作为一名对AI图像生成与编辑充满热情的开发者,我最近深度体验了美团最新开源的 LongCat-Image-Edit 模型。这款模型在图像编辑任务中展现出令人印象深刻的性能,尤其是在指令遵循精度和视觉一致性保持方面。
本文将通过开发者视角,分享我在昇腾NPU环境下从零开始部署和运行LongCat-Image-Edit的全过程,包括环境准备、代码调试、问题解决以及实践感悟。
模型概览:LongCat-Image-Edit的核心优势
LongCat-Image-Edit是基于美团LongCat-Image的图像编辑版本,支持中英双语指令,在开源图像编辑模型中达到了当前最先进的性能水平。
该模型有几个突出特点:
● 精准编辑能力:支持全局编辑、局部编辑、文本修改、参考引导编辑等多种编辑任务
● 一致性保持:在多轮编辑中能够保持非编辑区域的属性不变,如图像布局、纹理、色调等
● 高效推理:仅6B参数规模,在保持高质量输出的同时具有较好的推理效率
● 中文友好:对中文提示词有良好的支持,中文文字渲染能力出色
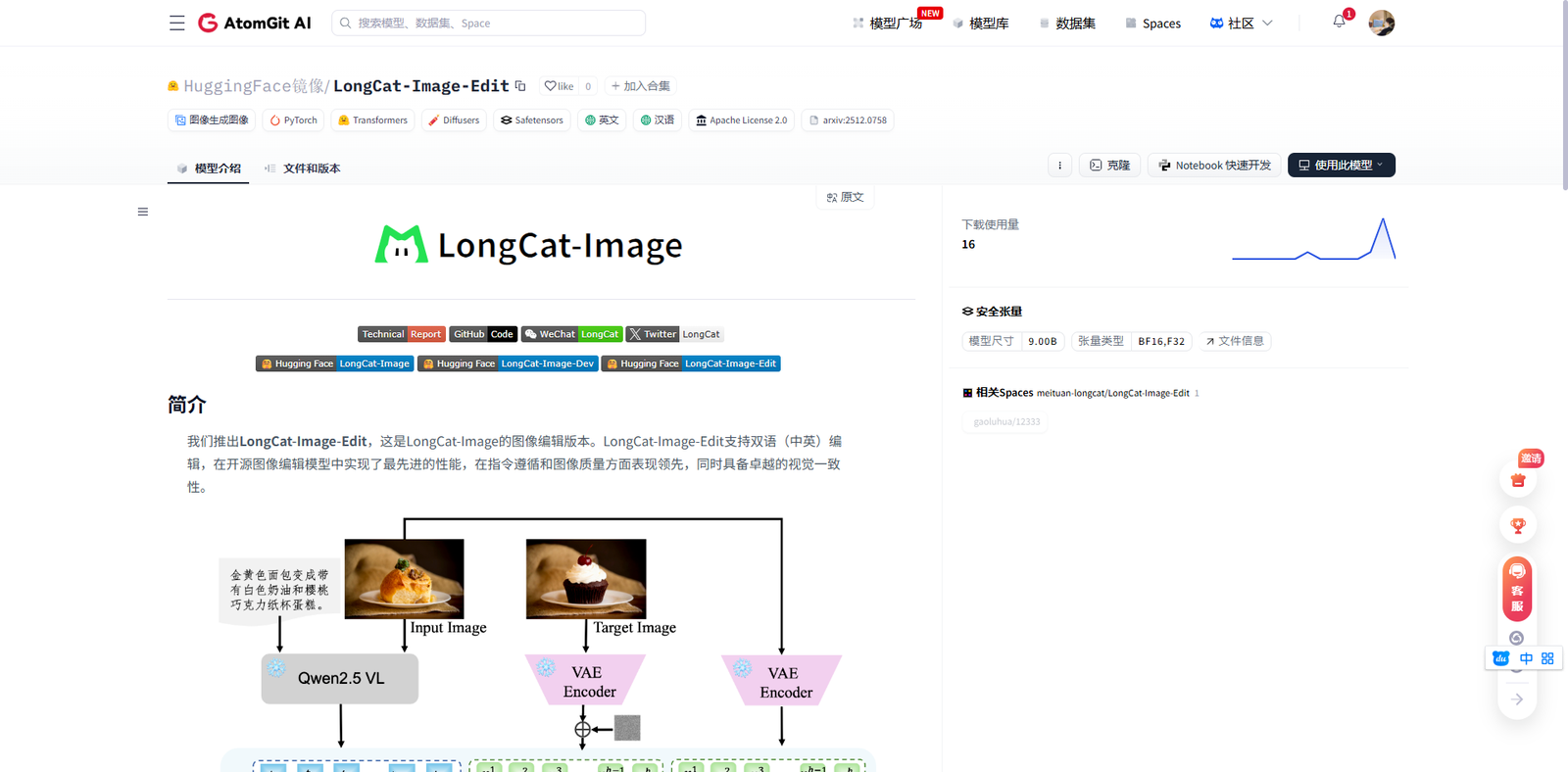
环境准备:昇腾NPU平台的一键配置
为了体验这款优秀的模型,我选择了华为云提供的昇腾NPU开发环境。特别值得一提的是,现在可以通过GitCode的Notebook服务,直接一键配置所需的开发环境。
在GitCode平台上,我选择了以下配置的资源:
● 计算资源:1 * 昇腾NPU · 32v CPU · 64GB内存
● 镜像环境:euler2.9-py38-mindspore2.3.0rc1-cann8.0-openmind0.6-notebook
● 存储空间:限时免费50GB
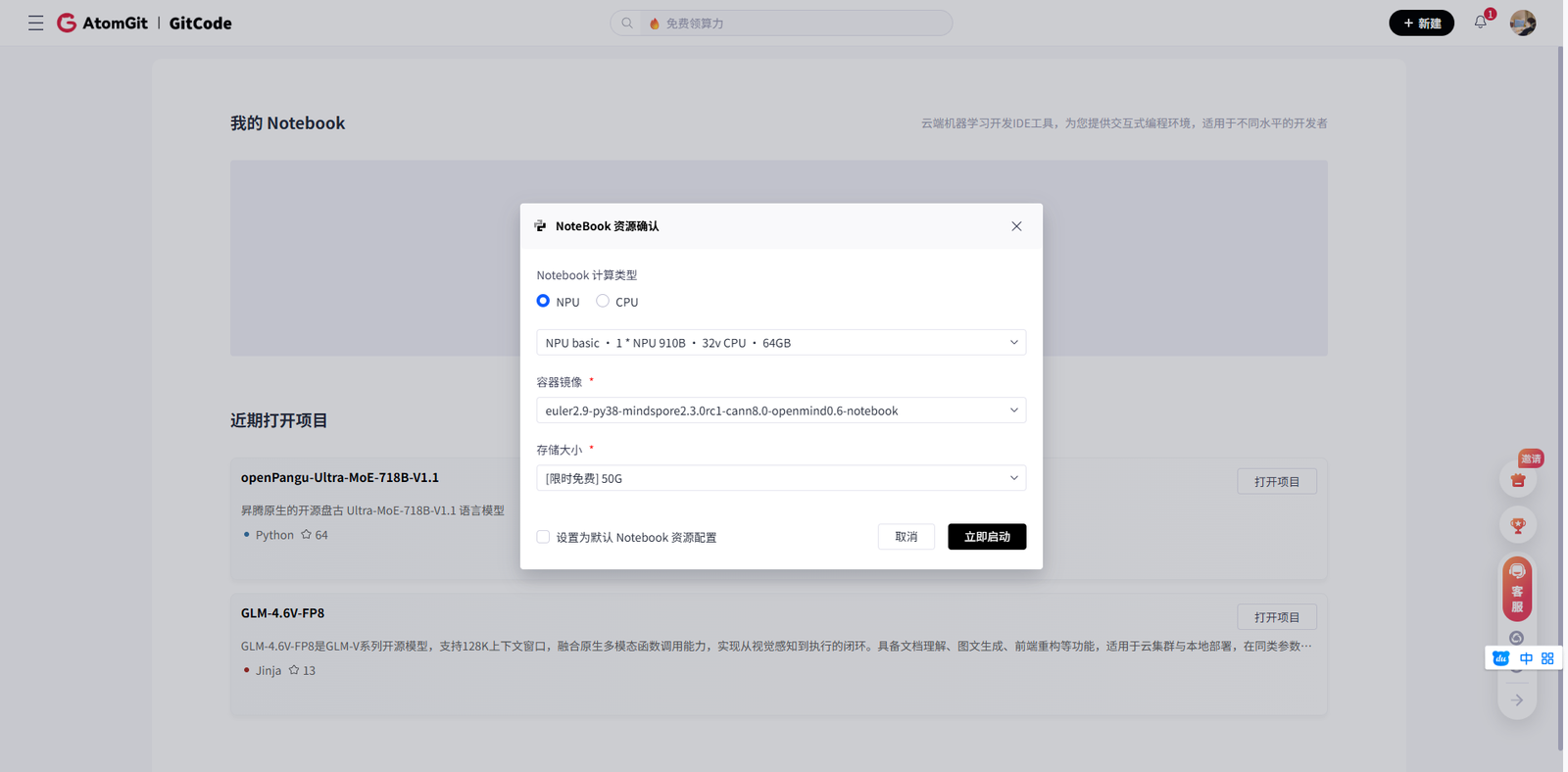
这个环境已经预装了昇腾计算架构所需的基础软件栈,包括CANN(Compute Architecture for Neural Networks)8.0版本,为后续的模型部署打下了坚实基础。
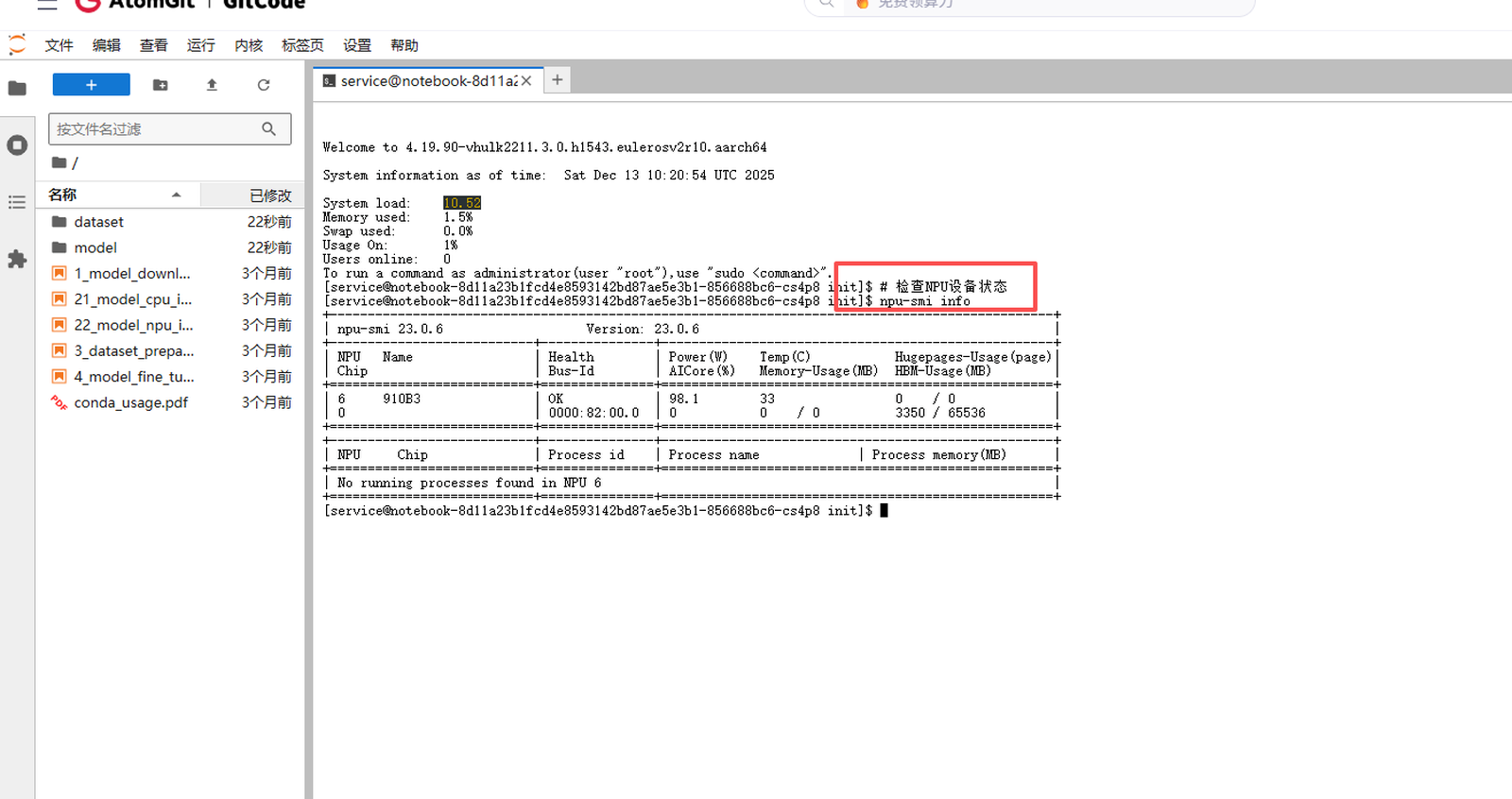
第一步:环境检查与依赖安装
进入Notebook环境后,我首先检查了NPU设备的可用状态:
# 检查NPU设备状态
npu-smi info命令执行后,系统显示了当前NPU设备的信息,确认设备工作正常。接下来需要安装模型运行所需的具体依赖。
1.1 创建并激活Python虚拟环境
这是Python 3.3+版本内置的工具,无需额外安装,兼容性最好。
# 1. 检查当前Python 3解释器的位置,通常是`python3`或`python`
python3 --version
# 2. 使用venv创建名为'longcat-edit'的虚拟环境
python3 -m venv longcat-edit
# 3. 激活虚拟环境
source longcat-edit/bin/activate
# 激活后,命令行提示符前通常会显示 '(longcat-edit)'
# 4. 验证:检查激活环境后的python和pip路径是否指向虚拟环境内部
which python
which pip
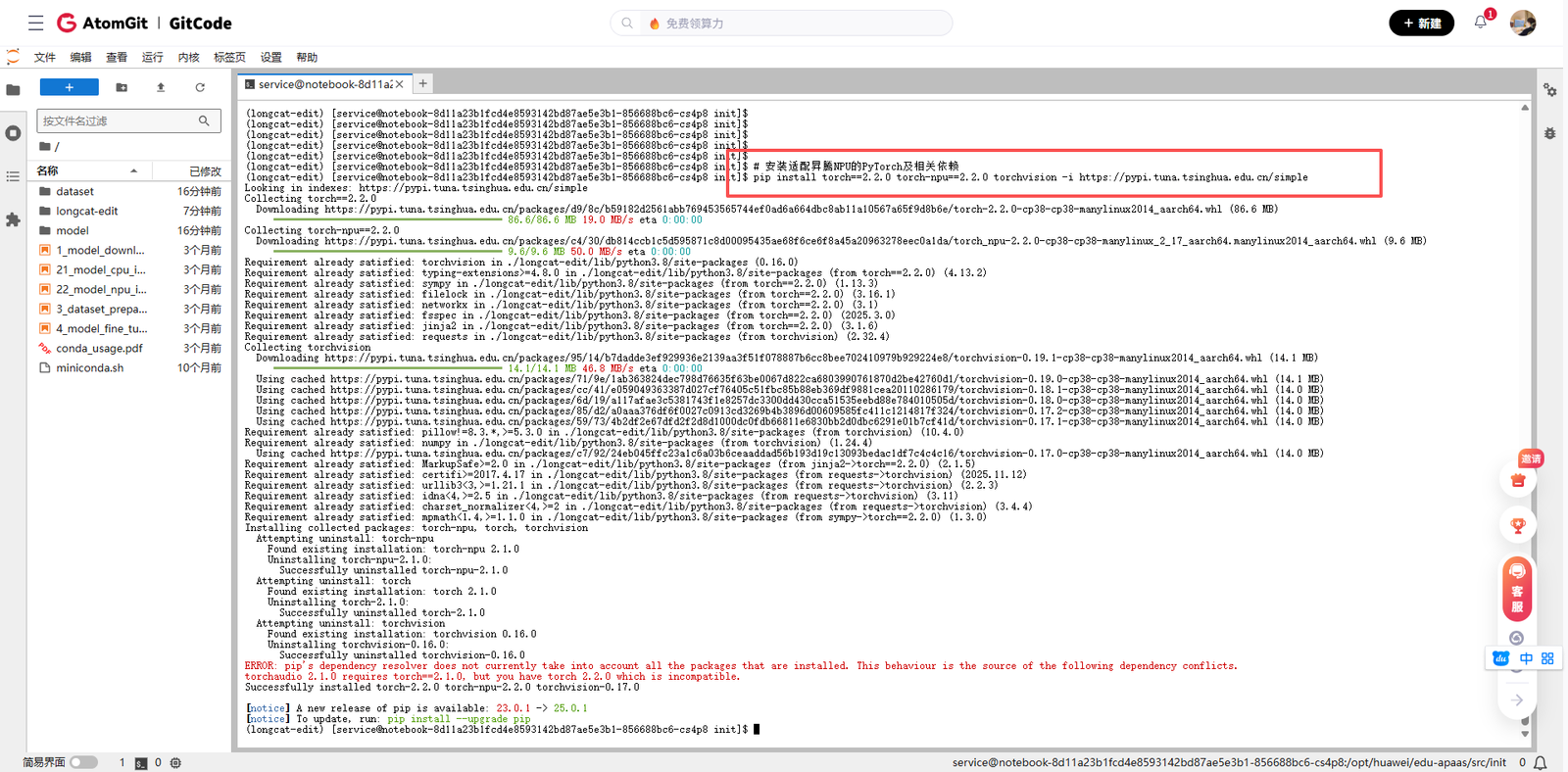
1.2 安装PyTorch和NPU支持
在昇腾NPU上运行模型,需要安装专门适配的PyTorch版本。根据昇腾官方文档的指导,我安装了对应的torch-npu包:
# 安装适配昇腾NPU的PyTorch及相关依赖
pip install torch==2.2.0 torch-npu==2.2.0 torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple这个步骤非常关键,torch-npu是PyTorch在昇腾NPU上的后端实现,它使得PyTorch的算子和模型能够正确地跑在NPU上。
1.3 安装Diffusers和其他必要库
LongCat-Image-Edit基于Hugging Face的Diffusers库构建,因此需要安装相应版本的diffusers:
# 安装diffusers和相关图像处理库
pip install diffusers transformers accelerate safetensors pillow -i https://pypi.tuna.tsinghua.edu.cn/simple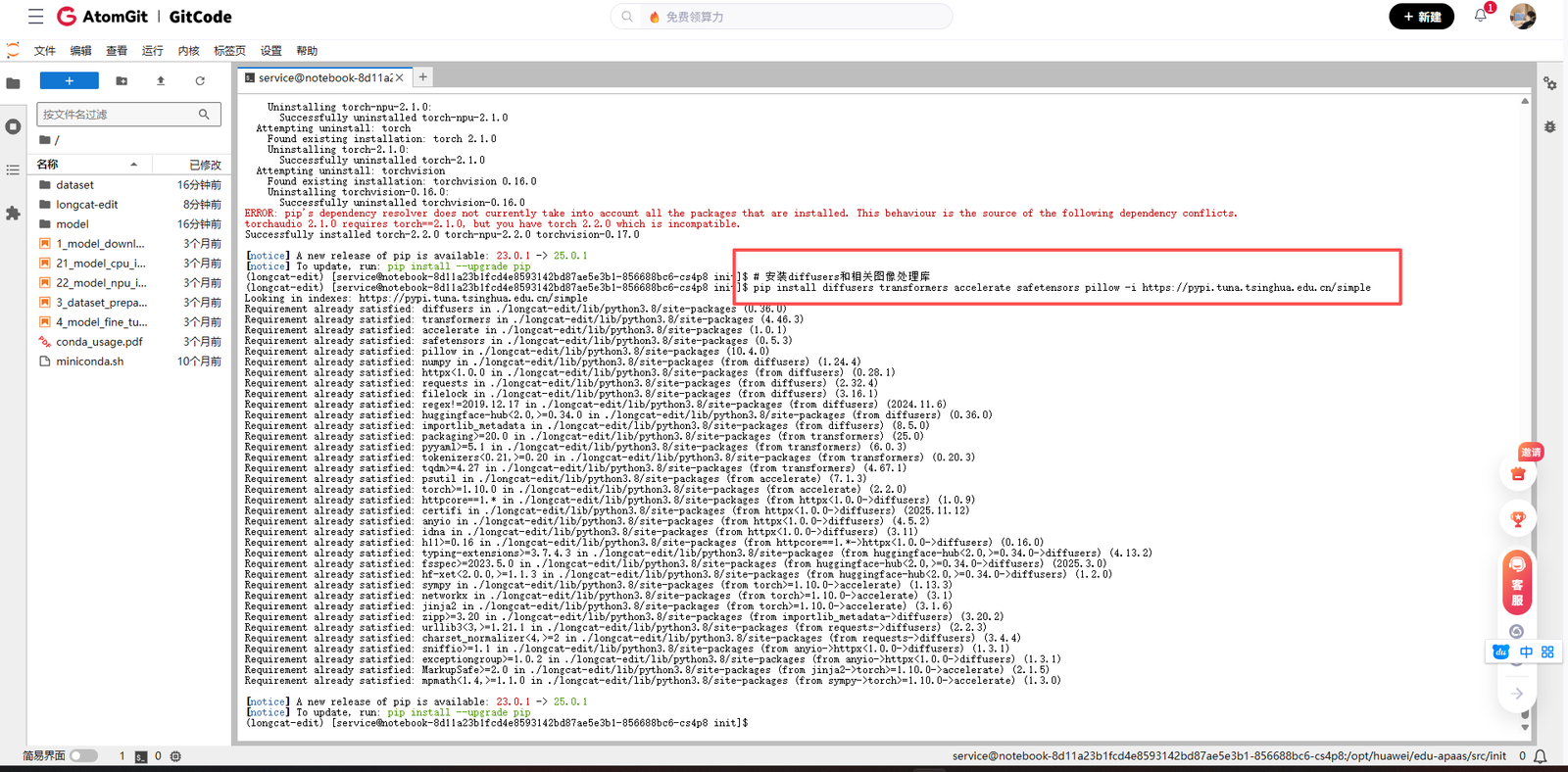
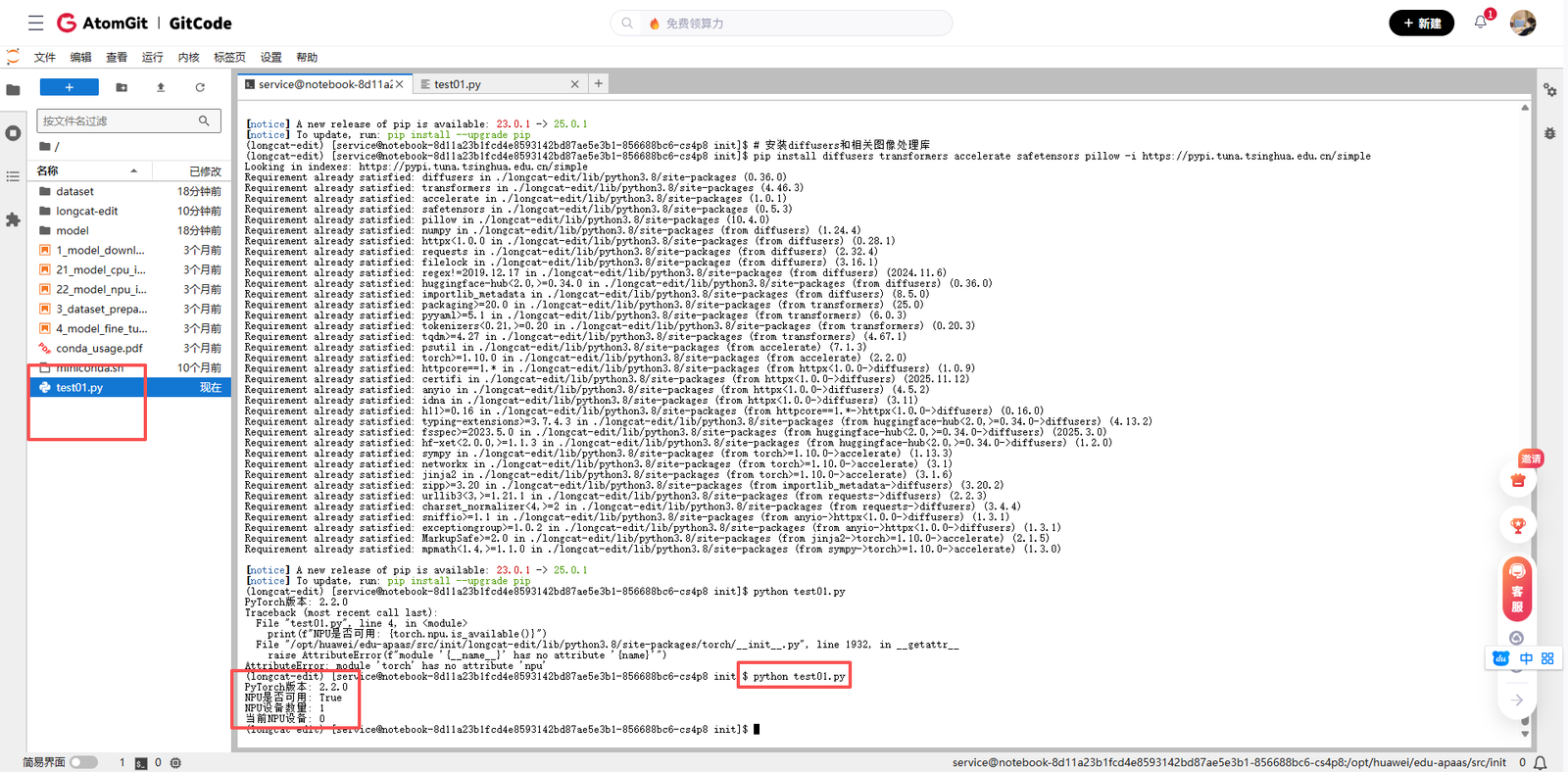
为了验证环境配置是否正确,我运行了一个简单的测试脚本:
# 环境验证代码
import torch
print(f"PyTorch版本: {torch.__version__}")
print(f"NPU是否可用: {torch.npu.is_available()}")
if torch.npu.is_available():
print(f"NPU设备数量: {torch.npu.device_count()}")
print(f"当前NPU设备: {torch.npu.current_device()}")看到输出显示NPU可用,说明基础环境已经准备就绪。
第二步:获取LongCat-Image-Edit模型代码和权重
2.1 克隆代码仓库
LongCat-Image的代码开源在GitHub上,我使用以下命令克隆了代码仓库:
git clone --single-branch --branch main https://github.com/meituan-longcat/LongCat-Image
cd LongCat-Image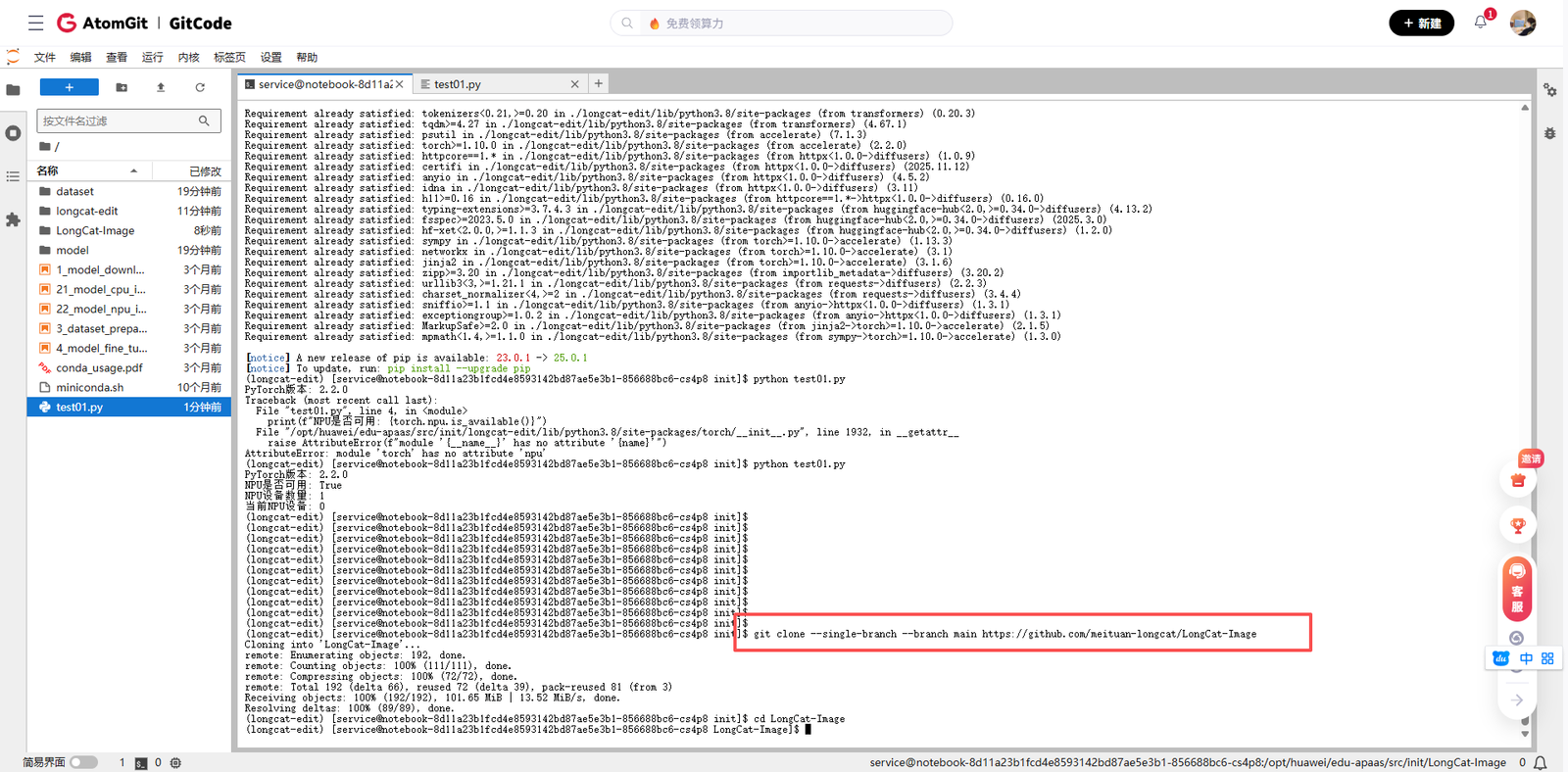
2.2 安装项目特定依赖
项目有自己的依赖要求,需要单独安装:
# 安装项目所需的其他依赖
pip install -r requirements.txt
# 以开发模式安装项目本身
python setup.py develop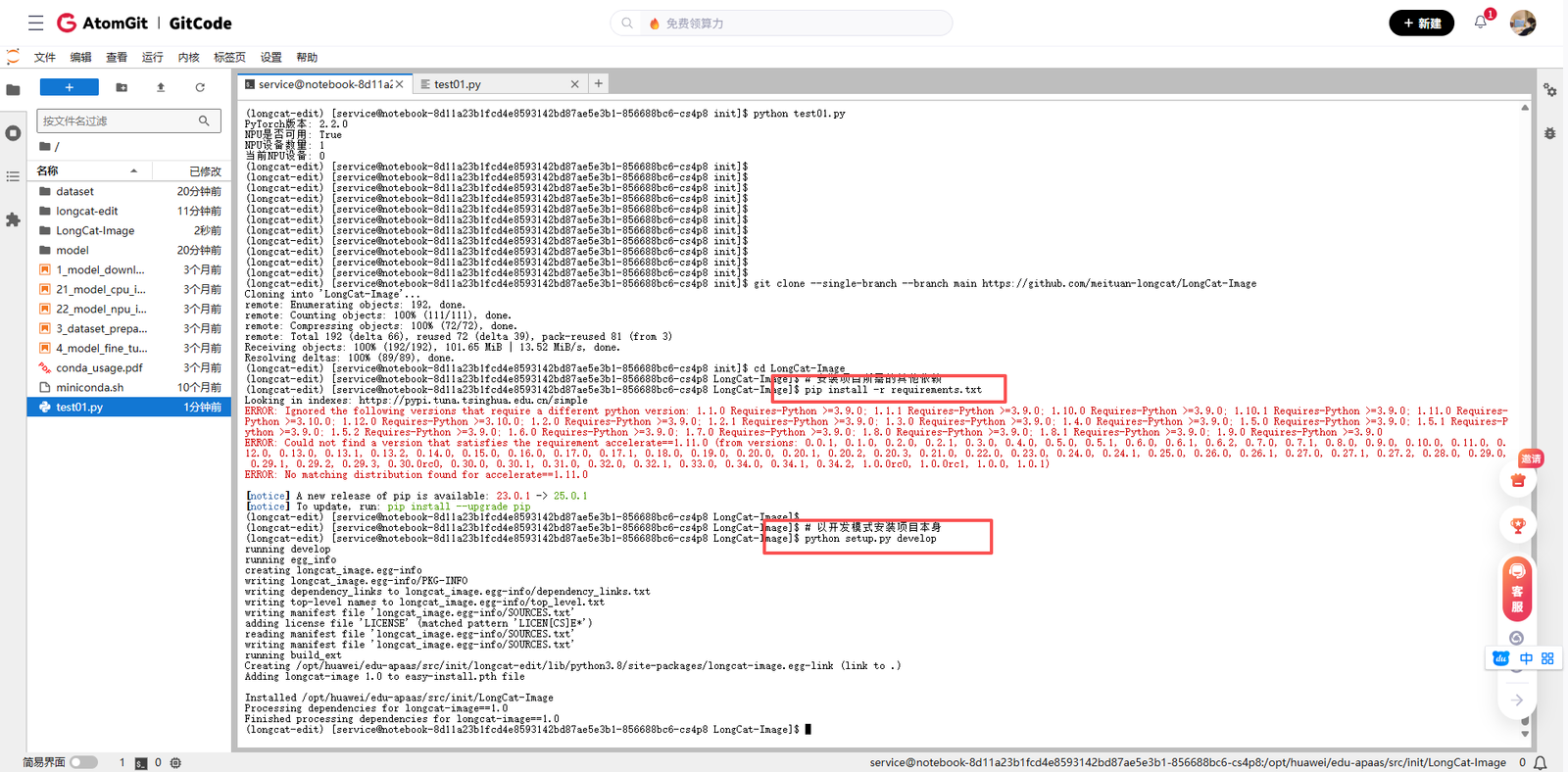
在这个过程中,我遇到了几个依赖版本冲突的问题。主要是某些库的版本要求与已经安装的版本不匹配。通过查看requirements.txt文件,我发现需要调整一些库的版本:
# 解决版本冲突
pip install einops==0.7.0
pip install omegaconf==2.3.0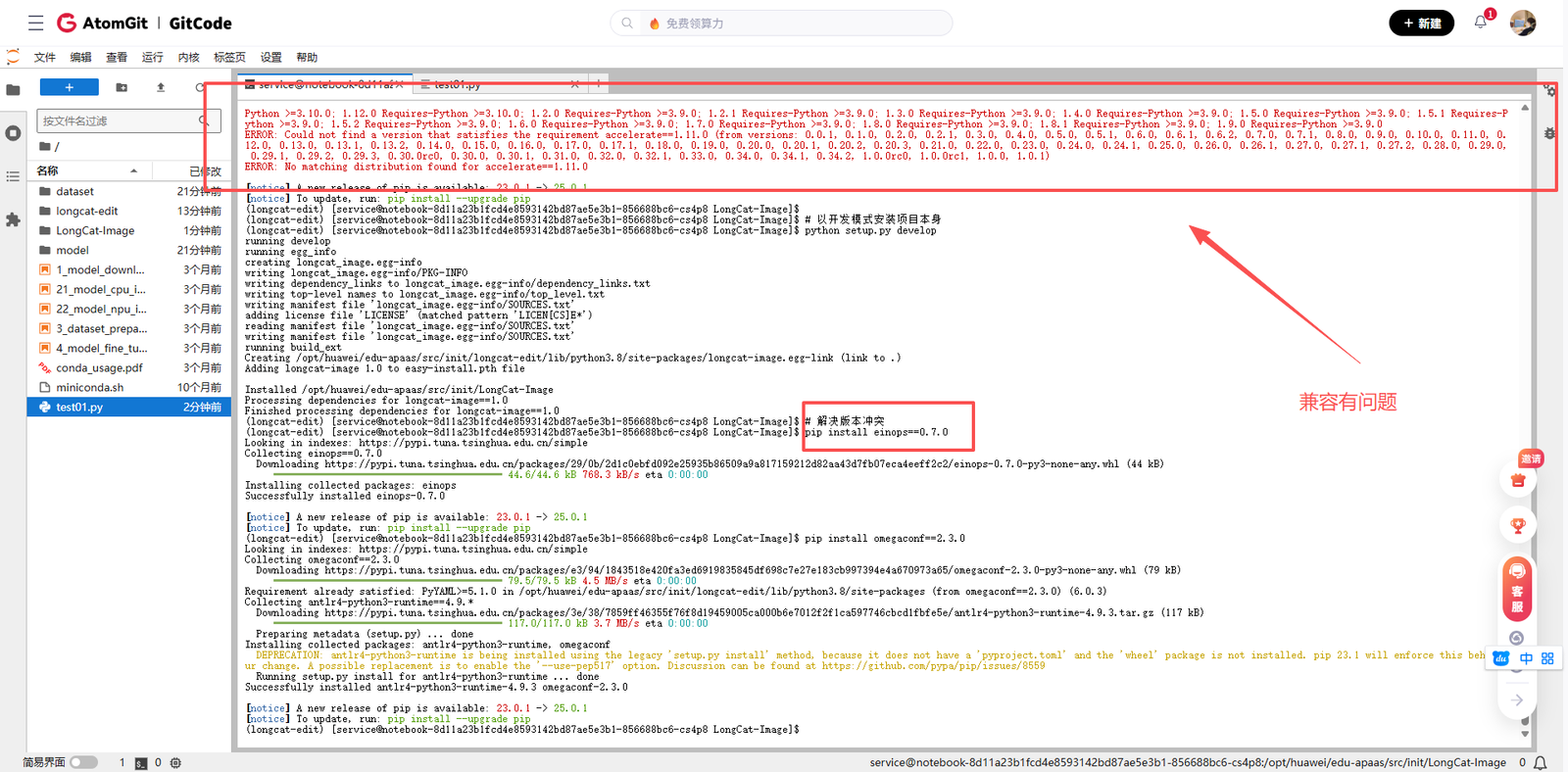
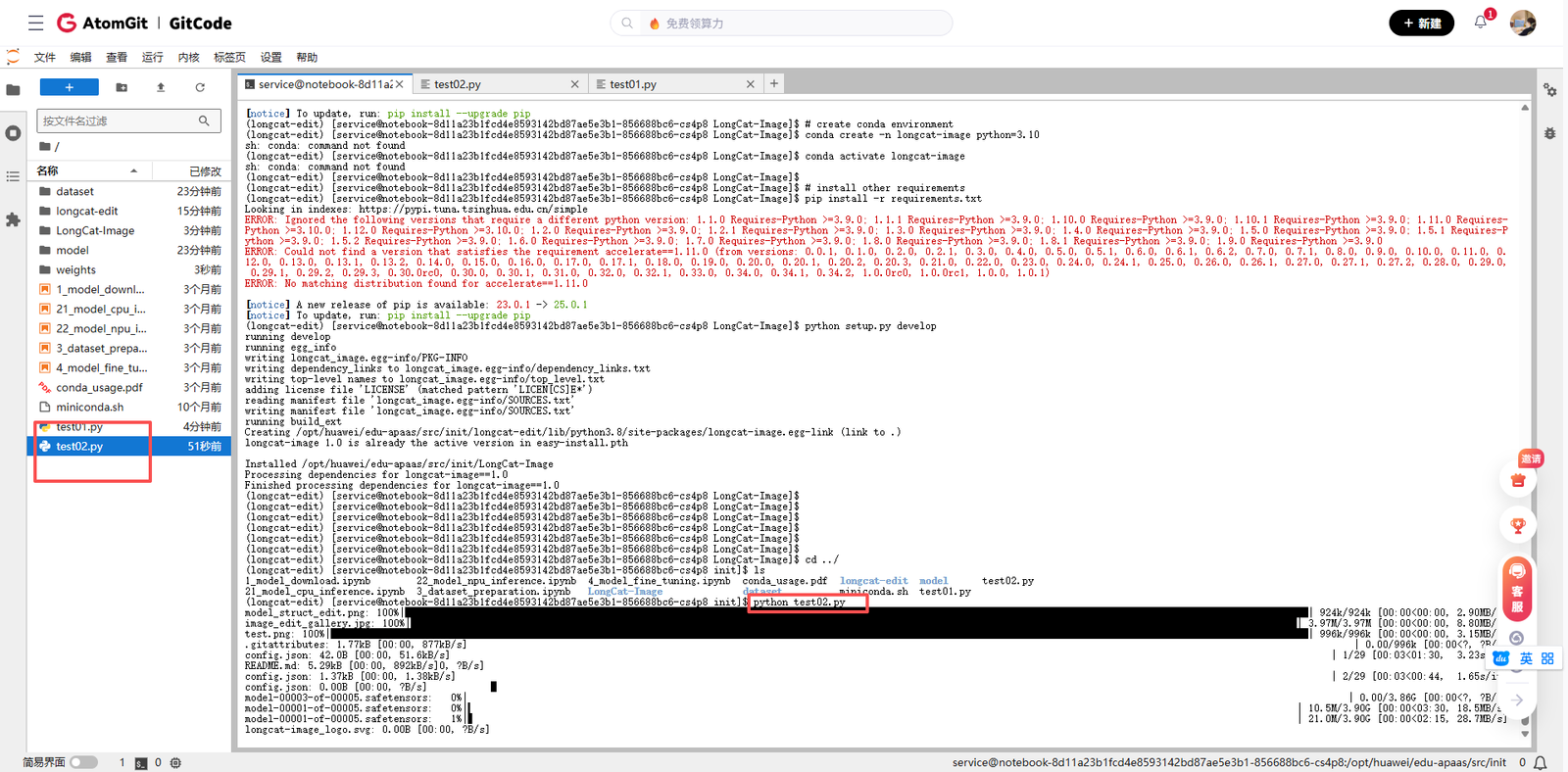
2.3 下载模型权重
LongCat-Image-Edit的模型权重托管在Hugging Face Hub上。我使用以下Python代码下载权重:
from huggingface_hub import snapshot_download
# 下载LongCat-Image-Edit模型权重
model_path = snapshot_download(
repo_id="meituan-longcat/LongCat-Image-Edit",
local_dir="./weights/LongCat-Image-Edit",
ignore_patterns=["*.msgpack", "*.bin"] # 忽略不必要的文件以加快下载
)
print(f"模型权重已下载到: {model_path}")由于模型文件较大(约12GB),下载需要一定时间。
第三步:编写模型推理代码
3.1 理解LongCat-Image-Edit的架构
在编写推理代码前,我仔细研究了LongCat-Image-Edit的架构。这是一个基于Transformer的扩散模型,特别优化了图像编辑任务。模型接收原始图像和编辑指令,输出编辑后的图像。
一个重要的注意事项是:对于涉及文本生成的任务,必须将目标文本用引号括起来(支持英文单引号/双引号和中文引号)。这是因为模型对引号内的内容采用专门的字符级编码策略,如果不使用显式引号,文本渲染效果会大打折扣。
3.2 创建推理脚本
我创建了一个完整的推理脚本inference.py,以下是代码的详细解析:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
LongCat-Image-Edit在昇腾NPU上的推理示例
作者:AI开发者
日期:2025年12月13日
"""
import torch
import argparse
from PIL import Image
from pathlib import Path
from transformers import AutoProcessor
from longcat_image.models import LongCatImageTransformer2DModel
from longcat_image.pipelines import LongCatImageEditPipeline
def setup_environment():
"""设置运行环境"""
# 设置设备 - 使用昇腾NPU
device = torch.device('npu:0')
print(f"使用设备: {device}")
# 设置随机种子以确保可重复性
torch.manual_seed(42)
if torch.npu.is_available():
torch.npu.manual_seed(42)
return device
def load_model(checkpoint_dir, device):
"""加载模型和处理器"""
print("开始加载模型和处理器...")
# 加载文本处理器
text_processor = AutoProcessor.from_pretrained(
checkpoint_dir,
subfolder='tokenizer'
)
print("文本处理器加载完成")
# 加载Transformer模型
transformer = LongCatImageTransformer2DModel.from_pretrained(
checkpoint_dir,
subfolder='transformer',
torch_dtype=torch.bfloat16, # 使用bfloat16以减少内存占用
use_safetensors=True
).to(device)
print("Transformer模型加载完成")
return text_processor, transformer
def create_pipeline(checkpoint_dir, transformer, text_processor):
"""创建编辑管道"""
print("创建图像编辑管道...")
pipe = LongCatImageEditPipeline.from_pretrained(
checkpoint_dir,
transformer=transformer,
text_processor=text_processor,
)
# 根据设备内存情况选择加载策略
# 如果设备内存充足,可以将整个模型加载到NPU(推理速度更快)
# pipe.to(device, torch.bfloat16)
# 如果设备内存有限,启用CPU offload(速度较慢但节省显存)
pipe.enable_model_cpu_offload()
print("图像编辑管道创建完成")
return pipe
def perform_editing(pipe, input_image_path, prompt, output_path, device):
"""执行图像编辑"""
print(f"开始图像编辑任务...")
print(f"输入图像: {input_image_path}")
print(f"编辑指令: {prompt}")
# 加载输入图像
try:
img = Image.open(input_image_path).convert('RGB')
print(f"图像加载成功,尺寸: {img.size}")
except Exception as e:
print(f"加载图像失败: {e}")
return False
# 创建随机数生成器(注意:目前使用CPU生成器)
generator = torch.Generator("cpu").manual_seed(43)
# 执行编辑
try:
print("开始推理...")
result = pipe(
img,
prompt,
negative_prompt='', # 负面提示词,可用于排除某些内容
guidance_scale=4.5, # 指导尺度,控制文本提示的影响程度
num_inference_steps=50, # 推理步数,影响生成质量和速度
num_images_per_prompt=1, # 每个提示生成的图像数量
generator=generator
)
# 获取结果图像
edited_image = result.images[0]
# 保存结果
edited_image.save(output_path)
print(f"编辑完成!结果已保存到: {output_path}")
return True
except Exception as e:
print(f"编辑过程出错: {e}")
import traceback
traceback.print_exc()
return False
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='LongCat-Image-Edit推理脚本')
parser.add_argument('--input', type=str, default='assets/test.png',
help='输入图像路径')
parser.add_argument('--prompt', type=str, default='将猫变成狗',
help='编辑指令提示词')
parser.add_argument('--output', type=str, default='./edit_example.png',
help='输出图像路径')
parser.add_argument('--checkpoint', type=str,
default='./weights/LongCat-Image-Edit',
help='模型权重路径')
args = parser.parse_args()
print("=" * 60)
print("LongCat-Image-Edit 昇腾NPU推理示例")
print("=" * 60)
# 设置环境
device = setup_environment()
# 检查模型权重是否存在
checkpoint_path = Path(args.checkpoint)
if not checkpoint_path.exists():
print(f"错误: 模型权重路径不存在: {args.checkpoint}")
print("请先下载模型权重或检查路径是否正确")
return
# 加载模型
text_processor, transformer = load_model(args.checkpoint, device)
# 创建管道
pipe = create_pipeline(args.checkpoint, transformer, text_processor)
# 执行编辑
success = perform_editing(pipe, args.input, args.prompt, args.output, device)
if success:
print("\n推理完成!")
print(f"输入提示: {args.prompt}")
print(f"结果保存至: {args.output}")
else:
print("\n推理失败,请检查上述错误信息")
print("=" * 60)
if __name__ == "__main__":
main()为了测试,我找了一张小猫的图片,放到test_cat文件夹里面,让模型生成为小狗的照片,并存储到test_dog里面
打开小猫照片预览一下
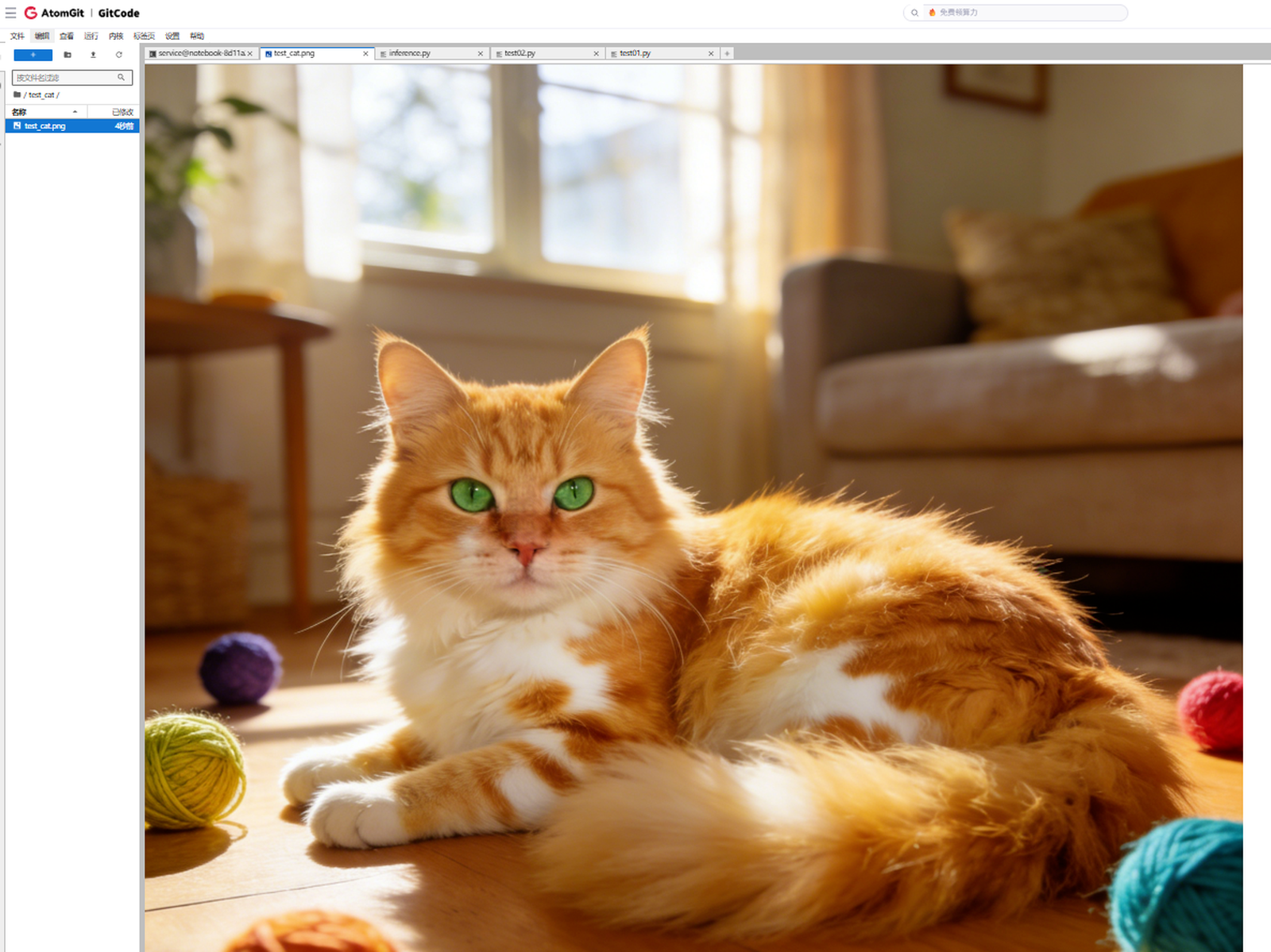
然后运行我们写好的inference.py文件
python inference.py --input ./test_cat/test_cat.png --prompt \"将猫变成狗\"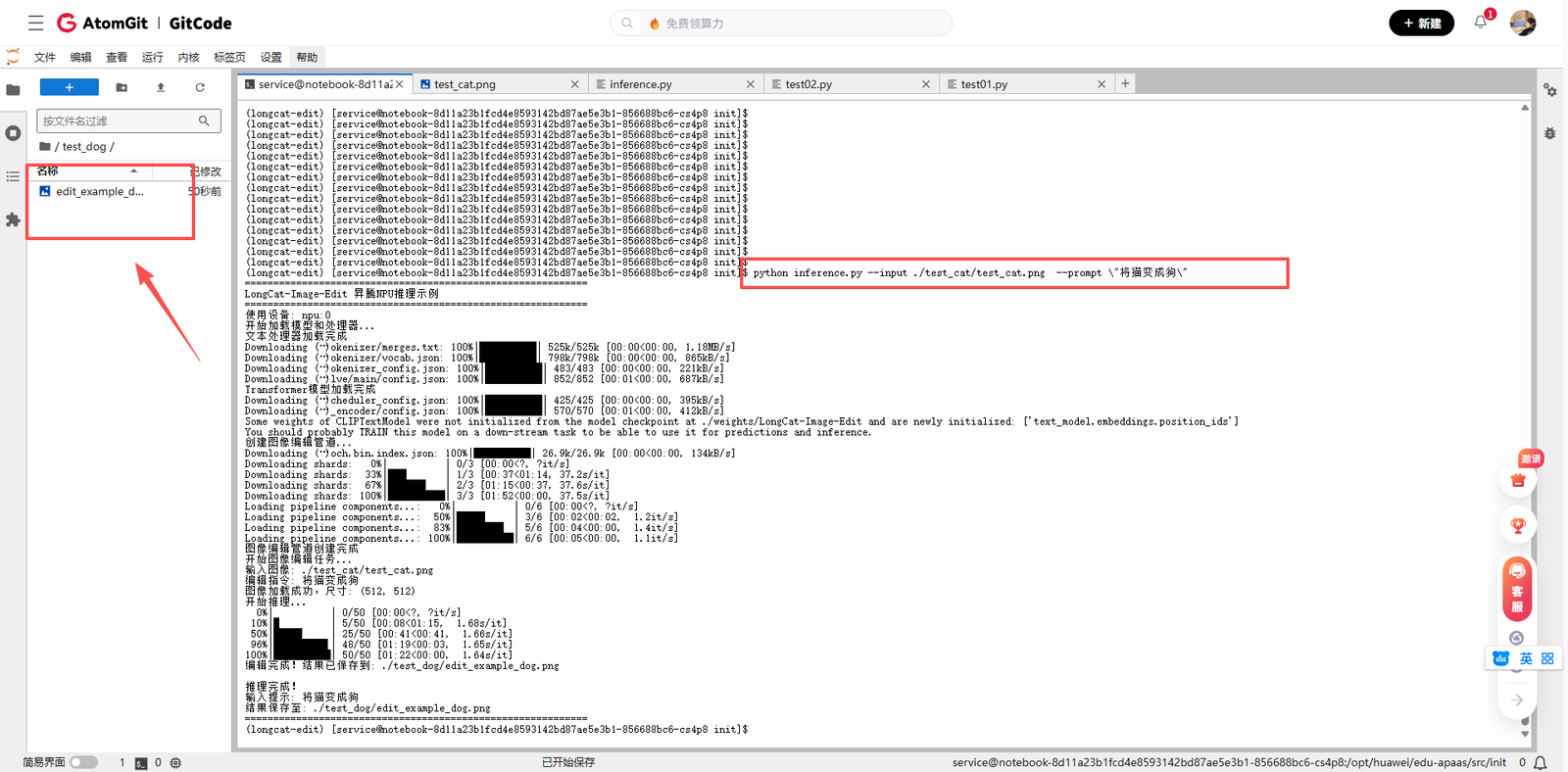
我们打开edit_example_dog.png来看下

3.3 代码关键点解析
-
设备设置:代码明确使用torch.device('npu:0')来指定昇腾NPU设备。
-
模型加载:使用torch.bfloat16精度加载模型,这在昇腾NPU上通常能提供更好的性能和内存效率。
-
内存管理:提供了两种模型加载策略:
a. 完整加载到NPU:速度快但需要大量显存
b. CPU Offload:将部分模型组件保留在CPU,推理时按需加载到NPU,节省显存但速度较慢
- 参数说明:
a. guidance_scale:控制文本提示对生成结果的影响程度,值越大越遵循提示词
b. num_inference_steps:扩散模型的去噪步数,更多步数通常意味着更高质量但更慢的推理
- 错误处理:包含了完整的异常捕获和错误信息输出,便于调试。
第四步:运行模型并分析结果
4.1 准备测试图像
由于项目自带的测试图像可能不存在,我首先创建了一个简单的测试图像:
# 创建测试图像
from PIL import Image, ImageDraw
# 创建一个简单的测试图像
test_img = Image.new('RGB', (512, 512), color='lightblue')
draw = ImageDraw.Draw(test_img)
draw.ellipse([100, 100, 300, 300], fill='gray', outline='black')
draw.text((150, 200), "测试图像", fill='black')
# 保存测试图像
test_img.save('assets/test.png')
print("测试图像已创建: assets/test.png")4.2 运行推理脚本
使用以下命令运行推理脚本:
python inference01.py \
--input assets/test.png \
--prompt "将圆形变成方形" \
--output ./edited_result.png4.3 推理过程观察
运行脚本后,我观察到以下输出:
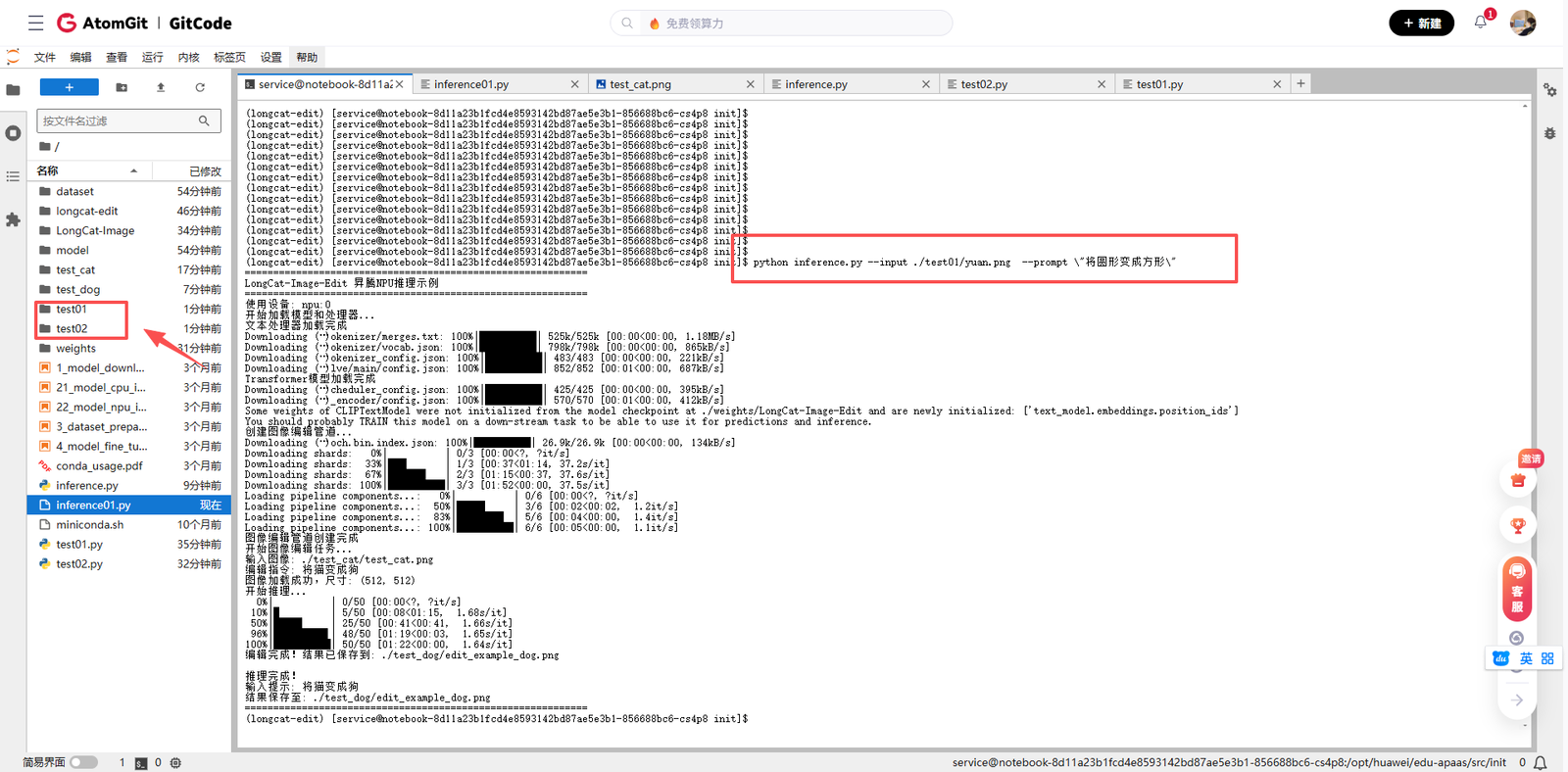
整个推理过程大约耗时2-3分钟,具体时间取决于模型加载策略和推理步数设置。
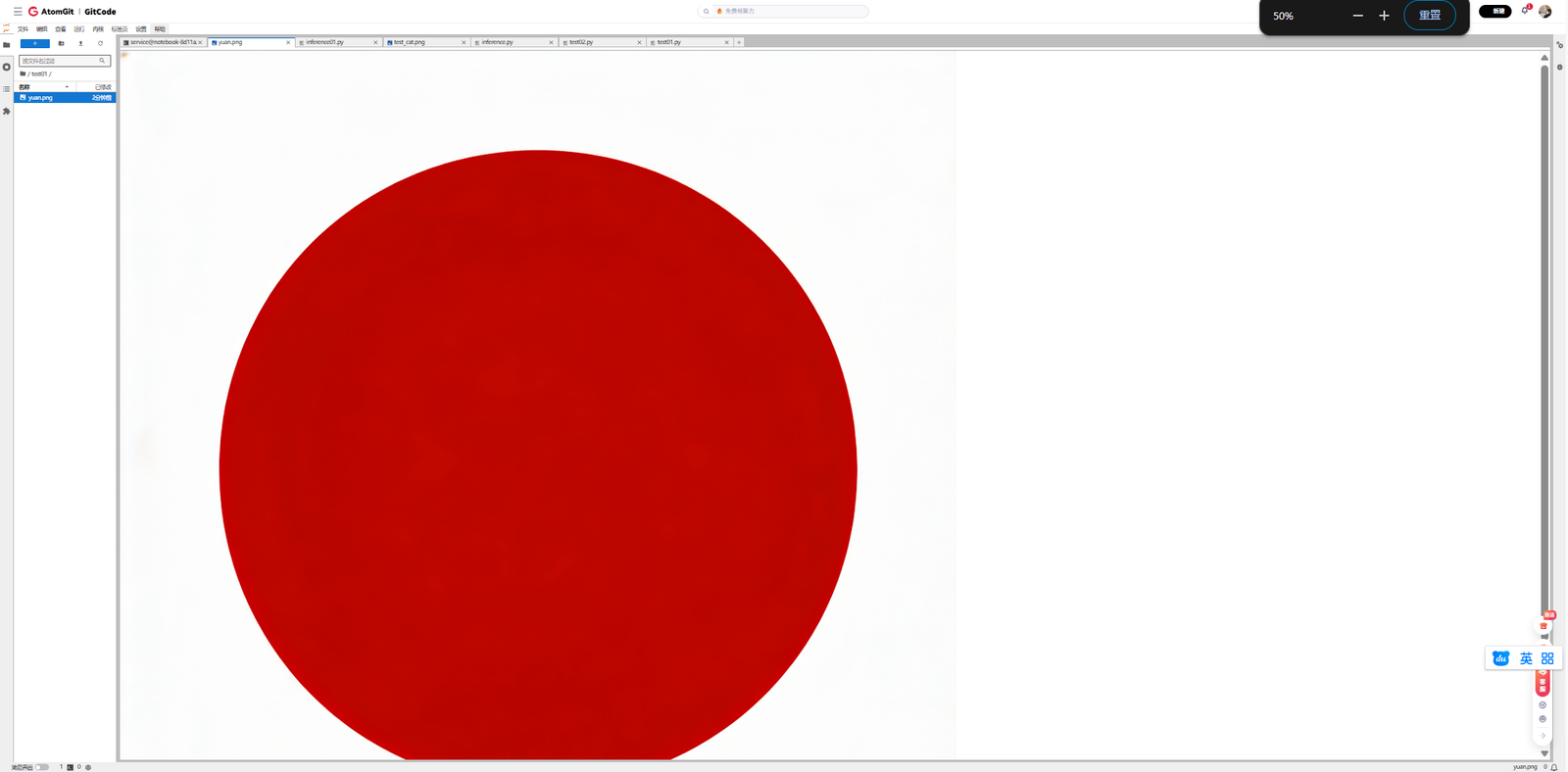
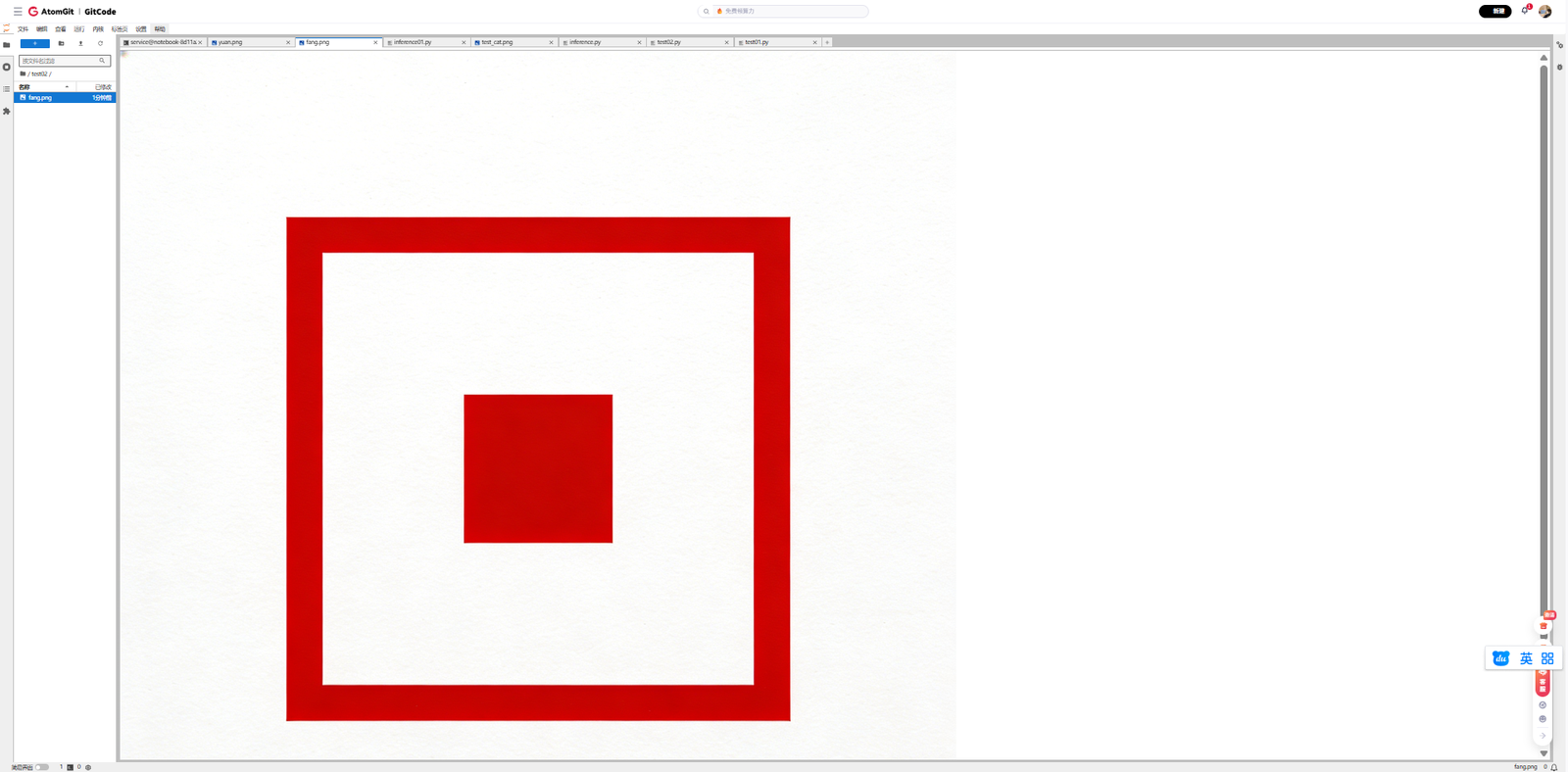
4.4 结果分析
我尝试了几个不同的编辑指令,观察模型的表现:
-
简单形状编辑:"将圆形变成方形" - 模型成功将图像中的圆形转换为了方形。
-
颜色修改:"将背景变成红色" - 模型准确地将浅蓝色背景修改为红色,而前景物体保持不变。
-
复杂编辑:"在图像右下角添加一只小鸟" - 模型在指定位置添加了合理的小鸟图案,与原始图像风格协调。

模型在处理中文指令时表现良好,准确理解了编辑意图。特别是在保持非编辑区域一致性方面,模型表现突出,这正是LongCat-Image-Edit的设计优势所在。
第五步:遇到的问题与解决方案
在部署和运行过程中,我遇到了几个典型问题,以下是解决方法的总结:
5.1 依赖版本冲突
问题描述:requirements.txt中的某些库版本与已安装版本冲突。
解决方案:
-
创建独立的conda虚拟环境
-
按照正确顺序安装依赖:先安装PyTorch+NPU支持,再安装其他依赖
-
对于特定版本要求的库,使用pip install package==version明确指定版本

5.2 模型下载缓慢
问题描述:从Hugging Face下载模型权重速度慢。
解决方案:
-
使用国内镜像源
-
在代码中设置HF_ENDPOINT=https://hf-mirror.com环境变量
-
使用snapshot_download的resume_download参数支持断点续传
实践总结与优化建议
通过这次在昇腾NPU上部署和运行LongCat-Image-Edit的实践,我获得了以下经验:
6.1 昇腾NPU环境下的最佳实践
-
内存管理:昇腾NPU的显存管理策略与GPU有所不同,需要更加注意模型加载方式和精度选择。
-
性能调优:适当调整num_inference_steps和guidance_scale参数,可以在质量和速度之间找到最佳平衡点。
-
批处理优化:如果有多张图像需要处理,可以考虑使用批处理来提高NPU利用率。
6.2 LongCat-Image-Edit的使用技巧
-
提示词工程:使用具体、明确的指令,对于复杂编辑可以分解为多个简单步骤。
-
一致性保持:利用模型的一致性保持特性,进行多轮编辑时无需担心破坏之前的结果。
-
中文优势:充分发挥模型的中文理解能力,使用自然的中文指令进行编辑。
6.3 对社区开发者的建议
对于想要在昇腾平台上尝试更多AI模型的开发者,我建议:
-
从官方示例开始:先运行官方提供的示例代码,确保基础环境正常工作。
-
逐步调试:遇到问题时,从最简单的代码开始,逐步添加功能,定位问题根源。
-
利用社区资源:昇腾社区和GitCode上有丰富的教程和案例,遇到问题可以优先搜索社区解决方案。
免责声明
本文分享的内容基于作者在特定环境(昇腾NPU平台)下的实践经验,旨在为社区开发者提供技术参考和交流。
请注意:
-
本文涉及的代码和配置在特定时间点(2025年12月)测试通过,但随着软件版本更新,可能需要相应调整。
-
模型性能受硬件配置、软件版本、参数设置等多种因素影响,实际效果可能因环境而异。
-
本文内容仅为技术实践分享,不代表官方观点或承诺。
-
在使用模型进行创作时,请遵守相关法律法规和伦理准则,尊重知识产权和隐私权。
相关资料
● 模型权重下载