心问题:
- 资源管理:自动清理不再需要的状态
- 成本控制:避免存储资源无限增长
- 数据时效性:只保留有业务价值的状态
TTL 配置的典型参数
java
// 通常在主程序中这样创建 ttlConfig
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.days(30)) // 设置存活时间为30天
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // 更新时机
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 过期不可见
.build();完整流程
java
public class FirstPurchaseJob {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 纯内存状态
env.setStateBackend(new HashMapStateBackend());
// 从 MySQL 表 A 读取数据
DataStream<OrderCenterTOrders> sourceData = env
.addSource(new FirstPurchaseTagReadProcess())
.setParallelism(1)
.assignTimestampsAndWatermarks(WatermarkStrategy.noWatermarks());
// 配置状态TTL
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.hours(24))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(1000)
.build();
// 4. 解析变更数据
SingleOutputStreamOperator<FlinkUserTags> processedStream = sourceData
.keyBy(FirstPurchaseTagJob::extractOrderKey)
.process(new FirstPurchaseTagProcess(ttlConfig))
.name("firstPurchase Parser")
.filter(Objects::nonNull);
processedStream.addSink(UserTagsSink.create()).uid("FirstPurchaseJob-sink");
env.executeAsync("FirstPurchaseJob");
}
private static String extractOrderKey(OrderCenterTOrders value) {
try {
if (value != null) {
return value.getUid() + "_" + value.getBqkey();
}
} catch (Exception e) {
log.info("Failed to extract key from order data: {}", e.getMessage());
}
return "unknown";
}
}
java
@Slf4j
public class FirstPurchaseTagReadProcess extends RichSourceFunction<OrderCenterTOrders> {、
private QueryRunner queryRunner;
private volatile boolean isRunning = true;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
DataSource dataSource = ConnectionPool.getDataSource();
queryRunner = new QueryRunner(dataSource);
}
@Override
public void run(SourceContext<OrderCenterTOrders> ctx) throws Exception {
while (isRunning) {
executeQuery(ctx);
TimeUnit.MINUTES.sleep(30);
}
}
private void executeQuery(SourceContext<OrderCenterTOrders> ctx) {
try {
// 使用 BeanListHandler 如果需要返回列表
queryRunner.query(getSql(),
rs -> {
while (rs.next() && isRunning) {
ctx.collect(new OrderCenterTOrders());
}
return null;
});
} catch (SQLException e) {
log.info("数据库查询异常", e);
}
}
private String getSql(String payTime) {
return "SELECT * from xxx";
}
}
java
@Slf4j
public class FirstPurchaseTagProcess extends KeyedProcessFunction<String, OrderCenterTOrders, FlinkUserTags> {
private ValueState<Boolean> processedState;
private final StateTtlConfig ttlConfig;
public FirstPurchaseTagProcess(StateTtlConfig ttlConfig) {
this.ttlConfig = ttlConfig;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 初始化状态描述符
ValueStateDescriptor<Boolean> processedStateDescriptor =
new ValueStateDescriptor<>("processedState", Boolean.class);
processedStateDescriptor.enableTimeToLive(ttlConfig);
processedState = getRuntimeContext().getState(processedStateDescriptor);
}
@Override
public void close() throws Exception {
super.close();
}
@Override
public void processElement(OrderCenterTOrders value, Context context, Collector<FlinkUserTags> collector) throws Exception {
try {
// 检查是否已经处理过(状态去重)
Boolean isProcessed = processedState.value();
if (isProcessed != null && isProcessed) {
return;
}
FlinkUserTags target = createFlinkUserTags(value);
collector.collect(target);
// 更新状态表示已处理
processedState.update(true);
}catch (Exception e){
}
}
}
Flink常用函数详解
基础转换函数
MapFunction
作用详解: 将输入数据流中的每个元素一对一地转换为另一个元素。是最基础的数据转换操作,适用于简单的逐元素转换场景,如数据类型转换、字段提取、格式转换等。
使用案例:
java
public class MapFunctionExample {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 创建数据源
DataStream<String> source = env.fromElements(
"apple:5",
"banana:3",
"orange:8",
"grape:12"
);
// 3. 使用MapFunction转换数据
DataStream<Fruit> result = source.map(new FruitParser());
// 4. 输出结果
result.print();
// 5. 执行任务
env.execute("Map Function Example");
}
// 自定义MapFunction实现类
public static class FruitParser implements MapFunction<String, Fruit> {
@Override
public Fruit map(String value) throws Exception {
String[] parts = value.split(":");
return new Fruit(parts[0], Integer.parseInt(parts[1]));
}
}
// 数据POJO类
public static class Fruit {
public String name;
public int quantity;
public Fruit() {}
public Fruit(String name, int quantity) {
this.name = name;
this.quantity = quantity;
}
@Override
public String toString() {
return "Fruit{name='" + name + "', quantity=" + quantity + "}";
}
}
}输出结果
java
10> Fruit{name='grape', quantity=12}
9> Fruit{name='orange', quantity=8}
7> Fruit{name='apple', quantity=5}
8> Fruit{name='banana', quantity=3}FlatMapFunction
作用详解: 将每个输入元素转换为零个、一个或多个输出元素。常用于拆分、过滤和展开操作。
使用案例:
java
public class FlatMapFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> source = env.fromElements(
"hello world",
"flink streaming",
"big data processing"
);
// 使用FlatMap拆分单词
DataStream<String> words = source.flatMap(new WordSplitter());
words.print();
env.execute("FlatMap Example");
}
public static class WordSplitter implements FlatMapFunction<String, String> {
@Override
public void flatMap(String value, Collector<String> out) {
// 拆分句子为单词,并过滤空字符串
for (String word : value.split("\\s+")) {
if (!word.isEmpty()) {
out.collect(word);
}
}
}
}
}
// Lambda写法
DataStream<String> words = source.flatMap((String value, Collector<String> out) -> {
for (String word : value.split("\\s+")) {
if (!word.isEmpty()) {
out.collect(word);
}
}
}).returns(Types.STRING);输出结果
java
5> flink
5> streaming
6> big
4> hello
6> data
4> world
6> processingFilterFunction
作用详解: 根据条件过滤数据流中的元素,保留满足条件的元素。
使用案例:
java
public class FilterFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Integer> numbers = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 过滤偶数
DataStream<Integer> evenNumbers = numbers.filter(new EvenFilter());
// Lambda写法
DataStream<Integer> oddNumbers = numbers.filter(num -> num % 2 != 0);
evenNumbers.print("偶数: ");
oddNumbers.print("奇数: ");
env.execute("Filter Example");
}
public static class EvenFilter implements FilterFunction<Integer> {
@Override
public boolean filter(Integer value) {
return value % 2 == 0;
}
}
}输出结果
java
偶数: :5> 10
偶数: :1> 6
奇数: :2> 3
奇数: :4> 5
偶数: :11> 4
偶数: :3> 8
偶数: :9> 2
奇数: :6> 7
奇数: :8> 9聚合函数
ReduceFunction
作用详解: 对两个相同类型的元素进行归约,产生一个同类型的新元素。
使用案例:
java
public class ReduceFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Transaction> transactions = env.fromElements(
new Transaction("user1", 100.0),
new Transaction("user1", 50.0),
new Transaction("user2", 200.0),
new Transaction("user1", 150.0),
new Transaction("user2", 100.0)
);
// 按键分组后Reduce
DataStream<Transaction> totalPerUser = transactions
.keyBy(t -> t.userId)
.reduce(new SumReducer());
totalPerUser.print();
env.execute("Reduce Example");
}
public static class SumReducer implements ReduceFunction<Transaction> {
@Override
public Transaction reduce(Transaction t1, Transaction t2) {
return new Transaction(t1.userId, t1.amount + t2.amount);
}
}
public static class Transaction {
public String userId;
public double amount;
public Transaction() {}
public Transaction(String userId, double amount) {
this.userId = userId;
this.amount = amount;
}
@Override
public String toString() {
return String.format("用户%s: 总计%.2f", userId, amount);
}
}
}输出结果
java
9> 用户user1: 总计100.00
1> 用户user2: 总计200.00
9> 用户user1: 总计150.00
1> 用户user2: 总计300.00
9> 用户user1: 总计300.00checkpoint
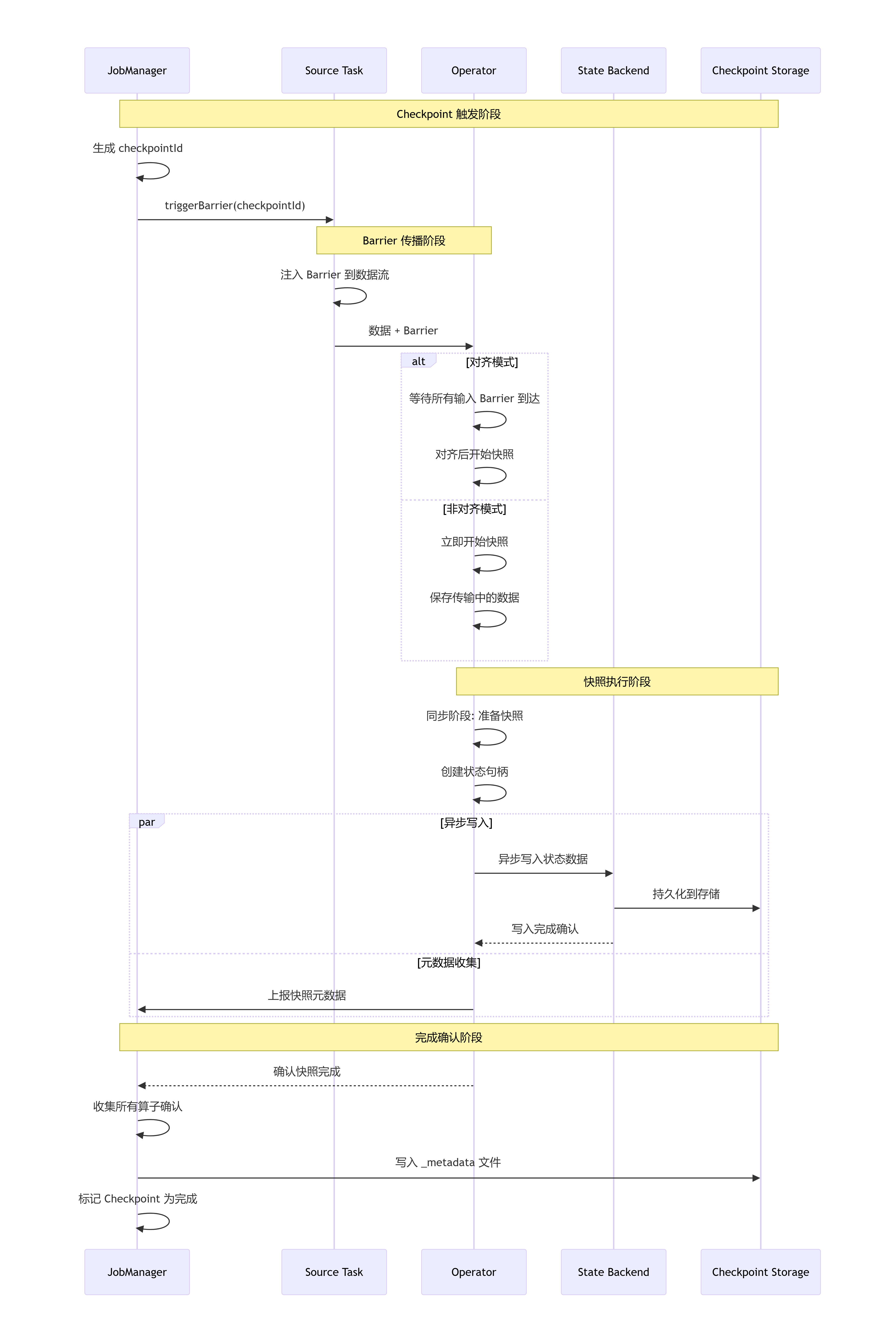
什么是 Checkpoint?
Checkpoint是Flink实现容错机制的核心技术,通过定期将应用状态持久化到可靠存储,在发生故障时可以从最近的检查点恢复,实现 Exactly-Once 或 AtLeast-Once 语义。
核心原理:Chandy-Lamport 算法
Flink 使用改进的 分布式快照算法,通过插入特殊的 Barrier 在数据流中,实现全局一致性快照:
java
Source → Barrier → Operator → Barrier → Sink
↓ ↓ ↓ ↓
状态保存 状态保存 状态保存 状态保存flink-conf.yaml 配置 Checkpoint 模板
java
#
# 基本配置
execution.checkpointing.interval: 30s # 检查点间隔,测试环境可以设置较短
execution.checkpointing.mode: EXACTLY_ONCE # 检查点模式
execution.checkpointing.timeout: 2min # 检查点超时时间
execution.checkpointing.min-pause: 5s # 检查点间最小间隔
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.tolerable-failed-checkpoints: 2
# 内存状态后端配置(生产环境不推荐)
state.backend: hashmap # 使用HashMapStateBackend
state.backend.memory.checkpoint-storage: jobmanager # 检查点存储在JobManager内存
state.backend.memory.savepoint-storage: jobmanager # Savepoint存储在JobManager内存
# 内存配置(针对内存存储优化)
state.backend.memory.max-size: 512mb # 内存状态最大大小
state.backend.memory.preallocate: false # 是否预分配内存
# 非对齐检查点配置
execution.checkpointing.unaligned.enabled: true # 启用非对齐检查点
execution.checkpointing.aligned-checkpoint-timeout: 30s # 对齐超时时间
# 检查点压缩(减少内存占用)
execution.checkpointing.snapshot-compression: true
# 任务完成后检查点(测试用)
execution.checkpointing.checkpoints-after-tasks-finish: falseJava代码 Checkpoint 配置
java
public class MemoryCheckpointConfigExample {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 配置本地文件系统检查点
configureLocalFileSystemCheckpoint(env);
// 启用检查点,设置间隔为30秒
env.enableCheckpointing(30 * 1000);
// 设置检查点模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置检查点超时时间(2分钟)
env.getCheckpointConfig().setCheckpointTimeout(2 * 60 * 1000);
// 设置检查点间最小间隔(5秒)
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5 * 1000);
// 设置最大并发检查点数
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 设置容忍的连续失败检查点数
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
// 启用非对齐检查点(减少背压影响)
env.getCheckpointConfig().enableUnalignedCheckpoints();
// 设置对齐超时(30秒后回退到对齐检查点)
env.getCheckpointConfig().setAlignedCheckpointTimeout(Duration.ofSeconds(30));
// 业务逻辑
env.socketTextStream("localhost", 9999)
.flatMap((String line, org.apache.flink.util.Collector<Tuple2<String, Integer>> out) -> {
for (String word : line.split("\\s+")) {
out.collect(new Tuple2<>(word, 1));
}
})
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class))
.keyBy(0)
.sum(1)
.print();
System.out.println("开始执行作业,使用本地文件系统存储检查点...");
System.out.println("检查点间隔: 30秒");
System.out.println("状态后端: HashMapStateBackend");
System.out.println("检查点存储: 本地文件系统");
System.out.println("检查点目录: file:///tmp/flink-checkpoints");
env.execute("Local FileSystem Checkpoint Example");
}
/**
* 配置本地文件系统检查点存储
* 使用 HashMapStateBackend + FileSystemCheckpointStorage
*/
private static void configureLocalFileSystemCheckpoint(StreamExecutionEnvironment env) {
// 1. 创建 HashMapStateBackend
HashMapStateBackend stateBackend = new HashMapStateBackend();
// 2. 设置状态后端
env.setStateBackend(stateBackend);
env.getCheckpointConfig().setCheckpointStorage("file:///E://checkpoint");
}
}下面是生成的检查点

Checkpoint 执行流程
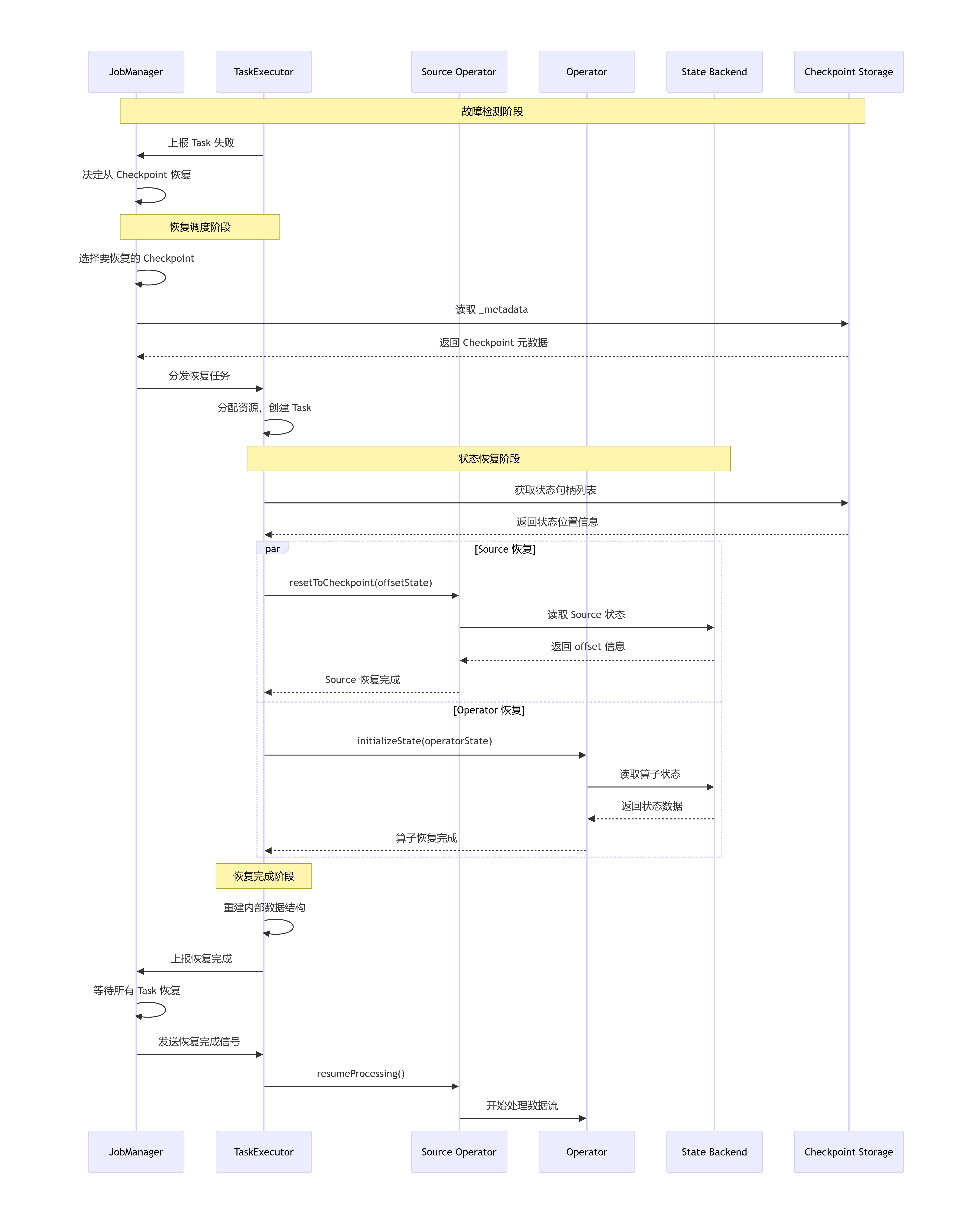
状态恢复机制
savepoint
Savepoint 是 Flink 提供的一个强大的状态快照功能。它可以被理解为在某个时间点,为你的流处理应用拍摄的一张"全局一致性"的快照。这张照片完整地捕获了:
- 所有算子的状态:例如,窗口累计的内容、键控状态中的值、Kafka消费者消费的偏移量等。
- 整个作业的执行图:即数据流图的结构。
Savepoint 的核心设计目标是用于有计划的手动备份和恢复,例如进行应用程序更新、Flink版本升级、集群迁移、A/B测试或暂停与重启任务。
Savepoint 与 Checkpoint 的区别
| 特性 | Checkpoint | Savepoint |
|---|---|---|
| 主要目的 | 容错恢复。用于在任务失败时自动恢复,保证 "精确一次"或 "至少一次"语义。 | 有计划的手动操作。用于应用升级、迁移、扩缩容、重启等运维操作。 |
| 触发机制 | 自动触发,由 Flink 根据配置的时间间隔自动、周期性地创建。 | 手动触发,或通过停止任务时配置触发。 |
| 生命周期 | 短暂保存,通常任务停止后就会被删除。 | 持久保存,除非用户手动删除,否则会一直存在。 |
| 存储格式 | 轻量、高效的私有二进制格式,可能随Flink版本变化而优化。 | 标准化格式,更注重兼容性和可移植性,结构更稳定。 |
| 性能影响 | 设计目标是对运行时影响最小,可能采用增量检查点、异步屏障快照等技术。 | 对性能要求相对宽松,因为是有计划的操作,更看重可靠性和完整性。 |
| 状态大小 | 可能只包含增量变化,以节省存储空间和I/O。 | 通常是完整的全局状态快照。 |
如何使用 Savepoint
java
//停止作业生成保存点
./bin/flink stop --savepointPath file:///xxx/checkpoints
//从保存点开始执行作业
./bin/flink run -s file:///xxx/checkpoints/savepoint-<uuid> your-job.jar关于失败重试
在使用Flink跑数据的过程中出现了网络链接中断导致Flink作业失败的问题。
java
flink--taskexecutor-0-taskmanager-6f8c698d99-qmlnd.log-Caused by: akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@jobmanager.base.svc.cluster.local:6123/user/rpc/jobmanager_34#700942522]] after [10000 ms]. Message of type [org.apache.flink.runtime.rpc.messages.RemoteFencedMessage]. A typical reason for `AskTimeoutException` is that the recipient actor didn't send a reply.
flink-taskexecutor-0-taskmanager-6f8c698d99-qmlnd.log-2025-09-24 03:28:08.426 [flink-akka.actor.default-dispatcher-16] INFO o.apache.flink.runtime.taskexecutor.DefaultJobLeaderService Could not resolve JobManager address akka.tcp://flink@jobmanager.base.svc.cluster.local:6123/user/rpc/jobmanager_39, retrying in 10000 ms: Could not connect to rpc endpoint under address akka.tcp://flink@jobmanager.base.svc.cluster.local:6123/user/rpc/jobmanager_39.复现问题
使用tc工具模拟网络延时
java
# 使用 tc 工具模拟网络延迟(在 Pod 内执行)
kubectl exec -it <taskmanager-pod> -- apt-get update && apt-get install -y iproute2
# 添加 5秒延迟模拟网络问题
kubectl exec -it <taskmanager-pod> -- tc qdisc add dev eth0 root netem delay 5s
# 运行测试作业,观察超时行为
kubectl exec -it <taskmanager-pod> -- /opt/flink/bin/flink run \
-c org.apache.flink.streaming.examples.socket.SocketWindowWordCount \
/opt/flink/examples/streaming/SocketWindowWordCount.jar \
--port 9000
# 恢复网络
kubectl exec -it <taskmanager-pod> -- tc qdisc del dev eth0 root问题成功复现,然后就是去解决这个问题,首先想到的就是增加网络延时的时长
java
# Akka 通信配置 - 大幅增加容忍度
akka.ask.timeout: 300s # 300秒 = 5分钟
akka.tcp.timeout: 300s # 300秒 = 5分钟
akka.watch.heartbeat.interval: 30s # 增加检测间隔
akka.watch.heartbeat.pause: 300s # 300秒 = 5分钟
# Flink 心跳配置(关键!)
heartbeat.timeout: 300000 # 300秒 = 5分钟(原来60秒)
heartbeat.interval: 30000 # 30秒发送一次心跳(减少频率)增加了超时时间之后使用tc根据模拟网络延时,确实是不会在时间点内报错了。
但是随后又出现了一个很奇怪的问题,我现在jobManager和taskManager都配置5分钟的容忍度,然后我测试延时10-20秒 Flink作业确实没有超时失败,但是我把延时增加到60s之后他还是触发了超时失败。
这是怎么回事了?
原因是 Akka 框架有内置的超时限制,即使我配置了5分钟,但某些 Akka 内部机制有硬编码的上限。
添加 Akka 远程传输配置
java
# 在 flink-conf.yaml 中添加以下 Akka 专用配置
akka.remote.transport-failure-detector.heartbeat-interval: 60s
akka.remote.transport-failure-detector.acceptable-heartbeat-pause: 300s
akka.remote.watch-failure-detector.heartbeat-interval: 60s
akka.remote.watch-failure-detector.acceptable-heartbeat-pause: 300s
akka.remote.retry-gate-closed-for: 60s
akka.remote.transport.timeout: 300s之后就是处理如果网络延时超过了我配置的最大容忍时长怎么办?
配置失败重试策略
java
# ==================== 重启策略配置 ====================
# 作业失败时的自动重启策略
# 使用指数退避重启策略
restart-strategy: exponential-delay
# 最大重启尝试次数
restart-strategy.exponential-delay.attempts: 20
# 初始重启延迟时间
restart-strategy.exponential-delay.initial-backoff: 15000 # 15秒
# 最大重启延迟时间
restart-strategy.exponential-delay.max-backoff: 600000 # 600秒 = 10分钟
# 退避乘数(每次延迟时间乘以这个系数)
restart-strategy.exponential-delay.backoff-multiplier: 2.0 # 延迟时间翻倍在验证的时候发现有的任务重启了有的任务没有触发重启,然后在代码中发现了原因
java
// 设置执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String parallelism = NacosConfig.getProperty("UserSourceTagJob.parallelism");
env.setParallelism(Integer.parseInt(parallelism));
// 纯内存状态
env.setStateBackend(new HashMapStateBackend());
env.setRestartStrategy(RestartStrategies.noRestart());我在代码里设置了禁止重试
java
env.setRestartStrategy(RestartStrategies.noRestart());以下是完整的配置
JobManager的flink.conf配置
java
JobManager
# ==================== Akka 通信配置 ====================
# (与 TaskManager 配置相同,保持对称)
akka.ask.timeout: 120s
akka.tcp.timeout: 60s
akka.watch.heartbeat.interval: 15s
akka.watch.heartbeat.pause: 120s
# ==================== Flink 心跳配置 ====================
# (与 TaskManager 配置相同,保持对称)
heartbeat.timeout: 180000
heartbeat.interval: 20000
# ==================== Akka 远程传输层配置 ====================
# (与 TaskManager 配置相同,保持对称)
akka.remote.transport-failure-detector.heartbeat-interval: 60s
akka.remote.transport-failure-detector.acceptable-heartbeat-pause: 180s
akka.remote.watch-failure-detector.heartbeat-interval: 60s
akka.remote.watch-failure-detector.acceptable-heartbeat-pause: 180s
akka.remote.retry-gate-closed-for: 120s
akka.remote.transport.timeout: 120s
akka.remote.initial-system-message-delivery-timeout: 120s
# ==================== 重启策略配置 ====================
# 作业失败时的自动重启策略
# 使用指数退避重启策略
restart-strategy: exponential-delay
# 最大重启尝试次数
restart-strategy.exponential-delay.attempts: 20
# 初始重启延迟时间
restart-strategy.exponential-delay.initial-backoff: 15000 # 15秒
# 最大重启延迟时间
restart-strategy.exponential-delay.max-backoff: 600000 # 600秒 = 10分钟
# 退避乘数(每次延迟时间乘以这个系数)
restart-strategy.exponential-delay.backoff-multiplier: 2.0 # 延迟时间翻倍
# ==================== 资源管理配置 ====================
# JobManager 管理资源和 Slot 的配置
# TaskManager 无响应超时时间(与 TaskManager 的 registration.timeout 对应)
resourcemanager.taskmanager-timeout: 1800000 # 1800秒 = 30分钟
# Slot 请求超时时间(申请 Slot 的最大等待时间)
slotmanager.request-timeout: 600000 # 600秒 = 10分钟
# 资源需求检查延迟
slotmanager.requirement-check-delay: 10000 # 10秒 = 10000毫秒
# 最小 Slot 数量要求
slotmanager.number-of-slots.min: 1
# 与 ResourceManager 重连间隔
resourcemanager.reconnect-interval: 10000 # 10秒TaskManager的flink.conf配置
java
TaskManager的配置
# ==================== Akka 通信配置 ====================
# Akka 是 Flink 底层使用的分布式通信框架
# RPC 请求超时(单个请求的最大等待时间)
akka.ask.timeout: 120s # 120秒 = 2分钟 - 单个请求最大等待时间
# TCP 连接建立超时
akka.tcp.timeout: 60s # 60秒 = 1分钟 - TCP连接超时
# 节点健康检测间隔(发送心跳的频率)
akka.watch.heartbeat.interval: 15s # 每15秒发送一次健康检测
# 节点无响应容忍时间(多久没响应才认为节点故障)
akka.watch.heartbeat.pause: 120s # 120秒 = 2分钟 - 故障检测延迟
# ==================== Flink 心跳配置 ====================
# Flink 自身的心跳机制,用于检测组件存活状态
# 心跳超时时间(多久收不到心跳认为节点死亡)
heartbeat.timeout: 180000 # 180秒 = 3分钟 - 心跳超时
# 心跳发送间隔
heartbeat.interval: 20000 # 20秒发送一次心跳
# ==================== Akka 远程传输层配置 ====================
# Akka 网络传输层的故障检测配置
# 传输层心跳间隔
akka.remote.transport-failure-detector.heartbeat-interval: 60s
# 传输层可接受的心跳暂停时间
akka.remote.transport-failure-detector.acceptable-heartbeat-pause: 180s
# watch机制心跳间隔(用于监控远程节点)
akka.remote.watch-failure-detector.heartbeat-interval: 60s
# watch机制可接受的心跳暂停时间
akka.remote.watch-failure-detector.acceptable-heartbeat-pause: 180s
# 连接失败后重试间隔(连接失败后多久尝试重新连接)
akka.remote.retry-gate-closed-for: 120s
# 远程传输操作超时
akka.remote.transport.timeout: 120s
# 初始系统消息传递超时
akka.remote.initial-system-message-delivery-timeout: 120s
# ==================== 资源管理配置 ====================
# TaskManager 注册相关配置
# TaskManager 注册到 JobManager 的超时时间
taskmanager.registration.timeout: 30 min # 30分钟 - 注册过程超时时间
# 最大注册等待时间(Infinity 表示无限等待)
taskmanager.maxRegistrationDuration: Infinity # 风险:可能造成资源无法释放