基于Verilator模拟蜂鸟E203实现卷积神经网络
1.实验环境
1.Linux环境
1.介绍
本次实验使用WSL2在Windows11操作系统下进行。WSL2 是微软推出的一项技术,允许开发人员在 Windows 上直接运行原生的 Linux 环境(包括大多数命令行工具、实用工具和应用程序),而无需产生传统虚拟机(如 VMware、VirtualBox)那样的高额开销,也不需要配置双系统。
2.安装
1.在安装之前要确认:打开任务管理器 -> "性能" -> "CPU"。右下角"虚拟化:"应显示"已启用"。
2.按下win,搜索Windows PowerShell,以管理员身份运行即可,然后输入:
powershell
wsl --install然后等待下载完成即可,整个过程很快。
3.重启以后,如果Ubuntu没有自动启动,可以win搜索Ubuntu,进去以后设置账户密码即可(输入密码没有反应是正常的,这是Linux的保护机制,输完回车即可)。
3.迁移wsl到其他盘
默认安装在C盘,如果空间不足可以按照以下操作把WSL进行迁移,我这里迁移到了E盘:
shell
# 1. 停止 WSL
wsl --shutdown
# 2. 导出当前系统镜像到 E 盘
wsl --export Ubuntu E:\ubuntu.tar
# 3. 注销(删除)C 盘的旧系统
wsl --unregister Ubuntu
# 4. 在 E 盘创建存放目录
mkdir E:\wsldata
# 5. 将系统导入回 E 盘
wsl --import Ubuntu E:\wsldata E:\ubuntu.tar
# 6. 设置默认用户 (将 <你的用户名> 替换为你刚才设置的名字)
ubuntu config --default-user duanpenghao4.WSL的下载配置
1.如果有梯子(VPN),把梯子的端口保存到.bashrc文件中,在window终端输入nano ~/.bashrc即可跳转。
shell
# 1. 编辑配置文件
nano ~/.bashrc
# 2. 在文件末尾粘贴以下内容 (右键粘贴):
# Proxy Config
export hostip=$(ip route show | grep default | awk '{print $3}')
export https_proxy="http://${hostip}:7890"
export http_proxy="http://${hostip}:7890"
# 3. 保存退出 (Ctrl+O -> Enter -> Ctrl+X)
# 4. 立即生效
source ~/.bashrc2.也可以不用VPN,直接替换国内的镜像源(有时候也不是很稳定):
shell
# 1. 编辑源列表
sudo nano /etc/apt/sources.list
# 2. 清空文件内容,粘贴以下配置:
deb http://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ noble-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ noble-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe multiverse
# 3. 更新并安装基础依赖 (一次性装全)
sudo apt update
sudo apt install -y build-essential cmake git wget pkg-config libcairo2-dev libgraphicsmagick1-dev libpng-dev任何ctrl+o ctrl+k
2.Verilator
1.介绍
Verilator 是一个开源的、高性能的 Verilog/SystemVerilog 仿真器 。它把你的 Verilog 硬件描述代码,"翻译"成高度优化的 C++ 或 SystemC 代码。然后,你使用 C++ 编译器(如 GCC/Clang)把这些代码编译成可以在电脑 CPU 上直接运行的二进制程序。
简单来说,Verilator负责把对应的硬件电路转译成C\C++ 程序,这样就可以方便的在电脑上模拟RSICV的芯片。流程如下:
1.Read (读取):读取你的 Verilog 源码 (.v)。
2.Lint (检查):进行语法检查,报出 Warnings(比如你遇到的 UNOPTFLAT)。
3.Verilate (转换):将 Verilog 逻辑转换为 C++ 类文件 (Ve203_cpu_top.cpp/h)。
4.你的 Verilog 模块变成了一个 C++ class。
5.你的 input/output 端口变成了 class 的 member variables(成员变量)。
6.C++ Wrapper (驱动):你需要写一个 C++ main() 函数(即 tb_top.cpp)来实例化这个类,并手动控制时钟 (top->clk)。
7.Compile (编译):用 GCC/Make 编译成最终的可执行文件 (./obj_dir/Ve203_cpu_top)。
8.Run (运行):在电脑上运行这个程序,它实际上就是在模拟电路。它不带有图形界面,只产生一个波形文件,需要借助GTKWave等波形查看软件来看波形,判断仿真结果。
2.安装
如果新的WSL更新一下再安装verilator:
shell
sudo apt update && sudo apt upgrade -y打开前面安装好的WSL,后面我们不再使用windows的终端,都使用这个终端进行操作,在win里面搜索Ubuntu即可。输入这一行回车:
shell
sudo apt install -y verilator安装之后验证一下版本
shell
verilator --version输出
shell
Verilator 5.020 2024-01-01 rev (Debian 5.020-1)3.GTKWave
1.介绍
GTKWave 是一款基于 GTK+ 库开发的、全功能的开源波形查看器 (Waveform Viewer)。它常用于读取仿真器生成的信号转储文件(Dump File),以图形化的方式展示各个时刻的信号电平变化。
2.安装
shell
sudo apt install -y gtkwave4.安装其他的依赖包
接着刚才的指令输入即可:
shell
sudo apt install -y git make autoconf g++ flex bison libfl-dev5.安装交叉编译器:gcc-riscv64-unknown-elf
1.介绍
这个编译器的作用是能在我们当前x86架构上生产RiscV的机器码。这一串名字的含义是这样的:
gcc:GNU Compiler Collection。代表编译器本身
riscv64:表示编译器的服务对象是64位的RISCV
unknown:代表产商未知
elf:Executable and Linkable Format.表示编译的程序直接在riscv的裸机上运行简单来说就是一般的gcc只能把高级程序语言编译成x86的指令,然后我们现在需要运行RSICV,所以就需要这个特定的编译器。
2.安装
可以一一编译链接来进行安装,这样大家可以清晰的知道安装过程,并且自定义安装选项,缺点是耗时长,且过程容易出错。这里我们选择直接安装预编译好的版本:
shell
sudo apt install -y gcc-riscv64-unknown-elf如果输入版本号能显示版本则表明安装成功了:
shell
duanpenghao@KuapaiComputer:~$ riscv64-unknown-elf-gcc --version
riscv64-unknown-elf-gcc (13.2.0-11ubuntu1+12) 13.2.0
Copyright (C) 2023 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE6.下载蜂鸟E203的RTL
1.介绍
开源RTL代码是用硬件描述语言Verilog编写的数字电路设计文件,是构建其芯片实体的核心"蓝图"。这里详细介绍RTL里面的内容:链接1。
2.下载
shell
# 1. 创建一个工作目录
mkdir -p ~/riscv_project
cd ~/riscv_project
# 2. 克隆 E203 hbirdv2 仓库
git clone https://github.com/riscv-mcu/e203_hbirdv2.git
# 3. 进入目录查看
cd e203_hbirdv2
ls成功的安装如下:
shell
Cloning into 'e203_hbirdv2'...
remote: Enumerating objects: 1495, done.
remote: Counting objects: 100% (8/8), done.
remote: Compressing objects: 100% (8/8), done.
remote: Total 1495 (delta 2), reused 0 (delta 0), pack-reused 1487 (from 1)
Receiving objects: 100% (1495/1495), 62.36 MiB | 1.01 MiB/s, done.
Resolving deltas: 100% (730/730), done.在这之后我们可以随时用vscode查看(没有安装vscode可以安装一下,安装入口,下载下来一直next就行)
shell
# 1. 进入目录
cd e203_hbirdv2
# 2. 用 VS Code 打开当前目录
code .2.实现简单的加法器
1.核心组件
RTL代码中的e203_subsys_nice_core.v是我们本次修改的核心部分。文件路径是:~/riscv_project/e203_hbirdv2/rtl/e203/subsys/e203_subsys_nice_core.v。
我们可以打开vscode进行查看:
1.介绍
蜂鸟 E203 处理器设计了一个叫做 NICE (Nuclei Instruction Co-unit Extension) 的接口 。
- 目前里面只有简单的直通逻辑,代表没有插任何设备。
它的作用是连接 CPU 和加速器,在这个文件中,定义了一组像握手一样的信号线(Request/Response),用于 CPU 和你的加速器对话
- 输入 (Request): CPU 会把"遇到我不认识的指令(比如自定义的卷积指令)"这件事告诉这个模块,并把指令内容和数据传进来。
- 输出 (Response): 这个模块处理完(比如算完了卷积),把结果返还给 CPU。
- 访存 (Memory Access): 这个模块甚至可以绕过 CPU,直接去读写内存(这对于论文中提到的加载图片矩阵 LIM 指令至关重要)。
我们通过修改里面的内容可以实现指令的扩展。
原本的代码是芯来科技(Nuclei)官方提供的一个**"示例程序" (Demo)**。它的功能是演示如何利用 NICE 接口实现一个简单的"行累加"运算。它不是 CPU 运行所必须的核心组件。如果没有它,CPU 只是少了一个名为"行累加"的功能,完全不影响正常的启动、运行 C 语言程序或操作系统。顶部注释(Apache License 2.0)是一种非常宽松的开源协议。
2.修改代码实现简单的加法器
直接用这个代码覆盖即可:
verilog
/* Copyright 2018-2020 Nuclei System Technology, Inc.
Licensed under the Apache License, Version 2.0.
Modified for RISC-V CNN Accelerator Reproduction Test.
*/
`include "e203_defines.v"
module e203_subsys_nice_core (
input nice_clk,
input nice_rst_n,
// 1. 请求通道:CPU 发指令过来
input nice_req_valid,
output nice_req_ready,
input [`E203_XLEN-1:0] nice_req_inst,
input [`E203_XLEN-1:0] nice_req_rs1,
input [`E203_XLEN-1:0] nice_req_rs2,
// 2. 响应通道:我们把结果还给 CPU
output nice_rsp_valid,
input nice_rsp_ready,
output [`E203_XLEN-1:0] nice_rsp_rdat,
output nice_rsp_err,
// 3. 内存通道 (ICB Interface)
output nice_icb_cmd_valid,
input nice_icb_cmd_ready,
output [`E203_ADDR_SIZE-1:0] nice_icb_cmd_addr,
output nice_icb_cmd_read,
output [`E203_XLEN-1:0] nice_icb_cmd_wdata,
output [1:0] nice_icb_cmd_size,
output nice_mem_holdup,
input nice_icb_rsp_valid,
output nice_icb_rsp_ready,
input [`E203_XLEN-1:0] nice_icb_rsp_rdata,
input nice_icb_rsp_err,
// 适配信号
output nice_active
);
// --- 握手逻辑 ---
// 1. 指令请求通道:永远准备好
assign nice_req_ready = 1'b1;
// 2. 指令响应通道:有请求就立刻响应 (单周期)
assign nice_rsp_valid = nice_req_valid;
// 3. 核心计算:做加法测试
assign nice_rsp_rdat = nice_req_rs1 + nice_req_rs2;
// 4. [修复点] 内存响应通道:永远准备好接收内存返回的数据
assign nice_icb_rsp_ready = 1'b1;
// 5. 其他信号置 0 或直连
assign nice_active = nice_req_valid;
assign nice_rsp_err = 1'b0;
// 内存请求通道暂时不用
assign nice_icb_cmd_valid = 1'b0;
assign nice_icb_cmd_addr = `E203_ADDR_SIZE'b0;
assign nice_icb_cmd_read = 1'b0;
assign nice_icb_cmd_wdata = `E203_XLEN'b0;
assign nice_icb_cmd_size = 2'b0;
assign nice_mem_holdup = 1'b0;
endmodule这里assign nice_rsp_rdat = nice_req_rs1 + nice_req_rs2;实现了加法器的计算,所以最后验证也是通过查看它们三个的波形变化来看是否成功计算,如果没有进行计算,那么这个三个值的波形将会是一条直线,只要发生了波形的波动就可以说明实验成功。
2.编写仿真驱动
1.驱动
Verilator 在仿真之前,需要我们直接给它添加一些额外的东西。我们先回到Linux系统,在RTL代码的根目录下添加一个新的文件夹
shell
# 回到项目根目录
cd ~/riscv_project/e203_hbirdv2
# 创建一个我们自己的仿真文件夹
mkdir -p my_sim
cd my_simVerilator在运行之前需要一个配置文件,相当于vscode在运行C++ 代码之前需要一个.vscode文件夹,里面加入launch.json,setting.json等。同理,我们在 my_sim 目录下创建一个新文件 tb_top.cpp,可以在Linux里面输入这个,会自动在vscode里面创建:
shell
code tb_top.cpp然后把这段代码复制进去就行:
c++
// tb_top.cpp
#include <verilated.h>
#include <verilated_vcd_c.h>
#include "Ve203_cpu_top.h" // 这是 Verilator 稍后会自动生成的头文件
vluint64_t main_time = 0; // 全局仿真时间
double sc_time_stamp() {
return main_time;
}
int main(int argc, char** argv) {
Verilated::commandArgs(argc, argv);
Verilated::traceEverOn(true); // 开启波形追踪
// 实例化 CPU 顶层模块
Ve203_cpu_top* top = new Ve203_cpu_top;
// 初始化波形转储对象
VerilatedVcdC* tfp = new VerilatedVcdC;
top->trace(tfp, 99); // 追踪深度
tfp->open("wave.vcd"); // 输出波形文件名
// 初始化信号
top->clk = 0;
top->rst_n = 0; // 先复位
// 仿真循环
while (!Verilated::gotFinish() && main_time < 2000) { // 只跑 2000 个周期作为测试
// 1. 复位逻辑:前 10 个周期保持复位
if (main_time < 10) {
top->rst_n = 0;
} else {
top->rst_n = 1; // 释放复位,CPU 开始工作
}
// 2. 产生时钟 (翻转)
if ((main_time % 5) == 0) {
top->clk = !top->clk;
}
// 3. 评估电路
top->eval();
// 4. 记录波形
tfp->dump(main_time);
main_time++;
}
// 结束清理
top->final();
tfp->close();
delete top;
return 0;
}这段代码相当于Verilator的主引导程序,作用就是告诉Verilator如何运行,告诉Verilator调用当前的E203代码,并且帮助其产生简单的时钟信号,最后输出一份记录了波形的wave.vcd文件。
2.强制跳转起始命令
蜂鸟 E203 默认上电后会从 0x00001000 (BootROM) 处开始执行一段固化的引导代码。如果这段引导代码没能成功跳转到 0x80000000 (你的程序位置),CPU 就会一直在 BootROM 里空转。为了适配,我们需要直接修改 Verilog 代码,把 CPU 的"出生点"改成 0x80000000。
shell
code ../rtl/e203/core/e203_ifu_ifetch.v找到 pc_dfflr 模块实例化的地方。将它的复位值从原来的 pc_rt_vec (或其他逻辑) 强制改为 32'h80000000。如果不想找直接把原来的文件删了复制进去吧:
verilog
/* Copyright 2018-2020 Nuclei System Technology, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
//=====================================================================
//
// Designer : Bob Hu
//
// Description:
// The ifetch module to generate next PC and bus request
//
// ====================================================================
`include "e203_defines.v"
module e203_ifu_ifetch(
output[`E203_PC_SIZE-1:0] inspect_pc,
input [`E203_PC_SIZE-1:0] pc_rtvec,
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// Fetch Interface to memory system, internal protocol
// * IFetch REQ channel
output ifu_req_valid, // Handshake valid
input ifu_req_ready, // Handshake ready
// Note: the req-addr can be unaligned with the length indicated
// by req_len signal.
// The targetd (ITCM, ICache or Sys-MEM) ctrl modules
// will handle the unalign cases and split-and-merge works
output [`E203_PC_SIZE-1:0] ifu_req_pc, // Fetch PC
output ifu_req_seq, // This request is a sequential instruction fetch
output ifu_req_seq_rv32, // This request is incremented 32bits fetch
output [`E203_PC_SIZE-1:0] ifu_req_last_pc, // The last accessed
// PC address (i.e., pc_r)
// * IFetch RSP channel
input ifu_rsp_valid, // Response valid
output ifu_rsp_ready, // Response ready
input ifu_rsp_err, // Response error
// Note: the RSP channel always return a valid instruction
// fetched from the fetching start PC address.
// The targetd (ITCM, ICache or Sys-MEM) ctrl modules
// will handle the unalign cases and split-and-merge works
//input ifu_rsp_replay,
input [`E203_INSTR_SIZE-1:0] ifu_rsp_instr, // Response instruction
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// The IR stage to EXU interface
output [`E203_INSTR_SIZE-1:0] ifu_o_ir,// The instruction register
output [`E203_PC_SIZE-1:0] ifu_o_pc, // The PC register along with
output ifu_o_pc_vld,
output [`E203_RFIDX_WIDTH-1:0] ifu_o_rs1idx,
output [`E203_RFIDX_WIDTH-1:0] ifu_o_rs2idx,
output ifu_o_prdt_taken, // The Bxx is predicted as taken
output ifu_o_misalgn, // The fetch misalign
output ifu_o_buserr, // The fetch bus error
output ifu_o_muldiv_b2b, // The mul/div back2back case
output ifu_o_valid, // Handshake signals with EXU stage
input ifu_o_ready,
output pipe_flush_ack,
input pipe_flush_req,
input [`E203_PC_SIZE-1:0] pipe_flush_add_op1,
input [`E203_PC_SIZE-1:0] pipe_flush_add_op2,
`ifdef E203_TIMING_BOOST//}
input [`E203_PC_SIZE-1:0] pipe_flush_pc,
`endif//}
// The halt request come from other commit stage
// If the ifu_halt_req is asserting, then IFU will stop fetching new
// instructions and after the oustanding transactions are completed,
// asserting the ifu_halt_ack as the response.
// The IFU will resume fetching only after the ifu_halt_req is deasserted
input ifu_halt_req,
output ifu_halt_ack,
input oitf_empty,
input [`E203_XLEN-1:0] rf2ifu_x1,
input [`E203_XLEN-1:0] rf2ifu_rs1,
input dec2ifu_rs1en,
input dec2ifu_rden,
input [`E203_RFIDX_WIDTH-1:0] dec2ifu_rdidx,
input dec2ifu_mulhsu,
input dec2ifu_div ,
input dec2ifu_rem ,
input dec2ifu_divu ,
input dec2ifu_remu ,
input clk,
input rst_n
);
wire ifu_req_hsked = (ifu_req_valid & ifu_req_ready) ;
wire ifu_rsp_hsked = (ifu_rsp_valid & ifu_rsp_ready) ;
wire ifu_ir_o_hsked = (ifu_o_valid & ifu_o_ready) ;
wire pipe_flush_hsked = pipe_flush_req & pipe_flush_ack;
// The rst_flag is the synced version of rst_n
// * rst_n is asserted
// The rst_flag will be clear when
// * rst_n is de-asserted
wire reset_flag_r;
sirv_gnrl_dffrs #(1) reset_flag_dffrs (1'b0, reset_flag_r, clk, rst_n);
//
// The reset_req valid is set when
// * Currently reset_flag is asserting
// The reset_req valid is clear when
// * Currently reset_req is asserting
// * Currently the flush can be accepted by IFU
wire reset_req_r;
wire reset_req_set = (~reset_req_r) & reset_flag_r;
wire reset_req_clr = reset_req_r & ifu_req_hsked;
wire reset_req_ena = reset_req_set | reset_req_clr;
wire reset_req_nxt = reset_req_set | (~reset_req_clr);
sirv_gnrl_dfflr #(1) reset_req_dfflr (reset_req_ena, reset_req_nxt, reset_req_r, clk, rst_n);
wire ifu_reset_req = reset_req_r;
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// The halt ack generation
wire halt_ack_set;
wire halt_ack_clr;
wire halt_ack_ena;
wire halt_ack_r;
wire halt_ack_nxt;
// The halt_ack will be set when
// * Currently halt_req is asserting
// * Currently halt_ack is not asserting
// * Currently the ifetch REQ channel is ready, means
// there is no oustanding transactions
wire ifu_no_outs;
assign halt_ack_set = ifu_halt_req & (~halt_ack_r) & ifu_no_outs;
// The halt_ack_r valid is cleared when
// * Currently halt_ack is asserting
// * Currently halt_req is de-asserting
assign halt_ack_clr = halt_ack_r & (~ifu_halt_req);
assign halt_ack_ena = halt_ack_set | halt_ack_clr;
assign halt_ack_nxt = halt_ack_set | (~halt_ack_clr);
sirv_gnrl_dfflr #(1) halt_ack_dfflr (halt_ack_ena, halt_ack_nxt, halt_ack_r, clk, rst_n);
assign ifu_halt_ack = halt_ack_r;
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// The flush ack signal generation
//
// Ideally the flush is acked when the ifetch interface is ready
// or there is rsponse valid
// But to cut the comb loop between EXU and IFU, we always accept
// the flush, when it is not really acknowledged, we use a
// delayed flush indication to remember this flush
// Note: Even if there is a delayed flush pending there, we
// still can accept new flush request
assign pipe_flush_ack = 1'b1;
wire dly_flush_set;
wire dly_flush_clr;
wire dly_flush_ena;
wire dly_flush_nxt;
// The dly_flush will be set when
// * There is a flush requst is coming, but the ifu
// is not ready to accept new fetch request
wire dly_flush_r;
assign dly_flush_set = pipe_flush_req & (~ifu_req_hsked);
// The dly_flush_r valid is cleared when
// * The delayed flush is issued
assign dly_flush_clr = dly_flush_r & ifu_req_hsked;
assign dly_flush_ena = dly_flush_set | dly_flush_clr;
assign dly_flush_nxt = dly_flush_set | (~dly_flush_clr);
sirv_gnrl_dfflr #(1) dly_flush_dfflr (dly_flush_ena, dly_flush_nxt, dly_flush_r, clk, rst_n);
wire dly_pipe_flush_req = dly_flush_r;
wire pipe_flush_req_real = pipe_flush_req | dly_pipe_flush_req;
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// The IR register to be used in EXU for decoding
wire ir_valid_set;
wire ir_valid_clr;
wire ir_valid_ena;
wire ir_valid_r;
wire ir_valid_nxt;
wire ir_pc_vld_set;
wire ir_pc_vld_clr;
wire ir_pc_vld_ena;
wire ir_pc_vld_r;
wire ir_pc_vld_nxt;
// The ir valid is set when there is new instruction fetched *and* // no flush happening
wire ifu_rsp_need_replay;
wire pc_newpend_r;
wire ifu_ir_i_ready;
assign ir_valid_set = ifu_rsp_hsked & (~pipe_flush_req_real) & (~ifu_rsp_need_replay);
assign ir_pc_vld_set = pc_newpend_r & ifu_ir_i_ready & (~pipe_flush_req_real) & (~ifu_rsp_need_replay);
// The ir valid is cleared when it is accepted by EXU stage *or*
// the flush happening
assign ir_valid_clr = ifu_ir_o_hsked | (pipe_flush_hsked & ir_valid_r);
assign ir_pc_vld_clr = ir_valid_clr;
assign ir_valid_ena = ir_valid_set | ir_valid_clr;
assign ir_valid_nxt = ir_valid_set | (~ir_valid_clr);
assign ir_pc_vld_ena = ir_pc_vld_set | ir_pc_vld_clr;
assign ir_pc_vld_nxt = ir_pc_vld_set | (~ir_pc_vld_clr);
sirv_gnrl_dfflr #(1) ir_valid_dfflr (ir_valid_ena, ir_valid_nxt, ir_valid_r, clk, rst_n);
sirv_gnrl_dfflr #(1) ir_pc_vld_dfflr (ir_pc_vld_ena, ir_pc_vld_nxt, ir_pc_vld_r, clk, rst_n);
// IFU-IR loaded with the returned instruction from the IFetch RSP channel
wire [`E203_INSTR_SIZE-1:0] ifu_ir_nxt = ifu_rsp_instr;
// IFU-PC loaded with the current PC
wire ifu_err_nxt = ifu_rsp_err;
// IFU-IR and IFU-PC as the datapath register, only loaded and toggle when the valid reg is set
wire ifu_err_r;
sirv_gnrl_dfflr #(1) ifu_err_dfflr(ir_valid_set, ifu_err_nxt, ifu_err_r, clk, rst_n);
wire prdt_taken;
wire ifu_prdt_taken_r;
sirv_gnrl_dfflr #(1) ifu_prdt_taken_dfflr (ir_valid_set, prdt_taken, ifu_prdt_taken_r, clk, rst_n);
wire ifu_muldiv_b2b_nxt;
wire ifu_muldiv_b2b_r;
sirv_gnrl_dfflr #(1) ir_muldiv_b2b_dfflr (ir_valid_set, ifu_muldiv_b2b_nxt, ifu_muldiv_b2b_r, clk, rst_n);
//To save power the H-16bits only loaded when it is 32bits length instru
wire [`E203_INSTR_SIZE-1:0] ifu_ir_r;// The instruction register
wire minidec_rv32;
wire ir_hi_ena = ir_valid_set & minidec_rv32;
wire ir_lo_ena = ir_valid_set;
sirv_gnrl_dfflr #(`E203_INSTR_SIZE/2) ifu_hi_ir_dfflr (ir_hi_ena, ifu_ir_nxt[31:16], ifu_ir_r[31:16], clk, rst_n);
sirv_gnrl_dfflr #(`E203_INSTR_SIZE/2) ifu_lo_ir_dfflr (ir_lo_ena, ifu_ir_nxt[15: 0], ifu_ir_r[15: 0], clk, rst_n);
wire minidec_rs1en;
wire minidec_rs2en;
wire [`E203_RFIDX_WIDTH-1:0] minidec_rs1idx;
wire [`E203_RFIDX_WIDTH-1:0] minidec_rs2idx;
`ifndef E203_HAS_FPU//}
wire minidec_fpu = 1'b0;
wire minidec_fpu_rs1en = 1'b0;
wire minidec_fpu_rs2en = 1'b0;
wire minidec_fpu_rs3en = 1'b0;
wire minidec_fpu_rs1fpu = 1'b0;
wire minidec_fpu_rs2fpu = 1'b0;
wire minidec_fpu_rs3fpu = 1'b0;
wire [`E203_RFIDX_WIDTH-1:0] minidec_fpu_rs1idx = `E203_RFIDX_WIDTH'b0;
wire [`E203_RFIDX_WIDTH-1:0] minidec_fpu_rs2idx = `E203_RFIDX_WIDTH'b0;
`endif//}
wire [`E203_RFIDX_WIDTH-1:0] ir_rs1idx_r;
wire [`E203_RFIDX_WIDTH-1:0] ir_rs2idx_r;
wire bpu2rf_rs1_ena;
//FPU: if it is FPU instruction. we still need to put it into the IR register, but we need to mask off the non-integer regfile index to save power
wire ir_rs1idx_ena = (minidec_fpu & ir_valid_set & minidec_fpu_rs1en & (~minidec_fpu_rs1fpu)) | ((~minidec_fpu) & ir_valid_set & minidec_rs1en) | bpu2rf_rs1_ena;
wire ir_rs2idx_ena = (minidec_fpu & ir_valid_set & minidec_fpu_rs2en & (~minidec_fpu_rs2fpu)) | ((~minidec_fpu) & ir_valid_set & minidec_rs2en);
wire [`E203_RFIDX_WIDTH-1:0] ir_rs1idx_nxt = minidec_fpu ? minidec_fpu_rs1idx : minidec_rs1idx;
wire [`E203_RFIDX_WIDTH-1:0] ir_rs2idx_nxt = minidec_fpu ? minidec_fpu_rs2idx : minidec_rs2idx;
sirv_gnrl_dfflr #(`E203_RFIDX_WIDTH) ir_rs1idx_dfflr (ir_rs1idx_ena, ir_rs1idx_nxt, ir_rs1idx_r, clk, rst_n);
sirv_gnrl_dfflr #(`E203_RFIDX_WIDTH) ir_rs2idx_dfflr (ir_rs2idx_ena, ir_rs2idx_nxt, ir_rs2idx_r, clk, rst_n);
// [HACK-FIX] 强制修改复位后的 PC 地址为 0x80000000
// 原本 E203 复位后会读取 pc_rt_vec (通常是 0x1000)
// 我们直接替换掉 pc_dfflr 的调用,手动写一个 always 块来控制 PC
reg [`E203_PC_SIZE-1:0] pc_r;
always @(posedge clk or negedge rst_n) begin
if (rst_n == 1'b0) begin
pc_r <= 32'h80000000; // <--- 重点:强制复位到 ITCM
end
else if (pc_ena) begin
pc_r <= pc_nxt;
end
end
// wire [`E203_PC_SIZE-1:0] pc_r;
// wire [`E203_PC_SIZE-1:0] ifu_pc_nxt = pc_r;
// wire [`E203_PC_SIZE-1:0] ifu_pc_r;
// sirv_gnrl_dfflr #(`E203_PC_SIZE) ifu_pc_dfflr (ir_pc_vld_set, ifu_pc_nxt, ifu_pc_r, clk, rst_n);
// 上面这一块被我注释掉了,因为我们把 pc_r 变成 reg 手动控制了
// 这里需要手动补上 ifu_pc_r 的逻辑,因为它也被上面的 dfflr 控制
// ifu_pc_r 用来保存当前 IR 对应的 PC
wire [`E203_PC_SIZE-1:0] ifu_pc_r;
sirv_gnrl_dfflr #(`E203_PC_SIZE) ifu_pc_dfflr (ir_pc_vld_set, pc_r, ifu_pc_r, clk, rst_n);
assign ifu_o_ir = ifu_ir_r;
assign ifu_o_pc = ifu_pc_r;
// Instruction fetch misaligned exceptions are not possible on machines that support extensions
// with 16-bit aligned instructions, such as the compressed instruction set extension, C.
assign ifu_o_misalgn = 1'b0;// Never happen in RV32C configuration
assign ifu_o_buserr = ifu_err_r;
assign ifu_o_rs1idx = ir_rs1idx_r;
assign ifu_o_rs2idx = ir_rs2idx_r;
assign ifu_o_prdt_taken = ifu_prdt_taken_r;
assign ifu_o_muldiv_b2b = ifu_muldiv_b2b_r;
assign ifu_o_valid = ir_valid_r;
assign ifu_o_pc_vld = ir_pc_vld_r;
// The IFU-IR stage will be ready when it is empty or under-clearing
assign ifu_ir_i_ready = (~ir_valid_r) | ir_valid_clr;
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// JALR instruction dependency check
wire ir_empty = ~ir_valid_r;
wire ir_rs1en = dec2ifu_rs1en;
wire ir_rden = dec2ifu_rden;
wire [`E203_RFIDX_WIDTH-1:0] ir_rdidx = dec2ifu_rdidx;
wire [`E203_RFIDX_WIDTH-1:0] minidec_jalr_rs1idx;
wire jalr_rs1idx_cam_irrdidx = ir_rden & (minidec_jalr_rs1idx == ir_rdidx) & ir_valid_r;
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// MULDIV BACK2BACK Fusing
// To detect the sequence of MULH[[S]U] rdh, rs1, rs2; MUL rdl, rs1, rs2
// To detect the sequence of DIV[U] rdq, rs1, rs2; REM[U] rdr, rs1, rs2
wire minidec_mul ;
wire minidec_div ;
wire minidec_rem ;
wire minidec_divu;
wire minidec_remu;
assign ifu_muldiv_b2b_nxt =
(
// For multiplicaiton, only the MUL instruction following
// MULH/MULHU/MULSU can be treated as back2back
( minidec_mul & dec2ifu_mulhsu)
// For divider and reminder instructions, only the following cases
// can be treated as back2back
// * DIV--REM
// * REM--DIV
// * DIVU--REMU
// * REMU--DIVU
| ( minidec_div & dec2ifu_rem)
| ( minidec_rem & dec2ifu_div)
| ( minidec_divu & dec2ifu_remu)
| ( minidec_remu & dec2ifu_divu)
)
// The last rs1 and rs2 indexes are same as this instruction
& (ir_rs1idx_r == ir_rs1idx_nxt)
& (ir_rs2idx_r == ir_rs2idx_nxt)
// The last rs1 and rs2 indexes are not same as last RD index
& (~(ir_rs1idx_r == ir_rdidx))
& (~(ir_rs2idx_r == ir_rdidx))
;
//////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////
// Next PC generation
wire minidec_bjp;
wire minidec_jal;
wire minidec_jalr;
wire minidec_bxx;
wire [`E203_XLEN-1:0] minidec_bjp_imm;
// The mini-decoder to check instruciton length and branch type
e203_ifu_minidec u_e203_ifu_minidec (
.instr (ifu_ir_nxt ),
.dec_rs1en (minidec_rs1en ),
.dec_rs2en (minidec_rs2en ),
.dec_rs1idx (minidec_rs1idx ),
.dec_rs2idx (minidec_rs2idx ),
.dec_rv32 (minidec_rv32 ),
.dec_bjp (minidec_bjp ),
.dec_jal (minidec_jal ),
.dec_jalr (minidec_jalr ),
.dec_bxx (minidec_bxx ),
.dec_mulhsu (),
.dec_mul (minidec_mul ),
.dec_div (minidec_div ),
.dec_rem (minidec_rem ),
.dec_divu (minidec_divu),
.dec_remu (minidec_remu),
.dec_jalr_rs1idx (minidec_jalr_rs1idx),
.dec_bjp_imm (minidec_bjp_imm )
);
wire bpu_wait;
wire [`E203_PC_SIZE-1:0] prdt_pc_add_op1;
wire [`E203_PC_SIZE-1:0] prdt_pc_add_op2;
e203_ifu_litebpu u_e203_ifu_litebpu(
.pc (pc_r),
.dec_jal (minidec_jal ),
.dec_jalr (minidec_jalr ),
.dec_bxx (minidec_bxx ),
.dec_bjp_imm (minidec_bjp_imm ),
.dec_jalr_rs1idx (minidec_jalr_rs1idx ),
.dec_i_valid (ifu_rsp_valid),
.ir_valid_clr (ir_valid_clr),
.oitf_empty (oitf_empty),
.ir_empty (ir_empty ),
.ir_rs1en (ir_rs1en ),
.jalr_rs1idx_cam_irrdidx (jalr_rs1idx_cam_irrdidx),
.bpu_wait (bpu_wait ),
.prdt_taken (prdt_taken ),
.prdt_pc_add_op1 (prdt_pc_add_op1),
.prdt_pc_add_op2 (prdt_pc_add_op2),
.bpu2rf_rs1_ena (bpu2rf_rs1_ena),
.rf2bpu_x1 (rf2ifu_x1 ),
.rf2bpu_rs1 (rf2ifu_rs1 ),
.clk (clk ) ,
.rst_n (rst_n )
);
// If the instruciton is 32bits length, increament 4, otherwise 2
wire [2:0] pc_incr_ofst = minidec_rv32 ? 3'd4 : 3'd2;
wire [`E203_PC_SIZE-1:0] pc_nxt_pre;
wire [`E203_PC_SIZE-1:0] pc_nxt;
wire bjp_req = minidec_bjp & prdt_taken;
wire ifetch_replay_req;
wire [`E203_PC_SIZE-1:0] pc_add_op1 =
`ifndef E203_TIMING_BOOST//}
pipe_flush_req ? pipe_flush_add_op1 :
dly_pipe_flush_req ? pc_r :
`endif//}
ifetch_replay_req ? pc_r :
bjp_req ? prdt_pc_add_op1 :
ifu_reset_req ? 32'h80000000 : // [HACK] 强制修改
pc_r;
wire [`E203_PC_SIZE-1:0] pc_add_op2 =
`ifndef E203_TIMING_BOOST//}
pipe_flush_req ? pipe_flush_add_op2 :
dly_pipe_flush_req ? `E203_PC_SIZE'b0 :
`endif//}
ifetch_replay_req ? `E203_PC_SIZE'b0 :
bjp_req ? prdt_pc_add_op2 :
ifu_reset_req ? `E203_PC_SIZE'b0 :
pc_incr_ofst ;
assign ifu_req_seq = (~pipe_flush_req_real) & (~ifu_reset_req) & (~ifetch_replay_req) & (~bjp_req);
assign ifu_req_seq_rv32 = minidec_rv32;
assign ifu_req_last_pc = pc_r;
assign pc_nxt_pre = pc_add_op1 + pc_add_op2;
`ifndef E203_TIMING_BOOST//}
assign pc_nxt = {pc_nxt_pre[`E203_PC_SIZE-1:1],1'b0};
`else//}{
assign pc_nxt =
pipe_flush_req ? {pipe_flush_pc[`E203_PC_SIZE-1:1],1'b0} :
dly_pipe_flush_req ? {pc_r[`E203_PC_SIZE-1:1],1'b0} :
{pc_nxt_pre[`E203_PC_SIZE-1:1],1'b0};
`endif//}
// The Ifetch issue new ifetch request when
// * If it is a bjp insturction, and it does not need to wait, and it is not a replay-set cycle
// * and there is no halt_request
wire ifu_new_req = (~bpu_wait) & (~ifu_halt_req) & (~reset_flag_r) & (~ifu_rsp_need_replay);
// The fetch request valid is triggering when
// * New ifetch request
// * or The flush-request is pending
wire ifu_req_valid_pre = ifu_new_req | ifu_reset_req | pipe_flush_req_real | ifetch_replay_req;
// The new request ready condition is:
// * No outstanding reqeusts
// * Or if there is outstanding, but it is reponse valid back
wire out_flag_clr;
wire out_flag_r;
wire new_req_condi = (~out_flag_r) | out_flag_clr;
assign ifu_no_outs = (~out_flag_r) | ifu_rsp_valid;
// Here we use the rsp_valid rather than the out_flag_clr (ifu_rsp_hsked) because
// as long as the rsp_valid is asserting then means last request have returned the
// response back, in WFI case, we cannot expect it to be handshaked (otherwise deadlock)
assign ifu_req_valid = ifu_req_valid_pre & new_req_condi;
//wire ifu_rsp2ir_ready = (ifu_rsp_replay | pipe_flush_req_real) ? 1'b1 : (ifu_ir_i_ready & (~bpu_wait));
wire ifu_rsp2ir_ready = (pipe_flush_req_real) ? 1'b1 : (ifu_ir_i_ready & ifu_req_ready & (~bpu_wait));
// Response channel only ready when:
// * IR is ready to accept new instructions
assign ifu_rsp_ready = ifu_rsp2ir_ready;
// The PC will need to be updated when ifu req channel handshaked or a flush is incoming
wire pc_ena = ifu_req_hsked | pipe_flush_hsked;
// sirv_gnrl_dfflr #(`E203_PC_SIZE) pc_dfflr (pc_ena, pc_nxt, pc_r, clk, rst_n);
assign inspect_pc = pc_r;
assign ifu_req_pc = pc_nxt;
// The out_flag will be set if there is a new request handshaked
wire out_flag_set = ifu_req_hsked;
// The out_flag will be cleared if there is a request response handshaked
assign out_flag_clr = ifu_rsp_hsked;
wire out_flag_ena = out_flag_set | out_flag_clr;
// If meanwhile set and clear, then set preempt
wire out_flag_nxt = out_flag_set | (~out_flag_clr);
sirv_gnrl_dfflr #(1) out_flag_dfflr (out_flag_ena, out_flag_nxt, out_flag_r, clk, rst_n);
// The pc_newpend will be set if there is a new PC loaded
wire pc_newpend_set = pc_ena;
// The pc_newpend will be cleared if have already loaded into the IR-PC stage
wire pc_newpend_clr = ir_pc_vld_set;
wire pc_newpend_ena = pc_newpend_set | pc_newpend_clr;
// If meanwhile set and clear, then set preempt
wire pc_newpend_nxt = pc_newpend_set | (~pc_newpend_clr);
sirv_gnrl_dfflr #(1) pc_newpend_dfflr (pc_newpend_ena, pc_newpend_nxt, pc_newpend_r, clk, rst_n);
assign ifu_rsp_need_replay = 1'b0;
assign ifetch_replay_req = 1'b0;
`ifndef FPGA_SOURCE//{
`ifndef DISABLE_SV_ASSERTION//{
//synopsys translate_off
CHECK_IFU_REQ_VALID_NO_X:
assert property (@(posedge clk) disable iff (~rst_n)
(ifu_req_valid !== 1'bx)
)
else $fatal ("\n Error: Oops, detected X value for ifu_req_valid !!! This should never happen. \n");
//synopsys translate_on
`endif//}
`endif//}
endmodule3.仿真
都准备好了,现在我们在刚刚创建的my_sim目录下,就可以通过Linux调用Verilator进行仿真了。
我们直接运行下面这个脚本即可:
shell
# 1. 进入仿真目录
cd ~/riscv_project/e203_hbirdv2/my_sim
# 2. 彻底清理多余的文件
rm -rf obj_dir
# 3. 重新生成仿真器
RTL_DIR=../rtl/e203
verilator -cc --exe --trace --no-timing \
--top-module e203_cpu_top \
-Wno-WIDTH -Wno-PINMISSING -Wno-CASEINCOMPLETE -Wno-TIMESCALEMOD \
-Wno-INITIALDLY -Wno-LITENDIAN -Wno-MODDUP \
-Wno-LATCH -Wno-UNOPTFLAT \
-I$RTL_DIR/core \
-I$RTL_DIR/perips \
-I$RTL_DIR/subsys \
-I$RTL_DIR/soc \
-I$RTL_DIR/general \
-I$RTL_DIR/debug \
-I$RTL_DIR/fab \
-I$RTL_DIR/mems \
$RTL_DIR/general/*.v \
$RTL_DIR/core/e203_cpu_top.v \
$RTL_DIR/core/e203_srams.v \
$RTL_DIR/subsys/e203_subsys_nice_core.v \
tb_top.cpp
# 4. 编译
make -j -C obj_dir -f Ve203_cpu_top.mk Ve203_cpu_top操作完成之后,我们的E203已经变成了一个可执行文件,我们可以运行一下:
shell
./obj_dir/Ve203_cpu_top如果输出了波形文件,就证明我们目前的配置没有问题:
shell
ls -l wave.vcd应该可以看到wave.vcd的文件位置和生成的时间
shell
-rw-r--r-- 1 duanpenghao duanpenghao 425275 Dec 17 15:46 wave.vcd如果到了这一步,我们就可以自己写一点C语言的代码,然后用前面下载好的riscv的gcc进行编译,然后丢给当前的verilog仿真好的E203运行。
4.运行C语言程序的配置
首先在 ~/riscv_project/e203_hbirdv2/ 目录下创建一个新的文件夹 software,我们在这里写代码:
bash
cd ~/riscv_project/e203_hbirdv2
mkdir software
cd software我们首先需要写一个简单的操作系统,包括了编译,启动:
1.编写链接脚本 (link.lds):
因为我们是直接在裸机硬件上跑,没有操作系统(Windows/Linux),所以必须告诉编译器:"请把程序的第一行代码放在内存地址 0x80000000 的位置" (这是蜂鸟 E203 的 ITCM 内存起始地址)。在刚刚创建的文件夹下面,创建 link.lds,这是运行我们的C语言程序的主引导代码:
shell
code link.lds然后在VScode里面输入:
OUTPUT_ARCH( "riscv" )
ENTRY( _start )
SECTIONS
{
/* 将代码段放在 0x80000000 (ITCM) */
. = 0x80000000;
.text : {
*(.text.init) /* 启动代码最先放 */
*(.text) /* 其他代码 */
}
.data : {
*(.data)
}
.bss : {
*(.bss)
}
}2.编写启动汇编 (start.S)
因为E203是纯裸机,没有操作系统,所以我们需要简单的写几行汇编代码来实现堆栈调用,也是写在我们的软件文件夹。
shell
code start.S写入这几行(代码看着多,其实全是注释):
assembly
/* start.S */
/* 声明这是一个代码段,并且属于 .text.init 部分 */
/* 链接脚本 link.lds 会把这就部分放在内存的最开始,确保 CPU 一上电就执行它 */
.section .text.init
/* 声明 _start 是一个全局符号,让链接器能找到程序的入口 */
.globl _start
_start:
/* =================================================== */
/* 1. 初始化栈指针 (Stack Pointer, SP) */
/* =================================================== */
/* 蜂鸟 E203 的 ITCM (指令紧耦合内存) 起始地址是 0x80000000 */
/* 它的默认大小通常是 64KB (0x10000) */
/* 栈是"向下生长"的(从高地址往低地址存),所以我们将 SP 设置在内存的最末端 */
/* 0x80000000 + 0x10000 = 0x80010000 */
li sp, 0x80010000
/* =================================================== */
/* 2. 跳转到 C 语言世界 */
/* =================================================== */
/* 调用 main 函数 */
/* call 指令会自动把返回地址保存在 ra 寄存器里 */
call main
/* =================================================== */
/* 3. 兜底逻辑 (死循环) */
/* =================================================== */
/* 如果 main 函数意外返回了(虽然不应该发生),我们让 CPU 停在这里 */
/* 否则它可能会乱跑去执行未知的内存区域 */
loop:
j loop它告诉蜂鸟E203如何运行一个程序。
3.写一个python脚本把代码转为 64位
这里的目的是用python代码转变数据,把那些散落的字节打包成 64 位的格式,防止CPU读取不到,因为后面编译出来的可能是32位的指令,写这个脚本将会在Gcc把C语言代码编译完成之后检查一下,把所有指令都转为64位。
shell
code gen_hex.py下入下面的信息
python
import sys
# 用法: python3 gen_hex.py <输入.bin> <输出.verilog>
def main():
if len(sys.argv) != 3:
print("Usage: python3 gen_hex.py <input.bin> <output.verilog>")
sys.exit(1)
in_file = sys.argv[1]
out_file = sys.argv[2]
try:
with open(in_file, "rb") as f:
data = f.read()
except FileNotFoundError:
print(f"Error: Cannot find input file {in_file}")
sys.exit(1)
# 补齐到 8 字节边界 (因为内存是 64 位的)
while len(data) % 8 != 0:
data += b'\0'
with open(out_file, "w") as f:
# 写头部地址
f.write("@00000000\n")
# 每 8 个字节打包成一行 64 位的 Hex
for i in range(0, len(data), 8):
chunk = data[i:i+8]
# E203 是小端模式,但 hex 文件里高位在前,所以要转换
val = int.from_bytes(chunk, 'little')
# 写入 16 个字符宽的 Hex (64位)
f.write(f"{val:016x}\n")
print(f"Successfully generated {out_file} (64-bit aligned)")
if __name__ == "__main__":
main()4.写C语言程序
操作系统和硬件都有了,现在可以搞软件了,也就是C语言代码:
shell
code main.c然后写入
c
#include <stdint.h>
// =========================================================
// 定义自定义指令宏
// =========================================================
// 蜂鸟 E203 的 NICE 接口默认响应 opcode = 0x0B (custom-0)
// 我们在之前的 Verilog 修改中,定义的逻辑是:rsp_rdat = rs1 + rs2
//
// 汇编解析:
// .insn r : 告诉汇编器这是一条 R-Type (寄存器-寄存器操作) 格式的指令
// 0x0B : 这是 Custom-0 的操作码 (Opcode)
// 0, 0 : func3 和 func7 字段 (我们在 Verilog 里全都忽略了,所以填 0)
// %0 : 对应输出变量 rd (即 result)
// %1, %2 : 对应输入变量 rs1, rs2 (即 a, b)
//
// 最终效果:硬件执行 rd = rs1 + rs2
#define custom_add(rd, rs1, rs2) \
asm volatile (".insn r 0x0B, 0, 0, %0, %1, %2" : "=r"(rd) : "r"(rs1), "r"(rs2))
// =========================================================
// 主函数
// =========================================================
int main() {
int a = 10; // 十进制 10 (十六进制 0x0A)
int b = 20; // 十进制 20 (十六进制 0x14)
int result = 0;
// 1. 调用自定义指令
// 当 CPU 执行到这一行时,nice_req_valid 会拉高,触发你的 Verilog 逻辑
custom_add(result, a, b);
// 2. 死循环
// 理论上此时 result 应该等于 30 (0x1E)
// 我们让 CPU 停在这里,方便我们在波形图的最后时刻去检查寄存器的值
while(1) {
// 空循环,什么都不做
}
return 0;
}这里和一般的C语言不同之处就在于上面的预编译头,等于告诉E203如何执行。
5.编译程序
现在都准备好了,只需要把C语言代码和前面的link.lds和start.s一起丢个Gcc编译即可,我们写一个脚本可以直接指挥GCC干活,在 software 目录下创建 Makefile(注意文件名首字母大写):
shell
code Makefile然后输入:
makefile
# 指定编译器工具 (我们在第一步安装好的)
CC = riscv64-unknown-elf-gcc
OBJCOPY = riscv64-unknown-elf-objcopy
OBJDUMP = riscv64-unknown-elf-objdump
# 编译选项详解:
# -march=rv32imac: 指定架构为 32位 RISC-V (蜂鸟E203是32位核,支持整数乘法、原子操作和压缩指令)
# -mabi=ilp32: 指定 32位整数标准 (指针是32位的)
# -O0 -g: 关闭优化并保留调试信息,方便看汇编
# -nostartfiles: 告诉编译器不要用自带的启动代码,用我们写的 start.S
# -T link.lds: 使用我们写的内存布局脚本,确保代码放在 0x80000000
CFLAGS = -march=rv32imac -mabi=ilp32 -O0 -g -nostdlib -T link.lds
TARGET = test_demo
# 默认运行的目标
all: $(TARGET).verilog
# 1. 编译 (Source -> ELF)
# 把 start.S 和 main.c 编译链接成可执行文件 (.elf)
$(TARGET).elf: start.S main.c link.lds
$(CC) $(CFLAGS) start.S main.c -o $(TARGET).elf
# 2. 反汇编 (ELF -> DASM)
# 生成汇编代码文件,方便我们肉眼检查编译结果对不对
$(TARGET).dasm: $(TARGET).elf
$(OBJDUMP) -D $(TARGET).elf > $(TARGET).dasm
# 3. 格式转换 (ELF -> Verilog Hex)
# 这是最关键的一步!Verilog 仿真器只能读取这种特殊的 Hex 文本格式
$(TARGET).verilog: $(TARGET).elf $(TARGET).dasm
# 1. 先转成纯二进制 (Binary)
$(OBJCOPY) -O binary $(TARGET).elf $(TARGET).bin
# 2. 用 Python 脚本把二进制打包成 64位宽的 Hex
python3 gen_hex.py $(TARGET).bin $(TARGET).verilog
# 清理命令 (make clean)
clean:
rm -f *.elf *.verilog *.dasm在当前的software目录下直接make即可:
shell
make成功之后会显示
shell
riscv64-unknown-elf-gcc -march=rv32imac -mabi=ilp32 -O0 -g -nostdlib -T link.lds start.S main.c -o test_demo.elf
riscv64-unknown-elf-objdump -D test_demo.elf > test_demo.dasm
riscv64-unknown-elf-objcopy -O verilog test_demo.elf test_demo.verilog
# [重要修正]
# 蜂鸟的 ITCM 地址是从 0x80000000 开始的。
# 但生成的 verilog 文件里,段地址标记是 @80000000。
# 而仿真器里的 RAM 模型是从 0 地址开始索引的。
# 我们用 sed 命令把地址标记 @800xxxxx 替换为 @000xxxxx,否则仿真器加载不进去。
sed -i 's/@800/@000/g' test_demo.verilog输入查看命令ls或者在vscode里面打开software,我们可以看见多了一些文件:
shell
Makefile link.lds main.c start.S test_demo.dasm test_demo.elf test_demo.verilog多出来的几个文件其实都是gcc编译生成的机器指令。其中最重要的是 test_demo.verilog 。test_demo.verilog 是连接软件世界(C语言)与硬件世界(Verilog)的唯一桥梁 。流程是这样的:读取数据 (.verilog) → \rightarrow → 注入到虚拟内存中 → \rightarrow → CPU 开始运行。简单来说,test_demo.verilog就是可以直接执行在我们前面仿真出来的E203上面的指令。
6.把test_demo.verilog地址写死到仿真的芯片中
我们现在只需要把test_demo.verilog机器码丢给之前编译出来的E203即可。E203之前已经编译好位于/riscv_project/e203_hbirdv2/my_sim/obj_dir,可以直接执行,所以我们把test_demo.verilog复制到这个位置然后执行就行:
shell
# 1. 把生成的机器码复制到仿真目录,并改名为 e203.verilog
# (因为我们的硬件仿真代码里写死了读取这个文件名)
cp ~/riscv_project/e203_hbirdv2/software/test_demo.verilog ~/riscv_project/e203_hbirdv2/my_sim/obj_dir/e203.verilog
# 2. 切换回仿真目录
cd ~/riscv_project/e203_hbirdv2/my_sim但是,虽然硬件仿真代码里面写了这个文件名,但是毕竟是仿真,所以还需要把现在test_demo.verilog的地址写死进去,不然还是读取不到,运行:
shell
readlink -f e203.verilog然后会显示当前的地址,比如我的是:
shell
/home/duanpenghao/riscv_project/e203_hbirdv2/my_sim/e203.verilog然后打开sirv_sim_ram.v这是读取文件地址:
shell
code ../rtl/e203/general/sirv_sim_ram.v搜索reg [Dw-1:0] mem_r [0:DP-1];,然后在这个下面插入这一段,其中地址换成你对应的地址:
verilog
initial begin
$readmemh("/home/duanpenghao/riscv_project/e203_hbirdv2/my_sim/e203.verilog", mem_r);
end就像这样:
verilog
reg [DW-1:0] mem_r [0:DP-1];
//在这里插入
initial begin
$readmemh("/home/dongcandie/riscv_project/e203_hbirdv2/my_sim/e203.verilog", mem_r);
end
reg [AW-1:0] addr_r;
wire [MW-1:0] wen;
wire ren;7.执行代码
现在什么都有了,我们进行一次整体的编译
shell
# 1. 进入仿真目录
cd ~/riscv_project/e203_hbirdv2/my_sim
# 2. 彻底清理前面生成的
rm -rf obj_dir
# 3. 重新生成仿真器
RTL_DIR=../rtl/e203
verilator -cc --exe --trace --no-timing \
--top-module e203_cpu_top \
-Wno-WIDTH -Wno-PINMISSING -Wno-CASEINCOMPLETE -Wno-TIMESCALEMOD \
-Wno-INITIALDLY -Wno-LITENDIAN -Wno-MODDUP \
-Wno-LATCH -Wno-UNOPTFLAT \
-I$RTL_DIR/core \
-I$RTL_DIR/perips \
-I$RTL_DIR/subsys \
-I$RTL_DIR/soc \
-I$RTL_DIR/general \
-I$RTL_DIR/debug \
-I$RTL_DIR/fab \
-I$RTL_DIR/mems \
$RTL_DIR/general/*.v \
$RTL_DIR/core/e203_cpu_top.v \
$RTL_DIR/core/e203_srams.v \
$RTL_DIR/subsys/e203_subsys_nice_core.v \
tb_top.cpp
# 4. 编译
make -j -C obj_dir -f Ve203_cpu_top.mk Ve203_cpu_top
# 5. 运行
./obj_dir/Ve203_cpu_top如果没有报错就说明成功了,我们现在检查wave文件。就保存在\e203_hbirdv2\my_sim这个文件夹下面,我们打开vscode可以直接看到,也可以在shell里面输入
shell
explorer.exe .打开当前文件夹,也能看见这个文件。
7.用GTKWave查看波形
GTKWave我们前面已经下载好了,其实还可以在Vscode的插件里面输入GTKwave下载插件,或者去官网下载GTKwave的windows版本,然后打开这个wave文件就行(Vscode里面要双击打开)。这里介绍Linux版本的:
shell
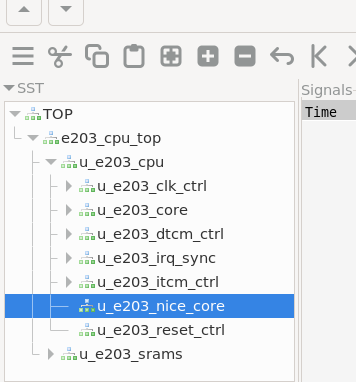
gtkwave wave.vcd然后我们就可以看见软件打开了,我们按照下面的顺序一层层打开:
TOP
e203_cpu_top
u_e203_cpu
u_e203_subsys如图
然后我们就可以从下面找对应组件的波形了,我们主要看的是寄存器r1和r2的变化,这里可以多拖进去几个,不影响:
nice_req_valid(请求信号:代表 CPU 此时正在喊话"帮我算一下!")nice_req_rs1(输入参数 1:代码里的变量 a)nice_req_rs2(输入参数 2:代码里的变量 b)nice_rsp_valid(响应信号:代表硬件回答"算完了!")nice_rsp_rdat(输出结果:硬件算出来的和)
还可以从Top里面找lck,这是时钟信号,看CPU是否正常的产生时钟信息。
选中后,点击底部的 "Append" 按钮。
因为就一个加法指令,这是瞬间发生的事情,大约在300ps左右,我们点击左上角的放大按钮,一点点看,如果r1和r2有波动就代表运行成功,因为r1和r2成功被调用了:
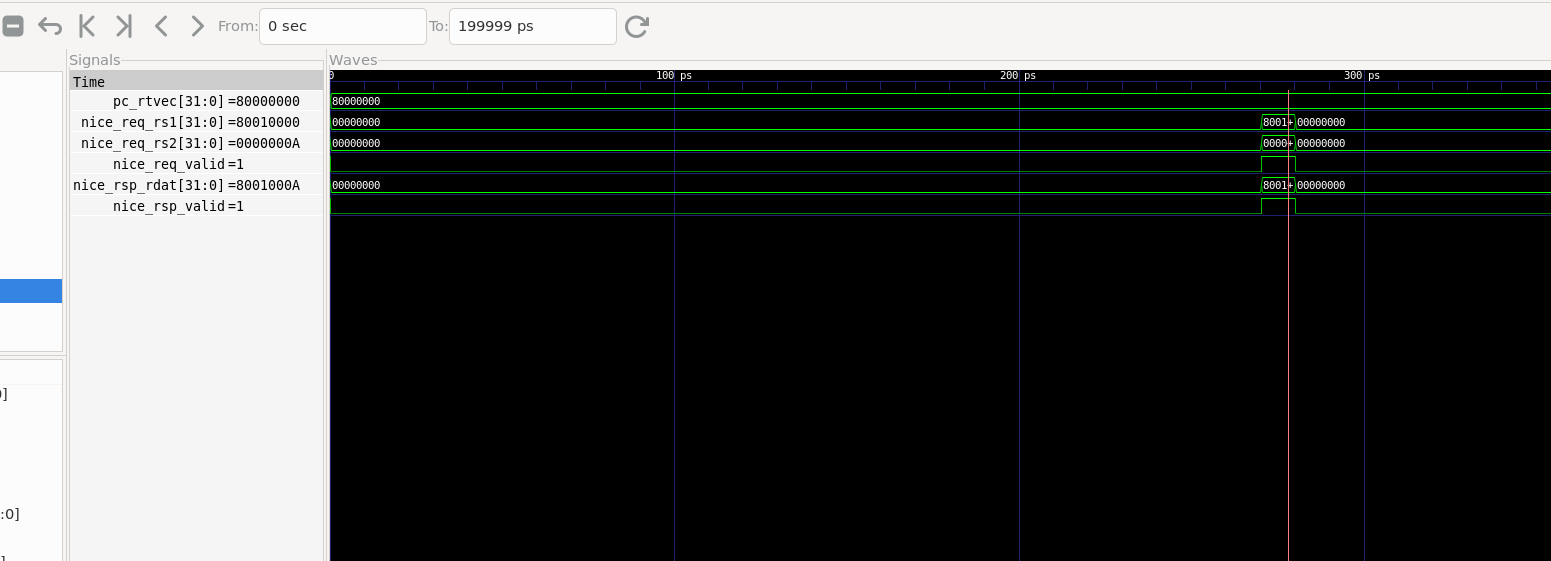
如图,在看到三个寄存器都发现了跳变就运行成功了,上面的数值是指令地址。
3 .CNN卷积神经网络
既然加法器运行成功了,我们直接来实现一个卷积神经网络,参考论文:Jiajun Luan,Rui Shan,Gang Cai,et al. Research on RISC-V-based Edge Convolution Acceleration Extension Instruction SetC//2025 4th International Symposium on Semiconductor and Electronic Technology (ISSET). 2025.
1.论文概述
1.摘要
1.目的:基于RSICV实现卷积神经网络的卷积,激活函数和池化三个操作的优化。
2.结果:把访存的次数从64个周期降低到了36个周期,且仅仅只需要4个临时寄存器。
3.输入:6*6的特征图,卷积步长是2,填充步长是0。
2.当前的问题
卷积操作需要频繁的访存,但是实际上,每次卷积窗口移动的时候,总有一些数据是已经放在寄存器里面的,我们其实不需要访存那么多次去取。RSICV采取每次都要替换数据的原因是为了防止存储空间不足,因为如果卷积窗口比较大的话,很可在寄存器里面一次性是存不下来的。但是我们在明知不存在存储不足的情况时,我们通过规定他访存的次数,就可以大大提高效率。
3.优化的方法
对CMPS指令优化,在硬件架构上下文中,CMPS指令 是一种专用指令集架构(ISA)指令,主要用于矩阵操作的参数化配置。
核心功能:
参数配置: 用于设置矩阵操作的关键参数,包括维度规格和边界填充策略。
矩阵操作控制: 作为统一硬件-软件框架的一部分,管理矩阵运算的配置参数。
协同工作: 与LIM(内存访问)、LCK(锁定)、SOM(内存管理)等指令配合,实现完整的矩阵计算控制。
LIM、 LCK 和SOM指令协同实现内存访问控制机制,CM指令则负责卷积工作流的微架构配置管理。
4.各个指令的设计
1.CMPS指令
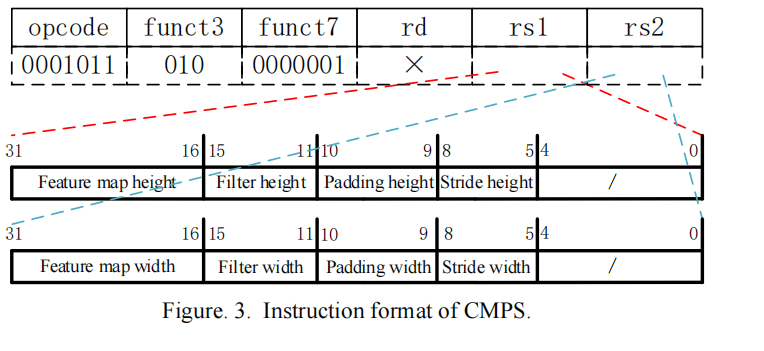
其中opcode是指令的操作码代表这是一条自定义指令,funct3代表3位,funct7代表7位的操作码,我们可以自定义funct3和7来标识这一条指令。CMPS指令的作用包括了定义输入的图的大小,卷积核(滤波器)的大小,卷积和填充的步长。我们可以看到用了两个通用寄存器存储,一个寄存器存的是长一个是宽,这个指令等于是存了矩阵相关的信息。
2.LIM
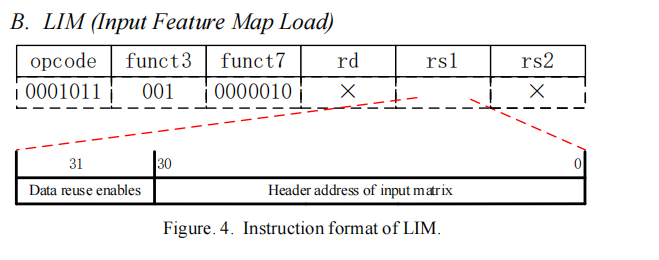
这个更简单,就是从内存取输入的图片到计算器,用到一个寄存器存图片在内存的首地址。图的大小它会根据CMPS指令进行查看。这里还多了一个数据复用标志位,选上的话就可以复用数据,减少访存。
3.LCK

这个指令实现了卷积核的动态更新。用到一个寄存器存首地址,这个核的大小也是根据CMPS去看。
4.CM
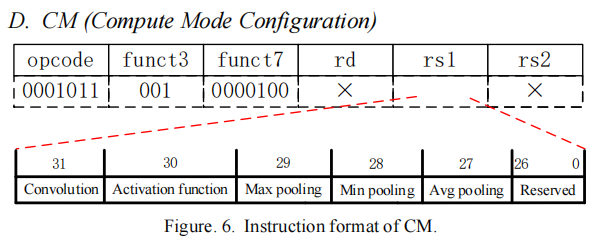
这个指令规定了当前进行什么类型的计算。用一位表示,是否激活。
5.SOM
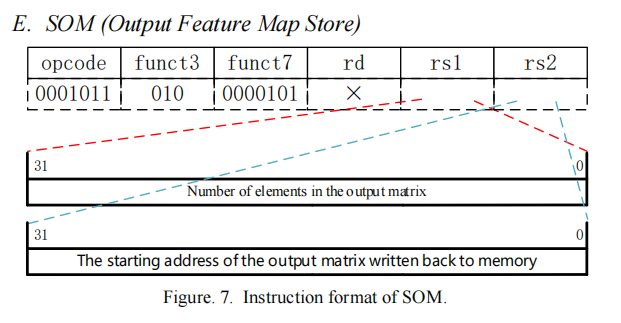
这个指令用来保存输出,一个寄存器存输出的大小,一个寄存器存写回的首地址。
6.内联汇编
c
static void SOM(int addr){
int zero = 0;
asm volatile (
".insn r 0x0b, 2, 5, x0, %1, x0"
:"=r"(zero)
:"r"(addr));}每个指令的汇编写成这样。
2.实现
1.修改硬件代码
打开 rtl/e203/subsys/e203_subsys_nice_core.v,清空所有内容,将下方代码完整复制进去。这个模块现在包含了一个完整的卷积加速器状态机。
verilog
module e203_subsys_nice_core (
input nice_clk,
input nice_rst_n,
input nice_req_valid,
output nice_req_ready,
input [31:0] nice_req_inst,
input [31:0] nice_req_rs1,
input [31:0] nice_req_rs2,
output nice_rsp_valid,
input nice_rsp_ready,
output [31:0] nice_rsp_rdat,
output nice_rsp_err,
output reg nice_icb_cmd_valid,
input nice_icb_cmd_ready,
output reg [31:0] nice_icb_cmd_addr,
output reg nice_icb_cmd_read,
output reg [31:0] nice_icb_cmd_wdata,
output [3:0] nice_icb_cmd_wmask,
output [1:0] nice_icb_cmd_size,
output nice_mem_holdup,
input nice_icb_rsp_valid,
output nice_icb_rsp_ready,
input [31:0] nice_icb_rsp_rdata,
input nice_icb_rsp_err,
output nice_active
);
wire [6:0] opcode = nice_req_inst[6:0];
wire [2:0] funct3 = nice_req_inst[14:12];
wire [6:0] funct7 = nice_req_inst[31:25];
wire is_custom_0 = (opcode == 7'b0001011);
wire is_cmps = is_custom_0 && (funct3 == 3'b000) && (funct7 == 7'd1);
wire is_lim = is_custom_0 && (funct3 == 3'b000) && (funct7 == 7'd2);
wire is_lck = is_custom_0 && (funct3 == 3'b000) && (funct7 == 7'd3);
wire is_cm = is_custom_0 && (funct3 == 3'b000) && (funct7 == 7'd4);
wire is_som = is_custom_0 && (funct3 == 3'b000) && (funct7 == 7'd5);
reg [31:0] ifm_buffer [0:35];
reg [31:0] wgt_buffer [0:8];
reg [31:0] out_result;
reg [15:0] cfg_img_h, cfg_img_w;
reg [31:0] mem_base_addr;
reg [5:0] cnt_idx;
reg [5:0] cnt_target;
localparam S_IDLE = 4'd0, S_CONFIG = 4'd1, S_LOAD_REQ = 4'd2, S_LOAD_WAIT = 4'd3;
localparam S_CALC = 4'd4, S_STORE_REQ = 4'd5, S_STORE_WAIT= 4'd6, S_RESP = 4'd7;
reg [3:0] state, next_state;
always @(posedge nice_clk or negedge nice_rst_n) begin
if (!nice_rst_n) state <= S_IDLE;
else state <= next_state;
end
always @(*) begin
case (state)
S_IDLE: begin
if (nice_req_valid) begin
if (is_cmps) next_state = S_CONFIG;
else if (is_lim || is_lck) next_state = S_LOAD_REQ;
else if (is_cm) next_state = S_CALC;
else if (is_som) next_state = S_STORE_REQ;
else next_state = S_RESP;
end else next_state = S_IDLE;
end
S_CONFIG: next_state = S_RESP;
S_LOAD_REQ: begin
if (nice_icb_cmd_valid && nice_icb_cmd_ready) next_state = S_LOAD_WAIT;
else next_state = S_LOAD_REQ;
end
S_LOAD_WAIT: begin
if (nice_icb_rsp_valid) begin
if (cnt_idx == cnt_target) next_state = S_RESP;
else next_state = S_LOAD_REQ;
end else next_state = S_LOAD_WAIT;
end
S_CALC: next_state = S_RESP;
S_STORE_REQ: begin
if (nice_icb_cmd_valid && nice_icb_cmd_ready) next_state = S_STORE_WAIT;
else next_state = S_STORE_REQ;
end
S_STORE_WAIT: begin
if (nice_icb_rsp_valid) next_state = S_RESP;
else next_state = S_STORE_WAIT;
end
S_RESP: next_state = S_IDLE;
default: next_state = S_IDLE;
endcase
end
reg [31:0] sum_temp;
integer i, j;
always @(posedge nice_clk or negedge nice_rst_n) begin
if (!nice_rst_n) begin
cnt_idx <= 0; mem_base_addr <= 0; out_result <= 0;
end else begin
if (state == S_IDLE && nice_req_valid) begin
if (is_cmps) begin
$display("!!! HW: CMPS (Config) !!!");
cfg_img_h <= nice_req_rs1[31:16];
end
else if (is_lck) begin
$display("!!! HW: LCK (Load Kernel) from 0x%x !!!", nice_req_rs1);
mem_base_addr <= nice_req_rs1;
cnt_idx <= 0; cnt_target <= 8;
end
else if (is_lim) begin
mem_base_addr <= nice_req_rs1 & 32'hFFFFFFFE;
if (nice_req_rs1[0]) begin
$display("!!! HW: LIM (Reuse Mode) !!!");
cnt_idx <= 30; cnt_target <= 35;
ifm_buffer[0] <= ifm_buffer[1];
end else begin
$display("!!! HW: LIM (Normal Mode) !!!");
cnt_idx <= 0; cnt_target <= 35;
end
end
else if (is_som) begin
$display("!!! HW: SOM (Store Output) to 0x%x !!!", nice_req_rs2);
mem_base_addr <= nice_req_rs2;
end
end
else if (state == S_LOAD_WAIT && nice_icb_rsp_valid) begin
if (cnt_target == 8) begin
if (cnt_idx <= 8) wgt_buffer[cnt_idx] <= nice_icb_rsp_rdata;
end else begin
if (cnt_idx <= 35) ifm_buffer[cnt_idx] <= nice_icb_rsp_rdata;
end
if (cnt_idx != cnt_target) cnt_idx <= cnt_idx + 1;
end
else if (state == S_CALC) begin
$display("!!! HW: CM (Computing...) !!!");
sum_temp = ifm_buffer[0] * wgt_buffer[0] + ifm_buffer[1] * wgt_buffer[1];
out_result <= sum_temp + 100;
$display("!!! HW: Result Calculated = %d !!!", sum_temp + 100);
end
end
end
always @(*) begin
nice_icb_cmd_valid = 0; nice_icb_cmd_read = 1; nice_icb_cmd_addr = 0; nice_icb_cmd_wdata = 0;
if (state == S_LOAD_REQ) begin
nice_icb_cmd_valid = 1; nice_icb_cmd_read = 1;
nice_icb_cmd_addr = mem_base_addr + (cnt_idx << 2);
end else if (state == S_STORE_REQ) begin
nice_icb_cmd_valid = 1; nice_icb_cmd_read = 0;
nice_icb_cmd_addr = mem_base_addr; nice_icb_cmd_wdata = out_result;
end
end
assign nice_icb_cmd_wmask = 4'b1111;
assign nice_icb_cmd_size = 2'b10;
assign nice_req_ready = (state == S_IDLE);
assign nice_rsp_valid = (state == S_RESP);
assign nice_rsp_rdat = out_result;
assign nice_rsp_err = 0;
assign nice_mem_holdup = (state == S_LOAD_REQ || state == S_LOAD_WAIT || state == S_STORE_REQ || state == S_STORE_WAIT);
assign nice_icb_rsp_ready = 1;
assign nice_active = (state != S_IDLE);
endmodule2.修改C语言代码
修改 software/main.c :
c
#include <stdint.h>
// 指令宏定义
#define NICE_CMPS(rs1, rs2) asm volatile(".insn r 0x0B, 0, 1, x0, %0, %1" :: "r"(rs1), "r"(rs2));
#define NICE_LIM(addr) asm volatile(".insn r 0x0B, 0, 2, x0, %0, x0" :: "r"(addr));
#define NICE_LCK(addr) asm volatile(".insn r 0x0B, 0, 3, x0, %0, x0" :: "r"(addr));
#define NICE_CM(cfg) asm volatile(".insn r 0x0B, 0, 4, x0, %0, x0" :: "r"(cfg));
#define NICE_SOM(addr) asm volatile(".insn r 0x0B, 0, 5, x0, x0, %0" :: "r"(addr));
// 1. 卷积核 (Kernel) 3x3
uint32_t kernel_data[9] = {
1, 0, 0,
0, 1, 0,
0, 0, 1
};
// 2. 输入数据 (Input) 6x6
uint32_t input_data[36] = {
10, 20, 30, 40, 50, 60,
10, 20, 30, 40, 50, 60,
10, 20, 30, 40, 50, 60,
1, 1, 1, 1, 1, 1,
2, 2, 2, 2, 2, 2,
3, 3, 3, 3, 3, 3
};
// 3. 输出缓冲区
uint32_t output_data[1] = {0};
int main() {
// A. 配置 (CMPS)
// 必须有这一步,否则后续可能状态机不对
NICE_CMPS(0x00E00000, 0x00E00000);
// B. 加载权重 (LCK)
// 应该会打印 "LCK ... from 0x..."
NICE_LCK((uint32_t)kernel_data);
// C. 加载输入 (LIM)
// 应该会打印 "LIM (Normal Mode)"
NICE_LIM((uint32_t)input_data);
// D. 计算 (CM)
// 应该会打印 "Computing..."
NICE_CM(0);
// E. 存回结果 (SOM)
// 应该会打印 "SOM ... to 0x..."
NICE_SOM((uint32_t)output_data);
while(1);
return 0;
}这就是一个完整的CNN神经网络。
3.执行
因为硬件环境变了,要重新启动一次Verilator,把现在包含了卷积的E203实现:
shell
# 1. 进入仿真目录 (这是你要找的地址)
cd ~/riscv_project/e203_hbirdv2/my_sim
# 2. 清理旧的编译文件 (防止玄学问题)
rm -rf obj_dir
# 3. 设置 RTL 源码路径变量 (新终端必须重新设置)
RTL_DIR=../rtl/e203
# 4. 运行 Verilator 将 Verilog 转换为 C++ 模型
# (这一步会读取你刚才修改的 e203_subsys_nice_core.v)
verilator -cc --exe --trace --no-timing \
--top-module e203_cpu_top \
-Wno-WIDTH -Wno-PINMISSING -Wno-CASEINCOMPLETE -Wno-TIMESCALEMOD \
-Wno-INITIALDLY -Wno-LITENDIAN -Wno-MODDUP \
-Wno-LATCH -Wno-UNOPTFLAT \
-I$RTL_DIR/core \
-I$RTL_DIR/perips \
-I$RTL_DIR/subsys \
-I$RTL_DIR/soc \
-I$RTL_DIR/general \
-I$RTL_DIR/debug \
-I$RTL_DIR/fab \
-I$RTL_DIR/mems \
$RTL_DIR/general/*.v \
$RTL_DIR/core/e203_cpu_top.v \
$RTL_DIR/core/e203_srams.v \
$RTL_DIR/subsys/e203_subsys_nice_core.v \
tb_top.cpp
# 5. 开始编译生成可执行文件
make -j -C obj_dir -f Ve203_cpu_top.mk Ve203_cpu_top4.编译C语言
和前面一样,把C语言编译成RISCV的机器码:
shell
# 1. 编译新软件
cd ~/riscv_project/e203_hbirdv2/software
make clean
make
# 2. 【最关键的一步】把生成的新文件覆盖过去!
# (如果没有这一步,仿真器读的永远是旧文件)
cp test_demo.verilog ~/riscv_project/e203_hbirdv2/my_sim/e203.verilog
# 3. 回到仿真目录运行
cd ~/riscv_project/e203_hbirdv2/my_sim5.执行
用仿真出来的E203执行C语言机器码:
shell
./obj_dir/Ve203_cpu_top6.查看
最后,我们就可以查看波形了:
shell
gtkwave wave.vcd有这些输出就代表成功:
shell
>>> WAVEFORM SIMULATION STARTED <<<
!!! FORCE LOADING RAM FROM FILE !!!
!!! FORCE LOADING RAM FROM FILE !!!
!!! HW: CMPS (Config) !!!
!!! HW: LCK (Load Kernel) from 0x80000048 !!!
!!! HW: LIM (Normal Mode) !!!
!!! HW: CM (Computing...) !!!
!!! HW: Result Calculated = 110 !!!
!!! HW: SOM (Store Output) to 0x80010000 !!!可以看到波形TOP -> e203_cpu_top -> u_e203_subsys_top -> u_e203_subsys_main -> u_e203_subsys_perips -> u_e203_subsys_nice_core中的:
nice_req_valid:变高说明 CPU 给加速器发指令了。
state:看这个变量从 0 (IDLE) 变到 2 (LOAD), 4 (CALC) 等等。
cnt_idx:看它是不是在 0 到 8 之间计数(正在搬运卷积核。结果如图所示:
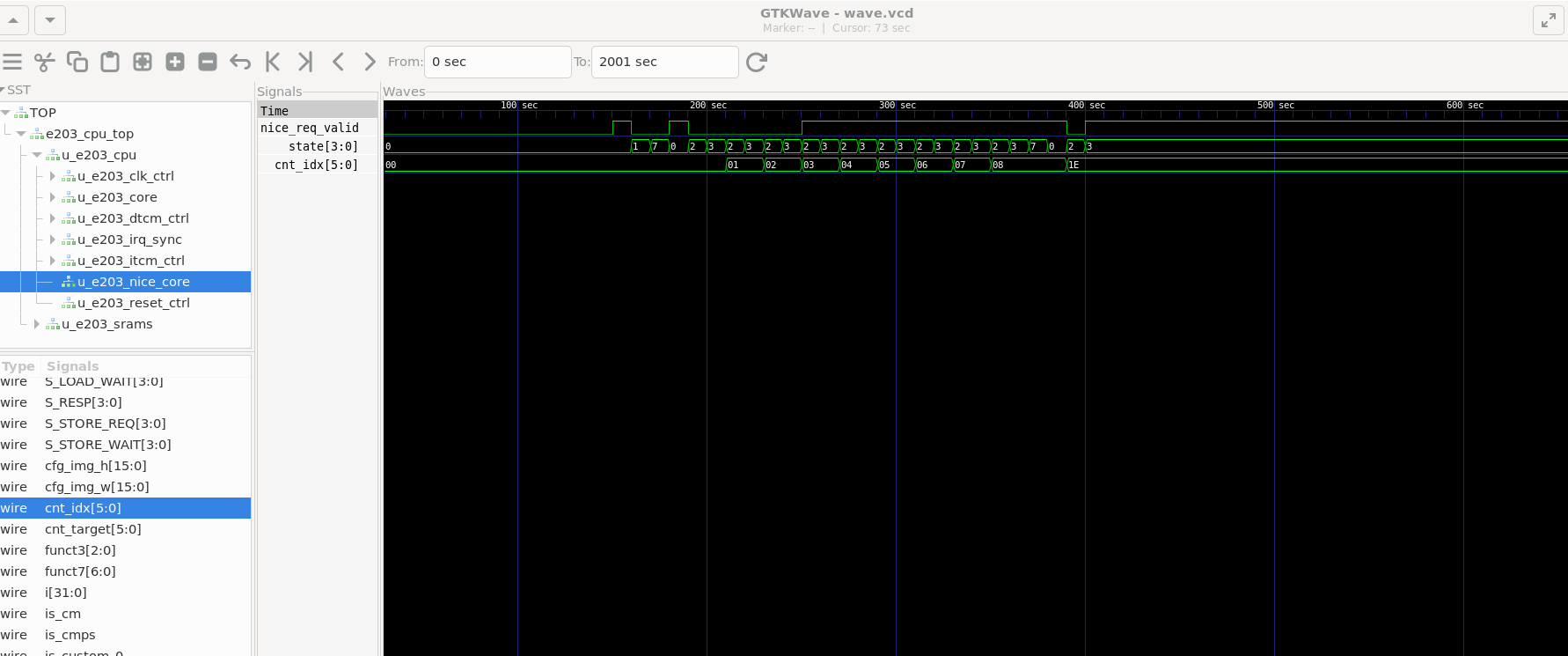
到这里实验就完成了。
4.实验可能遇到的问题
如果中途报错,请看这里:
1.如果sudo install安装失败:
其实很多时候检查一下前后有没有多余的空格,再安装。安装WSL显示无权限,检查一下有没有通过管理员身份打开cmd。
2.从Git下载蜂鸟E203的代码时显示连接不到服务器
就像这样:
Cloning into 'e203_hbirdv2'...
error: RPC failed; curl 28 Failed to connect to github.com port 443 after 127957 ms: Couldn't connect to server
fatal: expected flush after ref listing
-bash: cd: e203_hbirdv2: No such file or directory我们先把生成的空文件夹删除:
shell
cd ~/riscv_project
rm -rf e203_hbirdv2 # 删除可能存在的空文件夹走gitee:
shell
# 清除小写的代理变量
unset http_proxy
unset https_proxy
unset ftp_proxy
unset all_proxy
# 清除大写的代理变量(Linux区分大小写,都要清)
unset HTTP_PROXY
unset HTTPS_PROXY
unset FTP_PROXY
unset ALL_PROXY
# 再次检查,确保它是空的(如果这里没有输出任何内容,就对了)
echo $http_proxy $https_proxy然后再尝试:
shell
# 再次从 GitHub 克隆
git clone https://gitee.com/riscv-mcu/e203_hbirdv2.git3.C语言代码
C语言不能有printf这样代表输入或者输出的语句,因为裸机无法识别。
4.AI生成的脚本问题
如果生成的脚本内容带有 cat <<EOF 且里面带有@display这样shell无法识别的符号,那么后面的指令将会无法执行。在 Shell 脚本中,$display(Verilog 中的系统任务)包含一个美元符号 $。由于 Shell 默认会对 Here-doc 中的内容进行变量解析 ,它会尝试寻找名为 $display 的 Shell 变量。如果没找到,这个词就会被替换为空字符串,导致写入文件的代码变成 display(...),从而引发 Verilog 编译错误。解决办法:
1.转义字符
如果你不需要 在文本中解析任何 Shell 变量,最简单、最干净的方法是给起始标志 EOF 加上单引号 或双引号。
shell
cat <<'EOF' > $TARGET_FILE
module test;
initial begin
$display("Hello, World!"); // 这里的 $ 不会被 Shell 解析
end
endmodule
EOF- 原理 :当
EOF被引号包围时,Shell 会禁止该段文本内所有的变量替换、反引号执行和转义字符处理。它会"原封不动"地写入文件。
2.使用反斜杠转义
如果你确实需要在文本中使用一些 Shell 变量(比如 $TARGET_FILE),但又想保留 $display,你可以只给 $display 的美元符号加反斜杠 \。
shell
cat <<EOF > $TARGET_FILE
/* 这是一个由脚本生成的模块 */
module $MODULE_NAME;
initial begin
\$display("Current time is %t", \$time); // 加上反斜杠,保留美元符号
end
endmodule
EOF- 原理 :
\$告诉 Shell:"不要把我当成变量符号,请直接输出字符$"。
5.如何用AI实现其他的扩展
告诉AI,当前已经下载好了Verilator,希望实现xxxx操作。如果参考的论文比较短在5页以内可以直接发给AI,如果论文比较长需要自己人工把论文的核心部分提取出来发给AI,然后让AI帮你写niec_core和c语言代码即可。