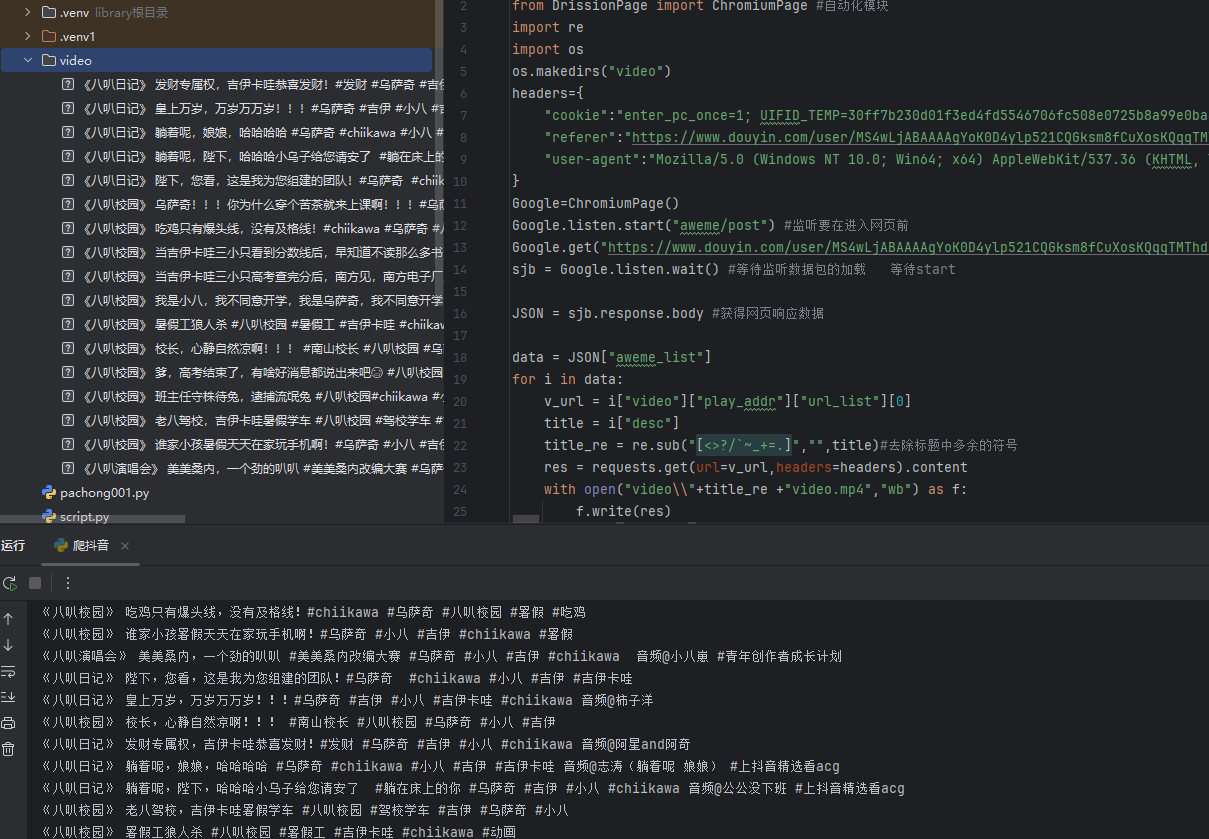
python爬虫爬取视频
1.导入模块
pip install requests
pip install DrissionPage
注意:项目文件不要放在中文目录下
使用到了自启动谷歌浏览器,记得安装一个谷歌浏览器
DrissionPage是Python第三方模块,可以用
来操作网页、抓取内容、模拟登录、处理JavaScript页面等
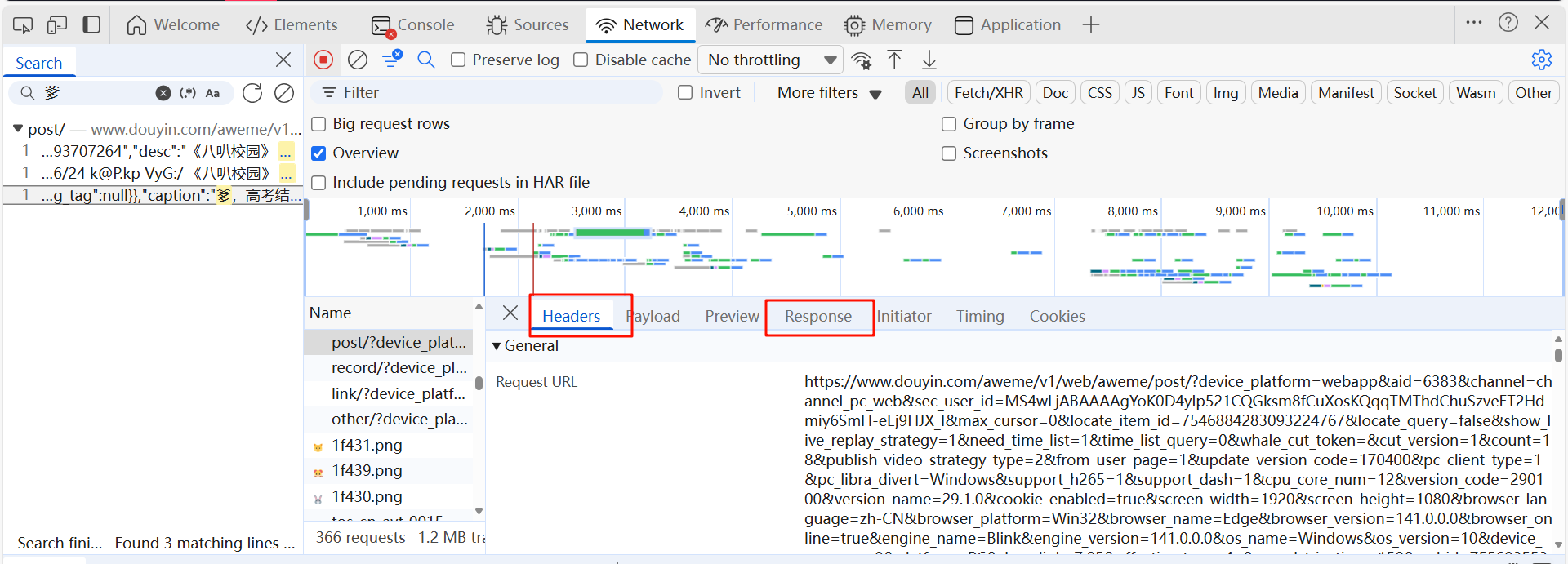
2.找到想要爬取的界面
需要注意我标注的地方
需要获取请求头中cookie,referer,user-agent
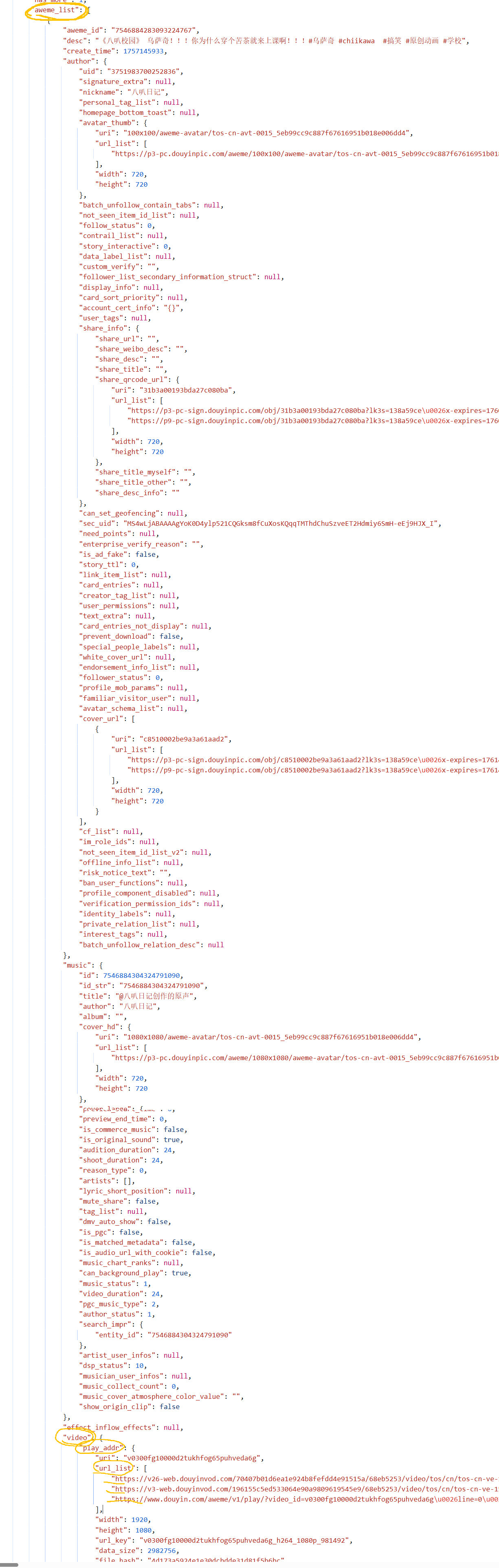
和响应回来的response中视频的链接地址,我有用黄圈圈出出来
可以看到视频地址在aweme_list下的video下的play_addr下的url_list中3条视频地址都可以用分别对应索引中的0,1,2
版权声明:本文为CSDN博主「摸鱼的泡泡糖」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_56387846/article/details/153113568
3.代码
这里cookie和referer太长,自己打开开发者工具复制就行
爬取视频的主页不同记得换下主页地址就是换Google.get和监听Google.listen.start后的内容
bash
import requests
from DrissionPage import ChromiumPage #自动化模块
import re
import os
os.makedirs("video") #创建video目录
headers={
"cookie":"",
"referer":"",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"
}
Google=ChromiumPage()#自动打开谷歌浏览器
Google.listen.start("aweme/post") #监听要在进入网页前
Google.get("https://www.douyin.com/user/MS4wLjABAAAAgYoK0D4ylp521CQGksm8fCuXosKQqqTMThdChuSzveET2Hdmiy6SmH-eEj9HJX_I?from_tab_name=main&vid=7520453386236349706")#爬取视频的主页
sjb = Google.listen.wait() #等待监听数据包的加载 等待start
JSON = sjb.response.body #获得网页响应数据
data = JSON["aweme_list"]
for i in data:
v_url = i["video"]["play_addr"]["url_list"][0]#找到视频地址
title = i["desc"]#获取视频标题
title_re = re.sub("[<>?/`~_+=.]","",title)#去除标题中多余的符号
res = requests.get(url=v_url,headers=headers).content
with open("video\\"+title_re +"video.mp4","wb") as f:
f.write(res)
print(title_re)