平时我们经常会听到进程,但是如果说要具体描述它,我们却又难以组织语言。这个进程到底是个什么东西呢?
要了解进程,首先我们要知道,一个进程是从什么时候开始诞生的。程序是静态的,没有被访问时被储存在磁盘中。我们要执行这个程序就要把它从磁盘中拿出来放到CPU中,当操作系统为我们要做的这件事(执行一个磁盘中的程序)分配内存时,一个进程便诞生了。在一个进程诞生时,为了方便管理,每一个进程都会有一个"名字"------进程pid。
进程PCB
操作系统需要同时处理多个进程,如何有效管理这些进程呢?关键方法是"先描述再组织":首先用结构体记录每个进程的信息,然后将所有进程放入容器中进行统一管理。
在Linux系统中,这个管理进程的结构体通常称为task_struct,它包含了描述一个进程运行状态所需的所有信息。
cpp
// Linux内核中的task_struct(极度简化版本)
struct task_struct {
// 1. 标识信息
pid_t pid; // 进程ID
pid_t tgid; // 线程组ID
uid_t uid, euid; // 用户ID
// 2. 状态信息
volatile long state; // 运行状态(运行/就绪/阻塞等)
int exit_state; // 退出状态
// 3. 调度信息
int prio; // 动态优先级
int static_prio; // 静态优先级
struct sched_entity se; // 调度实体
// 4. 内存管理
struct mm_struct *mm; // 内存描述符
// 5. 文件系统
struct files_struct *files; // 打开的文件
// 6. 信号处理
struct signal_struct *signal; // 信号处理结构
// 7. 进程关系
struct task_struct *parent; // 父进程
struct list_head children; // 子进程链表
struct list_head sibling; // 兄弟进程链表
// 8. 时间统计
u64 utime, stime; // 用户/内核态CPU时间
// 9. 组织链接
struct list_head tasks; // 所有进程的链表节点
// ... 还有很多很多字段(Linux 5.x内核中有几百个字段!)
};当一个进程诞生时,操作系统会自动为其初始化task_struct结构体。这个结构体中的数据会被放到多个数据结构中。
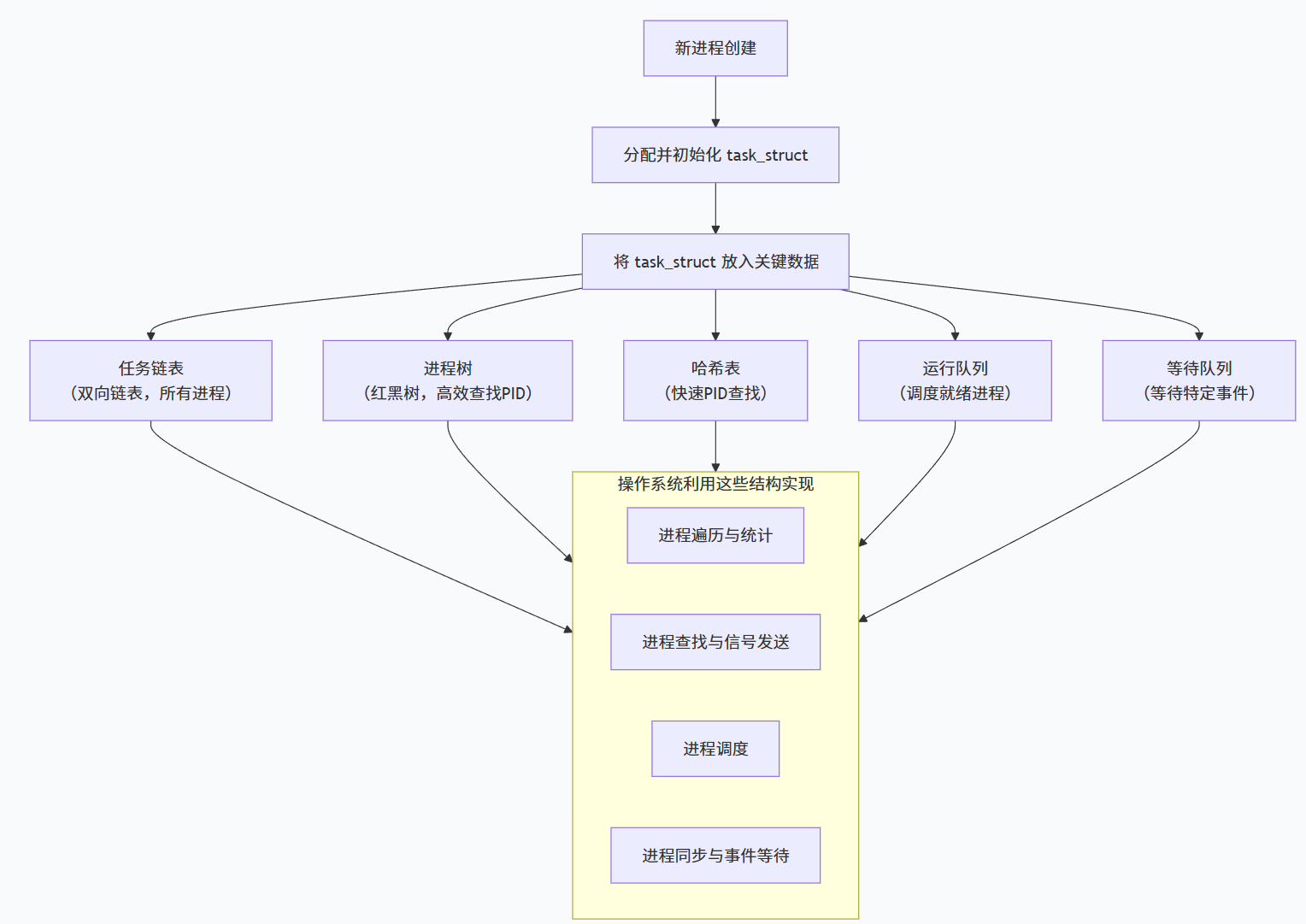
操作系统依据不同的键值将全局链表放到不同的数据结构中,方便完成不同的功能

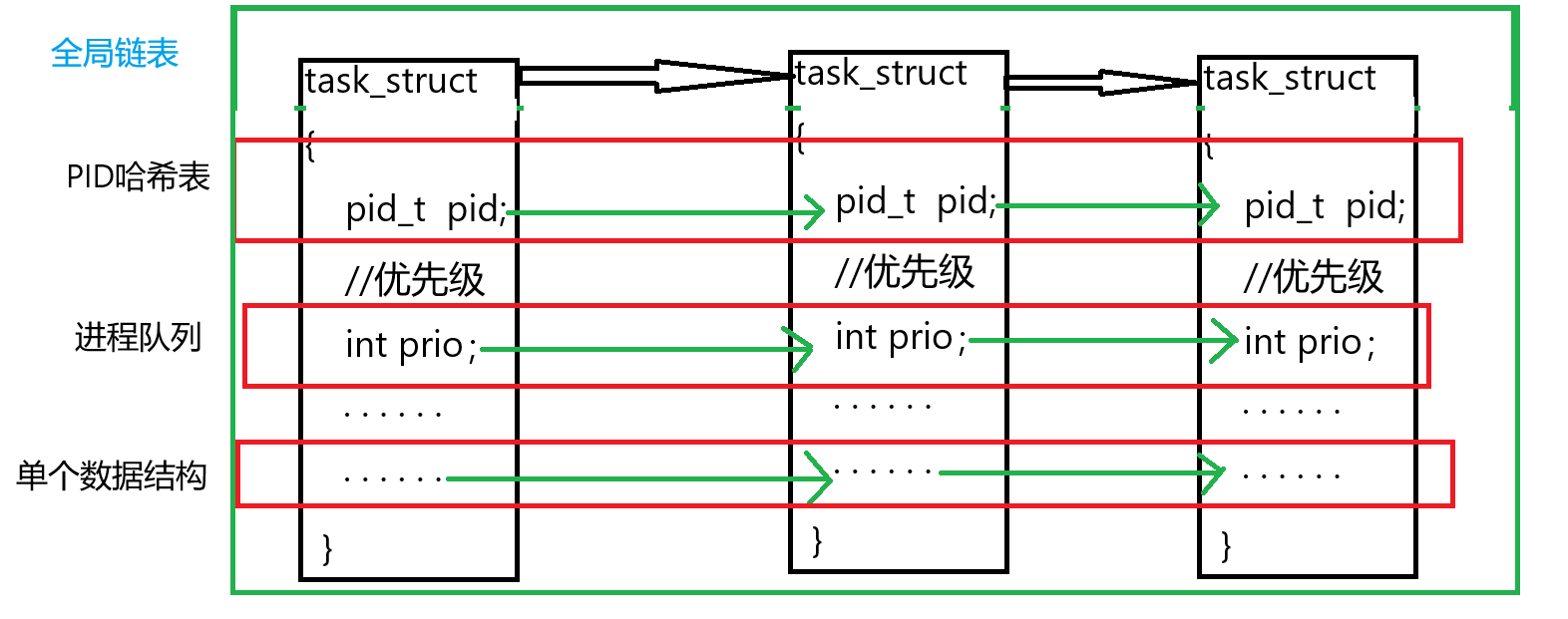
PCB加载过程
计算机执行程序时,必须通过CPU和内存协同工作。首先,磁盘中的可执行程序代码和数据会被加载到内存中。操作系统会创建task_struct(进程控制块)结构体,用于存储进程的所有属性信息,该结构体包含指向进程所需代码和数据的指针。同时,结构体还维护着指向下一个进程节点的指针。值得注意的是,操作系统本身是一个具有最高优先级的特殊进程,它负责管理其他所有进程,因此总是最先被加载到内存中运行。一个进程=进程PCB+自己的代码和数据。
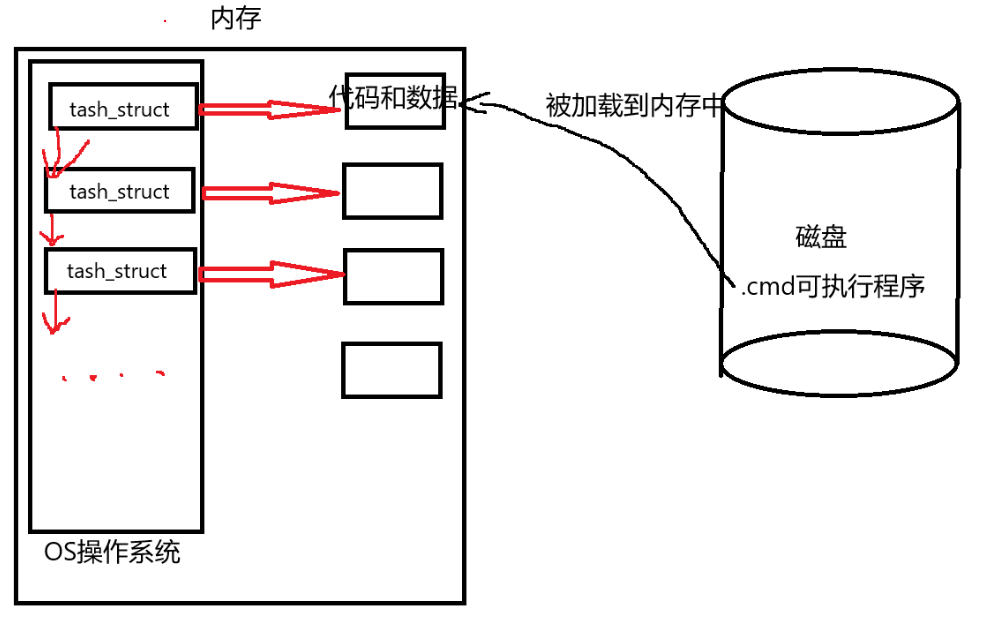
task_struct被放在一个双向链表中,这个双向链表被叫做进程列表。进程列表中的进程在被调度时被放到CPU中执行,执行完会变成僵尸状态(一种进程状态后面会讲到),等待父进程回收。一个进程结束后,调用exit()会发生。
cpp
// 进程结束的简化流程
void do_exit(long code)
{
// 1. 设置退出状态
current->exit_code = code;
// 2. 状态变为 EXIT_ZOMBIE
set_current_state(TASK_ZOMBIE);
// 3. 通知父进程
notify_parent(current, SIGCHLD);
// 4. 释放部分资源,但保留task_struct
exit_files(current); // 关闭文件
exit_fs(current); // 文件系统资源
exit_sem(current); // 信号量
// ... 但task_struct还在!
// 5. 调用调度器,不再被调度
schedule();
// 此时进程已是僵尸,等待父进程wait()
}查看进程
getpid
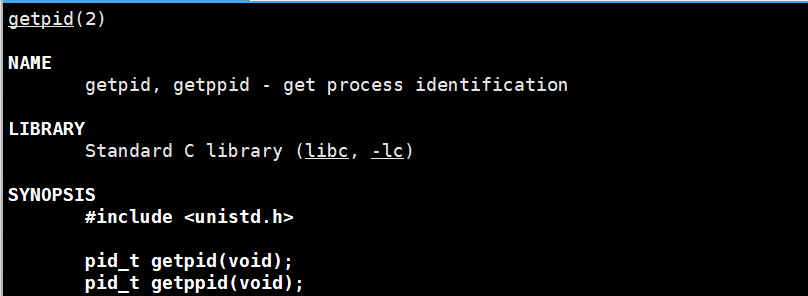
getpid 是 Linux/Unix 系统中获取当前进程 ID(PID) 的系统调用(对应手册页章节 2,即 man 2 getpid),本质是程序向内核发起的请求,返回当前运行进程的唯一标识(PID)。与之配套的还有 getppid(),用于获取当前进程的父进程 ID(PPID)。它们的返回值都是pid_t,这是linux系统级的数据类型,getpid和getppid总是成功,返回进程的pid,若父进程退出则返回1。
系统调用:系统调用是用户态程序向操作系统内核请求服务的接口 ,是用户程序与内核之间的 "桥梁",用于让应用程序获得内核级别的资源或功能(比如操作硬件、管理进程、访问文件等)。
cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
while(1)
{
sleep(1);
printf("\n");
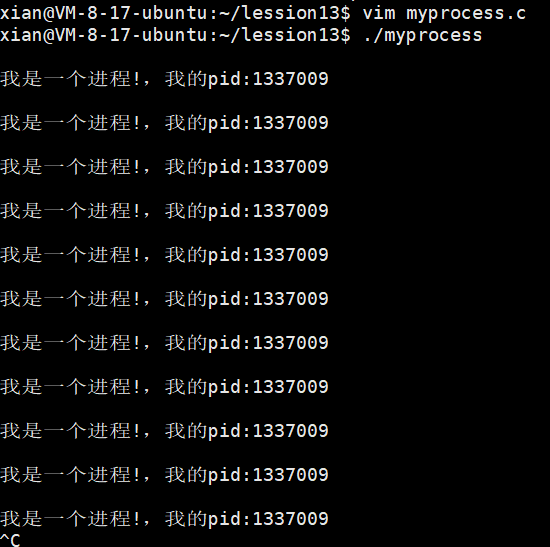
printf("我是一个进程!,我的pid:%d\n",getpid());
}
}
ps命令
ps(Process Status)是 Linux 中静态查看进程快照 的核心命令,它能列出命令执行瞬间的进程信息(区别于 top/htop 的动态监控),是学习 Linux 进程管理的入门必备,也是排查程序运行状态、资源占用的高频工具。

bash
# 命令1:最基本的进程查找
ps axj | grep myprocess

重复执行两次:
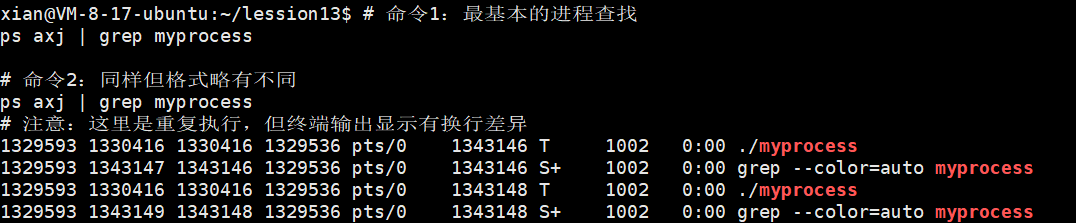
为什么第一次和第二次执行的结果不一样呢?因为执行grep命令本身也是一个进程。两次从grep进程的pid不同,第一次查看的时候shell会创建grep进程,每一个新的进程pid都不相同,调用结束后会销毁,第二次重复以上操作导致两次grep的pid不相同。
bash
# 命令3:查看ps输出列的含义
ps ajx | head -1
# 输出:
# PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND输出表头:

bash
# 命令4:使用&&连接两个命令
ps ajx | head -1 && ps axj | grep myprocess
# 正确执行:先显示表头,再显示匹配结果
bash
# 命令5:使用grep -v排除grep进程
ps ajx | head -1 && ps axj | grep myprocess | grep -v grep
# 最终只显示目标进程,不显示grep进程
proc目录
ps命令的本质是通过读取proc目录中的信息获取进程信息。/proc(process information pseudo-file system)是Linux内核提供的一个虚拟文件系统(内存级),它以文件形式提供系统和进程信息的接口,linux下一切皆文件,进程的所以信息都被放到文件中。
ps命令的本质与/proc文件系统
ps命令的工作原理
`ps`(process status)命令的本质是通过读取Linux内核提供的 **`/proc`虚拟文件系统**来获取进程信息。与传统的从内核数据结构直接读取不同,Linux采用了一种优雅的"文件接口"方式。
/proc:进程信息的虚拟文件系统
`/proc`(Process Information Pseudo-file System)是Linux内核提供的一个虚拟文件系统,它不占用实际磁盘空间,而是以文件形式提供系统和进程信息的实时接口。
"Linux下一切皆文件" - 包括运行中的进程信息也被抽象为文件系统中的虚拟文件。
进程信息的组织方式
每个运行中的进程都在`/proc`下有一个以PID命名的目录:
```bash
/proc/
├── 1/ # PID为1的进程(通常是init/systemd)
│ ├── cmdline # 启动命令行
│ ├── status # 进程状态信息
│ ├── fd/ # 打开的文件描述符
│ ├── exe -> /sbin/init # 可执行文件链接
│ └── ...
├── 1234/ # 某个具体进程
├── cpuinfo # 系统CPU信息
├── meminfo # 系统内存信息
└── ...

查看单个进程的信息:
cwd:当前工作路径
在 Linux 系统中 "一切皆文件",而所有文件都对应着相应的路径,多数情况下我们创建文件时只需输入文件名即可,这是因为系统会自动为文件名拼接当前路径,且该路径会被存储在进程控制块(PCB)中;cwd(Current Working Directory,当前工作目录)是每个进程运行时的一项重要属性,它决定了相对路径的解析基准 ------ 当我们使用./file.txt或../dir/这类相对路径时,系统会基于此目录完成路径解析,也就是自动拼接上cwd对应的当前工作路径。
技术实现
在进程控制块中的存储
在Linux内核中,每个进程的当前工作目录确实存储在进程控制块(`task_struct`)中:
cpp
struct task_struct {
// ...
struct fs_struct *fs; // 文件系统相关信息
// ...
};
struct fs_struct {
// ...
struct path pwd; // 当前工作目录(cwd)
struct path root; // 根目录(通常是/)
// ...
};
struct path {
struct vfsmount *mnt; // 挂载点信息
struct dentry *dentry; // 目录项(包含路径信息)
};exe:可执行文件
......
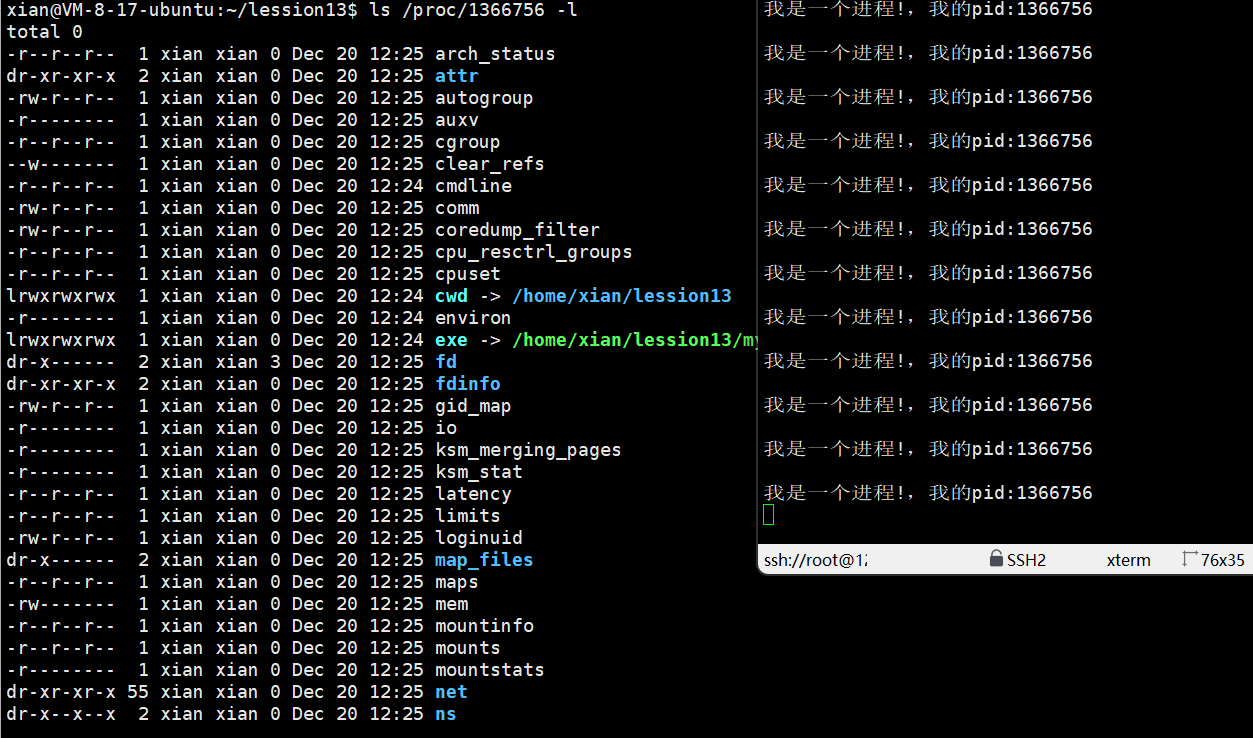
在程序运行时删除process可执行文件,程序还能继续运行,与进程有关的代码和数据在创建PCB时被拷贝到内存中了,但是运行结束之后无法再次运行,磁盘上没有这个可执行程序了,内存上的也在运行结束后被释放了。