工业控制SCADA(数据采集与监控系统)是智能制造、能源电网、轨道交通等关键基础设施的"神经中枢",其核心诉求是毫秒级延时响应 与99.999%以上的高可靠性------例如智能制造中机械臂协同控制需≤10ms响应,电网故障切除需≤20ms,轨道交通信号控制需≤5ms,任何超出阈值的延时或指令丢失都可能引发设备损坏、生产线停产甚至安全事故。然而,基于中心化云计算、传统数据库与普通交换机构建的SCADA系统,在工业控制的严苛需求下,普遍暴露不可控延时、控制指令失效、并发能力不足及单点故障瘫痪等致命缺陷。本文将从技术原理出发,结合实际案例深度剖析问题根源,并论证分布式边缘计算模式的必要性及数据库的合理定位。
一、中心化SCADA系统的架构短板:问题产生的底层逻辑
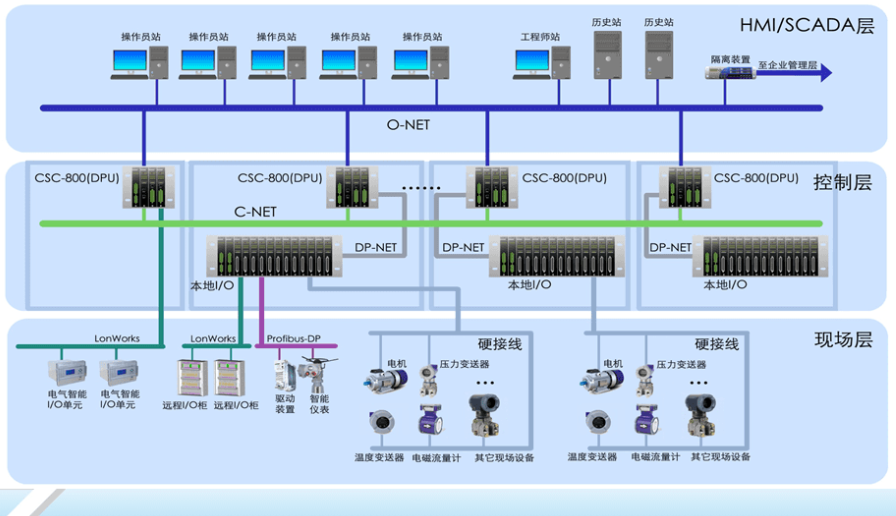
传统中心化SCADA系统的典型架构为"远端采集节点(传感器/PLC)→普通交换机网络→中心化云计算平台/数据库→中心化控制节点→普通交换机网络→远端执行机构"。其核心特征是"数据向上汇聚、指令向下分发",所有核心计算、存储与控制决策均依赖中心节点,网络传输依赖层级化普通交换机。这种架构在工业控制场景下的先天不足,直接导致了延时与可靠性问题,具体可从四大维度拆解。
二、核心问题一:不可控延时的三重技术根源,突破工业控制阈值
工业控制对延时的要求通常在1-50ms之间(不同场景差异),而中心化SCADA系统的延时由"数据库读写延时+网络传输延时+中心节点处理延时"叠加而成,且各环节均存在不可控变量,最终导致总延时远超阈值。
1. 传统数据库读写机制:工业实时控制的"性能瓶颈"
中心化SCADA系统中,所有远端采集的实时数据(如传感器的温度、压力、电流数据)需先写入中心数据库,控制节点再从数据库读取数据进行决策,决策生成的控制指令需再次写入数据库备案后下发------这种"读写闭环"完全无法匹配工业控制的实时性要求,技术根源如下:
-
磁盘IO与缓存机制限制:传统关系型数据库(如MySQL、Oracle)或分布式数据库(如Hadoop生态)的核心设计目标是数据一致性与存储可靠性,而非实时读写。数据写入时需经过"日志记录(WAL)→缓存同步→磁盘持久化"等流程,即使采用SSD硬盘,单次随机读写延时也普遍在10-50ms;若采用机械硬盘,延时可高达100-200ms。例如某汽车零部件智能制造产线,采用中心化SCADA系统,PLC采集的机械臂运动姿态数据(每秒100条)需写入中心MySQL数据库,再由控制节点读取数据调整运动参数,仅数据库读写环节就产生了35ms延时,导致机械臂抓取精度从±0.1mm下降至±0.5mm,不合格率提升20%。
-
锁机制与并发排队延迟:工业控制场景下,多远端节点(如成百上千个传感器)会并发向中心数据库写入数据,控制节点同时并发读取数据,数据库为保证数据一致性会启动行锁、表锁机制,导致并发请求排队等待。某化工园区的SCADA系统,接入200个反应釜的温度、压力传感器,每100ms上报一次数据,高峰期数据库并发写入请求达2000次/秒,锁等待导致的读写延时超80ms,远超反应釜控制所需的30ms阈值,多次引发温度波动过大的安全隐患。
-
数据冗余处理耗时:中心化数据库为保证可靠性,通常会开启数据备份、冗余校验等功能,这些操作会进一步占用计算资源,增加读写延时。例如某电网SCADA系统的中心数据库,为满足电力数据的安全性要求,开启了实时异地备份功能,导致单条故障电流数据的写入延时从25ms增至60ms,超出了电网故障切除的20ms临界延时,曾引发一次局部电网过载跳闸事故。
2. 普通交换机与网络架构:网络风暴引发的"传输拥堵"
中心化SCADA系统的网络依赖普通以太网交换机,采用"层级化路由"架构(远端节点→接入层交换机→汇聚层交换机→核心层交换机→中心节点),这种架构极易因网络风暴、带宽不足等问题导致传输延时剧增,技术根源与案例如下:
-
广播风暴的不可控性:普通交换机默认支持广播功能,工业控制场景下的设备接入量大、协议复杂(如Modbus、OPC UA、DNP3等),若某一设备故障(如传感器短路、PLC异常),可能会持续发送大量广播包,引发广播风暴,导致整个网络带宽被占满。某地铁环境监控SCADA系统,接入层采用普通千兆交换机,因一台新风系统的传感器故障,持续发送广播包,10分钟内导致接入层交换机带宽占用率从10%升至100%,控制指令从中心节点到通风阀门的传输延时从8ms增至520ms,车厢内温度失控超1小时。
-
层级路由的累积延时:数据从远端节点到中心节点需经过多层交换机转发,每一层转发都会产生"存储-转发"延时(普通交换机单跳转发延时约0.5-1ms),若跨区域部署,物理距离带来的传播延时会进一步叠加。例如某风电場的SCADA系统,风机分布在50平方公里范围内,中心节点位于市区,数据需经过4层交换机转发,物理距离导致的传播延时约20ms,叠加转发延时后,总传输延时达25ms,导致风机变桨控制不及时,风能利用率下降15%。
-
QoS机制缺失导致的优先级混乱:普通交换机缺乏工业级的QoS(服务质量)保障机制,无法区分控制指令、实时数据与非关键数据(如视频监控、报表统计数据)的优先级。某智能制造车间的SCADA系统,同时传输机械臂控制指令(关键)与车间视频监控数据(非关键),当视频数据占用大量带宽时,控制指令数据包被挤压,传输延时从10ms增至45ms,机械臂出现动作卡顿,导致产品碰撞损坏,单次损失超10万元。
3. 中心节点处理瓶颈:并发请求下的"决策延迟"
中心化SCADA系统的所有控制决策均由中心服务器完成,当远端节点数量激增、并发数据采集与控制请求增多时,中心服务器的CPU、内存资源会成为瓶颈,导致决策延时增加。某新能源汽车工厂的总装线SCADA系统,接入5条产线、共800个设备节点,高峰期每秒产生15000条数据采集请求和3000条控制指令请求,中心服务器的CPU占用率长期维持在90%以上,控制决策延时从12ms增至70ms,导致产线节拍从60秒/台降至85秒/台,产能下降30%。
三、核心问题二:控制指令不可靠与单点故障,系统瘫痪的致命风险
工业控制的可靠性要求"控制指令100%送达、系统无单点故障",而中心化SCADA系统的架构设计直接导致了控制指令不可靠,且存在严重的单点故障风险。
1. 控制指令不可靠:传输丢失与执行滞后
中心化架构下,控制指令需从中心节点经多层网络传输至远端执行机构,过程中易因网络拥塞、数据包冲突等问题导致丢失或滞后,具体案例如下:
-
网络拥塞导致指令丢失:某化工反应釜的温度控制SCADA系统,当反应釜温度接近阈值时,中心节点下发"降温"控制指令,但此时网络因传感器数据并发上报出现拥塞,指令数据包丢失率达8%,导致反应釜温度持续升高,触发紧急停车,造成2小时停产损失。
-
延时叠加导致执行滞后:某智能仓储的AGV小车控制SCADA系统,中心节点下发"转向"指令,经数据库备案(20ms)、网络传输(15ms)、AGV控制器响应(10ms),总延时达45ms,AGV小车因转向滞后与货架碰撞,损坏货物价值5万元。
2. 单点故障风险:中心节点失效引发系统整体瘫痪
中心化SCADA系统的中心服务器、数据库、核心交换机均为单点核心组件,一旦其中任一组件失效,整个系统将完全瘫痪,无法完成数据采集与控制决策,案例触目惊心:
-
中心数据库故障:某钢铁厂的能源管理SCADA系统,中心Oracle数据库因磁盘阵列故障宕机,导致所有高炉的煤气流量、电力消耗数据无法采集,控制指令无法下发,全厂能源供应中断,停产4小时,直接经济损失超200万元。
-
核心交换机故障:某核电站的辅助系统SCADA系统,核心交换机因硬件故障失效,中心节点与远端水泵、冷却风机等执行机构的通信中断,冷却系统无法正常工作,触发核安全紧急预警,后续排查与恢复耗时6小时。
-
中心服务器故障:某城市轨道交通的信号控制SCADA系统,中心服务器因电源故障宕机,导致沿线5个车站的信号机无法正常工作,列车调度中断,线路停运2.5小时,影响10万余名乘客出行。
四、核心问题三:大并发数采与控制响应不足,适配不了工业互联网转型
随着工业互联网的发展,智能工厂、智慧电网等场景的远端设备节点数量激增(如一条智能产线的传感器数量从几十个增至上千个),数据采集频率从秒级降至毫秒级,控制指令并发量从每秒几十条增至几千条,而中心化SCADA系统完全无法应对这种大并发需求:
-
数据采集并发瓶颈:某智慧电网的配网SCADA系统,接入1000个台区的智能电表,每个电表每100ms上报一次负荷数据,每秒并发采集请求达10000次,而中心服务器的网卡带宽(10G)与CPU处理能力仅能支撑6000次/秒的并发请求,导致大量数据积压,负荷监控滞后超1分钟,无法及时发现台区过载问题。
-
控制指令并发瓶颈:某柔性制造车间的SCADA系统,同时控制50台机械臂、30台AGV小车,每秒并发控制指令达5000条,中心控制器的内存资源不足,导致指令队列溢出,部分指令被丢弃,产线出现多设备协同紊乱,停产1.5小时。
五、破局之道:分布式边缘计算模式,适配高可靠低延时工业控制
针对中心化SCADA系统的上述缺陷,分布式边缘计算模式通过"计算下沉、分布式协同、轻量化通信"的核心设计,从根源上解决了延时、可靠性、并发及单点故障问题,成为高可靠低延时工业控制的必然选择。
1. 分布式边缘计算的核心架构优势
-
计算下沉,消除数据库实时读写延时:将数据采集、控制决策等实时性需求高的功能下沉至边缘节点(如工业边缘网关、边缘控制器),边缘节点本地处理数据、生成控制指令,无需经过中心数据库的读写闭环,延时可降至1-10ms。例如某邯钢的能源管理系统,采用分布式边缘计算模式,边缘节点本地处理高炉煤气流量数据,控制指令直接下发至执行机构,总延时仅5ms,较原中心化架构的80ms延时提升16倍。
-
分布式协同,消除单点故障风险:边缘节点采用对等网络架构,无中心节点依赖,各节点通过分布式协议协同工作,单个边缘节点故障时,其他节点可自动接管其功能,系统整体不受影响。某天津地铁的环境监控系统,部署20个边缘节点,某一节点故障后,相邻节点在100ms内完成功能接管,控制指令下发未出现任何中断,系统可靠性提升至99.999%。
-
工业级网络优化,避免网络风暴与传输延时:采用工业级分布式交换机,支持分区广播域、优先级QoS机制,可将控制指令数据包的优先级设为最高,避免被非关键数据挤压;同时,边缘节点之间可直接通信,无需经过多层路由,传输延时大幅降低。某智能制造车间的AGV控制系统,采用工业级分布式交换机,控制指令传输延时从45ms降至8ms,数据包丢失率降至0.01%以下。
-
并发能力提升,适配大规模设备接入:分布式架构下,并发数据采集与控制请求由多个边缘节点分布式承载,而非集中于单一中心节点,系统并发处理能力随边缘节点数量线性提升。某新能源汽车工厂的总装线SCADA系统,部署10个边缘节点,每个节点负责一条产线的设备管理,并发数据采集能力从15000次/秒提升至50000次/秒,控制指令并发处理能力从3000条/秒提升至15000条/秒,完全满足大规模设备接入需求。
2. 数据库的合理定位:从"实时核心"回归"存储分析"
分布式边缘计算模式并非完全摒弃数据库,而是重新定义其角色------数据库不再参与实时数据采集与控制指令的闭环流程,仅作为"历史数据存储中心"和"非延时应用的数据分析中心",具体应用场景如下:
-
历史数据存储:边缘节点处理后的实时数据(如传感器原始数据、控制指令记录)定期同步至中心数据库存储,用于数据追溯、合规审计等。例如某化工园区的SCADA系统,边缘节点每小时将处理后的温度、压力数据同步至中心数据库,存储周期为3年,既保证了数据的可追溯性,又不影响实时控制。
-
非延时数据分析:利用中心数据库的海量数据进行离线分析、趋势预测、运维优化等非实时应用。例如某风电場的SCADA系统,通过中心数据库存储的历年风速、发电量数据,进行风机运维预测分析,提前排查设备故障隐患,提升风机利用率,而这些分析工作不会对风机的实时变桨控制产生任何影响。
-
可视化展示:中心数据库的数据通过BI工具进行可视化展示,为管理人员提供决策支持(如产能统计、能耗分析报表),这些展示需求对延时无要求,完全适配数据库的性能特点。
六、案例验证:分布式边缘计算的工业落地成效
某智能制造企业的发动机装配线SCADA系统,原采用中心化架构,存在控制延时超50ms、并发能力不足、单点故障风险高等问题,改造为分布式边缘计算模式后,成效显著:
-
控制延时从50ms降至8ms,机械臂协同精度提升至±0.1mm,产品不合格率下降20%;
-
并发数据采集能力从8000次/秒提升至30000次/秒,支持1500个传感器节点接入;
-
消除单点故障风险,系统可靠性从99.5%提升至99.999%,全年停产时间从48小时降至2.6小时;
-
中心数据库仅用于存储历史数据和生成产能报表,读写压力降低70%,运行稳定性显著提升。
七、结论
基于中心化云计算、数据库与普通交换机的SCADA系统,因数据库实时读写瓶颈、网络风暴引发的传输延时、中心节点并发处理不足及单点故障风险,无法满足工业控制对高可靠、低延时的核心需求,已成为工业互联网转型的主要障碍。而分布式边缘计算模式通过"计算下沉、分布式协同、工业级网络优化",从根源上解决了上述问题,实现了1-10ms的低延时控制与99.999%以上的高可靠性。同时,将数据库重新定位为"历史数据存储中心"与"非延时数据分析中心",既保留了数据的可追溯性与分析价值,又避免了其对实时控制的性能拖累。
未来,随着工业控制场景的规模化、智能化升级,分布式边缘计算将成为高可靠低延时工业控制的主流架构,推动智能制造、智慧能源、轨道交通等关键基础设施的安全高效运行,为工业互联网转型提供核心技术支撑。